
基于分布式计算框架的机器学习系统分析
2022-01-07 12:52胡常礼邵剑飞
电视技术 2021年11期
胡常礼,邵剑飞
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引言
大数据技术的不断发展,促进了大数据在机器学习领域的使用。基于大数据技术的机器学习能够精准实现训练机器学习的能力,对机器学习的研究是当前人工智能系统重要的研究方向。在机器学习的基础上对大数据进行智能分析处理,可以得到有价值的信息[1]。使用数据规模越大,机器从数据学习到的有用信息就越多,学习的效果就越好,就不容易出现欠拟合和过拟合问题。创建分布式机器学习系统,涉及大数据处理和机器学习两方面,多种不同因素的影响提高了系统设计的复杂性和稳定性,为设计人员开发系统带来了挑战。因此,在机器学习系统的设计过程中,设计人员要重视分布式与并行化大数据技术,从而在可接受的时间内实现计算[2]。
1 机器学习模型的设计概念
1.1 Spark 方法
Spark 是使用scala 实现的基于内存计算的大数据开源集群计算环境。Spark 设计方法具有以下特点:其一,计算方式比较迅速,通过有向无环图支持循环数据流,在内存存储中间数据,运行效率更快;其二,通用性较强,具有丰富的组件;其三,使用比较方便,可实现多开发语言的兼容。Spark 设计工作相关流程如图1 所示。

图1 Spark 设计工作流程
Spark 工作流程中,利用分布式数据集RDD 的可分区特性将数据集进行划分,并通过RDD 之间的关联形成DAG 有向无环图。有向无环图DAG 被划分成多个stage,每个stage 含有多个任务,而Driver设置好任务调度组件,将任务分配到Workers。Spark 通过模型参数在driver 节点中存储,并且与workers进行信息交互,通过不断迭代更新相关参数。在大模型的数据处理过程中,由于模型的相关参数无法完全存储在driver 里,使得RDD 数据存储成为问题。将参数以分布式方式存储数据集RDD 里,通过并行计算可以使参数同时更新[3]。
1.2 机器学习模型
