
人脸属性编辑的全局组织网络算法
2022-01-13 08:47戴忠健顾晓炜
北京理工大学学报 2021年12期
戴忠健, 顾晓炜
(北京理工大学 自动化学院,北京 100081)
人脸属性编辑是指将一张任意人脸图像作为输入,生成具有其他期望属性的人脸图像. 人脸属性编辑可以作为人脸识别数据增广的有效方式,其生成的不同属性的人脸图像丰富了人脸类内数据,部分解决了自然环境下由于人脸可变性带来的精度损失,提高识别模型泛化能力. 人脸属性编辑属于多域的图像到图像的翻译任务,它可以预测年老的样貌,生成各种属性变换后的人脸,是一个有趣同时也充满挑战的任务.
一方面,由于无法在同一张人脸上收集具有不同属性的人脸图像标签(一个人无法同时具有秃头和刘海特征),研究人员采用无监督的生成学习方法[1-2]完成人脸属性编辑任务;另一方面,人脸包含各种不同属性,每个属性都需要一个合适的模型去编辑. 为了在单个模型中编辑多个人脸属性,一些基于编码解码器结构的方法被提出[3-6].
然而,人脸属性复杂多样,包含了如眼镜、发色这样的局部特征,以及男女、年龄等编辑范围大的全局特征. 如何把属性标签信息融入编码解码器中将很大程度上决定整个模型的编辑效果. 为了提高编辑能力,CycleGAN[7]引入了cycle-consistent 编码解码器结构,AttGAN[3],Stargan[4]使用了跳跃连接的方法. 但是,直接将潜在表达与属性标签连接并解码会降低人脸还原度,而添加跳跃连接会以损失属性编辑能力为代价提高人脸重塑能力. 为了解决这个问题,STGAN[8]提出了选择转移单元STU,将潜在表达与属性标签连接作为初始状态,并向上采样生成一系列状态信息,使属性标签与编码特征充分融合. 然而,选择转移单元将具有高维语意信息的编码器特征作为初始状态,该状态在进行上采样生成不同尺寸的状态时会丢失细节信息,造成属性细节表述模糊,并且在重塑人脸时会产生随机噪声. 图1展示了STGAN与本文方法的人脸还原结果与属性编辑结果.

图1 STGAN与本文方法的人脸编辑结果Fig.1 The editing results of STGAN and the proposed method
基于以上分析,本文提出了一种新的属性信息传递方式U型传递,新的信息融合单元全局组织单元以及新的下采样模式. 与之前网络所采用的上采样提取状态不同,U型传递方式首先通过下采样将属性信息融入浅层编码器特征并生成一系列反向状态,再利用全局组织单元把反向状态、属性标签及编码器特征进行融合,并上采样生成不同尺寸的全局状态. 用U型传递方式获得的全局状态兼具细节与属性信息,以此结合解码器特征能够同时提高人脸重塑能力与属性编辑能力.
实验结果证明,与其他人脸属性编辑算法相比,本文所提出的全局组织网络算法在人脸还原与属性编辑性能上表现得更加优秀.
1 方 法
1.1 U型传递
在人脸属性编辑网络中[3-4,8],属性信息是通过将解码器特征与属性标签结合并上采样进行传递的. 为了提高性能,STGAN[8]提出选择转移单元STU. STU引入GRU[9]中的状态信息,利用重置门选择提取前一层的状态并通过更新门生成该层的新状态,生成的状态特征将属性信息从高维传递至低维. 但是,STU将具有高维语意信息的编码器特征与属性标签结合作为初始状态,该状态在进行上采样时会丢失细节信息,造成属性细节表述模糊并产生随机噪声.
为了解决这个问题,本文提出U型传递方式,模型结构如图2所示. 首先,将低维编码器特征(尺寸64×64)与属性标签结合作为初始状态,利用STU生成从低维到高维的反向状态. 这个过程有效地将属性标签与编码器特征融合,生成的反向状态具有属性信息且更加注重细节. 从图2中可以看到,STU生成的反向状态会输入到对应尺寸的全局组织单元GOU中. GOU是由GRU改进而来,其中增加了互补门,目的是融入反向状态并生成全局状态. GOU将高维编码器特征(尺寸4×4)与属性标签结合作为初始状态,在上采样过程中融入了反向状态,有效地补足细节信息,抑制噪声的产生,同时来自反向状态与隐藏状态两种不同维度的属性信息共同作用提高了模型属性编辑的能力. 如图2所示,模型的状态流动方向通过STU从低维流向高维,再经由GOU从高维流向低维,整个过程称为U型传递.

