基于遗传算法的智能粒子滤波重采样策略研究
2022-01-04 09:35刘海涛林艳明陈永华周尔民
电子与信息学报 2021年12期
刘海涛 林艳明 陈永华 周尔民* 彭 博
①(华东交通大学机电与车辆工程学院 南昌 330013)
②(清华大学苏州汽车研究院 苏州 215131)
1 引言
系统状态估计是从系统噪声测量中推断出系统内部隐状态的方法,其典型代表就是贝叶斯滤波。卡尔曼滤波和粒子滤波(Particle Filter, PF)是在贝叶斯滤波的基础上发展出来的状态估计技术。对于线性、高斯系统,卡尔曼滤波具有良好估计性能;对于非高斯、非线性系统,卡尔曼滤波易发散,而粒子滤波估计性能更具优势[1]。粒子滤波算法基本框架最早由Gordon等人[2]提出,已广泛运用于机器人[3]、通信与信号处理[4,5]、目标追踪[6,7]及目标定位[8]等领域。粒子退化是粒子滤波算法的一个重要问题,相关学者通过研究重采样方法来克服粒子匮乏的影响。近年来提出了大量重采样方法,比如分区重采样[9]、并行重采样[10]、系统重采样[11]、残差重采样[12]、正则重采样[13]等,但上述重采样方法均未能有效解决粒子退化问题。遗传重采样算法为解决粒子匮乏问题提供了一条有效的研究思路。叶龙等人[14]提出一种遗传重采样粒子滤波,在粒子滤波重采样中对粒子进行分区、交叉、变异等处理,有效抑制粒子退化。2012年,Bi等人[15]将遗传重采样粒子滤波算法应用于高速公路交通状况估计,并取得了良好的估计效果。Bi等人[16]将遗传重采样算法运用于电池健康状态估计中,其估计效果在性能上明显优于一般粒子滤波。Khong等人[17]利用遗传重采样粒子滤波降低车辆跟踪中的误差,即使车辆在受到各种遮挡情况下也能有效跟踪。