机器学习模型指的是利用人工智能技术让计算机能够完成类似人的主动学习,智能地完成相关计算,提高计算速度。计算机对数据进行分析处理,并从分析处理后相关有价值的信息中进行学习,在学习中形成自己的知识体系。机器学习从学习环境中获取原始信息即数据,通过从原始信息中学习构建学习元,然后在学习中不断更新知识库,通过形成的知识体系指导和纠正学习。本文设计的机器学习模型结构如图2 所示。
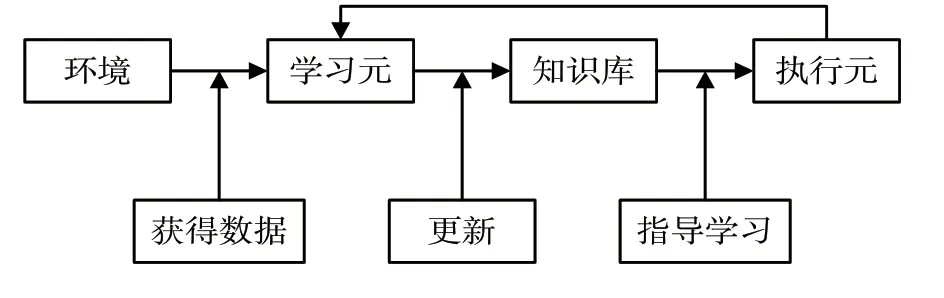
图2 机器学习模型的结构
2 基于分布式计算的机器学习系统的设计
2.1 系统总体框架
机器学习系统设计为R 语言中包(Package)的方式,通过上层用户加载此包实现系统提供矩阵运算的功能。图3 为机器学习系统的矩阵编程模型统一接口,包括矩阵API 接口设计与运行模式。对于此运行模式,用户在R 语言编程环境中采用交互式运行和批量解释运行方式使用系统[4]。
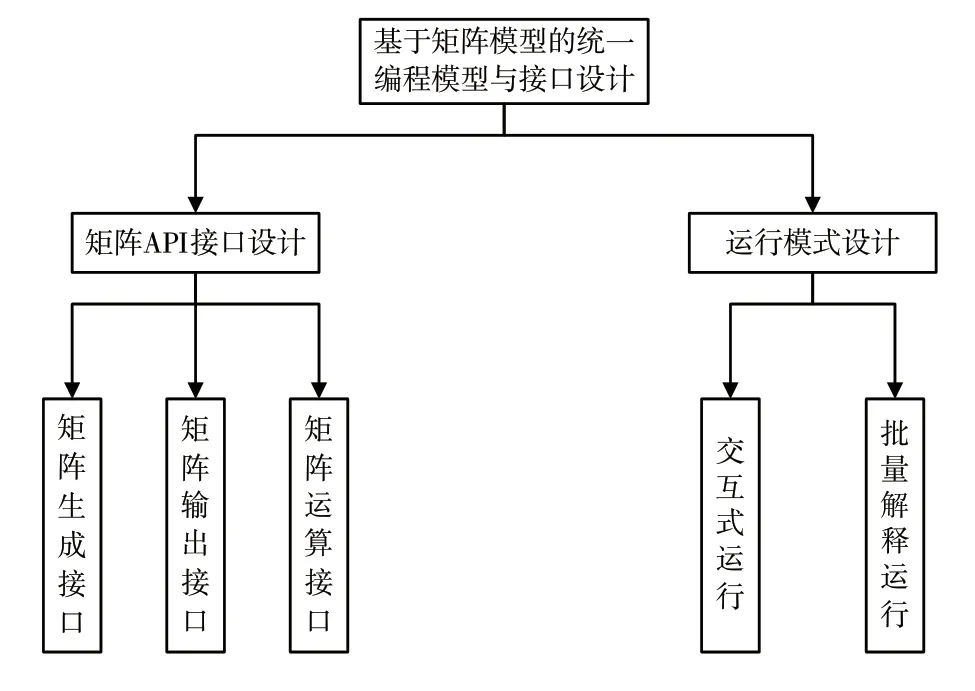
图3 机器学习系统的矩阵编程模型统一接口
针对矩阵API 接口设计,为了区分矩阵运算编程接口的性质,实现底层计算平台接口,将API 接口划分为3 个模块。
(1)矩阵生成接口模块。实现生成矩阵接口,比如内存生成矩阵、分布式文件生成矩阵以及随机初始矩阵。
(2)矩阵输出接口模块。实现矩阵的保存和展示,比如矩阵数据打印和保存在分布式文件系统中。
(3)矩阵运算接口模块。包括矩阵操作接口,比如用户自定义函数执行、四则运算等。
为了使上层程序在多种底层计算机平台中执行,系统要对所有计算平台使用矩阵库实现以上矩阵模型接口,并且通过用户矩阵接口封装多种底层计算平台矩阵函数实现[5]。
2.2 网络模型构建
此模型是机器学习和大数据的结合,运用SymboMaxtrix 接口是为了简化矩阵表达式,DAG逻辑优化优化分布式数据集RDD 之间的关系,OctMatrix 使得在不同的平台都可以进行矩阵操作,通过定义Spark、MPI、R 等矩阵库的在不同平台优先级,之后再通过Alluxio 文件系统实现在不同平台矩阵运算[6]。网络模型的结构如图4 所示。
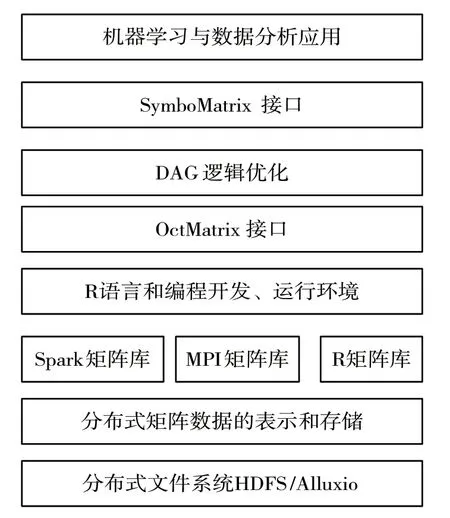