图2 网络模型整体结构Fig.2 The overall structure of the proposed network
1.2 全局组织单元
为了解决STGAN在编辑人脸时出现属性模糊及随机噪声的问题,本文提出全局组织单元GOU. GOU能够以有效的方式融合反向状态、隐藏状态、编码器特征与属性标签并以此生成全局状态. 其中,编码器特征是输入图像经过编码器下采样生成的潜在表达,反向状态是指由STU生成的一系列从低维到高维的状态信息,隐藏状态是GOU模块每一层更新后的状态,属性标签是指输入图像是否具有某种属性的一维向量标签. GOU通过重置门、互补门与更新门将上述信息结合生成全局状态,因此,全局状态兼具属性信息与细节特征,其与解码器特征连接能够同时提高人脸还原和属性编辑能力. 图3呈现了GOU的内部结构.
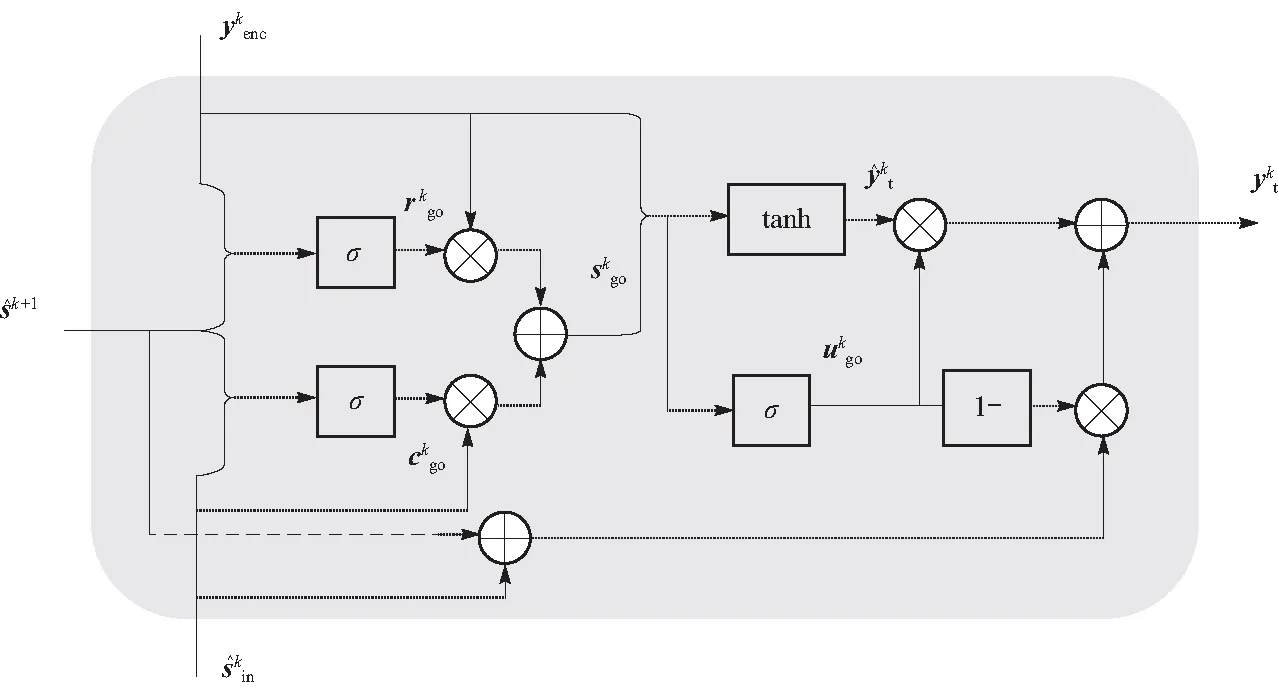
图3 全局组织单元详细结构Fig.3 The detailed architecture of GOU
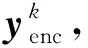
在STU中反向状态需由低维传递到高维. 为了匹配编码特征尺寸,用步长卷积层下采样
(1)

(2)
(3)
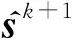
(4)
(5)
(6)
(7)
(8)
(9)
(10)
(11)
1.3 信息自组模块
U型传递首先利用STU由低维到高维生成反向状态. 考虑人脸属性复杂多变,低维编码器特征由于感受野不足无法提供满意的属性信息. 因此反向状态的作用会由于感受野的限制表现不佳. 为了更好地配合U型传递,本文重新设计了模型的编码器部分,即信息自组模块(IAB),如图4所示.