张民等人[18]对遗传重采样进行改进,其基本原理是将粒子群分类,保留最佳粒子群体,并将权值最低的粒子群体进行变异。上述遗传重采样算法有效提高了粒子多样性,但并未系统性分析粒子多样性和粒子后验概率分布情况。Yin等人[19]提出一种智能粒子滤波算法(Intelligent Particle Filter, IPF),该算法在重采样过程中结合遗传算法,将粒子按权值分为大、小两个群体,对权值较小的群体进行交叉、变异,使其进化成权值较大的粒子,有效克服了粒子退化的影响,并在多种模型中估计效果高于PF。但IPF中,遗传重采样粒子完全根据变异概率随机变异。在低权值粒子中,粒子权值分布并非均匀,粒子权值越低,该粒子越容易被淘汰,从而使得粒子多样性在多次迭代以后受到损失。因此,在交叉和变异算子中增加自适应处理,有望进一步提高粒子利用率并降低粒子退化影响。
本文在智能粒子滤波的基础上提出一种改进智能粒子滤波方法(Improved Intelligent Particle Filter, IIPF)。设计一种新的遗传重采样策略,对低权值粒子进行自适应处理,优化变异算子,以提高粒子多样性和估计性能。最后通过仿真实验来验证改进的智能粒子滤波性能。
2 基本粒子滤波算法与智能粒子滤波
2.1 基本粒子滤波算法
粒子滤波采用一组样本(或称粒子)来近似表示系统的后验概率分布,并使用这一近似的表示来估计非线性系统的状态。系统状态如下

传统重采样算法所得到的子代粒子都来自权值较大的父代粒子,迭代多次后所产生的子代粒子都来自少数几个初始粒子,将无法充分覆盖后验概率分布区域,从而严重影响估计性能。为降低粒子匮乏的影响,可直接增加粒子数量。但随着粒子数量的增加,运算效率也会降低。
为有效解决粒子匮乏现象,Yin等人[19]提出了一种智能粒子滤波,该方法未直接将权值低的粒子抛弃,而是使其通过交叉、变异,进化成为新的粒子,从而不断产生新的粒子,以提高粒子多样性。
