
基于深度学习的卫星多通道图像融合的海雾监测处理方法
2022-01-04 10:45黄彬吴铭孙舒悦赵伟崔战北吕成
气象科技 2021年6期
黄彬 吴铭 孙舒悦 赵伟 崔战北 吕成
(1 国家气象中心,北京 100081; 2 北京邮电大学,北京 100876)
引言
海雾是海洋上低层大气中的一种水汽凝结(华)现象,由于水滴或冰晶(或二者皆有)的大量积聚,使水平能见度降低到1 km以下。海雾无论在海上还是在沿岸地带,都因其恶劣的能见度对交通运输、海洋捕捞和海洋开发工程以及军事活动等造成不良影响。由于海雾的以上危害,所以对于海雾的实时监测和预报就显得尤为重要。基于气象卫星的海雾检测的现有方法中阈值法较多,即利用数值反演的方法,这类方法分析出云雾在物理特性上的区别,映射到数据通道上的差别设定不同的阈值进行区分,但需要根据时间和空间条件的不同,设置不同的阈值[1-2]。现有一种方法是使用U-Net深度学习模型构建MODIS多光谱图像的海雾检测模型[3],相比传统阈值方法该模型更加灵活和智能化,提高了海雾检测的准确率,但仅使用了可见光图像,红外通道包含的大气信息并未有效利用,且小块图像处理和简单拼接的方式,使得拼接痕迹明显,对海雾和云边缘的判断仍需改进。另一种方法是基于气象卫星数据(Himawari-8标准数据)[4],将安徽地区卫星图像划分为栅格,使用多通道卷积神经网络(Convolutional Neural Networks, CNN)分别判定每个栅格是否为雾区,但结果对雾的边缘检测不够准确,并且面向的是陆地雾监测。