图4 信息自组模块Fig.4 Information auto-organization block
为了更好地表达复杂的人脸属性,IAB引入空洞卷积来增加感受野. 但是,仅仅使用空洞卷积会因为空洞间隙造成信息遗漏. 为了解决这个问题,IAB将上一层特征分别与空洞率2和4的空洞卷积提取的特征结合,通过信息叠加弥补空洞遗漏. 同时,IAB加入通道注意力机制SE模块[10],帮助特征在通道上重新校准. 如图5所示,由IAB提取的特征能够获得更大的感受野.
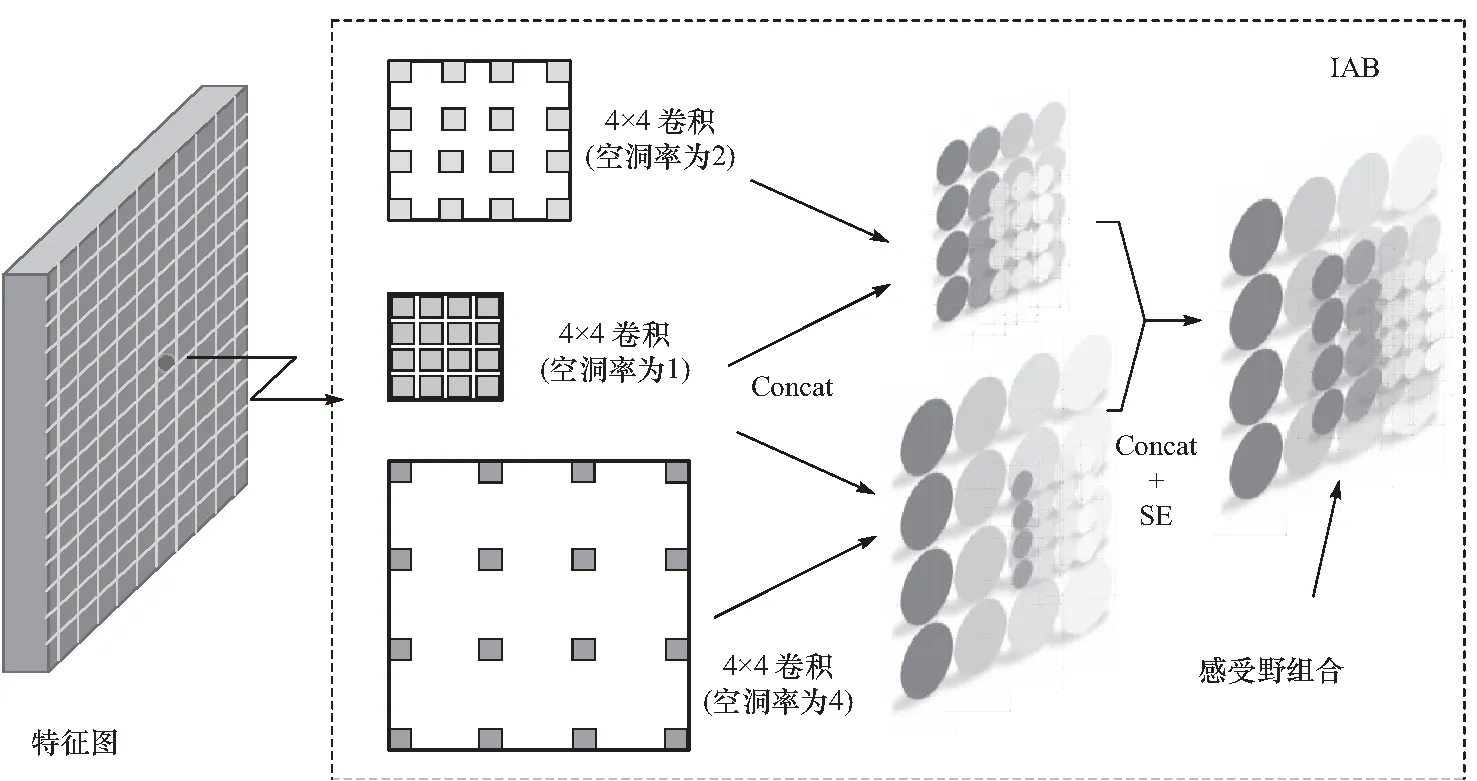
图5 信息自组模块提取的感受野组合Fig.5 The receptive fields extracted by information auto-organization block
2 模型结构
本文所提算法包括两个部分:判别器与生成器. 其中,生成器包含用来提取潜在表达的编码器Genc,以及用来生成假人脸图像的解码器Gdec. 判别器由两个分支组成:其中,Dcls用来限制生成图像,令其只对期望属性进行编辑,Gadv用来区分一张图像是否来自真实分布. 除此以外,GOU部署在编码器与解码器之间.