2.2 智能粒子滤波
为解决重采样后粒子退化问题,Yin等人[19]提出一种智能粒子滤波算法(IPF)。该算法的重采样过程结合遗传算法的思想,将低权值粒子与随机抽取的高权值粒子进行交叉、变异处理,生成新的粒子,以提高粒子的多样性。
(1) 分离:将粒子根据权值大小分为两个群体,权值较大的群体保留,不发生交叉、变异操作,而权值较小的群体进行后续交叉、变异操作。

有效粒子个数(Neff)用于判断是否仍有必要继续进行重采样。若粒子的有效粒子个数超过了预先设定的阈值,重采样过程终止;否则,继续进行。将权值集合按降序进行排列得到集合Z,式(7)中的阈值WT设置为Z中的第Neff个值。

与传统粒子滤波算法相比,智能粒子滤波大幅度提高粒子多样性,降低粒子退化现象。然而,在该算法中粒子均为随机变异,而低权值粒子群中粒子权值分布未必均匀,粒子权值越低,粒子越易淘汰。因此,在变异算子中加入自适应处理,有望进一步提高粒子的利用率。
3 改进智能粒子滤波
为进一步提高粒子多样性,优化粒子的交叉系数或变异概率的选择,在变异算子中加入自适应处理,提出一种改进智能粒子滤波方法,如表1。图1(a)所示为智能粒子滤波的遗传重采样示意图,图1(b)所示为改进智能粒子滤波的遗传重采样示意图。改进智能粒子滤波在遗传重采样中增加了自适应处理,即粒子根据其权值大小自行分为高权值粒子、低权值粒子和底层粒子,高权值粒子保留其状态信息;低权值粒子将根据变异概率随机变异;底层低权值粒子作为低权值粒子中的特殊群体,具有优先变异的资格;底层低权值粒子的变异策略不是根据变异概率变异,而是直接变异。


表1 改进的智能粒子滤波算法
