
基于数据挖掘的电商客户流失预测建模方法研究
2022-01-08 08:58吴涛
安徽水利水电职业技术学院学报 2021年1期
吴 涛
(安徽工业职业技术学院,安徽 铜陵 244000)
近年来电商市场竞争异常激烈,电子商务的特殊性和竞争的激烈性,导致其客户流失率高达90%以上,客户流失是电子商务应用所面临的棘手问题。因此如何有效挽留客户,成为企业急待解决的问题。传统的流失客户挽留方法是在客户流失之后才采取措施挽救,这是因为在客户流失前期没有快速、准确地捕捉客户即将流失的“信号”,采取相应地措施。在客户流失之后再做挽留,其维护成本高并且成功率低。近些年,数据挖掘技术发展迅速,该技术可自动从大量的数据样本中寻找数据间隐藏的特殊关系。面对传统客户挽留方法的不足,数据挖掘技术提供了有效的解决方案,它可以对历史海量数据进行学习,建立客户流失预测模型,动态地捕捉客户即将流失的信号,使得电商平台在客户流失之前提前介入,采取针对性、个性化的营销策略,从而有效地挽留客户。本文运用数据挖掘技术中的决策树、支持向量机算法分别对电商客户流失进行建模预测,旨在寻找预测精度高的模型。
1 数据挖掘方法
1.1 决策树
决策树算法原理简单、计算量小、泛化能力强,可有效的找出变量间的相互关系,已被广泛应用于数据挖掘技术中。但是决策树算法具有两个缺点。一是对于各类别样本数量不一致的数据,其稳定性与抗震荡性较差,决策树中的信息增益结果偏向于具有更多数值的特征。二是决策树内部节点的判别具有明确性,会带来一定的误差。
决策树构造分2步进行:第1步,决策树的生成,是由训练样本集生成决策树的过程;第2步,决策树的剪枝,是对上一阶段生成的决策树进行检验、校正和修正的过程。
2.2 支持向量机
支持向量机(Support Vector Machine,SVM)是一种对数据进行二分类的广义线性分类器,它在解决小样本、非线性、高维度问题中具有绝对的优势。
在二分类问题中,SVM通过在n维空间中找到一个能够实现二分类的最优超平面H(满足wT·x+b=0),并且能够使得两类中距离最近的点间隔尽量大。其中,H0(满足wT·x+b=1)和H1(满足wT·x+b=-1)与H平行,且分别经过两类样本中距离H最近的样本,则对于任意点xi满足式(1)的条件
(1)

s.t.yi(wT·xi+b)≥1,i=1,2,…,n
(2)
将Lagrange乘子法引入公式(2)中,可得:

(3)
其中,ai为拉格朗日乘子。求得最优w和b后,可得决策函数为:
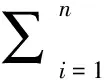
(4)
若解决非线性分类问题,可通过内积核函数,将数据映射到高维空间,进而在高维空间中将非线性问题转化为线性问题。
2 样本数据选取
客户流失的特征体现在如下3个方面:消费总频率低,消费总金额少,最后购买日期与当前日期相距的天数长,故本文构造的客户流失特征分别为消费总频率F( Frequency),消费总金额M( monetary) ,最后购买日期与当前日期相距的天数R( Recency)。本文电子商务客户流失分析选用2018年某电商平台客户交易数据库中的2000个订单数据,其中非流失客户有580个,流失客户有1420个,并将非流失客户量化为0,流失客户量化为1。
3 模型建立与评估
3.1 决策树预测模型建立
决策树预测模型建立的具体步骤为:
(1)导入数据。数据文件每组数据分4个字段:前3个字段分别为电子商务客户的消费总频率F( Frequency),消费总金额M( monetary) ,最后购买日期与当前日期相距的天数R( Recency)变量,第4个字段为客户流失状态。共2000组数据,为不失一般性,随机选取1600组数据作为训练集,剩余400组数据作为测试集。
(2)创建决策树分类器。利用MATLAB自带函数ClassificationTree.fit,即可基于训练数据创建一个决策分类器。
(3)仿真测试。利用MATLAB自带工具箱函数predict,即可对测试集数据进行仿真实验。
(4)找出叶子节点所含的最小样本数。如图1所示,本文将叶子节点所包含的最小样本数(minleaf)设置为10,此时交叉验证误差最小。
(5)剪枝。通过剪枝操作,使决策树分类器更加简化,同时交叉验证误差不变。根据训练数据创建剪枝后的决策树分类器,如图2所示。

