
基于迁移学习和预训练技术的推理机器阅读理解模型
2022-01-11 09:42薛汇泉方建安
现代计算机 2021年32期
薛汇泉,方建安
(东华大学信息科学与技术学院,上海 201620)
0 引言
机器阅读理解[1]是自然语言处理领域中一项重要任务,在搜索引擎、智能问答和对话系统等领域具有广泛的应用场景,是一项评估计算机是否真正理解自然语言并具备一定的逻辑推理能力的任务。按照答案形式的不同,Chen 等[2]将机器阅读理解分为完型填空式、多项选择式、跨度抽取式和自由答案形式四种任务。本文关注多项选择式机器阅读理解[3],该任务需要在给定上下文、问题和候选答案集下,输出正确的答案,通常需要更高级的阅读理解技能,如逻辑推理、归纳演绎等,常用的评估指标是准确度。
目前,机器阅读理解领域中主流的研究方法是预训练语言模型技术[5],如BERT[6]、Ro-BERTa[7]等预训练语言模型,其中,RoBERTa 相比于BERT,在模型参数量、训练资源上都有一定的增强,更具鲁棒性和高效性。然而,受限于数据样本的不足,强大的预训练语言模型在需要逻辑推理能力的多项选择阅读理解数据集上的表现较差。因此,考虑通过丰富预训练语言模型能学习到的逻辑推理知识来增强模型的推理能力。选择LogiQA[8]数据集作为目标数据集,该数据集收集自中国国家公务员考试。相较于其他阅读理解数据集,LogiQA 不依赖于外部知识,文本短小精悍,更专注于逻辑推理。表1 是来自LogiQA 数据集的两个典型例子,一个完整的样本由上下文、问题、候选答案集和正确答案组成。首先,复现了LogiQA 的原始论文中发布的最佳基准模型,并在开发集中进行了细致的参数调优,也同样实验了不同输入组合下,模型在开发集中的表现。接着,提出的模型经过一个答案选择器在多个不同粒度的域外数据集上进行微调,使用滑动窗口方法可以解决缓解过长文本输入情况下导致计算机的显存不足问题,模型在不同窗口大小和步长值的实验表明多次阅读部分重叠的同一上下文的不同片段能增强模型的逻辑能力。最后,使用数据扩充技术,将经过迁移学习方法微调得到的模型在目标数据集与扩充的数据集上进行多任务学习,最终在目标数据集的开发集上取得了最佳表现。
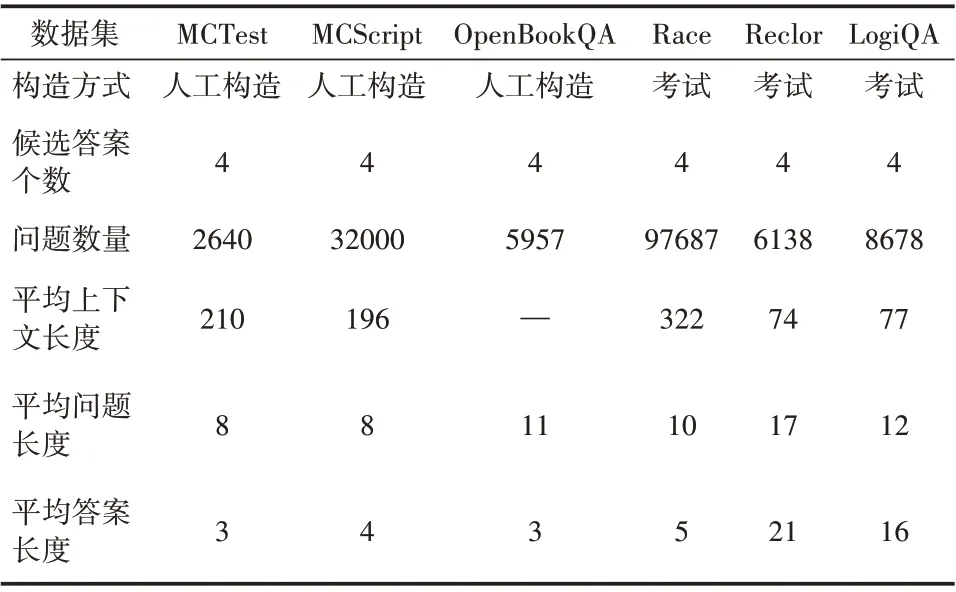
表1 数据集统计信息

表1 LogiQA数据集中的典型例子
1 相关工作
1.1 预训练+微调
