
基于深度学习的糖尿病眼底病变分级方法研究
2022-01-09 05:20姚凯学胡加德
计算机技术与发展 2021年12期
蒋 鹏,何 勇,姚凯学, 胡加德
(1.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;2.贵州科海新技术发展有限公司,贵州 贵阳 550002)
0 引 言
糖尿病会引起视网膜病变,在几乎所有的Ⅰ型糖尿病人和超过60%的Ⅱ型糖尿病人都会发生视网膜病变,对人体视力影响极大,糖尿病视网膜病变属于目前造成失明和视力受损的主要原因之一[1]。但处于糖尿病视网膜病变早期的患者,其视力或完全不受影响,患者无明显感受,然而目前没有治疗视网膜病变晚期的良好方案,需要在病变早期进行预防[2-3],在此前提下,对眼底图像病变程度的识别十分重要。然而除糖尿病外,动脉硬化、高血压、肾炎、妊娠、白血病、贫血等都会引起眼底变化[4],传统的人工识别需要具备专业、丰富的医学经验。因此,一种能有效、客观地观测和筛查糖尿病性视网膜病变的方法是十分有意义的。
目前,糖尿病视网膜眼底图像分级面临特征差异小,特征位置分布不均,干扰因素多等难题。深度学习可以有效提取图像隐含特征,学习识别特征层次结构,在医学图像领域内有广泛的应用[5]。因此,该文采用深度学习相关算法基于复合缩放模型建立神经网络,使用预处理后的眼底图像,训练神经网络模型进行糖尿病性视网膜病变程度分级,其结果可以作为诊断参考,同时将来还可以用来检测其他疾病,比如青光眼和黄斑变性。
1 数据集介绍与数据分析
该文使用了公开可用的Kaggle数据集。Kaggle数据集由免费的视网膜病变筛查平台EyePACS提供。该数据集中有5 590幅高分辨率彩色左右双眼的眼底图像,由专业的临床医生对每张图片上的糖尿病视网膜病变进行了0到4的评分,分别对应没有、一般、中度、严重、增生五种糖尿病视网膜病变程度。该文将数据集样本依上对其标注分为两部分,其中训练集3 662张图片,测试集1 928张图片,再由训练集分出验证集,其占比为0.2。
从整体数据集上分析,由数据集中提取每张图像的分级标签进行统计,可以发现该数据集的糖尿病视网膜病变等级分布十分不均,其中正常的眼底图像(等级0)的占比达到49.3%,属于有偏数据集,如图1所示。
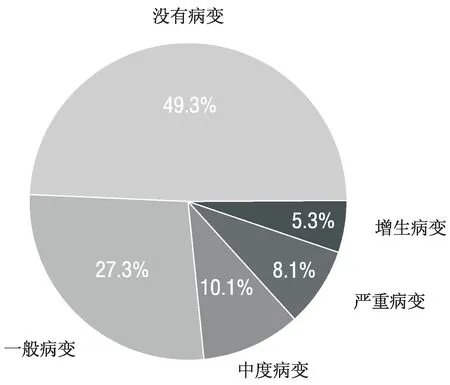
图1 数据集中不同视网膜病变程度分布饼状图
眼底主要由玻璃体、视网膜、视神经、黄斑区等结构构成。当眼底发生病变时,上述相应的结构及其颜色都会发生相应的改变[6],在眼底图像中会显现血噬菌体、硬性渗出物、小动脉瘤、出血、水肿和棉絮斑点等不同程度的症状。不同的病变等级,变性的范围或大或小,同时,伴随视神经的萎缩,其颜色也会有所不同[7-8]。
如图2所示,经由上述分析中总结得出,主要的图像特征有:渗出物、变性面积、视神经颜色。但同时图像特征的具体的结构和位置信息很难依靠经验总结[9-10],图像潜在的其他特征有待挖掘。

图2 数据集中严重的视网膜病变图样
2 数据预处理
数据预处理对于训练神经网络十分重要,对最终 模型的影响毋庸置疑。经观察分析,可发现数据集中的眼底图像由于采集图像时环境条件所限,图像数据有两个可以改进的地方。第一,图像中出现的黑边,这属于干扰信息,可以进行裁剪,消除其影响。第二,通过对比不同的照片,可以发现眼底图像有不同的亮度,有些图像非常昏暗,从而导致图像中主要特征与周围的差异不明显,需要减少光照的影响。以上数据集暴露的问题,主要来源于硬件设备,问题同时存在于实际之中。为克服以上的影响,该文研究了以下的数据预处理方法,流程如图3所示。