本文提出的基于深度学习的静止气象卫星多通道图像融合的方法能够结合多通道图像特征,使用深度卷积神经网络的深度学习方法实现对渤海和黄海地区的海雾特征检测提取与特征量设计,获得更加精准的海雾监测。
1 数据和处理
1.1 数据介绍
由于渤海、黄海海雾频繁发生,因此对该区域的海雾作为研究对象。采用Himawari-8半小时标准数据,每个时刻包含16通道数据,对应16通道卫星图像。
表1为Himawari-8数据介绍。数据经纬度范围:29.74°~41°N和117.5°~128.76°E。根据2017—2019年《海洋气象学报》中《海洋天气评述》描述的黄渤海区域发生海雾的时间段,选取包含海雾数据的样本[5-7]。
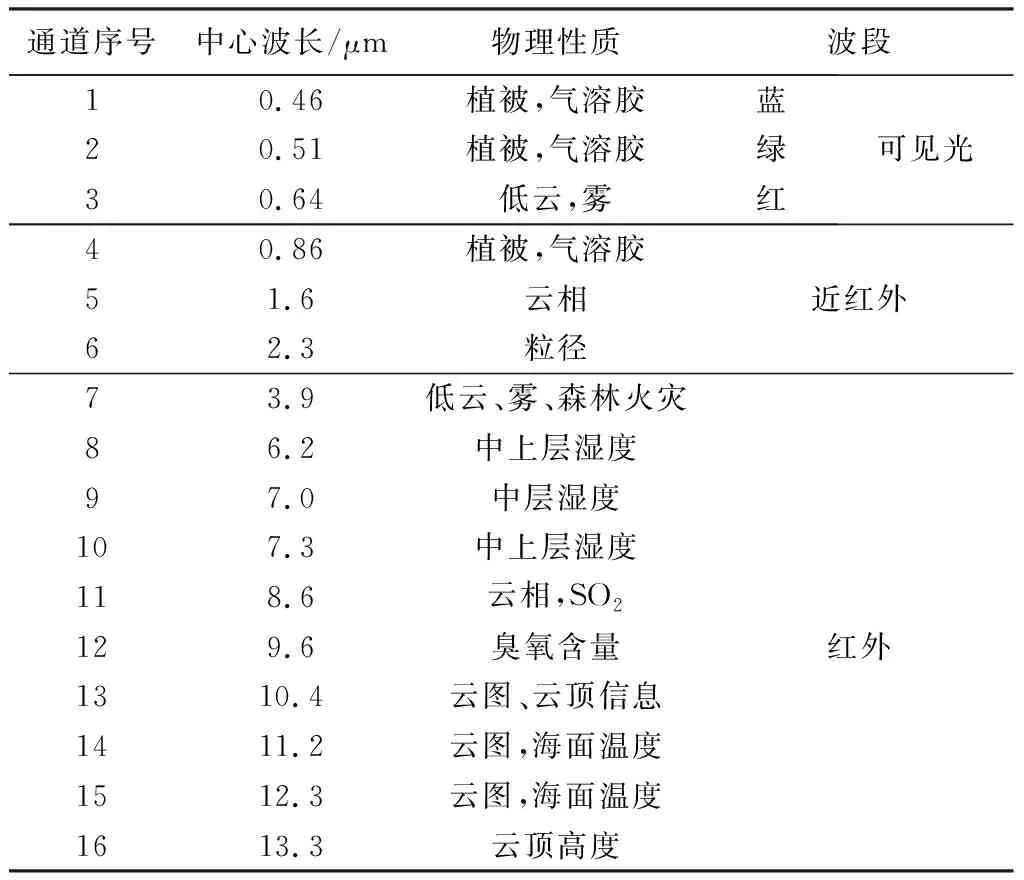
表1 Himawari-8数据介绍
这个数据集包含两部分,图像和标签。图像大小为1024列×1024行,包含16个通道的图像。通过选择3个通道,能够生成彩色图像。对于标签,每个标签大小是1024×1024,其中海雾区域标注为白色,其他区域标注为黑色。对于结果的评价指标有两个,一是均交并比(mIOU),二是观测值检验。在使用第一种评价指标时,我们将2017和2018年有超像素辅助人工标注标签的201个白天图像随机划分成151个有标签的训练图像和50个有标签的测试图像。