预训练技术的出现使得自然语言处理进入了一个新的时代,语言模型先在大规模无监督文本语料库上进行预训练再在目标任务上微调的方法已成为自然语言处理领域中的主流方法。Dai等[9]使用预训练技术改进了循环神经网络中序列学习方法,在多项文本分类任务中取得了不错的效果;Devlin 等[6]提出的BERT 模型开创了预训练+微调方法的先河;Khashabi 等[10]构建了一个统一的预训练自动问答任务框架,在四种不同格式的问答任务下多个数据集上表现良好。基于预训练语言模型BERT[6]和RoBERTa[7]重新实现了LogiQA[8]原论文中发布的基准模型以及最佳表现,并进行细致的超参数调优;提出了一个基于Ro-BERTa 语言模型的推理阅读理解模型,该模型能在一定精度下自动输出一批给定的逻辑推理问题的答案。
1.2 迁移学习VS多任务学习
迁移学习是指将一个或多个任务上学习到的知识或模式应用到某个与之相关的领域中,从而加快模型的训练效率。关于迁移学习方法的研究最早可追溯到2014 年,Yosinski 等[11]研究了神经网络中的各层特征与权重参数的可迁移性。Min等[12]通过实验证明了迁移学习方法有助于提升语言模型在问答数据集上的表现。多任务学习则是要求模型将相互关联的多个任务同时学好,达到举一反三的效果。Argyriou 等[13]发布的跨多任务共享学习方法上的实验结果表明当任务相关时,多任务学习相较于单任务学习能显著提升模型的表现。复现了LogiQA 原始数据集中提出的迁移学习方法,通过设置不同的随机种子,提出的模型在四个具有代表性的多项选择式阅读理解数据集上进行充分的预训练,收敛后的迁移学习模型再在源数据集和目标数据集上进行多任务学习。
1.3 逻辑推理数据集
大规模阅读理解数据集的发布在极大程度上推动了机器阅读理解模型的不断建立,促进了机器阅读理解领域的进步。多项选择式阅读理解任务受到人类语言能力考试的启发而发布。MCTest数据集[14]和MCScript 数据集[15]以儿童故事书为蓝本,包含了大量需要使用常识知识进行推理的问题;OpenBookQA 数据集[16]探索了计算机对某一主题的深入理解;Race[17]数据收集了中国中学生英语考试的相关内容。然而,上述数据集都或多或少地依赖于外部知识和简单的词汇匹配。Reclor[18]数据集的来源是研究生入学考试,且专注于逻辑推理问题,在许多方面都与LogiQA 很相似。选择MCTest、MCScript、OpenBookQA、Race作为域外数据集参与到模型第一阶段的训练过程,在此过程中,模型习得的知识能在一定程度上能提升模型的泛化能力。将LogiQA 数据集作为目标数据集,Reclor 数据集作为源数据集,与LogiQA 数据集共同参与到模型第二阶段的多任务学习过程,以丰富模型所能获取到的逻辑推理知识和经验。
