
文字识别技术在智慧教育中的应用与思考
2022-01-11 09:42李进豪
现代计算机 2021年32期
李进豪
(1.广东省海洋工程职业技术学校,广州 510320;2.广东生态工程职业学院,广州 510520)
0 引言
随着人工智能理论和技术的日益成熟,其应用正日趋普及化,并为教育教学改革带来一系列的创新应用。调研表明,在教育教学过程中,教育工作者经常需要对大量的文字、图片等原始资料进行处理,以便获取教育教学管理或课堂教学等所需的信息。为了减轻教育工作者的常规工作量和提高工作效率,基于文字识别技术的智能应用在教育教学过程中越来越多,其应用优化了教育过程和教学方式,助力教育实现了跨越式发展。
1 问题的提出
1.1 素材收集
作为广东省教师信息技术应用能力提升工程2.0专项科研课题主持人,在多技术融合应用的推进过程中,我们发现“素材收集”工作是每一位教育工作者都必须面对的,其工作量相对来说是较大的,耗费了大量的时间与精力。调研表明,每一位教育工作者都期望能有智能小助手来协助处理一些枯燥、流程化的工作,把自己从“低效的工作”中解脱出来。例如,纸质教材文字提取、外景拍摄图片文字提取等。因此,基于文字识别技术的批量图片文字智能提取是一项非常有意义的研究工作,有较强的实用价值,有利于助推多技术融合应用的普及化。
1.2 自动阅卷
作为广东省职业教育名师工作室主持人(信息技术方向),有助推广东省智慧教育前行的职责。在智慧教育的推进过程中,我们发现随着“翻转课堂”教学模式的普及化,越来越多的有效互动反馈都是基于测验(成果导向)来实现的。在测验中,我们需要处理大量的原始资料,以提取有效信息。对于职业教育来说,技能的培养是重中之重,而技能一般是需要学生亲自动手去操作的,其评价并不能用简单的文字题目来实现。例如,信息技术类技能测试的过程中,核心结果很多都是以图片形式呈现,其反馈不是文字描述可以替代的。因此,基于文字识别技术智能提取图片中的关键信息点是一项非常有价值的工作,有较高的研究价值,有利于助推智慧教育的大众化。
2 基于Python的文字识别技术
2.1 文字识别技术
文字识别技术是指利用计算机自动识别字符的技术,是模式识别应用的一个重要领域。一般包括文字信息的采集、信息的分析与处理、信息的分类判别等几个部分。
2.2 基于Python提取图片文字的基本原理
(1)调用一种高效的文字识别技术。
(2)以二进制格式打开一个图片文件。
(3)读取图片文件的全部内容。
(4)基于“OCR识别算法”识别文字。
(5)输出图片上的所有可识别文字。
2.3 一种支持限量免费使用的文字识别技术
2.3.1 百度智能云通用文字识别
基于业界领先的深度学习技术,提供多场景、多语种、高精度的整图文字检测和识别服务,基于接口支持限量的免费使用(免费账号)。如果需要获得更多的技术支持,可使用付费账号。
2.3.2 核心技术
(1)调用AipOcr。
from aip import AipOcr
(2)打开图片文件(二进制)。
with open(mypicfilename,′rb′)as myf:
(3)读取图片文件的信息。
myimg=myf.read()
(4)识别文字(调用接口函数)。
mymsg=client.basicGenera(lmyimg)
(5)循环获取所有的文字。
for i in mymsg.ge(t′words_result′):
myxx=myxx+i.ge(t′words′)
3 应用案例1:素材收集之文字获取
3.1 需求
在基于多技术融合的教育教学过程中,我们常需要批量提取纸质教材的文字、批量提取外景拍摄图片的文字等。例如,提取已经拍摄好的30张外景图片中的文字,并按指定的顺序合成为一个文本文件(或docx文档)。
需求来源:名师工作室专项课题(基于Python的文字自动识别系统的研究)。
3.2 基本原理
3.2.1 基础工作
基于扫描或拍摄将需要提取文字的图片按一定的顺序排序(此顺序一般将是批量识别的顺序,会将影响文件中的文字顺序),并复制到文字识别小程序的指定文件夹(例如input文件夹)。
3.2.2 智能提取
(1)按顺序智能读取每一张图片。
(2)基于Python 的文字识别技术识别图片中的所有文字。
(3)以追加模式写入指定文件夹中的文件中(例如output文件夹)。
3.2.3 后期编辑
在文字处理软件中读取文件中的所有文字,核查并编辑即可完成文字素材的获取。
3.3 基于Python的核心代码
3.3.1 调用AipOcr