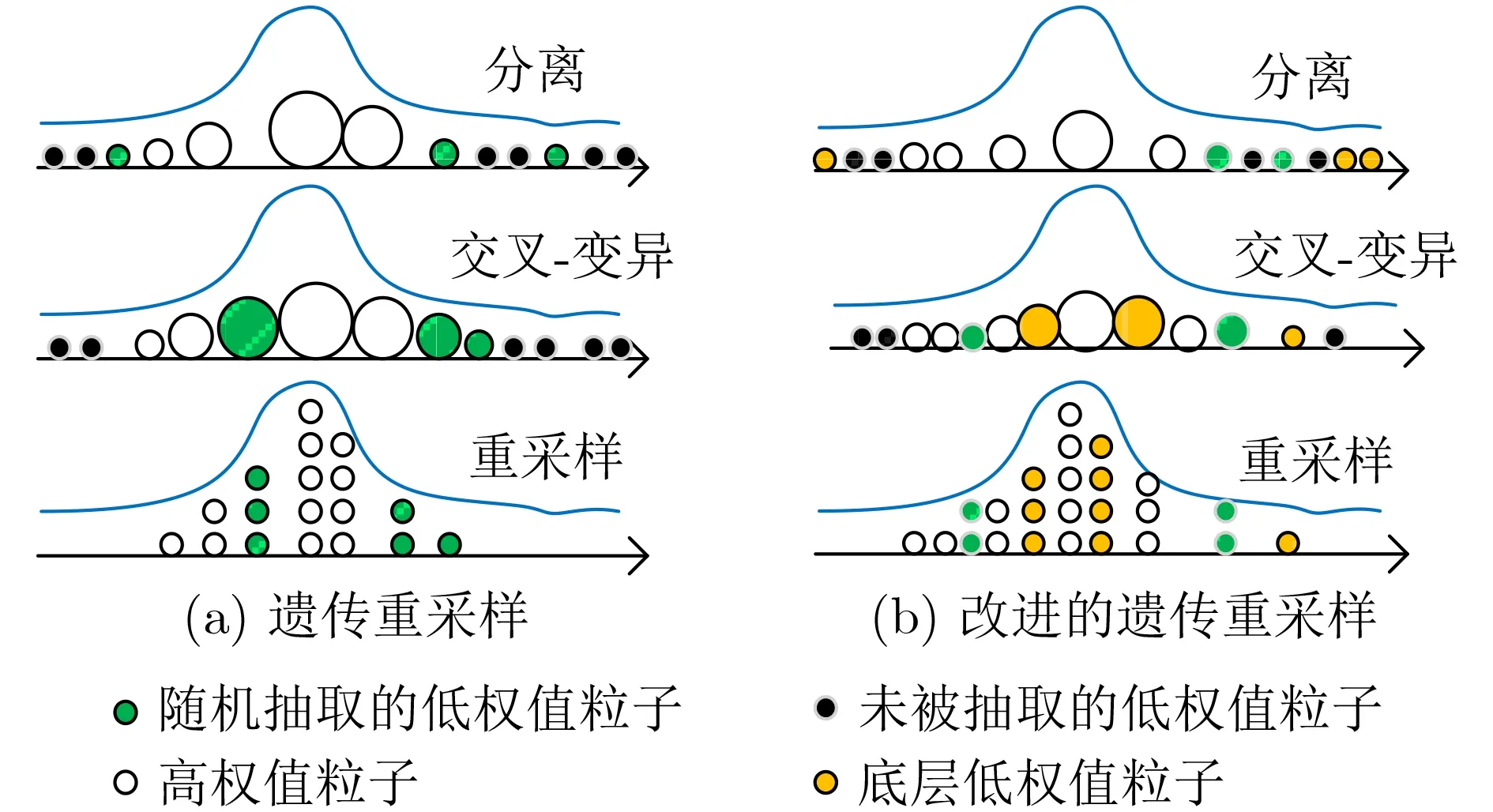
图1 智能粒子滤波和改进智能粒子滤波的遗传重采样示意图

4 仿真分析
实验仿真环境如下:处理器为Intel(R) Core(TM) i5-6200U CPU @ 2.3 GHz;RAM为8 GB;操作系统为Windows10 64位。为验证算法性能,选择两组运动模型,分别计算平均误差和均方根误差
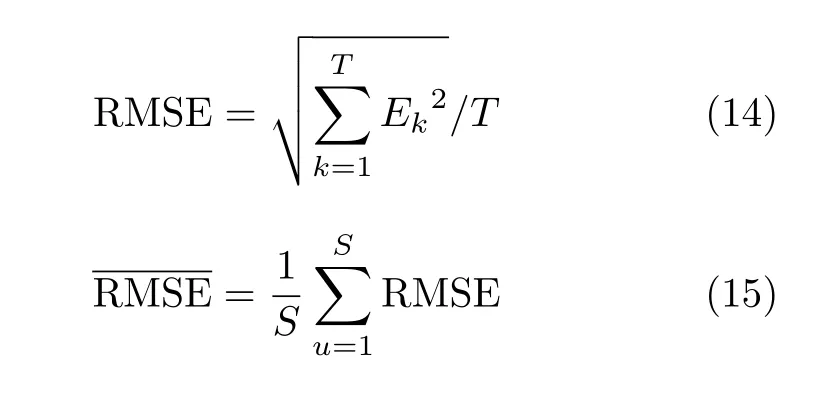

4.1 1维仿真模型

选择交叉系数α和变异概率pM分别为0.85和0.5,将正则粒子滤波(Regularized Particle Filter, RPF),PF和IPF作为对照组,进行1维仿真实验。图2为1维仿真模型的系统状态及平均误差。在大部分跟踪过程中,IPF和IIPF误差均小于PF和RPF,在55~63 s尤为明显。而IIPF在IPF中增加了自适应过程,使其在非线性程度更高的系统中,误差小于IPF,尤其在5 s时和15 s附近效果显著。图3所示为当N取200、跟踪至63 s时,粒子后验概率分布图。图3中,IIPF后验概率分布区域更为均匀,且底层低权值粒子数量因变异至高权值区域而减少,同时,IIPF峰值区域粒子分布较IPF更为均匀。
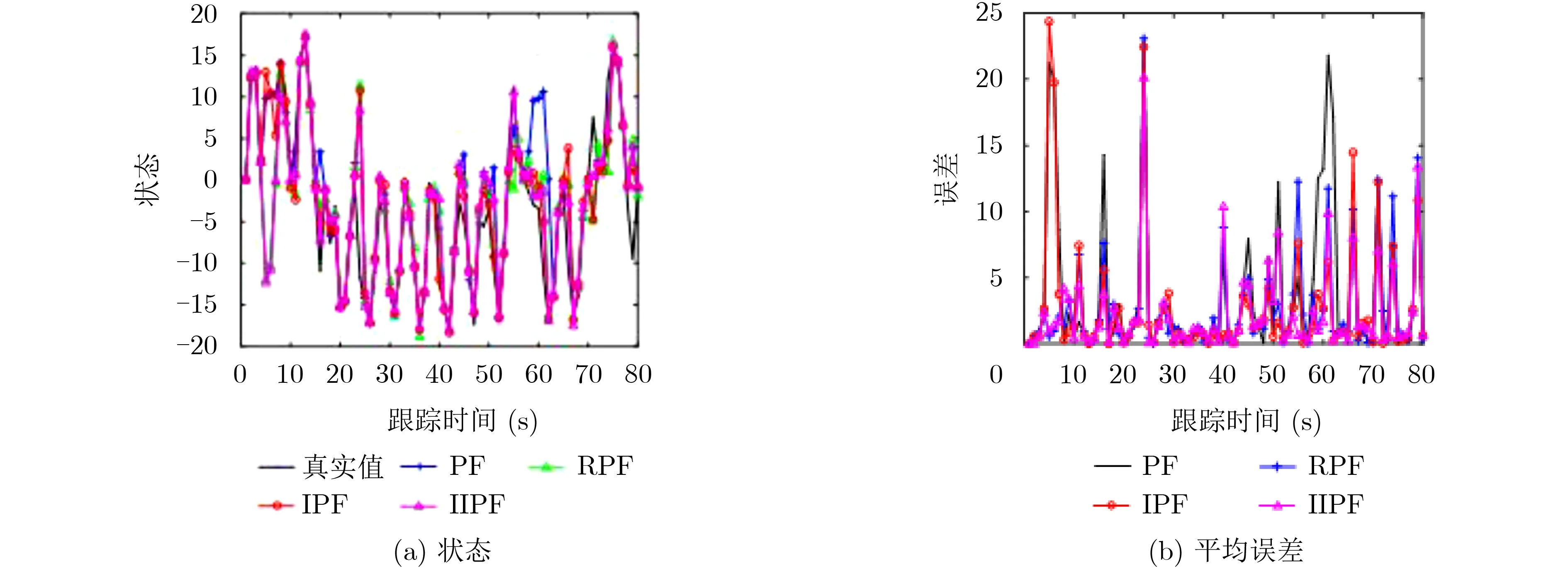
图2 1维仿真模型的状态及平均误差

图3 k =63时粒子分布图
由于单次仿真存在偶然性,图2未能完整展示IIPF优越性能。因此,选择粒子数为50,循环仿真100次,根据式(15)计算均方根误差的均值,并计算平均误差、平均耗时、平均有效粒子数用以佐证,计算结果统计于表2中。如表2所示,IIPF均方根误差较PF和IPF分别降低了7.4%和8.5%;平均误差分别降低了10.6%和7.5%。