2 模型
2.1 任务定义
给定上下文C、问题Q以及候选答案集A={A1,A2,…,An},n为候选答案的个数,Ai∈A,表示第i个候选答案项,多项选择式阅读理解的任务旨在从候选答案集A中选择出正确选项Ai。该任务要学习的函数或模型为F,见公式(1)。
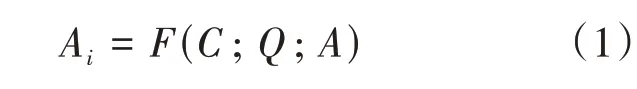
2.2 模型架构
基于RoBERTa 预训练语言模型,提出的推理阅读理解模型架构如图1 所示,主要由输入层、嵌入层、编码层、分类层以及答案选择层组成。模型将给定一组样本输入下编码层得到的高维特征向量与分类层输出的答案向量进行残差连接[19]以解决训练过程中出现的梯度消失和梯度爆炸问题;模拟人类在做逻辑推理类题目时会在做出初步推理判断后再次比对候选答案,以给出最终的答案选择的过程,模型在答案选择层中融合了候选答案输入下的编码信息与经过分类层输出的答案信息;使用滑动窗口方法,设置不同的窗口大小和步长值,将目标数据集中所有样本的上下文切分成部分重叠的长度相同的不同段,与问题和候选答案一起送入到模型的输入层当中,以解决模型不能吸收完整的样本内容导致答案预测效果不佳的问题。
(1)输入层。模型的输入层通过组织样本的表达形式以满足模型的输入要求。记给定上下文分词后的单词序列为C(c1,c2,…,cn),n为上下文长度; 给定问题分词后的单词序列为Q(q1,q2,…,qm),m为问题长度;给定候选答案集A(Ai∈A)中第i个答案项分词后的单词序列为Ai=(ai1,ai2,…,aik),长度为k。分别使用和 作为输入的起始标志和分割标志或结束标志。给定数据集中的任一样本,模型的输入层包含两个独立的模块。如式(2)所示,模块一将样本中的部分上下文、问题和一个候选答案连接成一个长句子T1,通过和标志分隔开来,其中,部分上下文取自样本中上下文经过滑动窗口方法得到的不同块。模块二的输入则仅包含候选答案信息,两端添加起始标志和结束标志,见式(3)。
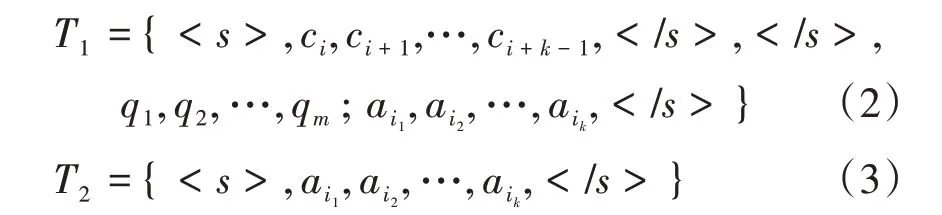