在使用第2种评价指标时,我们采用的卫星训练数据是2017和2018年有超像素辅助人工标注标签的201个白天图像,采用的卫星测试数据是2019年3月11日至7月20日,共计132 d,每天22张白天图,选取北京时间07:00—17:30,有少量缺失,共2756个时刻图。我们在黄渤海区域选了37个站点,包括海岛和浮标数据,选取的海上观测站数据是能与卫星测试数据时间和区域有交集的数据,其中海上观测站数据的时间间隔为3 h,每天4组数据(北京时间08:00、11:00、14:00和17:00),且缺失值较多,青岛的3个站点数据完整,且数据的时间间隔为1 h,下文统称黄渤海区域和青岛这40个观测站为海上观测站。综上共有海上观测站数据10559个。海上观测站数据不是用来建模,只是用这些观测站的观测值来检验卫星图像结果。
图1为黄渤海区域37个海上观测站点(1~37)和青岛3个观测站点(38~40)分布情况,其中蓝色为海洋,棕色和绿色为陆地,黄渤海区域37个站点标为红色三角,青岛3个站点标为橙色圆圈。表2为观测站点的具体经纬度。
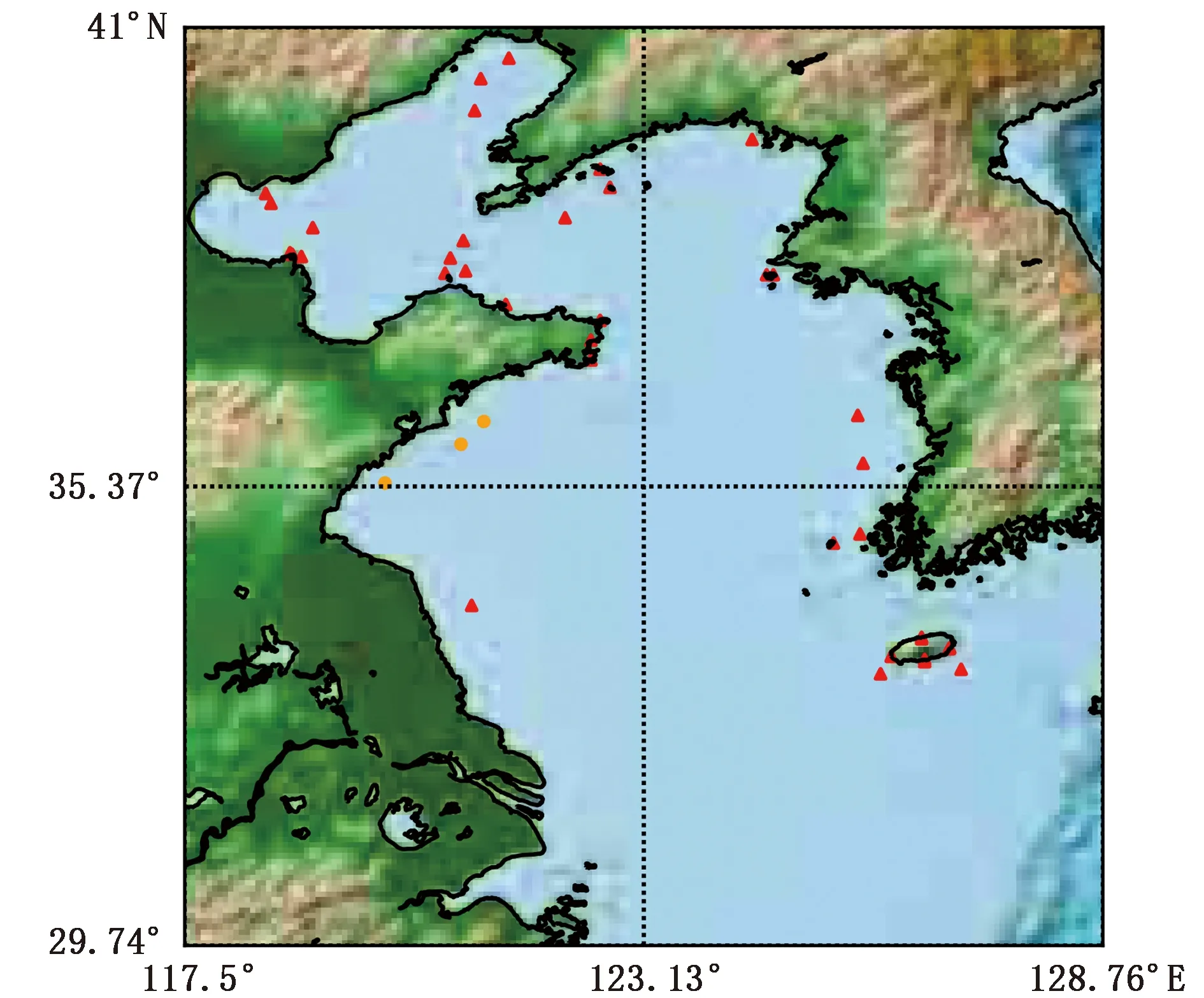
图1 黄渤海区域37个海上观测站点(红色三角)和青岛3个站点(橙色圆圈)(包括海岛和浮标数据)空间分布
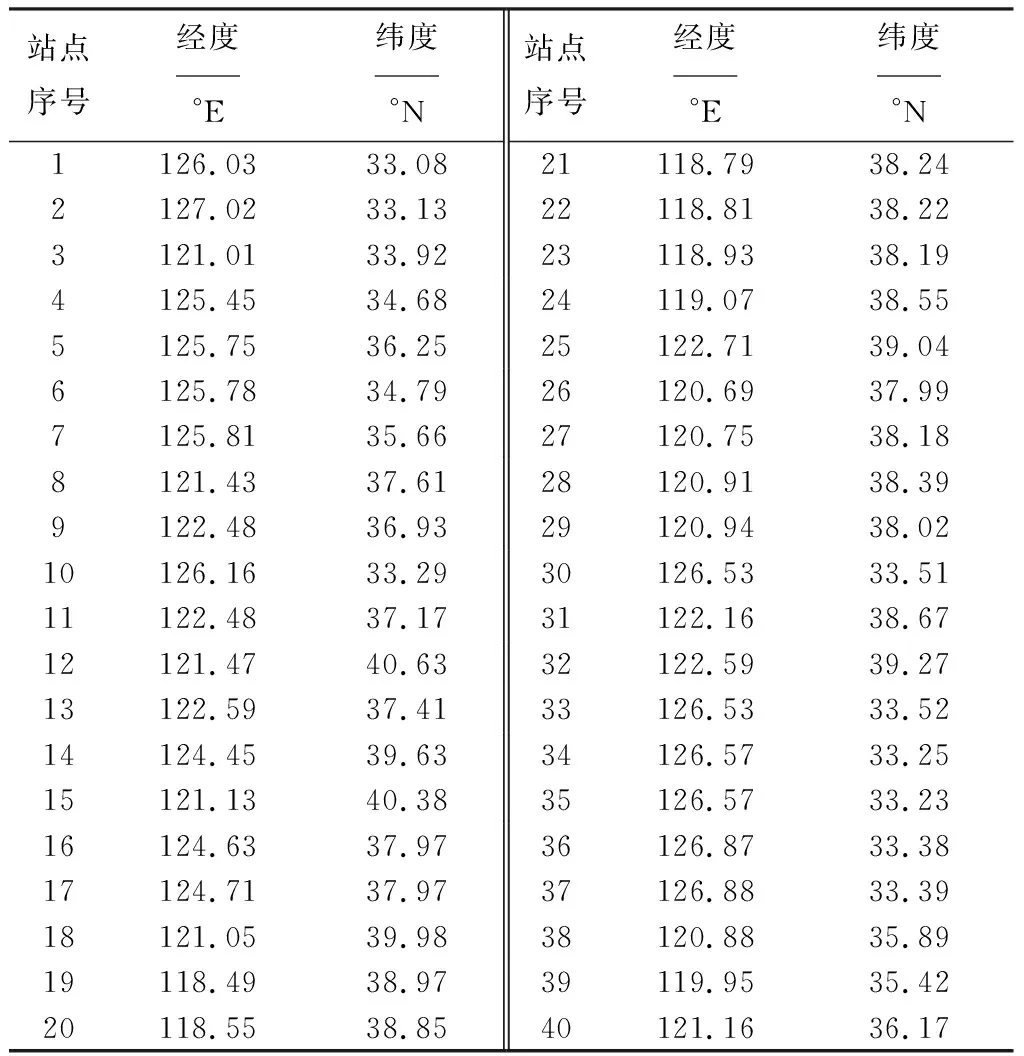
表2 黄渤海区域37个海上观测站点和青岛3个站点经纬度
1.2 图像增强及海雾标签标注
1.2.1 图像增强
