
应用情绪向量的相似性预测新闻点击量
2022-01-07 01:23毕阳阳
软件导刊 2021年12期
艾 均,毕阳阳,苏 湛
(上海理工大学光电信息与计算机工程学院,上海 200093)
0 引言
随着移动互联网的发展,智能终端已经普及,中国网民规模达8.54 亿,网民使用手机上网的比例达99.1%[1],互联网成为大众获取信息的重要渠道。自媒体等新兴形式使普通公众关注及参与公共事务,对政府动态、国际关系的关注远远高于传统媒体时代。普通民众参与度提高,而网络信息良莠不齐,不法分子利用网络舆情夸大新闻事实,使用夸张的表达吸引读者,谋取自身特殊利益。因此,把握网络舆情、理解用户群体偏好,预测用户群体对新闻可能出现的关注度,具有重要的理论及现实意义。
目前对互联网新闻的热度预测主要集中在两个方面[2]:①跟踪研究新闻在互联网的早期传播,以及用户点赞和评论等行为,预测其未来流行度;如文献[3]研究Twitter新闻传播,提出了基于新闻传播过程的新闻流行度预测模型;文献[4]则通过对评论数、用户数量、投票得分和争议程度等挖掘预测新闻受欢迎程度。新闻在发布后预测效果会更好,但具有一定的时间滞后性,需要对研究主体跟踪观测;②不使用早期的流行度或普及度指标,仅考虑文本本身的特征,如文献[5]考虑新闻来源、新闻类别、文本语言的主观性、文本提到的实体等特征用于新闻报道传播预测;文献[6]则通过关键字、发布日期和数据渠道提取特征用于流行度预测;文献[7]提出一个命名实体主题模型,以提取推动人气增长的文字因素。这种预测方式虽然在准确度上相对较低[8],但预测结果可取,因为它可在发布前进行自定义修改内容,灵活性更强。但是,这些基于文本特征的预测方法侧重于文本本身的含义和内容特征,极少考虑文本信息的情感特征。针对这一不足,本文从文本信息特征出发,基于情感特征度量来研究热点新闻的预测问题。
互联网上大量的文本信息往往蕴含情感色彩。情感分析又称为意见挖掘、情感挖掘,是对带有主观情感色彩的文本进行分析归纳,是人工智能的热门研究领域[9]。文献[10]提出将隐藏主题—情感转换模型用于检测文档级及句子级情感;文献[11]提出多标签分类的情感分析方法用于微博的情感分类工作,比较了3 种情感词典对多标签分类的影响,结果表明大连理工大学情感词典表现最佳;文献[12]关注在线用户社交情感挖掘,从用户角度分析社交媒体中的情感因素。挖掘文本的情感因素有助于分析文本中的立场和观点[13],并应用于舆情管控、观点分析、商业决策、信息预测等场景。