IIPF有效粒子数略大于IPF,远高于PF和RPF。PF平均耗时最短,RPF为3.884 s, IPF耗时0.041 s, IIPF为0.044 s。RPF性能虽强于PF和IPF,但RPF需在离散先验概率密度中重构其连续近似分布,并从该连续分布中重复采样,导致运算时间过长;IPF在PF基础上添加了遗传算子,其运算时间亦有所增加;而IIPF在IPF的遗传算子中增加了自适应过程,其运算时间略长于IPF。
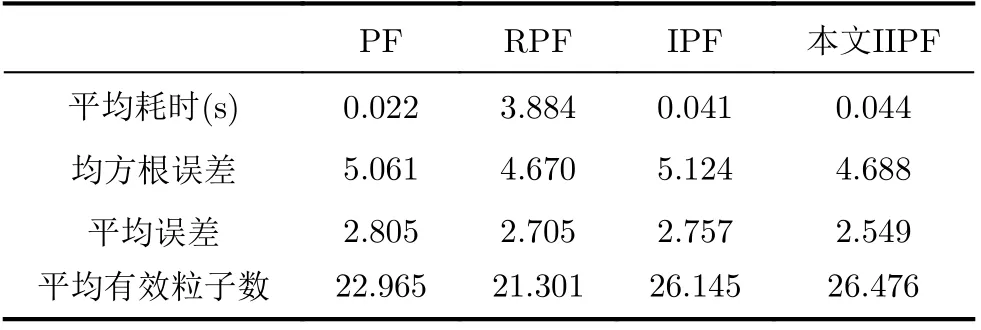
表2 1维模型仿真结果
为验证算法收敛性,取不同粒子数,对各粒子滤波进行收敛性分析。对各粒子滤波进行30次重复仿真,计算其平均RMSE。实验结果如图4所示,PF和IPF在粒子数达到1000后还未明显出现收敛现象,而RPF和IIPF在粒子数达到80时趋向于收敛。图4表明,IIPF的收敛性明显优于IPF和PF。
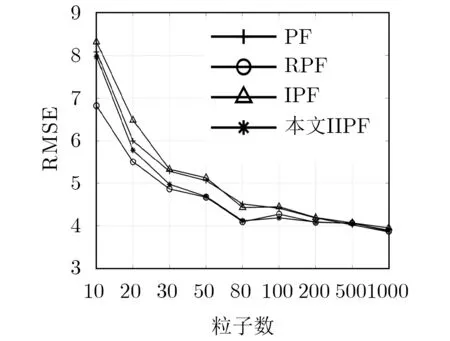
图4 不同粒子数下各算法均方根误差
通过1维仿真,可验证IIPF性能明显强于PF,RPF和IPF。IIPF相比于IPF计算效率略低,但在收敛性和准确性方面均优于IPF。
4.2 高斯随机噪声下的多维仿真模型
为了更好地测试提出的粒子滤波算法的性能,另外引入一种多维仿真模型。该模型为物体自高空坠入大气层[20],如式(18)和式(19)所示
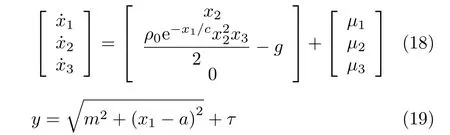
其中,x1,x2,x3分别代表物体坠入大气层时的高度、速度、恒定弹道系数,µ1,µ2,µ3为系统的高斯随机噪声,τ为观测噪声,E(τ2)取值929 m2。ρ0为海平面的空气密度,取值1.29 kg/m3,c为高度与空气密度的关系系数,取值6096 m,g为重力加速度,取值9.8 m/s2,a为观测高度,取值3.05×104m。