Himawari-8数据每个时刻的都有16张图片,每个图片代表一个通道。为了便于专家根据图像特征标注海雾区域,需要选择合适的三通道合成彩色图像,服务于人工解译。我们使用XGBoost[8]对16个通道进行评估。XGBoost可用于主成分分析,能够对所有通道的重要性进行排序,计算出哪些通道对于海雾在图像特征方面特点更加重要。XGBoost可以表示为:
(1)
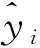
损失函数表示为:
(2)
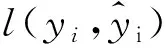
经过了XGBoost对16个通道进行分析后,我们得到16个通道关于海雾检测任务的重要性排序,排名前3的通道依次是3,4,14,因此对于每一个时刻,将这3个通道的数据提取出来,融合为彩色图像,便于专家进行标注。根据表1,选出的排名前3通道中3通道的物理性质包含雾。7通道的物理性质也包含雾,但其中心波长为3.9 μm,介于3.55~3.93 μm之间,这个范围通道在白天的中红外云图上物象间色调的相对变化十分复杂,是图像识别的一大技术难题[9],所以未选用7通道。另外,由于1,2,3通道合成的彩色图像是可见光图片,比较符合人眼的观察习惯,因此也将1,2,3通道合成真彩图片,辅助进行标注判断。图2为1,2,3通道合成的真彩图,图3为3,4,14通道合成的伪彩图。

图2 2018年4月28日03:00(UTC)黄渤海区域1,2,3通道合成图像(黄色矩形框中为海雾,下同)