(2)嵌入层。嵌入层的作用是将自然语言转换为模型可以理解的词嵌入向量以便进行后续的编码,使用RoBERTa 语言模型中的分词器将输入层中的每一个单词都映射到一个高维空间当中,以获得该单词唯一的向量表示。图2 展示了输入层文本T1经由嵌入层得到的最终特征向量EA={E1,E2,…,EL}。其中,EA∈RL×d,L表示向量的长度,该向量由对应的词嵌入向量、句子嵌入向量以及位置嵌入向量的级联组成。同理可得输入层文本T2经由嵌入层得到的最终特征向量EB。
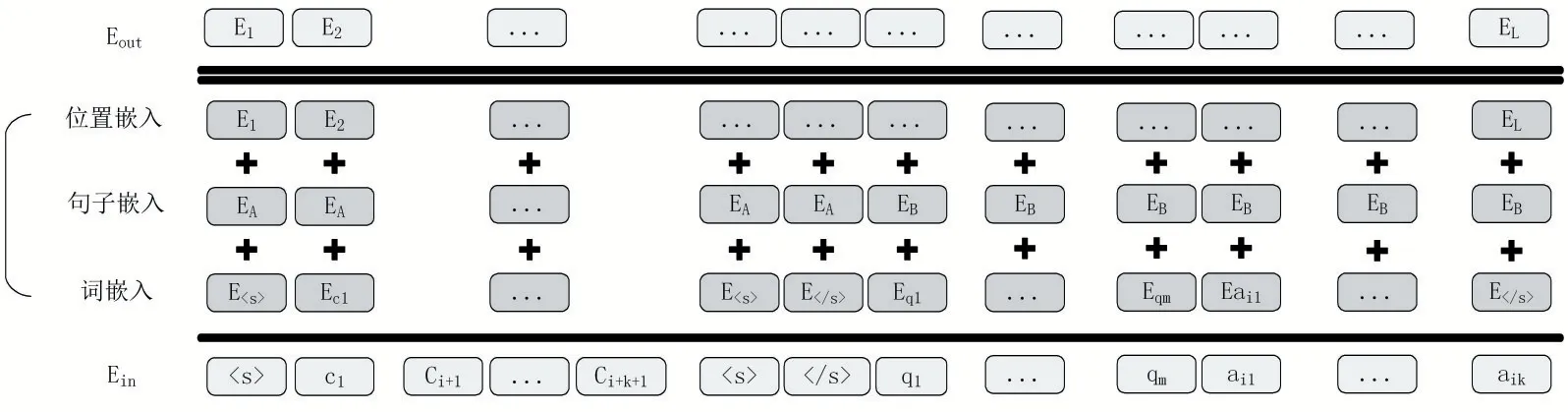
图2 T1输入下嵌入层的最终向量表示
(3)编码层。编码层利用RoBERTa-large 模型中的Transformer 结构[20],对经嵌入层得到的嵌入向量E={}E1,E2,…,EL进行深层次编码,且只使用该Transformer 结构的编码器模块。该编码器模块由N个相同的编码器组成,每个编码器都由一个多头自注意力机制和一个全连接前向反馈神经网络组成,除最后一个编码器外,每个编码器的输出作为下一个编码器的输入。RoBERTalarge模型共有24层Transformer编码器,每个编码器输出对应着嵌入层输入向量的不同特征表达,且各个编码器的周围都有一个“残差连接”[19]以及一个“层归一化”机制[21]。如式(4)和式(5),将各个编码器输出向量的加权求和作为编码层的输出。其中,En∈Rd为编码层的最终输出,El∈Rd(l= 2,3,…,N)为每个编码器的输出向量,E1为第一个编码器的初始输入向量,该输入向量来自于嵌入层的输出。d表示向量的维度大小,l为当前编码器的序号,N为编码器的数量,Wl∈Rd为当前编码器的权重参数。RELU 表示激活函数,计算公式见式(6)。LayerNorm[21]和Multihead[5]分别表示“层归一化”和“多头自注意力机制”。
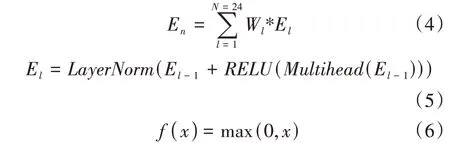

(5)答案选择层。如公式(8),答案选择层将分类层输出的答案概率向量与编码层的输出向量进行残差连接,再经过Softmax“归一化”函数后输出给定样本的正确答案Answer。W1和W2是权重参数,W1,W2∈Rd+1,d表示向量的维度,“⊕”表示残差连接。模型训练时的损失函数如式(9),N表示候选答案集的大小,模型的训练目标就是最小化损失函数Loss的值。

3 实验及分析
3.1 实验数据