选择变异概率pM为0.8,交叉系数α为0.9,进行100次仿真计算。图5所示为粒子选择1000时,PF, EKF, IPF, IIPF速度估计结果,其中,虚线为真实值。图中IPF和IIPF速度估计性能显著优于PF和EKF。
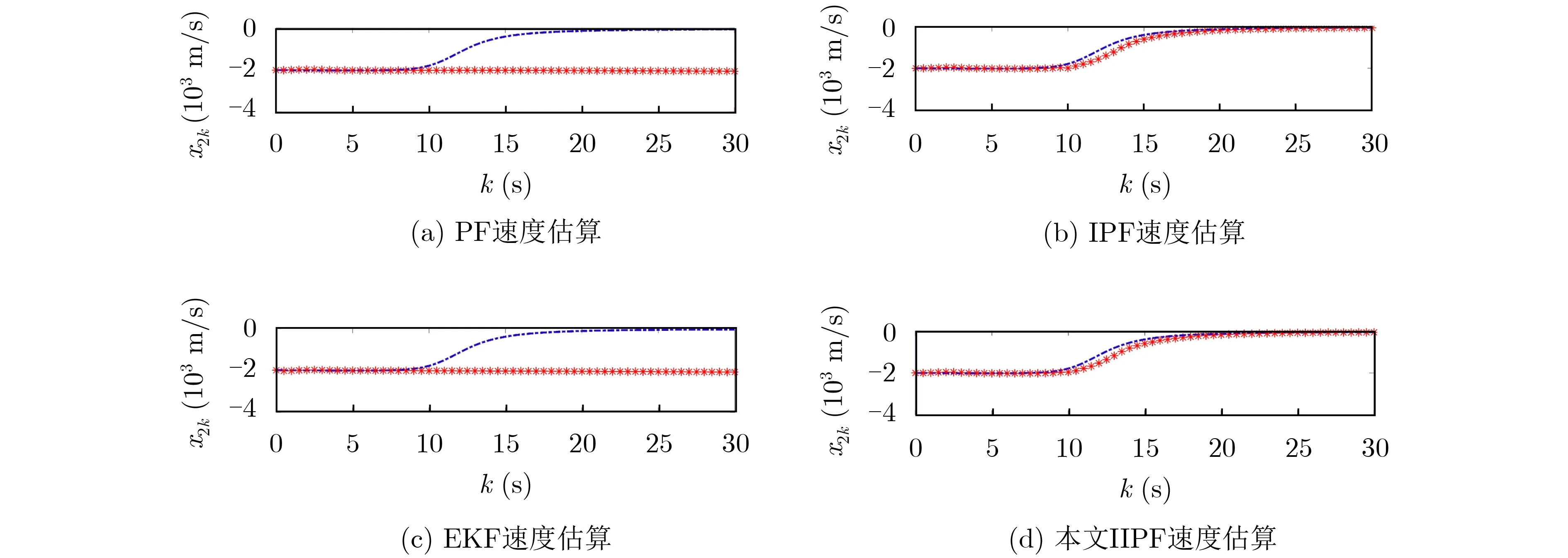
图5 速度状态估计图
图6为某时刻粒子后验概率分布图。从图6的结果对比可知,IIPF的粒子后验概率分布区域的粒子分布更为均匀,充分说明了本文提出的重采样策略可有效提升粒子的多样性。系统跟踪误差如表3所示,IIPF性能皆优于IPF, EKF和PF,IIPF高度和速度在均方根误差和平均误差上均低于其他算法。其中,高度均方根误差较IPF降低了11.5%,速度均方根误差较IPF降低了6.8%;且高度和速度平均误差也小于IPF。
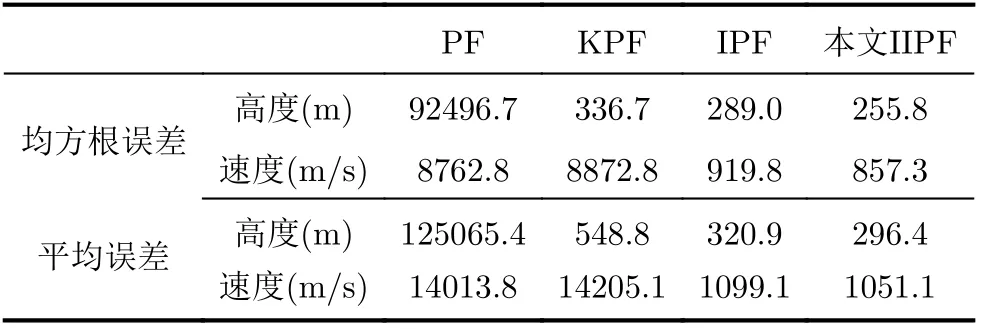
表3 多维模型均方根误差与平均误差表
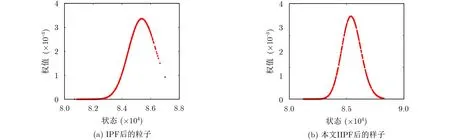
图6 k =11,N =500时粒子分布图
4.3 非高斯随机噪声和乘性噪声下的多维仿真模型
为进一步验证IIPF性能,将4.2节多维仿真模型(式(18))中的系统高斯随机噪声分别改为非高斯随机噪声和乘性噪声,其余参数设置不变。其中乘性系统噪声如式(20)所示

表4所示为IPF和IIPF算法的高度和速度均方根误差。结果表明,IIPF在高度和速度均方根误差上性能均优于IPF,在高度均方根误差上,IIPF均有超过10%的性能优势;在速度均方根误差上,IIPF相比于IPF也提升了6.5%以上。