如表1所示,编码器Genc的前3层由IAB组成,后2层由尺寸为4、步长为2的普通卷积组成,解码器Genc部署了5个与编码器相同尺寸的反卷积层. 判别器Gadv由5个卷积层与2个全连接层组成.Dcls与Dadv共享5个卷积层,同时独有额外的2个全连接层. 表1中,BN是文献[11]的缩写,IN是文献[12]的缩写,LN是文献[13]的缩写,Conv(64,4,2)表示卷积核尺寸4、步长2、通道数64的卷积操作.
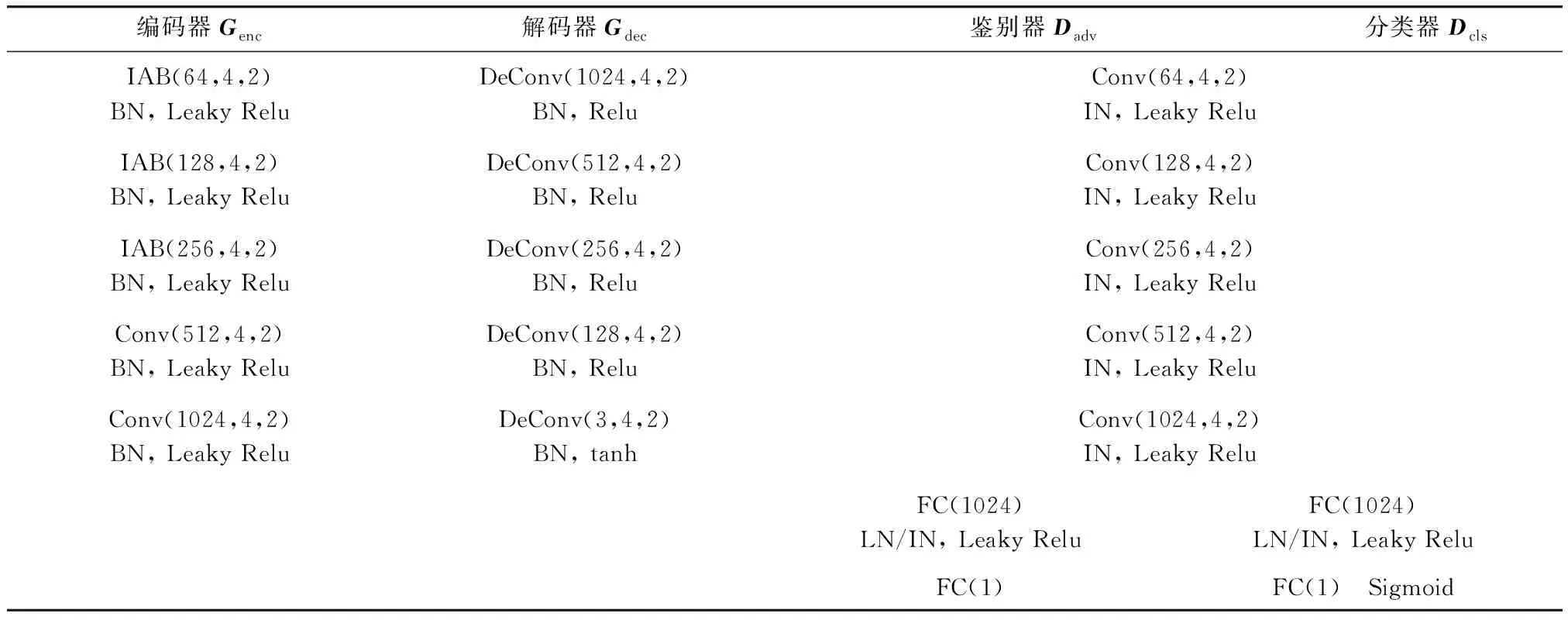
表1 模型结构Tab.1 The structure of the model
3 损失函数
将输入的人脸图像表示为x,编码器Genc把x抽象成编码器特征Yenc,Yenc的表达式如下(大写字母代指一系列输出的组合)
Yenc=Genc(x)
(12)
GOU将隐藏状态、反向状态、编码器特征以及属性标签组织成全局状态与输出
(Yt,Sgo)=Ggo(Yenc,Sin,S,att)
(13)
(14)
整个人脸属性编辑过程可以定义为无监督的编码器与解码器的学习过程. 编辑结果需要还原人脸并同时编辑期望属性. 为了达到这个目的,本文采用了对抗损失,重塑损失以及属性分类损失.