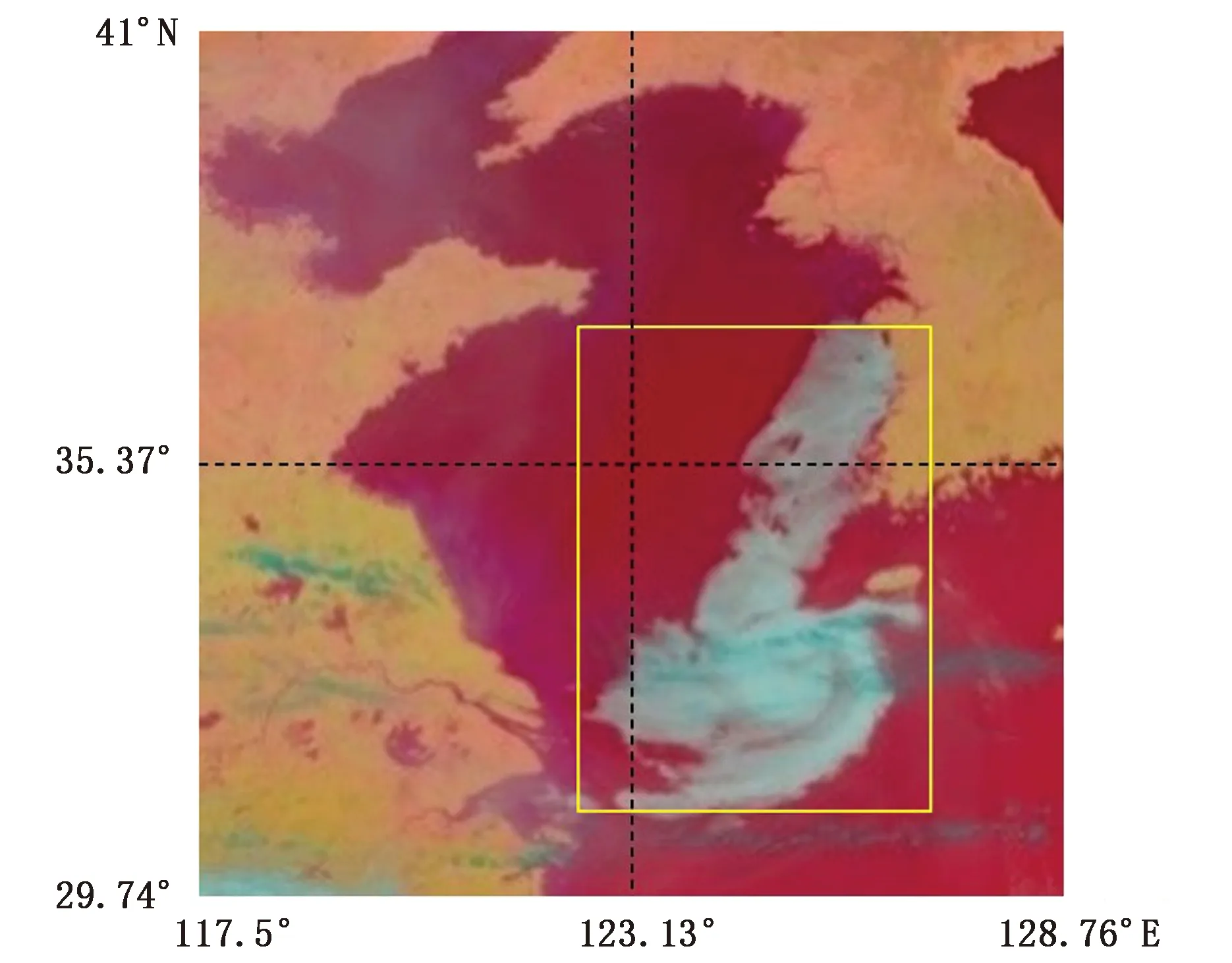
图3 2018年4月28号03:00(UTC)黄渤海区域3,4,14通道合成图像
1.2.2 超像素辅助的人工海雾标注
使用SLIC(Simple Linear Iterative Clustering)超像素算法[10],先对伪彩图做超像素分割,然后基于超像素块做人工海雾标注。超像素自适应的边缘算法非常适合云雾边缘的提取,同时超像素辅助的人工标注与人工边缘提取相比,更为高效,标签也更加精细。
设定每个图像使用SLIC生成300个像素块,决定算法生成超像素块形状的参数设定为4,为了方便标注,我们设计并实现了一个标注工具,将选择超像素图像块的操作内置到标注工具中,可以更加便捷地获取精细标注标签。其中海雾区域标注为白色,其他区域标注为黑色,如图4所示。
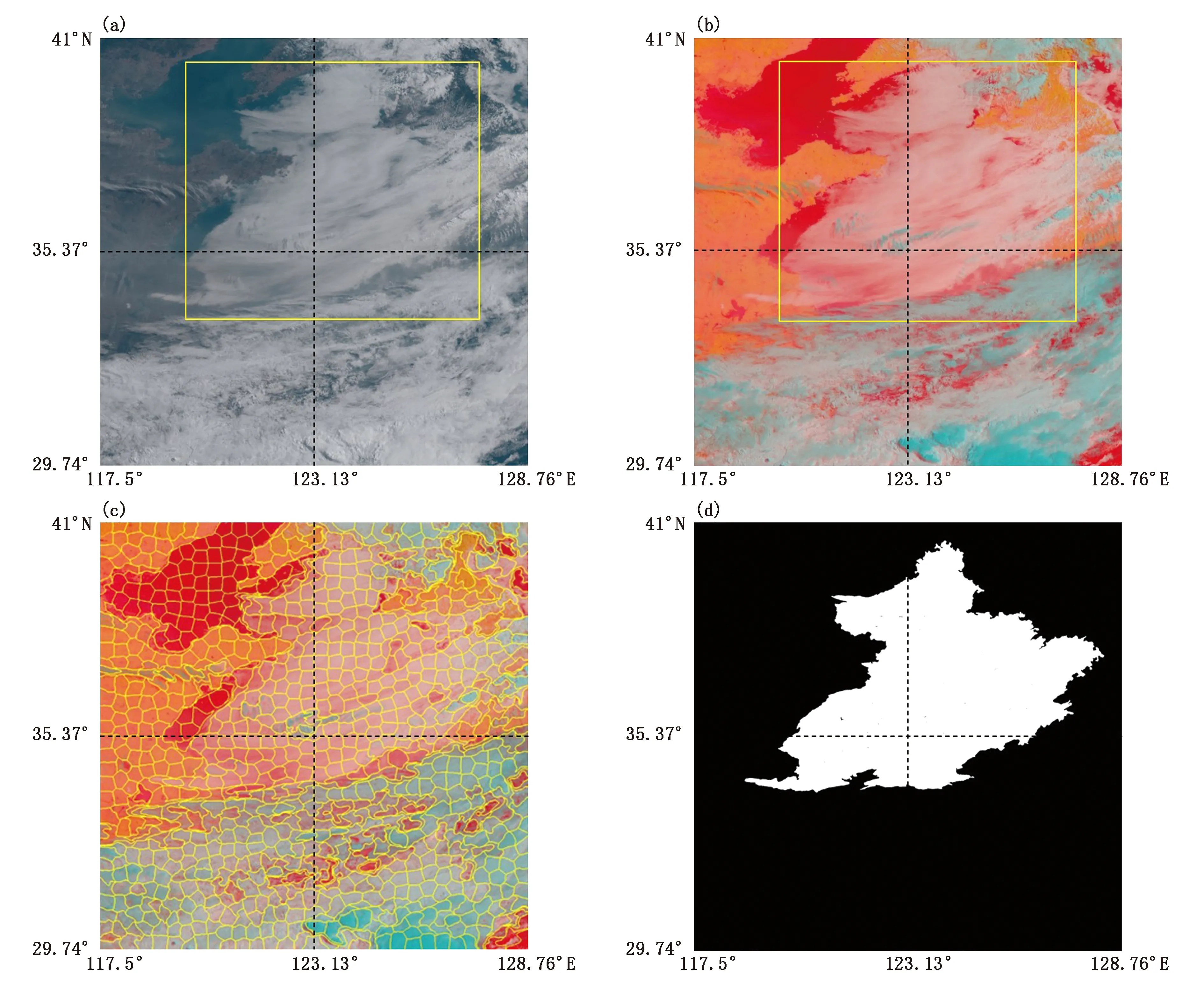
图4 2018年5月29号23:30(UTC)黄渤海区域1,2,3通道原图像(a)、3,4,14通道原图像(b)、超像素算法处理后图像(c)和标注结果图像(d)
2 深度学习海雾检测
2.1 深度学习海雾检测框架
首先使用训练集(151个有标签的训练图像)来训练下面图5中的初步模型,训练300期(epoch)后得到图5中海雾识别模型,再将测试集(50个有标签的测试图像)作为海雾识别模型的输入,海雾识别模型的输出为识别结果,最后对比得到的识别结果与测试集的真实标签,用相应的评估指标来评估海雾识别模型的准确度。