3.3.2 循环读取指定文件夹下的所有图片文件
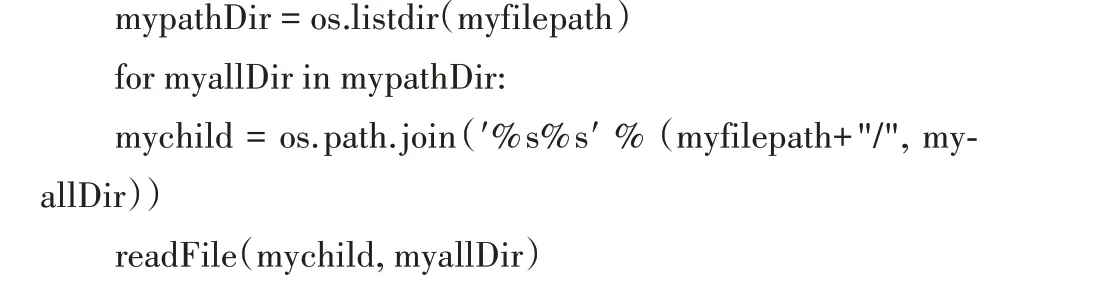
3.3.3 识别所有的文字


3.4 应用案例
3.4.1 图片(文件名:环山径简介.jpg)

图1 环山径简介
3.4.2 文字识别结果(文件名:环山径简介.txt)

图2 文字识别结果
3.5 思考
(1)为了提升图片的文字识别正确率,需要尽可能提高图片的清晰度与可辨认性。必要时,建议使用图片处理软件(例如Photoshop)对图片进行预处理。
(2)执行接口函数basicGenera(l)时,由于存在网络延时,因此有时会因为无法及时返回结果而导致程序中的后续语句出错。建议:在该语句之后使用延时语句time.sleep()解决。
(3)如果一次需要识别多个“批量图片”,而且需要等待的时间较长。建议:将不同的“批量图片”放在不同的文件夹中来实现。
(4)如果需要将识别结果直接保存为docx 格式,则将打开txt文件改为打开docx文件,其原理相似。
(5)百度智能云通用文字识别的免费使用次数对于普通教学应用是足够的(非营利性质)。特殊的应用场景,如果有需要,可采用付费模式解决。
(6)如果涉及保密信息,不建议使用调用“接口”的免费自动文字识别功能。
4 应用案例2:自动阅卷之图片关键信息点智能提取
4.1 需求
职业教育教学过程中的技能测试,测试的结果很多都不是可以用文字描述来替代的。例:《信息技术》课程的文档操作之“查找与替换”,我们需要知道的是学生的操作过程,而该操作过程的核心结果用截图的形式来呈现是比较科学的。为了实现自动阅卷,我们可以通过提取图片的关键信息点来判断学生的操作是否正确。如果有需要,可以通过判断多张图片(系列操作的图片)来确认,以提高自动阅卷的可靠性。
需求来源:名师工作室专项课题(基于Python的自动阅卷系统的研究)。
4.2 基本原理
4.2.1 基础工作
(1)每一位学生用自己的“姓名+学号”创建一个文件夹,所有操作截图(技能点)均按测试指定的文件名保存(文件名错误,视为0分)。
(2)教师设定自动阅卷时每一个技能点(操作截图)所需要判断的关键信息点,存放在参考答案的文件中(例如xlsx文件)。
(3)将学生的考试文件夹合并后存放在自动阅卷小程序指定的文件夹中(例如ksinput)。
4.2.2 自动阅卷
(1)自适应读取学生文件下的每一个文件(操作截图)。
(2)判断文件名是否为有效文件名。如果文件名不是参考答案中需要检测的文件,则视为无效文件。
(3)智能判断。如果文件名是参考答案中需要检测的文件,则自动提取该操作截图的关键信息点并与参考答案中的关键信息点相比较。如果完全一致,则认为该技能点可以得分,否则视为0分。
(4)循环读取并完成对所有文件的智能判断,累计得分即为学生本次技能测试的成绩。
(5)将成绩保存在指定的考试成绩文件中。
(6)按上述原理,循环读取所有学生的文件,即完成自动阅卷。
4.2.3 后期工作
根据需要处理考试成绩文件。若有规范性要求,则可使用Python 附加小程序来处理。例如:成绩排序、成绩分析等。
4.3 基于Python的核心代码
4.3.1 提取图片关键信息
核心代码:与应用案例1相同。
注意事项:如果需要识别的信息较多且没有专项经费支持(校内使用,非营利性质),在允许的情况下可申请多个百度智能云通用文字识别账号(免费账号);有可能的情况下,建议使用付费账号,以便获得更多的技术支持。
4.3.2 判断图片文件是否为有效文件