图1 叶子节点含有的最小样本数对决策树性能的影响

图2 剪枝后的决策树分类器
3.2 支持向量机预测模型建立
将电子商务客户的消费总频率F(Frequency),消费总金额M(monetary) ,最后购买日期与当前日期相距的天数R(Recency)3个变量作为输入特征值,客户流失状态作为输出特征值。随机选择1600组数据作为SVM模型的训练样本,剩余400组数据作为测试样本。具体步骤为:
(1)归一化处理。用MATLAB中的mapminmax函数来对2000组样本数据进行归一化处理,防止特征值范围过大或过小,影响模型的精确度。其中归一化的范围为[0,1]。
(2)选择SVM的类型选为C-SVC,核函数选取精度较高的RBF函数。
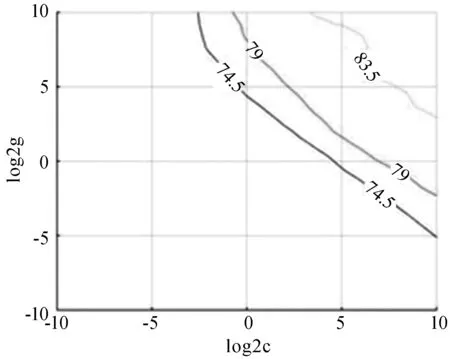
(3)惩罚参数C与核函数参数g的选取两者。对预测精度的影响较大,本文采用K-fold交叉验证(K-fold Cross Validation,K-CV)的参数优化方法选择最优参数,如图3、图4所示。
(4)将最佳参数(C,g)和训练样本代入SVC中,并得到精度较高的SVC模型。SVC模型预测结果,如图5所示。
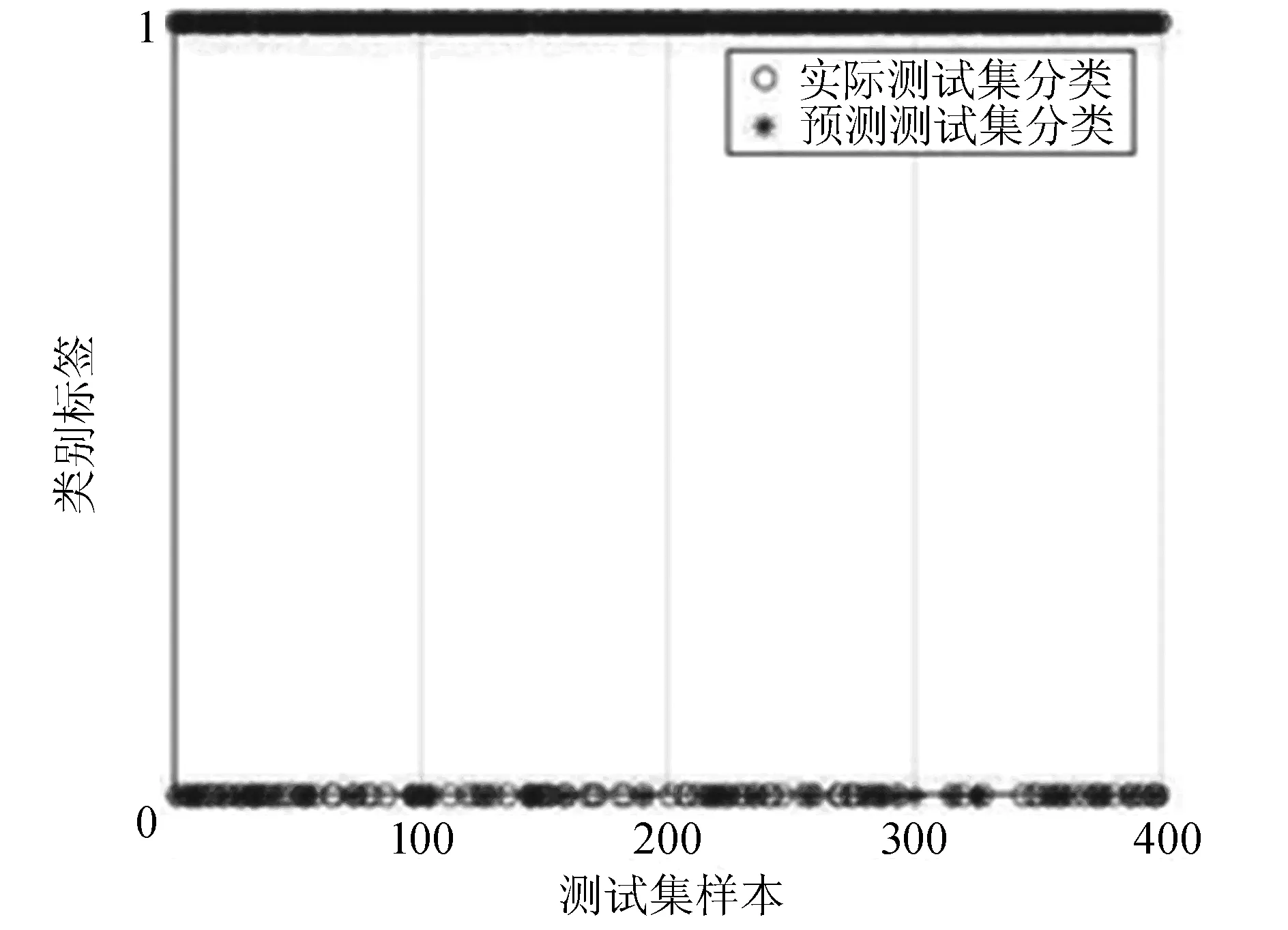
图5 SVC模型预测结果
3.3 模型的评估
决策树、支持向量机预测结果如表1所列。对表1预测结果进行分析,得到的结论如下:①相较于决策树分类模型,支持向量机模型分类准确率更高。这主要是由于本文样本数据量较少,支持向量机在解决小样本问题中具有绝对的优势。②决策树分类精度较低,可能是因为本文数据样本中各类别样本数量不均衡,非流失客户数量远远少于流失客户数量,决策树中信息增益结果偏向于具有更多数值的特征,故决策树用在电子商务客户流失预测中还有待优化。

表1 模型对预测样本预测精度比较
4 结束语
本文的研究结果可为电商平台提供决策支持,平台可以根据预测结果采取相应措施挽留客户,有效减少客户的流失,具有较强的实用性。随着电商网络的发展,电商行业产生的客户信息数据进一步增多,未来可考虑使用更深层次的数据挖掘技术处理海量数据。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
信息通信技术(2015年6期)2015-12-26
郑州大学学报(医学版)(2015年1期)2015-02-27
航天返回与遥感(2014年5期)2014-07-31