图4 网络模型的结构
2.3 功能设计
2.3.1 用户自定义函数
MPI 的矩阵库iPLAR 是将R 的pbdr 包实现,通过MPI 执行用户自定义R 函数。OctMatrix 是以Spark 为基础实现的分布式矩阵库,能够提供Scala接口,机器学习系统只是利用JVM 反射机制应用,所以用户自定义R函数不能够通过Spark平台执行。R 中用户自定义函数(UDP)通过Spark 执行,利用apply(m,margin,func)函数实现。在apply 函数中,m 为矩阵,func 为用户自定义函数或者R 原生函数。margin 包含c(1,2),指的是使func 在矩阵每个元素中使用。假如m 类型为R,由于func 为R 的函数,能够使func 在矩阵m 中使用。通过R 包的pbdR实现MPI,所以能够使func 直接在矩阵中使用。在矩阵为Spark 类型的时候,JVM 无法对R 函数进行识别。
图5 为apply 调用实现结构,在Spark 集群中的slave 中运行Rserve 守护进程,此进程能够使java传输数据在R 中操作,在java 中返回结果。利用func 函数和依赖序列化构成数组Array[Byte]传输到Driver 端,之后在Worker 进行广播,每个Worker和本地Rserve 通信,使结果在Worker 中传输,执行apply 函数[7]。

图5 Spark 执行R 函数
2.3.2 跨平台矩阵调用
由于矩阵计算平台包括Spark、MRI、R,所以将矩阵划分为这3 种类型。在矩阵类型转变的过程中,要实现矩阵跨平台调用。跨平台矩阵调用模块结构如图6 所示,利用矩阵读写Alluxio 两个模块。在矩阵写模块中,平台能够写Alluxio 函数;在矩阵读模块中,平台能够读Alluxio 函数。利用矩阵先写到Alluxio 中调用矩阵,之后通过Alluxio 读取矩阵进行实现。
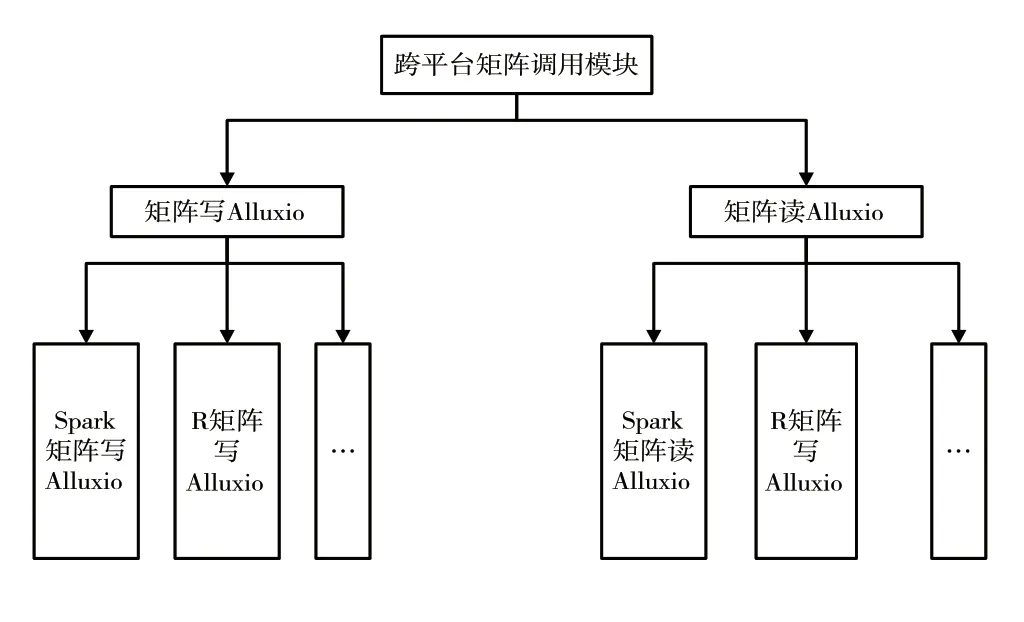
图6 跨平台矩阵调用结构
2.3.3 不同平台矩阵函数的计算