图3 数据预处理流程
2.1 图像预处理
针对图像中消除“黑边”的影响问题[11],该文采取裁剪的方法。首先取图像中心圆做掩模,保护眼球的有效区域,将图像转为灰度图,设定好灰度阈值,分别选三通道阈值以下区域进行裁剪,最后将三通道堆叠合成彩色图像,从而消除图像中的“黑边”。整个过程如图4所示。
在千岛湖“保水渔业”产业发展大会上,一系列重要举措被提上日程:“中国大水面生态净水研究中心”正式落户千岛湖,针对千岛湖地区特点和产业发展需求,开展共性关键技术的研发与示范推广;“中林两山学院”挂牌成立,为培训和普及千岛湖“保水渔业”提供渠道;与上海海洋大学、浙江海洋大学、浙江工业大学等高校合作,培养更多的千岛湖渔业产业人才。

图4 视网膜眼底图像裁剪过程
2.2 特征增强
针对消除图像中光照的影响,提升特征的对比度的问题,该文利用通过高斯滤波器后的眼底图像和原图像进行图像混合的方法,整个过程如图5所示。

图5 基于高斯滤波器的图像混合
从图5所示,可以明显地观察到一些图像特征如:斑点、渗出物、絮状物和血管等。说明在使用了该方法后,图像中特征和特征结构更加清晰,同时削弱了图像中光照的影响,保留了视神经的颜色这一特征。
2.3 数据增强及归一化
本次实验所用的Kaggle数据集样本图像有限且自身内部各病变程度等级的图像分布差异大,且图像分辨率大小不一,普遍很高。在此情况下,该文首先对准备输入神经网络的图像进行归一化,经实验调整图像分辨率为固定的380*380,采用该尺寸能有效地提升模型的收敛速度,且尽量使原图像特征得以保留。同时,采用对图像依概率进行水平、左右翻转、旋转等数据增强方法来按比例地增加训练样本,以达到各病变等级分布均匀的目的,形成无偏数据集。该方法起到了提高神经网络模型的泛化能力,避免模型出现过拟合情况的作用。
3 基于复合模型缩放算法的分级模型
3.1 迁移学习
在现实生活中,数据集样本的收集受隐私等条件问题影响,导致可用于实验的病变样本很少且样本分级不均。同时,对数据样本的识别标记工作需要专业人员来进行,导致已经标记的样本更少。由于上述原因,使用神经网络模型解决糖尿病视网膜病变分级问题前,对神经网络的训练非常容易导致模型过拟合,不能达到理想的分级效果。通常,面对已标记医疗图像资源少这一领域难题,相关专家使用迁移学习的方法来解决。该文采用在Imagenet项目上已经训练好的Efficient-B4模型预训练参数,再通过Kaggle数据集进行二次训练,这样使得模型有更好的初始化参数,显著提高模型训练效率,最终模型的泛化能力也会更好。
3.2 复合模型缩放算法
复合模型缩放算法[12]的核心思想是神经网模型的三大主要指标(深度、宽度、分辨率)并不是孤立的,其中有必然的联系。通过综合考虑三者之间的平衡可以使得神经网络模型有更好的表现,能让现有神经网络模型在不牺牲参数量和计算量的情况下,有效提升模型的准确率。
(1)
Accuracy(N(d,w,r))
(2)
(3)
Memory(N)≤targetmemery
(4)
(5)
一个卷积神经网络可由式(1)表达,其中X为输入张量,F为卷积操作,而其算法的优化问题可表达为式(2)~式(5),在现有基础模型的约束条件下,平衡基线模型的深度、宽度、分辨率三项指标,提升最佳准确率、控制参数量和计算量,达到优化模型的目的。
d=αφ
(6)
w=βφ
(7)
r=γφ
(8)
α·β2·γ2≈2
(9)
α≥1,β≥1,γ≥1
(10)
在复合模型缩放算法中,整个算法在约束条件式(10)下,通过使用复合系数φ(如式(6)~式(9))对模型统一进行缩放,其中d为神经网络的深度,w为神经网络的宽度,r为分辨率。
复合模型缩放算法同时可以应用于其他现有的分类模型中,其泛化效果十分不错,能够有效提高模型的效率。模型的缩放效率十分依赖于基线模型,该文采用谷歌团队开发的基线模型EfficientNet-B4,可分为9个stage,而每个stage由多个MBConvBlock组成,整个神经网络模型由1个Stem、32个MBConvBlock和最后连接层堆叠而成,其模型结构如表1所示。