文献[14]考虑情感信息的大小和极性用于自动检测有争议的新闻文章;文献[15]融合单词和句子级别的情感特征到人机对话模型中,生成与原始情感一致的对话文本;文献[16]通过分析Twitter 中情感指数,发现其可在一定程度上预测3、4 天后的股市变化。但这些研究中,未见应用情感分析对新闻点击量进行预测的相关工作。
针对上述问题,本文通过构建文本的情绪向量度量方法,分析新闻标题中的情感因素,计算新闻情绪向量之间的相似性;基于情绪向量的相似性以及基于相似性的邻居选择,采用协同过滤算法预测热点新闻的时均点击量;针对新闻点击量实际波动范围较大的特点设计了平均绝对比例误差和均方根比例误差两种误差度量方法。
1 热点新闻点击量预测模型
本文基于情绪内容分析文本的情感因素并用于热点新闻的点击量预测,算法整体结构如图1 所示。
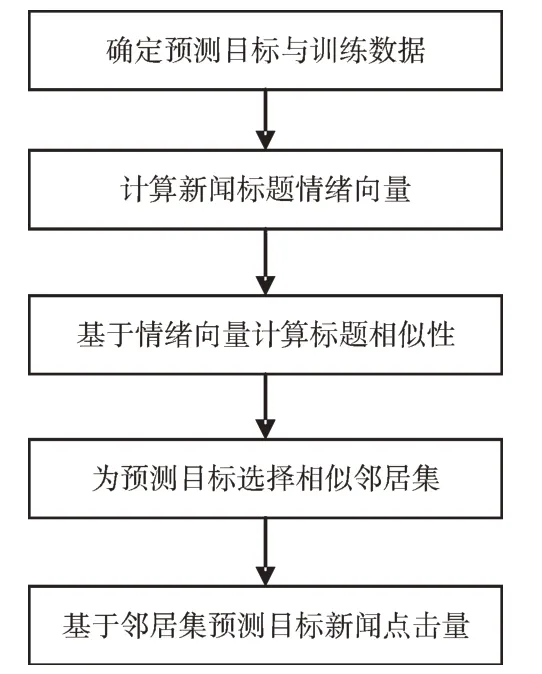
Fig.1 Algorithm general steps图1 算法一般步骤
1.1 使用情感词典分析并构建情绪向量
本文使用情感词典[17]方法分析新闻标题的情感因素。在比较了情感分析词语集(HowNet)[18]、中文情感极性词典(NTUSD)[19]、情感词汇本体库[20](DUTIR)等国内流行的中文情感词典后,最终选择使用大连理工大学的情感词汇本体。DUTIR 是在国外比较有影响的Ekman[21]情感分类基础上构建的,标注了常用词语的情感极性和情感强度。最终的词汇本体将情感分为7 大类21 小类,细粒度比较高。本文使用DUTIR 分别建立基于词的情绪向量(Word-based emotion vector,WBEV)和基于字的情绪向量(Characterbased emotion vector,CBEV)。
建立基于词的情绪向量需要对原有文本进行切割,本文采用目前比较流行的文本切割工具Jieba 分词,并使用精确模式,该模式下试图将句子最精确地切开,适合进行文本分析[22]。
将DUTIR 中的情感词汇定义为二元组w
新闻标题基于词的情绪向量构建过程可以表示为:

基于词的情绪向量流程如图2 所示。
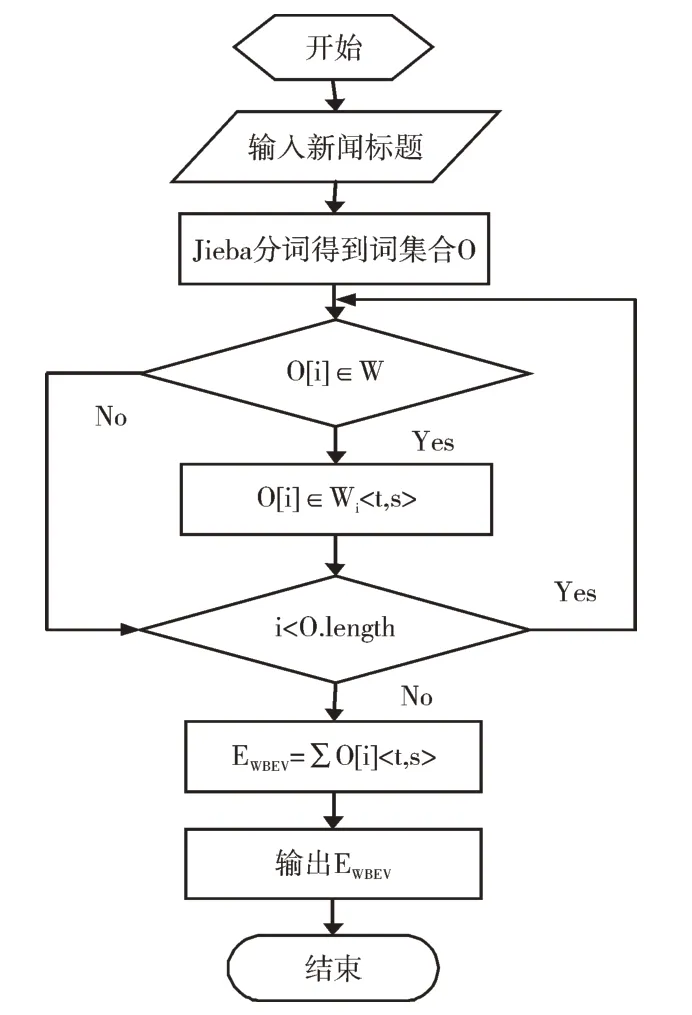
Fig.2 Word-based emotion vector flow图2 基于词的情绪向量流程
