
融合上下文信息图卷积的中文短文本分类方法
2022-01-07 12:52胡俊清杨志豪施敬磊
电视技术 2021年11期
胡俊清,杨志豪,施敬磊
(昆明理工大学 信息工程与自动化学院,云南 昆明 650000)
0 引言
短文本通常较短,一般不超过150 个字符。短文本分类广泛应用于电子商务[1]、社交媒体[2]、商品评论等方向,是自然语言处理中最重要的任务之一。随着电子设备的普及和电商平台的崛起,海量用户在网上购物,商品评论文本急剧增加,如何对这些文本进行科学有效的分类管理成为研究热点之一。评论文本的正确分类,可以影响用户的购买行为,同时也对商家和电商平台的营销决策起重要作用。
基于深度学习神经网络方法近年来受到广泛关注,其方法也在不断进步和演化,但是在图结构数据上受到了很大的限制。比如,卷积神经网络(Convolutional Neural Networks,CNN)不能直接处理图结构数据,因为CNN 不能维持平移不变性,而且CNN 的卷积核大小固定,限制了依赖的范围。因此,基于图卷积网络(Graph Convolution Network,GCN)[3]的文本分类方法越发受到研究人员们的重视[4]。虽然GCN 正逐渐成为基于图的文本分类中一种比较好的选择,但总体来说仍然存在一些弊端。
由于GCN 只聚合直接相邻节点的信息,在短文本中忽略了非常有用的词节点表示和词序中的语义信息,要想获得距离较长的上下文关系,只有利用增加图卷积层数来解决。但经研究发现,GCN层数过多会导致极高空间复杂度的出现,而且网络层数的增加也会使得节点信息过度平滑,不利于文本分类[5]。为了克服文本中上下文相关信息缺失的问题,本文在原有GCN 的基础上引入了双向长短时记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)[6],提出一种改进的GCN(BERT_BGCN)文本分类方法,讨论融合上下文信息后的图卷积网络模型对文本分类的影响。
1 相关工作
与传统的依靠人工提取特征的分类方法不同,目前基于深度学习的分类方法利用神经网络自动获取特征进行文本分类。例如,TAI 等[7]在序列化LSTM 中结合依存关系、短语构成等特性,使情感分析的语义表达更加明确。ZHANG 等[8]通过将情感词信息引入BiLSTM 对文本进行分类。YANG 等[9]在文本分类任务中引入了层次化的attention 机制,从句子和文档两个角度使用注意力机制,以提高文本分类的准确性。
图卷积神经网络近年来在自然语言处理领域有大量的应用。BASTINGS 等[10]将图卷积神经网络作用于依存句法树上,应用在英语和德语、英语和捷克语的机器翻译任务。LI 等[11]提出了一种基于任务自适应构造新拉普拉斯矩阵并生成不同任务驱动卷积核的方法,该方法在处理多任务数据集方面优于GCN。YAO 等[12]将GCN 引入文本分类,并将整个语料库建模为一个异构网络,在不使用预训练模型和外部知识的情况下取得了非常好的结果。尽管GCN 在文本分类中表现良好,但它仍然不能解决短文本分类任务中上下文语义信息缺乏和语义稀疏的问题。针对这个问题,提出融合上下文信息后图卷积网络的短文本分类模型。