用户在使用OctMatrix 时,不会只是使用同个平台,矩阵操作中的计算平台不同。比如,乘法的两个矩阵包括R 平台和Spark 平台。对于此情况,系统设计统一化处理规则。首先对平台优先级进行定义,Spark >MPI >Hadoop >R。在矩阵操作过程包括多个矩阵时,假如底层计算平台一致,使用此计算平台对矩阵操作进行执行;假如底层计算平台不同,使低优先级计算平台矩阵朝着高优先级转变,之后通过高优先级计算平台对矩阵执行操作。比如A%*%B,流程如图7 所示。
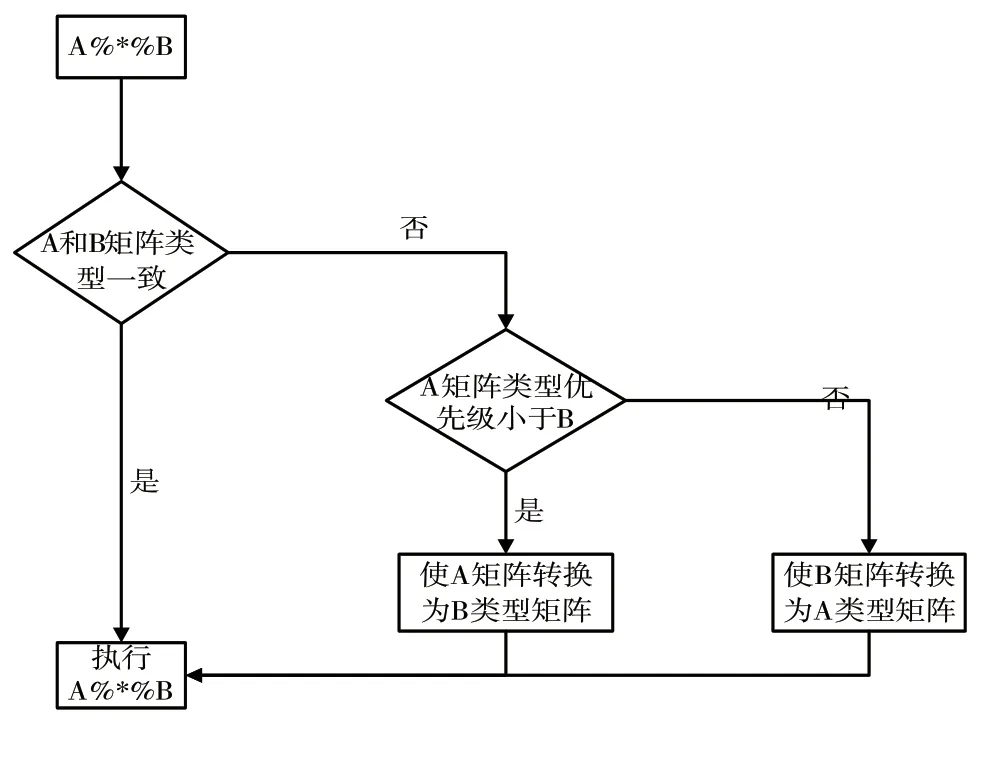
图7 工作流程
3 机器学习系统的评估
3.1 实验环境
本文利用VMware 虚拟软件进行实验,虚拟5台机器,集群配置如表1 所示。

表1 集群配置
3.1 模型评估
此实验基于QJM 中的HM 大数据平台,利用HDFS 和Aookeeper 两大工具,实现对本文中集群配置分布式管理。本文有5 个节点配置,如表1 所示,利用yarn 模型和局域网接入本平台,完成对平台的线管资源分配和分布执行任务。
3.1.1 和数据Partition 的关系
为了对训练中不同模型对训练时间的影响进行评估,使用MovieLens 数据集(1 000 万)进行分区计算实验,分区数和运行时间之间的影响关系如图8 所示。
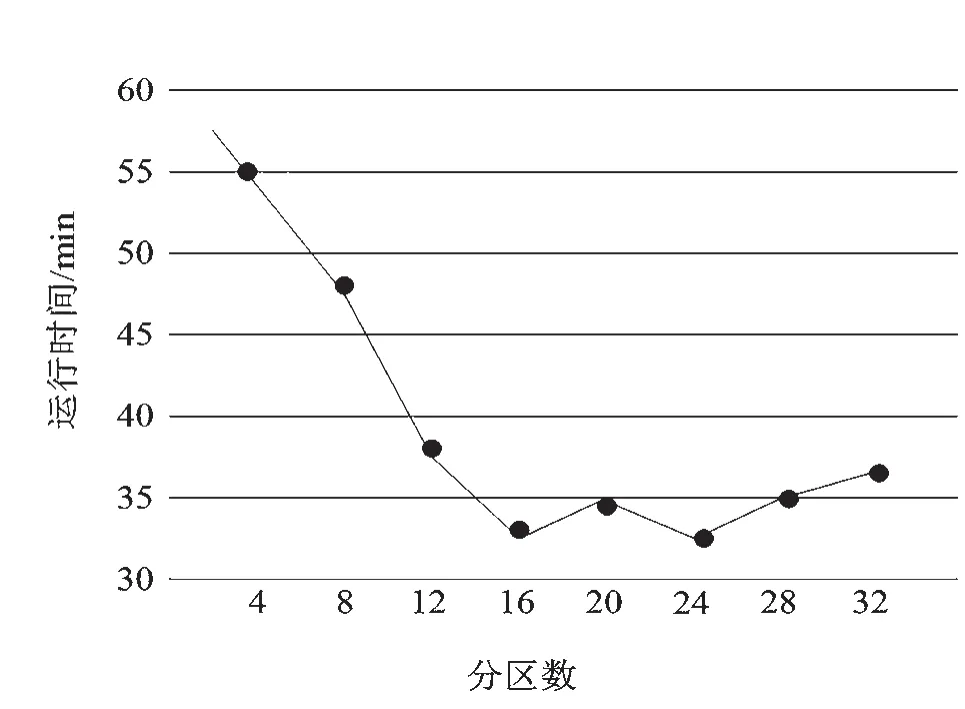
图8 分区数和运行时间
通过图8 可以看出,随着分区数目的增多,对模型训练的运行时间也减少;然后随着分区数的增加,运行时间并没有随着减少,而是在一定程度上增多。这是因为分区使得计算机可以并行执行,运行时间会随着分区数的增多而下降;但是随着分区数的增多,负责传输的通信网络的负担会增加,导致对机器的训练时间增加,因此运行时间没有继续下降反而小幅度上升。
3.1.2 算法运行时间
通过算法在不同节点下的训练效果测试以及执行时间测试展现算法的分布计算的效果,在MovieLens 数据集的m1-100k(1 万~10 万)、m1-1m(100 万)、m1-10m100k(1 000 万)情况下开展实验,最终实验结果如图9 所示。
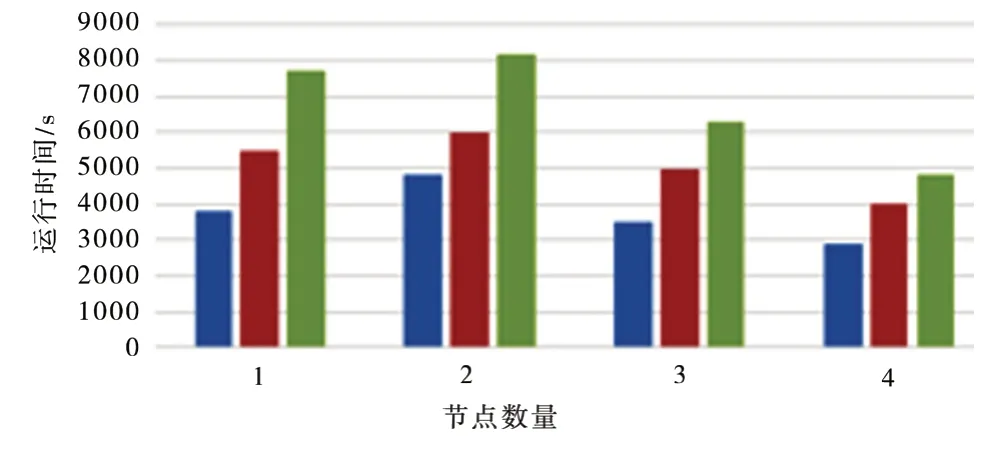
图9 最终实验结果