表1 EfficientNet-B4神经网络模型结构
其中关键模块为MBConvBlock,又可以分为多个Block,Block的通用结构如图6所示。

图6 Block通用结构
其Block模块结构借鉴了残差结构和反向残差结构,同时引用了注意力机制。首先利用卷积(conv2d )提升channel,再进行深度可分离卷积(depthwiseconn2d)操作,之后通过卷积(conv2d)降低channel,同时在该模块后增加了一个对通道的注意力机制,最后利用卷积(conv2d)降维后加上一个残差结构。其中整个过程使用swish激活函数。
4 结果与分析
4.1 实验设置
该文在Pytorch深度学习框架下进行实验,本次实验所采用的优化策略及超参数见表2。为了尽量保留图像的细节特征,综合Efficient-B4 模型的最佳输入分辨率,该文采用380*380图像输入。

表2 神经网络模型配置
4.2 评价标准
采用平均准确率Accuracy曲线来观察神经网络的过拟合情况,提前停止神经网络的训练。其计算方法如式(11)、式(12)所示,首先计算每个分级的准确率,再计算整体平均准确率。同时采用Kappa系数(式(13))来评估训练好的神经网络。
(11)
(12)
(13)
其中平均准确率Accuracy,能直接反映对病变程度正确分级的比率,但面对本数据集样本数量不均衡的情况,需要采用Kappa系数检验其一致性问题,当Kappa系数大于0.81时,说明其一致性强。
4.3 实验结果分析
为验证该文使用的方法和其他常规方法的分级效果,进行了两次模型训练,训练过程如图7所示。在相同条件下,一次使用了未预处理眼底图像对ResNet模型进行训练,另外使用了该文所研究的预处理方法后的眼底图像来训练EfficientNet-B4模型。两者就训练后进行结果对比。


图7 ResNet50与EfficientNet-B4的Accuracy曲线
利用该文所研究的方法对糖尿病视网膜病变程度等级分级的最后平均准确率为92.46%,Kappa系数0.88。结果表明,相对于采用传统的K近邻算法、支持向量机(SVM)的平均准确率更高[13]。
同时,该文对比了不同卷积神经网络模型对糖尿病视网膜病变检测的准确率,如LeNet、AlexNet和CompactNet神经网络模型[14-15],对比结果如表3所示。

表3 神经网络模型对比
由表3可知,虽然各个神经网络模型所用数据样本来源一致,然而最终模型得到的准确率却大相径庭,说明所用的预处理方法和采用的神经网络模型对准确率的影响巨大。相对前人采用的前三个模型,ResNet50网络模型引入残差模块,解决了由于模型网络过深带来的梯度弥散问题,但是没有结合网络深度、宽度、分辨率三者考虑。而该文采用了复合模型缩放算法,复合缩放后的模型更加倾向关注于具有更多对象细节的相关位置,对于视网膜病变区域及特征捕捉更好,最终结果表明,该方法平均准确率更高、泛化能力更好。
5 结束语
该文充分考虑了数据集特点(样本数少、样本标签分布不均、样本规格不统一)和数据特征(特征的种类、特征的分布、特征结构),采用了图像混合的预处理方法,利用了基于复合模型缩放算法的神经网络模型,实现视网膜病变等级分类准确率达92%,Kappa系数0.88。实验结果表明该方法对视网膜病变等级分级效果提升显著,可对糖尿病视网膜病变的诊断提供科学依据,同时对研究其他眼底病变图像也有一定参考价值。
后续工作将考虑不同级别间病变特征差异小的因素,导致少数处于分级界限边缘的样本分级时有偏差,考虑将目前多分类问题转化为多标签多分类问题。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
老友(2022年4期)2022-05-18
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农村百事通(2021年12期)2021-01-17
健康体检与管理(2021年10期)2021-01-03
保健与生活(2019年12期)2019-07-31
投资者报(2017年9期)2017-03-14
中学生英语·阅读与写作(2014年11期)2015-03-11