2 模型设计
本文通过对基于神经网络的文本分类研究,提出一种改进GCN(BERT_BGCN)短文本分类方法。模型结构分为文本预处理、得到初始特征矩阵、提取文本特征、构建邻接矩阵、拼接特征、训练网络以及分类器预测等部分。首先,利用BERT 得到分字后文档的初始特征表示,将其输入到BiLSTM 中获得更深层的文本特征,从而有效地利用了上下文信息。同时也将其输入到第一层GCN,将两种特征信息聚合形成BGCN 需要的特征矩阵。其次,为了提高分类效率,本文将文档中每一个字设为图节点,为每个输入文本单独构建一个全局点互信息(Pointwise Mutual Information,PMI)共享的图。再次,将特征矩阵和邻接矩阵输入神经网络进行训练。由于本文没有将文档作为节点,因此最后进行图读出操作(ReadOut),通过全连接层进行节点聚合分类。模型框架如图1 所示。
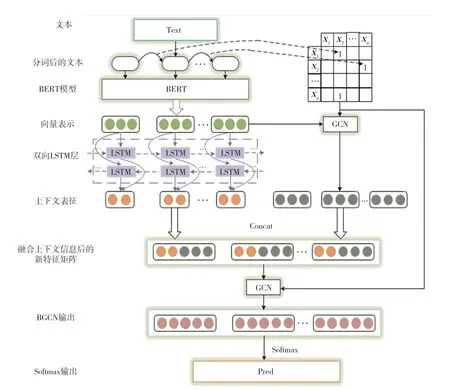
图1 BERT_BGCN 总体框架
2.1 基于全局PMI 构图
本文为每个输入文本构建全局参数共享的图,而不是为整个语料库构建单个图。这种方法消除了单个文本和支持在线测试的整个语料库之间的依赖性负担,但仍然保留了全局信息。为了确定节点间的关系,合理计算全局字共现信息,最常用的方法是使用一种关联度量即计算节点之间的点互信息量(PMI)。节点x和y的PMI 值计算如式(1)所示:
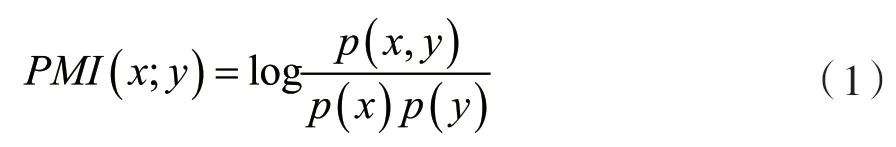
计算文本中x和y的概率分布,一般采用的是滑动窗口的计算公式,即使用一个固定长度的滑动窗口在文本上滑动,统计滑动窗口中字出现的次数,记录滑动窗口总数目,通过节点在滑动窗口中单独出现的次数以及共现的次数计算他们的概率分布,如式(2)、式(3)所示。
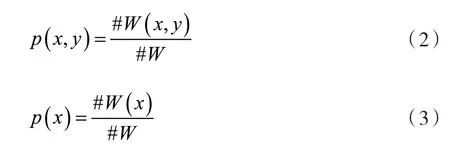
式中:#W为滑动窗口的总数目,#W(x)为x出现在滑动窗口的次数,#W(x,y)为共同出现在滑动窗口的次数。
2.2 图卷积网络
图卷积网络(GCN)是一种能处理图数据进行深度学习的模型,它通过运算将邻居节点的特征聚合到自身节点,多次聚合后捕获到节点与高阶邻域信息的依赖关系。对于一个图G=(V,E),V表示为图中节点的集合,E为边的集合。图卷积网络层与层的传播形式如式(4)所示。通过式(5)计算。
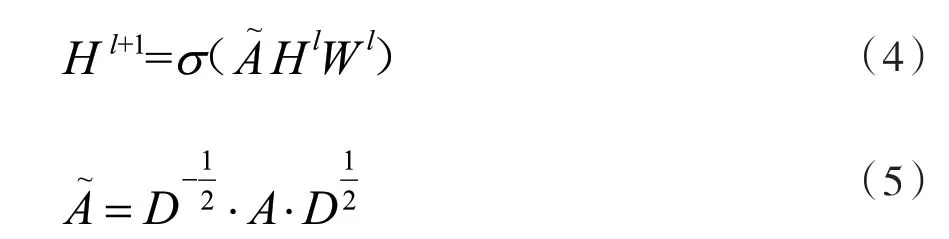
式中:A表示邻接矩阵,D表示度矩阵,l表示GCN 叠加层数。当l为0 时,Hl=X0,X0∈Rn×d是初始特征矩阵即第一层网络的输入,n为图中节点数,d代表每个节点特征的嵌入维度,A∈Rn×n为邻接矩阵表示节点之间的关系,Wl∈Rd×m为第l层的权重参数矩阵。(·)为非线性激活函数,例如ReLU。
2.3 融合语义信息的特征矩阵