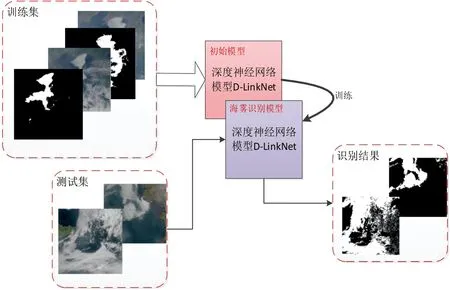
图5 深度学习海雾检测框架
2.2 深度卷积神经网络D-LinkNet
D-LinkNet[11]以LinkNet[12]作为基本骨架,D-LinkNet使用在ImageNet[13]数据集上训练好的ResNet[14]作为网络的骨架,并在中心部分添加带有直接连接的空洞卷积层,D-LinkNet结构如图6所示。
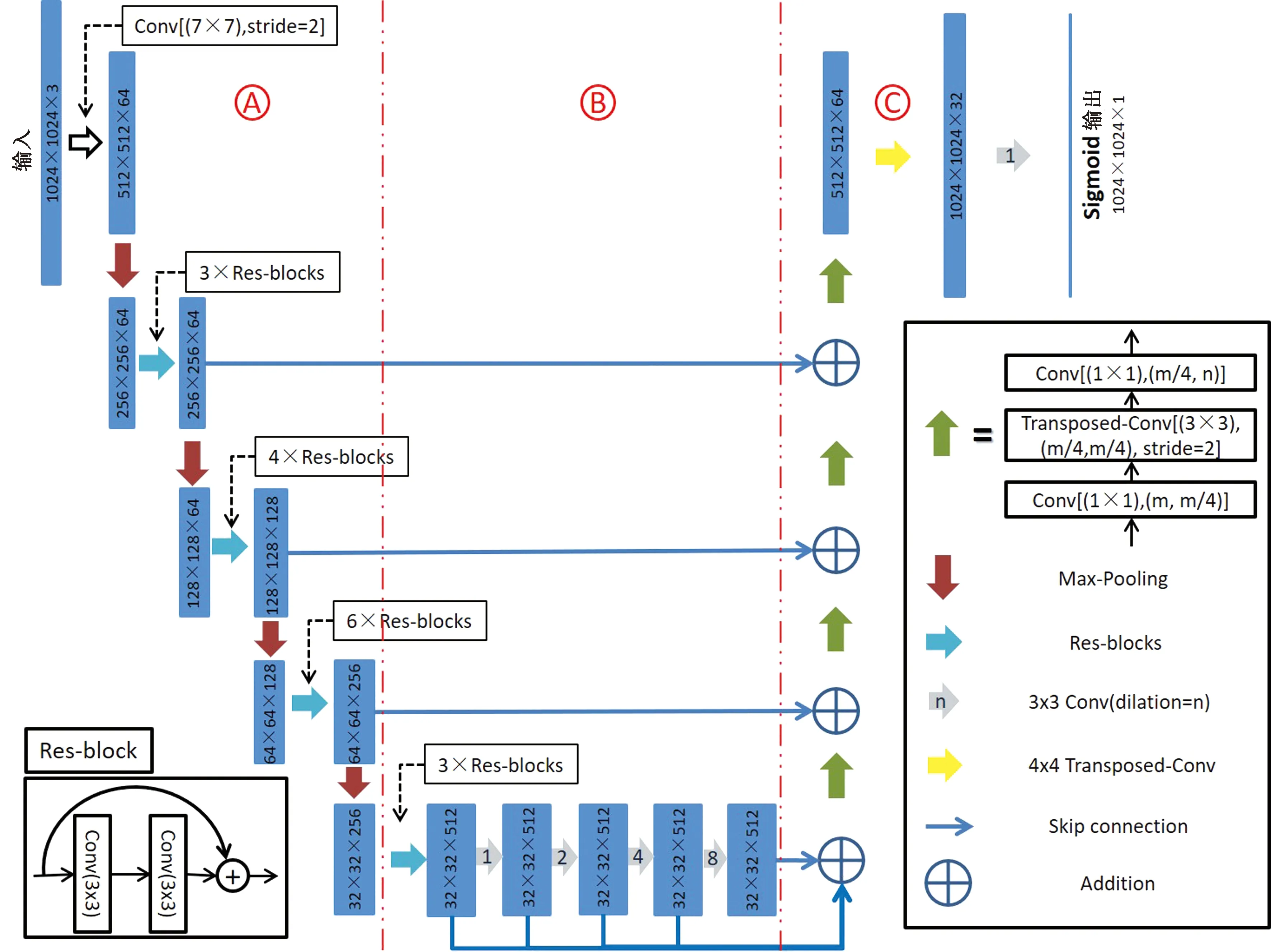
图6 D-LinkNet结构
D-LinkNet的A部分为网络的Encoder,这部分以预训练好的ResNet作为基础。使用ImageNet预训练的ResNet作为初始化可以增强D-LinkNet的表征与泛化能力,同时在训练时可以极大地提升网络的收敛速度。
B部分为网络的中心部分,如图7所示。这部分使用添加捷径连接的空洞卷积,形成串并结合的结构,展开结构见图。B部分展开图分为五条支路,其中每条支路都有不同的深度和不同的感受野大小,从上至下,网络对输入特征图谱的感受野大小分别为31,15,7,3,1,深度为4,3,2,1,0(深度为0表示恒等映射)。这种结构在保持特征的空间分辨率不变的同时,极大地扩增网络中心部分感受野,同时对不同深度、不同广度的特征进行融合,使最后生成的特征图既有足够大的感受野,又有丰富多维的语义信息,且特征尺度不变,没有损失空间上的相对信息。