3.1 对抗损失
本文采用对抗损失训练生成器和判别器. 与WGAN[14],WGAN-GP[15]相同,对抗损失表达式如下
(15)
(16)

3.2 重塑损失
本文采用重塑损失还原人脸,保留除编辑属性以外的人脸细节.重塑损失表达式如下
(17)
式中l1用来抑制模糊.
3.3 属性分类损失
本文采用属性分类器来实现人脸属性的编辑,属性分类损失定义如下
LDcls=
(18)
LGcls=
(19)
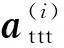
(20)
整个判别器损失表达式如下
(21)
式中:λ1=100,λ2=10,λ3=1为超参数平衡上述损失.
4 实验与结果
本文使用Tensorflow[16]深度学习框架,由ADAM[17]优化器(β1=0.5,β2=0.999)训练而成,批量大小为16,学习率设置为0.000 2.
本文在CelebA[18]数据集上进行训练与评价. 为了公平对比,本文所提算法在与人脸属性编辑算法[3-4,8]相同的实验环境下进行性能验证. CelebA数据包含202 599张对齐人脸图像,并分为训练集、测试集与验证集. CelebA数据中的图像均被裁剪为178×218大小的人脸图,且每张图都分配了属性标签. 与以往算法[3-4,8]相同,本文选择40个属性中13个具有代表性的属性,包括秃头、刘海、黑发、红发、棕发、浓眉、眼镜、男性、嘴微张、胡子、无胡须、浅肤色以及年轻. 与人脸属性编辑算法[4,8]相同,本文从两个方面评估人脸属性编辑性能. 一方面是属性编辑成功率,其反映了算法能够正确编辑期望属性的性能;另一方面是图像质量,能够验证编辑结果的真实性. 为了更加直观公平地对比,本文采用STGAN的方法来评估算法的属性编辑性能. STGAN利用CelebA训练集去训练一个属性分类器,该分类器在测试集的13个所选属性中测试并获得94.5%平均准确率. 本文将算法生成的编辑结果作为输入,通过属性分类器获得属性编辑成功率. 如表2所示,本文所提算法在大部分属性中获得了更高的编辑成功率. 值得注意的是,该算法的平均成功率比STGAN高出5%,这表明在属性编辑方面,本文所提算法具有更好的泛化能力. 图6展示了本文算法与其他对比算法的人脸属性编辑结果.

图6 人脸属性编辑结果Fig.6 The results of facial attribute editing

表2 不同方法的属性编辑成功率Tab.2 Attribute generation accuracy of different methods
对于图像质量的评价,表3给出了上述方法生成重塑图像的PSNR/SSIM结果. 很明显,本文所提算法比STGAN在PSNR指标上高出了5 dB.