4.4 应用案例
4.4.1 图片(文件名:查找与替换.jpg)

图3 查找与替换
4.4.2 关键信息点(9个)
查找与替换、查找内容、工作室、替换为、名师工作室、替换、全部替换、查找下一处、取消。
4.4.3 智能提取结果(文件名:查找与替换.txt)

图4 智能提取结果
4.5 思考
(1)自动阅卷小程序的可靠性主要依赖于技能点之“操作截图”选择的合理性和“关键信息点”选择的科学性。
(2)因为所有的图片均来源于截图,其文字识别的正确率较高,无需对图片进行预处理。建议:学生规范化操作(截图),以免因为识别问题而导致成绩存在争议。
(3)建议:“操作截图”界面上尽量有一些标志性的文字,以提升自动阅卷的可信度。
(4)建议:在真正使用前,教师对所有的题目进行一次模拟操作,在生成技能点“操作截图”之后进行一次“尝试性”自动阅卷,以保证技能点“操作截图”选择的合理性和“关键信息点”选择的科学性。
(5)基于文字识别有时可能存在不可预测性。建议:在模拟操作的基础上,对阅卷时所需的“关键信息点”进行优化,以弥补文字识别可能存在的偏差。
(6)自动阅卷对文件名的要求较高。建议:文件名尽可能使用大写字母,尽量避免使用有“争议性”的字符。
(7)Python 支持对多种类型文件的“强”读写功能。以docx 文档为例,除了可以读取文件的内容外,还可以读取其文档格式。因此,在自动阅卷过程中,若有需要可以直接读取文件的相关信息,辅以判断操作结果的正确性。
(8)如果需要将自动阅卷小程序发放到学生端,则可以将参考答案做加密的预处理。
5 实践效果分析
5.1 素材收集
5.1.1 应用场景
(1)案例。30 张图片,每张图片平均约200个汉字,合计约6000个汉字。
(2)人工录入(某教学团队平均速度)。录入速度每分钟约50个汉字。
(3)自动识别(文字识别小程序)。每张图片约2秒。
5.1.2 效果分析
(1)人工录入。理论上所需时间约7200 秒,实际时间会更长。
(2)自动识别。理论上所需时间约60秒,实际时间相近。
(3)效果分析。在素材收集方面,文字自动识别技术的应用是非常有效的,有助于提升教师的幸福感和成就感。
5.2 自动阅卷
5.2.1 应用场景
(1)案例。30 位学生,每位学生有20 张图片,合计600张图片。
(2)人工阅卷(某教学团队平均速度)。每张图片平均需要10秒(含简易成绩录入等)。
(3)自动识别(自动阅卷小程序)。每张图片约2秒。
5.2.2 效果分析
(1)人工阅卷。理论上所需时间约6000 秒,实际时间会更长。
(2)自动阅卷。理论上所需时间约1200 秒,实际时间相近。
(3)效果分析。在阅卷方面,文字自动识别技术的应用同样是非常有效的。但由于阅卷过于标准化,在个性化评分方面略有不足。
6 结语
在智慧教育中应用文字识别技术,有利于提高工作效率,有利于开启智慧教育的创新模式。文中提及的代码全部在“Office 2016+Python 3.8.3”环境下调试通过,并应用于实际工作中,效果好。
猜你喜欢
电脑报(2020年35期)2020-09-17
电脑爱好者(2019年9期)2019-10-30
电脑爱好者(2019年13期)2019-10-30
课程教育研究(2018年30期)2018-12-14
电脑爱好者(2017年21期)2017-12-04
电脑爱好者(2017年15期)2017-08-31
小天使·一年级语数英综合(2017年3期)2017-04-25
莫愁(2017年9期)2017-04-07
汽车博览(2016年9期)2016-10-18
小学阅读指南·低年级版(2016年1期)2016-09-10