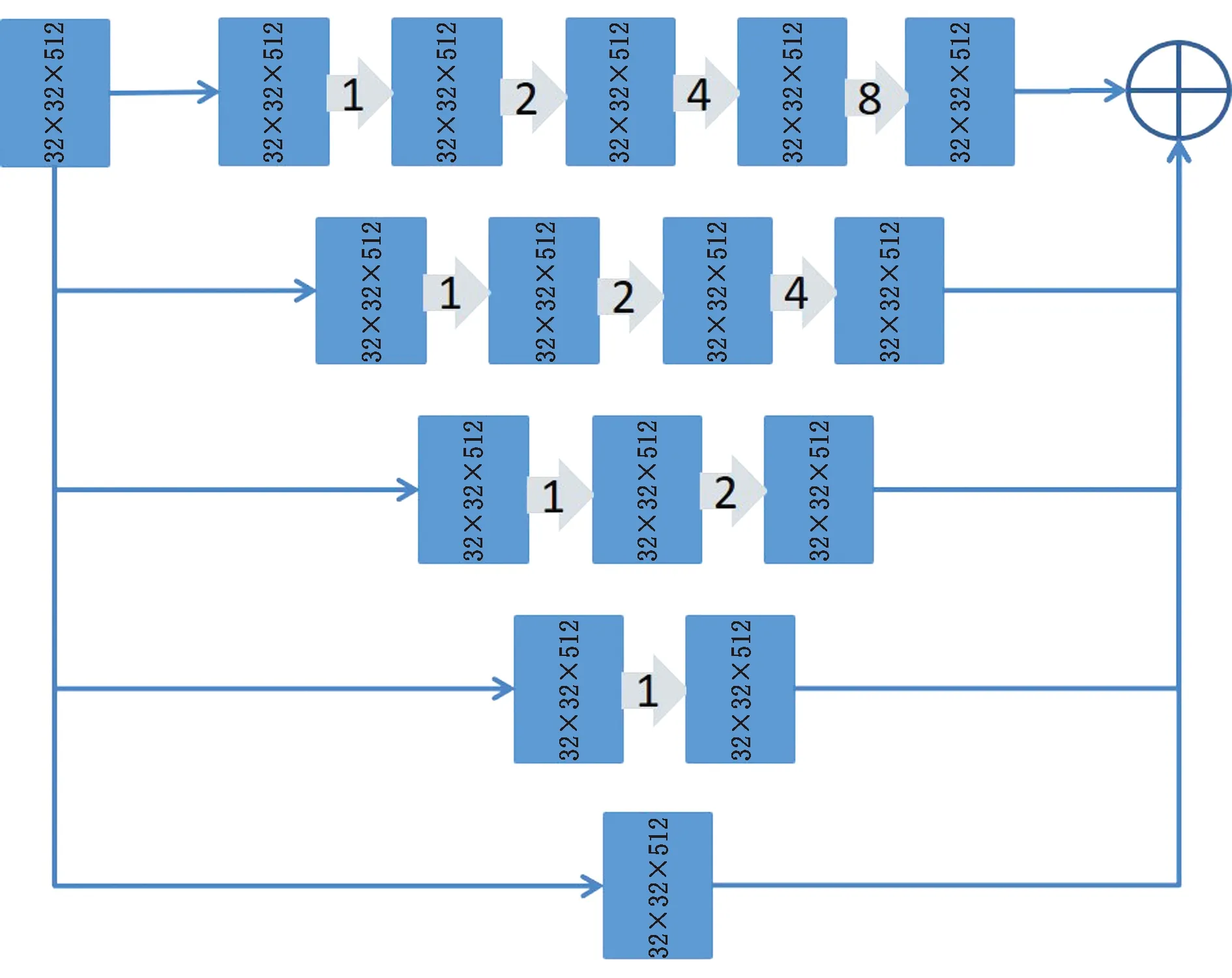
图7 D-LinkNet中心部分展开示意
C部分为网络的Decoder部分,图中绿色箭头部分使用残差网络的瓶颈结构,这种结构通过引入1×1的卷积核来降低整体的计算量,同时可以增加网络中激活函数的数目,提升网络的表征能力。C部分使用转置卷积进行上采样,对特征图谱进行边长32倍上采样,还原出与原始图像相同尺度的语义标签图。
3 试验
3.1 评价指标
选择均交并比(mIOU)和观测值检验作为语义分割结果的评估指标。
mIOU[15]是语义分割的标准度量,其计算两个集合的交集与并集之比。在语义分割问题中,这两个集合是真实值和预测值。其公式可变形为:
(3)
式中:TP为真正;FN为假负;FP为假正。
mIOU是各类IOU求和再取平均,其中IOU是交并比,表示某一类别预测结果和真实值的交集与并集的比值。mIOU的公式为:
(4)
式中:i是真实值;j是预测值;pij表示将i预测成j。
观测值检验,将得到的卫星测试数据结果与海上观测站数据结果进行对比,使用雾区准确率,雾区识别率和检测正确率作为评估指标,其公式为:
(5)
(6)
(7)
式中:mf表示海上观测站观测的有雾数据;sf表示经过我们方法检测显示有雾数据;mn表示海上观测站观测的无雾数据;sn表示经过我们方法检测显示无雾数据;cc表示云覆盖,密不透风的中高云覆盖;ntotal为所有观测样本数;Pa表示雾区准确率;Pr表示雾区识别率;Da表示检测正确率。