情感词典是以词为单位,只能识别带有情绪词的句子,并且在新闻标题中经常出现表达情感的单个字,例如“爆!”“惊!”等。因此,本文除了上述基于词的情感建立的情绪向量外,也将基于字的情感建立情绪向量。
首先要得到字的情感强度和大小。定义字的集合C={c1,c2,c3,...,cn},其中cj∈wi,即ci是DUTIR 中组成情感词汇的字。定义字的情绪向量EC=[t1,t2,t3,…,tn],此时,该向量代表字的情感。借助DUTIR 词库,采用复杂网络中二部图模型,将词和字看作两种不同类型的节点,词与字的包含关系作为连边的依据,如图3 所示。
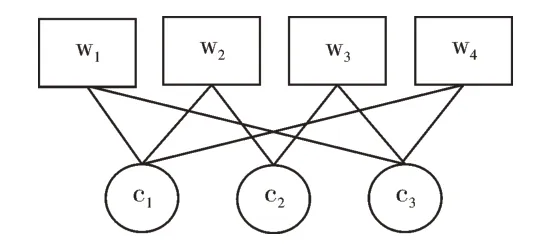
Fig.3 Character-word bipartite graph图3 字—词二部
通过情绪从词扩散[23]到字,得到字的情感,具体步骤如下:
初始阶段,对于wi,把情感和强度分配给组成该词的字cj,其中,l是词w的长度:
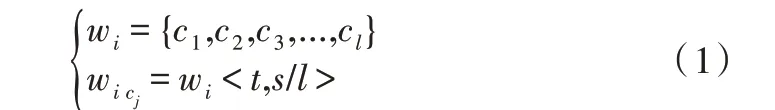
在二部图中字cj的情绪向量为:
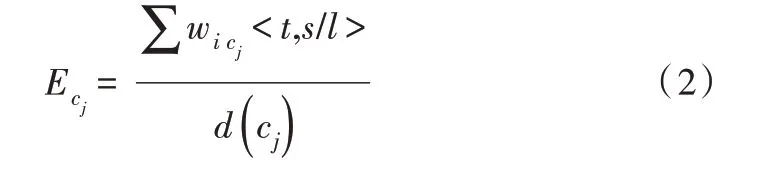
其中,d(cj)是cj在网络中的度值。
由此得到词库中每个字的情绪向量,代表这个字的情感倾向,由此构建新闻标题的情绪向量。

基于字的情绪向量流程如图4 所示。
Fig.4 Character-based emotion vector flow图4 基于字的情绪向量流程
1.2 基于相似性的协同过滤点击量预测
利用相似性进行预测,一个基本假设是相似性越高,他们之间具有联系的可能性越大。在本文模型中,假设热点新闻标题之间包含相似的情感和强度,那他们在用户之间的传播和影响是相似的[24],这种传播和影响则会反映在新闻的热度或者点击量上。因此,根据上述方法构建的代表新闻标题情感特性的情绪向量EWBEV和ECBEV,使用相似度的度量方法分别计算新闻节点两两之间EWBEV和ECBEV的相似性,得到相似性列表,然后根据相似性进行节点选择和预测。本文使用根据情绪向量设计的相似度度量方法,其中X,Y代表新闻的情绪向量,xi,yi是情绪向量X,Y对应维度的值,公式如下:

协同过滤算法(Collaborative filtering,CF)[25]广泛应用于预测和推荐,该方法通过对用户历史行为的挖掘来预测用户未来的行为。一条新闻的点击量可以看作全体用户对该新闻的评分,对点击量的预测问题就可以转化为预测全体用户对该新闻的评分问题,这样就可利用协同过滤算法实现对热点新闻点击量的预测。在EWBEV相似度列表和ECBEV相似度列表基础上,选择待预测新闻相似度最高的m个节点作为邻居集合,使用如下评分预测公式:
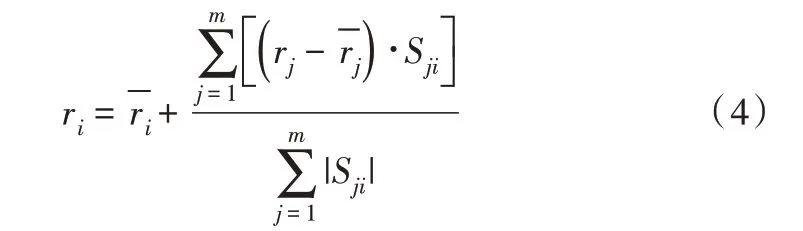
其中,ri为预测值,rj为选择的邻居,为平均值,Sji是ri,rj之间的相似度,即在预测时相似度越高对预测时的影响越大[26]。在基于词的情绪向量并使用协同过滤算法预测(WBEV-CF)和基于词的情绪向量并使用协同过滤算法预测(CBEV-CF)中,ri为热点新闻点击量的预测值。
2 实验结果与分析
2.1 实验数据
在网易24 小时热点新闻上爬取数据,从2019 年11 月到2020 年1 月共3 个月。数据内容包括新闻标题、新闻正文、新闻发布时间和爬取时间、点击量等信息;通过去除不完整及无效数据,共得到4 927 条有效数据。
由于点击量随时间变化,为简化讨论,采用时均点击量衡量新闻热点,即:

同时,不同新闻的热度持续时间不同。为讨论新闻热度问题,以每条新闻的最大时均点击量为代表,其分布如图5 所示。
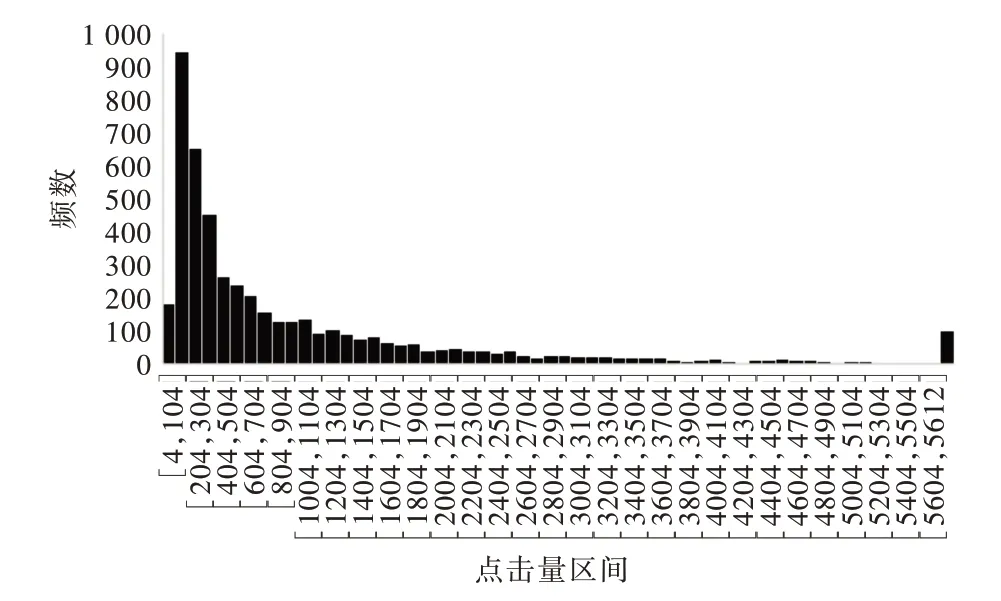
Fig.5 Distribution of the average hourly maximum hits图5 时均最大点击量分布
实验采用折十验证的方式,所有新闻数据随机平均分为10 组,每组依次作为验证集,其余9 组作为训练集,取10次的结果平均值作为最终结果。同时,在每个实验组中,分别依次取相似性邻居数为1,3,5,10,20,…,200 进行实验。为验证本文提出的基于相似性和情绪向量算法的有效性,实验除了使用本文WBEV-CF 和CBEV-CF 算法,也使用传统的基于字频方式作为对比。使用新闻标题之间的统计字频作为相似度依据,并使用协同过滤用于点击量预测(Frequency-CF)。
2.2 评价指标
评价指标有平均绝对误差(mean absolute error,MAE)[27]和均方根误差(root mean squared error,RMSE)[28]。MAE 反映的是真实误差,RMSR 则放大了预测误差,对预测误差较大的惩罚更重,对算法的要求更严苛。误差值越小说明算法越准确。
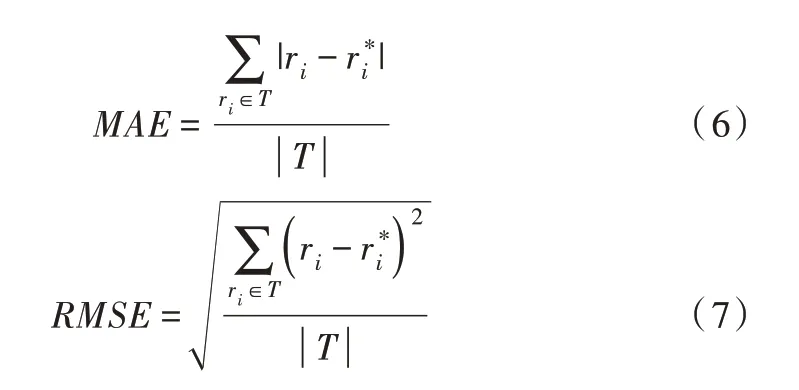
其中,T是测试集,ri为测试集中的真实值,为使用本文预测方法得到的预测值。