提出的模型首先在MCTest、MCScript、Open-BookQA 和Race 上进行充分的微调,再在目标数据集LogiQA 和源数据集Reclor 上进行多任务学习。数据集的统计信息见表2,由于OpenBookQA数据集只有问题和候选答案项,故该数据集下的平均上下文长度置空。LogiQA 数据集共包含8678个问题。
模型的表现使用准确度作为评估指标,计算公式见公式(9),N+和N分别表示模型预测正确的题目数量和总的题目数量。

3.2 实验细节
模型训练时,先固定好一个随机种子,再对多种不同的超参数组合进行了多次实验,并记录下在目标数据集的开发集上的表现,最佳表现对应的超参数组合见表3,其中,max_grad_norm 用来约束参数的梯度值,防止训练过程中出现梯度爆炸问题。max_input_size 规定了模型所能接收的最大输入文本长度,超过该长度的文本内容会被截断。使用的实验平台是Windows 10 家庭中文版,处理器型号为Intel(R)Core(TM)i7-9700K CPU @ 3.60 GHz 3.60 GHz,显卡为NVIDIA Ge-Force RTX 3060,显存容量为12 GB,深度学习框架选择Pytorch 1.8。
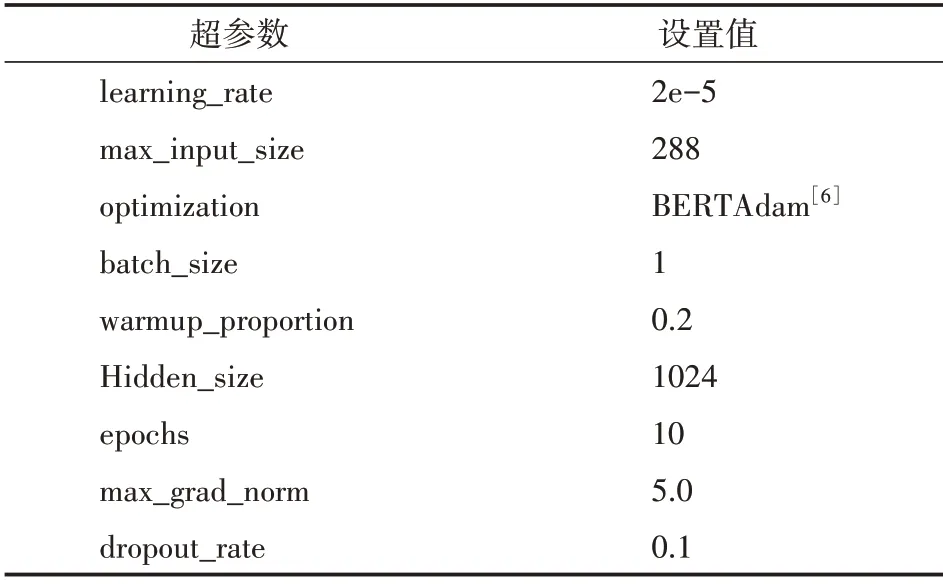
表3 超参数设置
3.3 实验结果及分析
基于BERT 和RoBERTa 预训练语言模型重新实现了LogiQA 数据集原始论文中使用的预训练方法。实验结果如表4 所示,表头中的开发集上的准确度选项计算公式见公式(9)。经过细致的参数调优,重新实现的方法相比于原论文发布的基于预训练技术的最佳表现,在目标数据集LogiQA的开发集上的准确度分别提高了约4%和5%,且RoBERTa 模型相比于BERT 模型在开发集上的推理效果更佳,准确度达到了40%,后续的实验均基于RoBERTa模型。

表4 LogiQA原论文发布的最佳表现与本文复现后的表现
受限于机器显存容量的不足,模型可接受最大输入文本长度是288,考虑使用滑动窗口方法,通过选取不同的窗口大小值和步长值,对所有样本中的上下文切分成同一长度的不同文本段,以提升模型在目标任务上的推理效果。基于Ro-BERTa 模型实验了不同输入组合下,模型在目标数据集的开发集中的表现,并单独实验了在给定上下文、问题以及候选答案集下,不同窗口大小和步长值对模型表现的提升效果,实验结果见表5。结果表明目标数据集中上下文、问题以及候选答案项三者之间的逻辑交互与内在联系是真实存在且至关重要的。后续的实验将固定滑动窗口大小和步长值为288和50。