图9 中Spark 下Kmeans 算法在不同规模的节点数和不同大小的数据规模的运行时间结果对比,发现在数据集在较小规模时使用KMeans 分类训练时间比较少,是因为集群计算要对任务进行初始化,会消耗大量的时间和成本。在数据规模不断增加的过程中,节点规模也会同时增加。另外发现在Spark 下的KMearns 算法下训练执行并行计算有一定程度的优势,主要是因为在Spark 下Kmeans 算法在信息交互和任务调度相关初始化所用时间比较少,使得机器对数据载入学习的时间减少,且Spark下Kmeans 算法能够将数据集均匀分成Data Block块,在Worker 中开展并行计算,降低训练时间。实验结果表明,本文所设计系统的运行时间、训练时间都比较优,并且在数据处理延迟方面表现良好。
4 结语
对分布式计算框架和机器学习模型对不同分区数的学习效率的分析和研究表明,分布式计算对于机器学习有效地处理大数据,对于人工智能的领域研究具有实际意义。本文的仿真实验和对比分析表明,基于分布式计算框架的机器学习系统可以提高训练样本的大小,即增强了机器对大数据集的学习和充分挖掘有用信息的处理能力。机器学习利用大量数据样本实现训练,通过不断的优化融合机器学习和大数据、分布式计算框架,提高两者关联性,实现数据挖掘过程与机器训练。在未来发展中,需要重点研究的内容是以常用机器学习和数据分析算法针对矩阵函数实现更多功能,以应用特性与平台特性提炼更多物理与逻辑的优化方法,针对已有多平台调度优化创建理论、精准的实践模型,使模型误差得到降低。
猜你喜欢
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-29)2022-03-29
环球时报(2022-03-14)2022-03-14
电影(2018年8期)2018-09-21
知识经济·中国直销(2018年7期)2018-07-27
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
雷达与对抗(2015年3期)2015-12-09
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