实际上,MAE 和RMSE 都是计算的误差平均值,这在评价点击量预测误差时具有一定的局限性。如预测误差值都为100 的两条新闻:一条新闻真实的点击量为1 000,而另一条为100,这个误差可能对于前者可以接受,但对于后者来说,由于本身点击量相对较小,这个误差就是不能接受的。因此,基于以上原因本文设计了平均绝对比例误差(Mean absolute proportional error,MAPE)和均方根比例误差(root mean squared proportional error,RMSPE)来反映相对于真实值的误差。
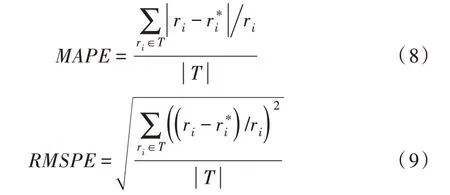
2.3 结果分析
本文使用情感字典构建出代表每条新闻的情绪向量,通过协同过滤算法预测新闻点击量。根据选取邻居节点数量的不同得出如图6、图7 所示结果,其中WBEV-CF 和CBEV-CF 是本文设计的方法,Frequency-CF 作为对比。

Fig.6 MAE values of different neighbor numbers图6 不同邻居数的MAE 值
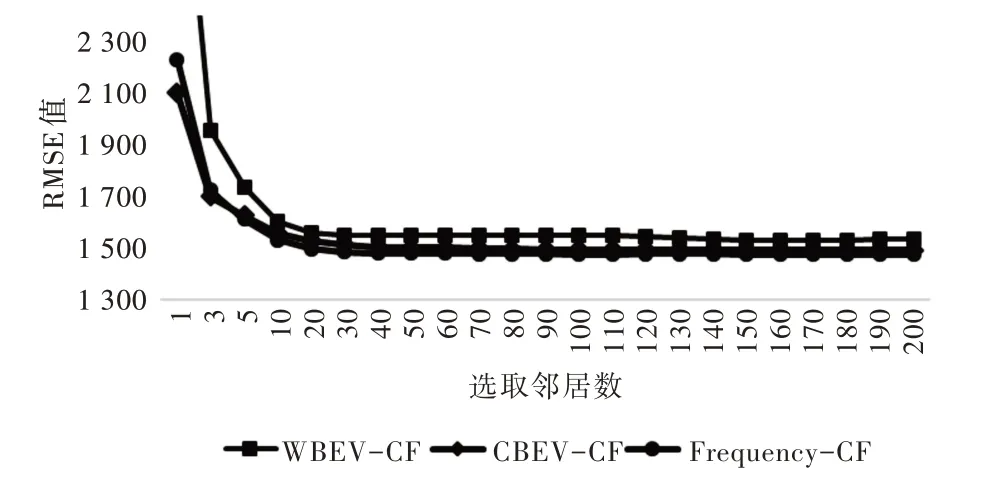
Fig.7 RMSE values of different neighbor numbers图7 不同邻居数的RMSE 值
随着点击量预测过程中选用邻居数量的不断增大,本文基于情绪向量的预测方法所产生的误差不断降低,直至邻居数量为200。在设计的两种方法中,WBEV-CF 预测误差明显低于CBEV-CF 的预测误差,与之相对的,Frequency-CF 的预测方法作为对照方法在邻居数大于70 之后误差便不再下降。
WBEV-CF 预测方法比Frequency-CF 方法更加准确。基于MAE 进行分析,在选择邻居数大于10 之后,预测误差平均降低3.7%,最小误差降低4.3%。几种算法的RMSE 误差结果相近,在选择的邻居数大于10 之后,平均相差2.8%。RMSE 结果相似,且Frequency-CF 的RMSE 值较低,意味着基于情绪向量的预测会产生较大误差。但MAE 显示的预测误差揭示了情绪向量整体上对点击量的预测更为准确。本文同样给出了MAPE 和RMSPE 曲线,反映了相对于真实值的误差。