本文提出U型传递方式,将低维编码器特征(尺寸64×64)与属性标签结合作为初始状态,利用STU生成从低维到高维的反向状态. 这个过程有效的将属性标签与编码器特征融合,生成的反向状态具有属性信息且更加注重细节. 与此同时,本文设计GOU模块,结合反向状态,隐藏状态与编码器特征,并生成全局状态. GOU将高维编码器特征(尺寸4×4)与属性标签结合作为初始状态,在上采样过程中融入了反向状态,有效补足细节信息,抑制噪声的产生,同时来自反向状态与隐藏状态两种不同维度的属性信息共同作用提高了模型属性编辑的能力. 此外,本文设计IAB下采样丰富浅层特征感受野,提高网络属性编辑的泛化能力. 从表2与表3的实验结果来看,本文所提方法能够同时提高人脸还原度与属性编辑性能.

表3 图像质量与平均编辑成功率Tab.3 Images quality and attribute generation average accuracy
为了进一步验证本文方法的属性编辑性能,本文从人脸识别的角度进行实验验证. 优秀的人脸属性编辑网络能够在还原人脸的基础上编辑期望属性. 因此,将其作为人脸识别数据增广的方式可以有效增加类内数据. 不同于普通数据增广,人脸属性编辑可以改变人脸各种属性,换句话说,它能够预测不同状态不同时期下的人脸图像,部分解决由于时间变化引起的自然环境下人脸可变性的问题,从而提高人脸识别网络的泛化能力. 本文以MS-Celeb-1M[19]作为人脸识别的训练集,并在LFW[20],CFP[21],AgeDB[22]测试集上进行测试验证. MS-Celeb-1M提供了5.8 M张照片,其中包含了85 K个不同身份的人物. 为了验证方便,本文在训练集前2 000个人物下进行属性增广,并将Mobilefacenet[23]作为识别模型. 如表4所示,在经过本文方法数据增广后,Mobilefacenet在3个测试集上的识别准确率都得到了提高,这进一步验证了本文所提方法优越的人脸还原与属性编辑能力.

表4 Mobilefacenet在不同数据下的识别准确率
5 消融实验
为了探究IAB下采样与GOU模块对人脸属性编辑的效果,本文对几个网络变体进行了相关实验. 本文设计了6个不同网络:ST-IAB1,ST-IAB2,ST-IAB3,GO-IAB0,GO-IAB1,GO-IAB2. 其中,ST表示采用STGAN[8]算法,IAB0是指编码器下采样均采用普通步长卷积,IAB1表示第一个下采样使用IAB模块,IAB2表示前两个下采样使用IAB模块,GO表示使用GOU模块,本文方法前3层编码器下采样采用IAB模块. 为了公平对比,所有实验均采取上述实验标准.
从表5中可以看出,用IAB模块作为编码器下采样可以有效丰富浅层特征的感受野,提高STGAN以及本文算法的人脸还原度与属性编辑成功率. 当IAB模块充当前3层编码器下采样时,STGAN的属性编辑成功率提高了1.5%,本文所提算法的编辑成功率达到91.5%. GO-IAB0表示将STGAN中的STU模块替换成GOU模块,从表5可以很明显地发现,GOU在融入反向状态后大幅提高了网络的人脸还原度与属性编辑成功率,这说明反向状态有效补足细节信息,帮助网络抑制噪声的产生. 与此同时,在GOU模块的基础上使用IAB模块能够进一步提高网络性能.

表5 不同网络的人脸重塑质量与属性编辑成功率Tab.5 Reconstruction quality and attributes generation accuracy of different networks
6 结 论
根据对人脸属性编辑网络的研究,本文提出了全局组织网络算法. 其中,U型传递改变传统属性信息的流动方式,生成的反向状态为全局组织单元提供浅层编辑属性与细节信息. 为了更好地配合全局组织单元,本文提出信息自组模块,取代原有编码器下采样. 信息自组模块通过结合普通卷积与空洞卷积有效增加了编码特征的感受野,改善模型浅层属性的提取能力. 最后,全局组织单元将编码特征、反向状态与全局状态进行融合,消除随机噪声并精细属性细节表达. 实验证明,本文所提算法能够同时提高人脸重塑与属性编辑能力. 值得注意的是,通过本文方法对人脸数据进行数据增广能够有效提高人脸识别模型的泛化能力.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
数字技术与应用(2021年1期)2021-03-24
金桥(2018年4期)2018-09-26
科技与创新(2017年5期)2017-03-28
米娜·女性大世界(2016年8期)2016-08-17
当代贵州(2014年13期)2014-09-21