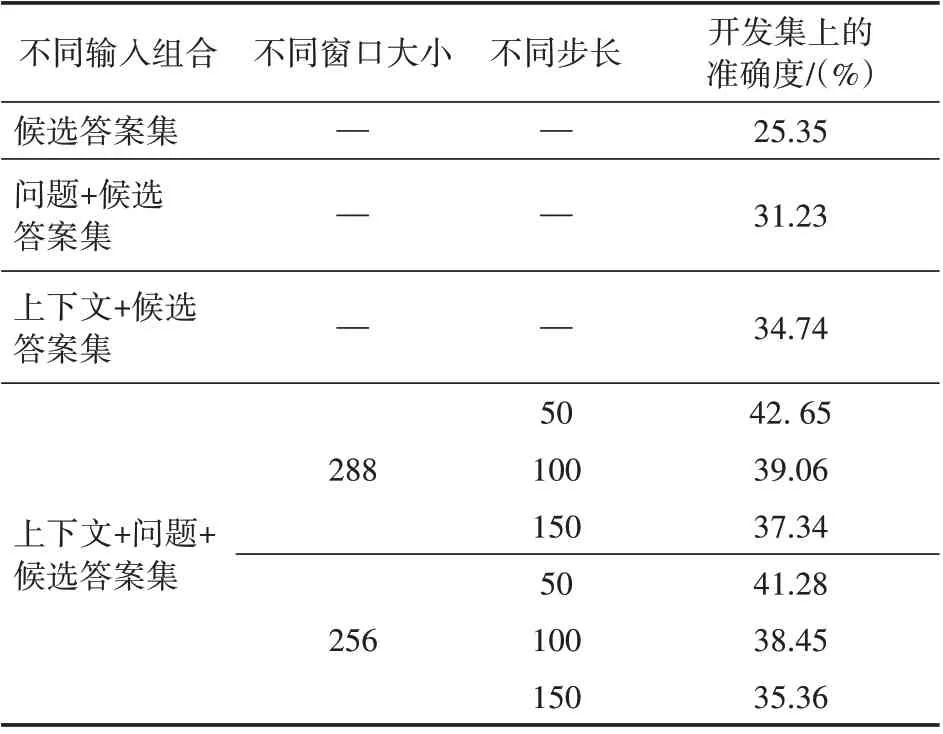
表5 不同输入组合和窗口大小下,RoBERTa模型的表现
在复现了目标数据集原论文中使用的预训练方法的基础上,提出的模型在目标任务上的分解消融实验见表6。

表6 模型的在目标数据集上的最终表现与分解消融实验
表格的最后两行取自原论文中发布的迁移学习方法的结果,RoBERTaRACE——>LogiQA和Ro-BERTaCOSMOS——>LogiQA分别表示将模型先在Race 数据集或者COSMOS 数据集[22]上进行训练,再在目标数据集上微调,而COSMOS 是基于常识推理的多项选择式阅读理解数据集。段落选择层对于模型的最终表现提升最大,提高了约7%左右,这说明引入的问题编码信息有利于模型的最终推理;使用Reclor 作为源数据集与目标数据集LogiQA 进行多任务学习的方法的效果略高于迁移学习方法,达到了44.74%的准确度。最终模型在目标数据集的开发集上的最佳表现达到了56.38%的准确度,相比于原论文中发布的最佳表现提升了约54.72%,证明了方法的有效性。
4 结语
针对当前最新的机器阅读理解模型在推理阅读理解数据集上普遍表现不佳的问题,在预训练语言模型的基础上,提出了基于迁移学习和预训练技术的推理阅读理解模型,使用滑动窗口方法解决了模型无法一次性吸收过长的输入文本的问题,段落选择器可以帮助模型在进行答案选择时做出正确的逻辑判断。模型在需要逻辑推理能力的阅读理解数据集LogiQA 上取得了当前的最佳效果,这表明模型具备了一定的逻辑推理能力。未来的研究工作将进一步考虑在模型内部研究上下文、问题与答案项之间的逻辑交互,并将交互信息编码进模型的段落选择层中,进一步提升模型的逻辑推理能力。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
民族文汇(2022年19期)2022-05-25
数学大王·低年级(2019年2期)2019-01-23
数学大王·低年级(2018年8期)2018-09-03
科技知识动漫(2017年8期)2017-08-09
科技与创新(2017年5期)2017-03-28
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
中学数学研究(2008年3期)2008-12-09
电子设计应用(2004年6期)2004-07-27