以往,GCN 通过建立一个全局字典进行onehot 编码,只能提取浅层的初始特征,而初始特征质量往往影响到整个模型的性能。BiLSTM 分前向、后向两个LSTM,能有效保留前后文信息,分析出所有节点的相关联系,通过BiLSTM 模型可以更好地捕获双向的语义关系。因此本文利用BiLSTM 提取文本的更深层次的文本特征,还可以保留文本的位置信息并捕获文本的序列化特征。本文利用BERT生成的初始特征矩阵同时输入至BiLSTM 和GCN网络,得到两个隐向量矩阵hBiLSTM和hGCN,将两个隐向量矩阵的特征信息聚合在一起,得到融合上下文信息的新特征矩阵hBGCN。操作如图2 所示。

图2 特征信息聚合过程
运算结果通过式(6)、式(7)、式(8)得到。

2.4 模型训练
本节使用随机梯度下降法对模型进行训练,模型的损失函数采用交叉熵代价函数。模型的输出层使用softmax 函数将向量压缩为每个类别的概率进行输出:
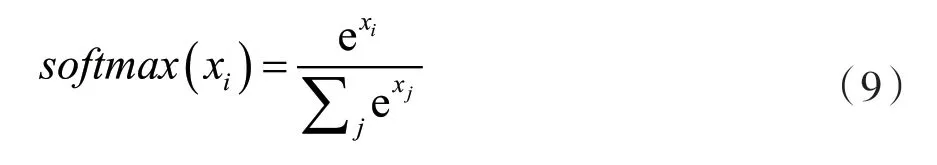
3 实 验
3.1 数据集及评价指标
本文使用3 个二分类数据集,分别是谭松波酒店评论数据集、外卖评论数据集、京东网购评论数据集。其中,谭松波酒店评论数据集来源于网络公开数据集,包括投宿者对酒店服务的正、反两面评论,外卖评论数据集的内容主要包含点餐用户对于食物味道的好坏、店家服务质量等方面的评价,京东网购数据集包括买家对商品及卖家服务的正、反两面评论。
本文使用Accuracy评价模型的性能。令TP、FP、FN、TN分别代表正阳性、假阴性、假阳性、正阴性的分类数量。评价指标计算公式如下:
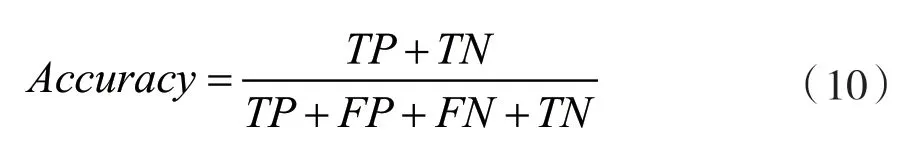
3.2 环境配置及参数设置
本文使用Python 3.7 的运行环境,实验基于Keras 2.2.4 和Tensorflow 1.14.0 深度学习框架构建,实验操作环境为Intel(R)Core(TM)i7-8700k,内存为8 GB。
本文模型使用的特征提取网络模型为KIPF 等人提出的GCN,每层特征维度为256 维,batch_size为128,学习率为0.01,激活函数使用ReLU 函数。在得到字向量过程中使用的BERT 版本为基础版本,有12 层神经,输出维度为786,多头注意力为12 头,总共110 MB 参数。
3.3 基线模型
为了评估BERT_BGCN 的模型性能,本文用以下几个基线模型与本文模型进行比较。
(1)LSTM。该模型是一个经典序列模型,直接使用输入处理过的文本数据,仅使用一个LSTM 对文本数据进行建模,将输出层输出的特征向量送入softmax 函数进行分类。
(2)BiLSTM。该模型使用两个不同方向的LSTM 对文本数据建模,解决了传统LSTM 模型只保留文本过去信息而忽视了下文信息的弊端。
(3)Self-attention。该模型是谷歌开发的Transfomer 模型的基础架构,使用注意力机制的思想,解决了文本信息长距离传输的问题。本文使用编码器和译码器均为6 层的模块进行堆叠,得到最终的输出。