由图8、图9 可知,MAPE 曲线中的WBEV-CF 依然远好于其他两种方式。与Frequency-CF 相比,当邻居数大于5之后,预测误差比例平均降低23.5%,最小误差比例降低25.5%。而在RMSPE 曲线中,不同于RMSE,WBEV-CF 反而优于Frequency-CF。当邻居数大于10 之后,RMSPE 预测误差比例平均降低22.6%,最小误差比例降低22.2%。
通过以上分析发现,在新闻标题点击量预测过程中,无论是平均绝对误差MAE,还是平均比例误差MAPE 和均方根比例误差RMSPE,本文提出的基于相似性和情绪向量的算法都取得了较好效果,算法整体上更准确;但均方根误差RMSE 差别不大甚至稍差一些,说明有一些点击数量较高的标题在非比例情况下会产生较大误差,但在比例上这些误差相对于真实点击量是较小的,因此本文提出的基于相似性与情绪向量的方法取得了较好效果。

Fig.8 MAPE values of different neighbor numbers图8 不同邻居数的MAPE 值
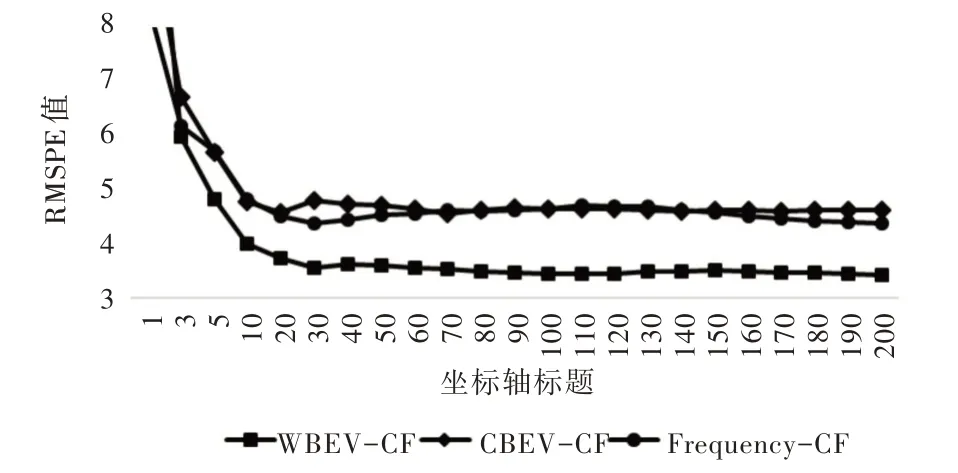
Fig.9 RMSPE values of different neighbor numbers图9 不同邻居数的RMSPE 值
3 结语
针对热点新闻点击量预测研究没有考虑情绪特征这一问题,本文从文本内容分析出发,利用分词方法对新闻标题进行分析并设计了情绪向量计算方法,以此建立各种情绪倾向和强度的情绪向量。通过计算新闻标题情绪向量之间的相似性,并基于相似性采用协同过滤方法预测热点新闻的时均点击量。实验结果表明,新闻标题中的情绪因素与其时均点击量相关,基于情绪向量的点击量预测方法在预测准确度上明显优于基于词频的预测方法。研究结果揭示了大众对新闻的反应中新闻标题的情绪起到重要的影响作用。新闻标题中的情绪一定程度上包含了作者的观点、立场和态度,这些信息通过情绪化的表达影响到读者的点击行为。此外,在对新闻热点的点击量预测中,将情绪因素和其他因素相结合进行预测,可进一步提高预测准确度。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
河北画报(2020年8期)2020-10-27
活力(2019年22期)2019-03-16
活力(2019年22期)2019-03-16
喜剧世界(2016年9期)2016-08-24
浙江大学学报(工学版)(2016年2期)2016-06-05
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