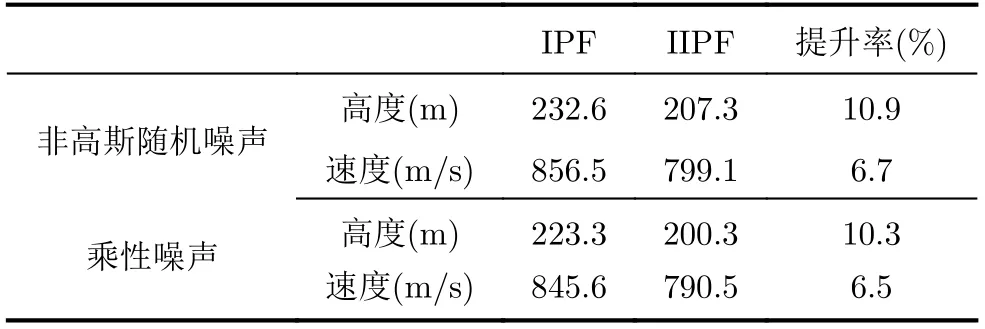
表4 非高斯随机噪声和乘性噪声下多维仿真模型的均方根误差
5 结论
为有效解决粒子退化现象,并提高智能粒子滤波的性能,本文设计了一种重采样新策略:对低权值粒子群体进行自适应处理,根据权值判定是否为底层粒子;底层粒子直接变异,其余低权值粒子根据变异概率进行变异。通过3组仿真实验得出以下结论:
(1) 与PF和IPF等其他算法相比,IIPF具有更好的估计性能,有效粒子个数高于IPF,而运算时间仅略高于IPF;另外IIPF还具有更好的收敛性。
(2) 通过对同一组父代分别进行IIPF和IPF,得到粒子后验分布情况,验证出IIPF后粒子后验分布区域较IPF更为均匀,显著提升底层粒子的利用率,有效地降低了粒子匮乏的影响。
(3) 在非高斯随机噪声和乘性噪声条件下,EKF无法完成系统状态的估计,而IIPF相比于IPF的状态估计性能仍有显著提升,充分证明了遗传重采样改进策略的有效性。
智能粒子滤波仍有改进和优化空间。在以后的研究中可优化粒子分类和变异算子,提高运算效率,进一步降低粒子退化的影响。
猜你喜欢
中学生数理化·七年级数学人教版(2023年3期)2023-03-21
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
趣味(数学)(2020年4期)2020-07-27
支部建设(2020年15期)2020-07-08
飞天(2019年6期)2019-07-08
自动化学报(2017年7期)2017-04-18
自动化学报(2017年2期)2017-04-04
现代电子技术(2016年15期)2016-12-01
百科知识(2015年18期)2015-09-10