(4)BiGRU-Capsnet。该模型是一种将BiGRU双向门控循环单元和Capsnet 胶囊神经网络结合的模型,有效地结合两个模型的优点。
(5)GCN。该模型除了没使用BiLSTM 层提取上下文相关性之外,其余部分模块和参数与本文模型一样。
3.4 实验结果及分析
为了验证BERT_BGCN 的性能,本文将文本分类中的几个经典模型作为基线模型进行对比实验,对比结果如表1 所示。
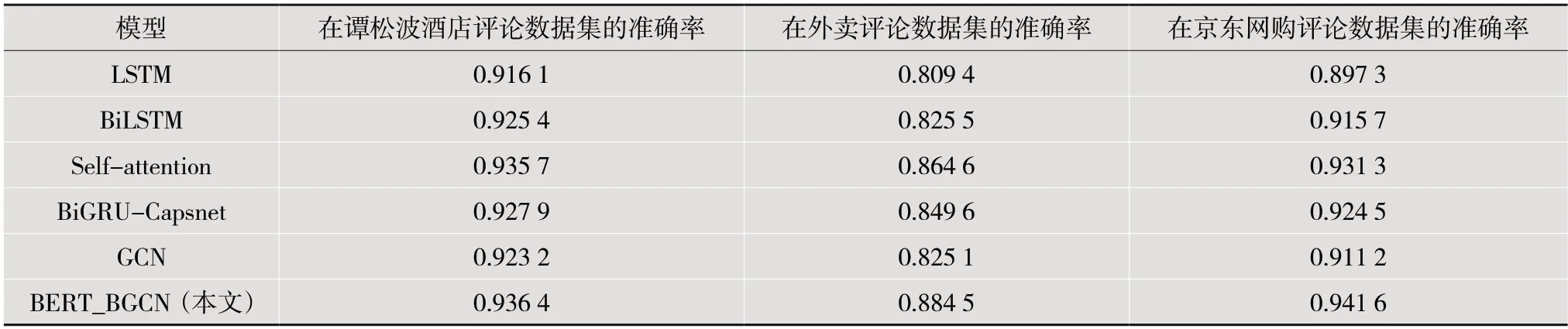
表1 模型性能对比
在3 个中文评论数据集上的实验结果证实了BERT_BGCN 的性能优于其他基线模型,这表明本文方法在评论短文本数据上的有效性。本文模型相较于普通GCN 有一定提升。普通GCN 在3 个数据集上的精确度除了LSTM 比其他几个基模型都低,分别为92.32%、82.51%、91.12%,这是因为GCN 在情感分类中不能充分利用上下文依赖关系。在3 个数据集上,与原始GCN 相比,引入BiLSTM的BERT_BGCN 模型分别将精确度提高了1.32%、5.94%、3.04%,虽然两个模型的初始特征表示相同,但是本文模型利用BiLSTM 进行特征提取具有很大的优势,说明模型引入BiLSTM 确实丰富了GCN 上下文语义相关性,提取出了更深层次的特征,提高了分类性能。在谭松波酒店评论数据集上,BERT_BGCN 的准确率只比其他基线模型中最好的Selfattention 模型高0.07%,这可能是因为此数据集文本长度相对较长,无关节点增多,为无关节点添加边会影响分类性能。在较短的平均文本长度下,本文模型性能提升更加明显,如外卖评论数据集和京东网购评论数据集。而文本长度较长的情况下,与其他模型相比,本文模型提升较少。
4 结语
本文结合双向LSTM 和图神经网络构建了一个融合上下文图卷积的分类模型。利用BERT 得到需要分类文本的初始特征,将其输入至BiLSTM和GCN 模型中,然后将两者输出结合作为融合上下文信息的新特征矩阵,利用双向长短时记忆网络捕捉上下文语义信息得到更深层次的特征表示,弥补GCN 网络的弊端。在3 个中文评论短文本数据集上进行实验,准确率同基线模型相比都有不同程度的提升。下一步将探究如何融合更多特征和外部知识进行分类,同时将本文模型应用到多分类任务上。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
数学小灵通(1-2年级)(2021年4期)2021-06-09
电子制作(2019年11期)2019-07-04
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
北京航空航天大学学报(2018年1期)2018-04-20
初中生世界·七年级(2017年9期)2017-10-13
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