雾区识别率没有统计云覆盖情况,因为基于图像,很难识别。
3.2 实现细节
对于mIOU指标,采用的卫星数据是2017和2018年超像素辅助人工标注201幅图像。在训练前,随机划分了151个有标签的训练图像和50个有标签的测试图像。训练图像是16通道(1024×1024×16)的原始图像,我们使用随机旋转和翻转来增强图像。在2张RTX2080Ti上训练D-LinkNet深度卷积神经网络,用Facol Loss[16]和MSE loss相加作为损失函数。其中Focal Loss旨在解决one-stage目标检测器在训练过程中出现的极端前景背景类不均衡问题(如,前景:背景=1:1000),Facol LossFL是由CE loss添加调制因子(1-pt)γ而成,其公式为:
FL(pt)=-(1-pt)γlg(pt)
(8)
(9)
式中:γ≥0为可调的注意力参数;(1-pt)γ为调制因子,该因子可以减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。在本问题中的体现是,对于大部分的样本,海雾区域只占整张图片的一小部分,使用Focal Loss能够让神经网络在训练时更加专注于小部分的海雾。y=1是真实类的标签;p∈[0,1]是模型对标签真实类的估计概率。
MSE loss指的是模型预测值f(x)与样本真实值y之间距离平方的平均值MSE,其公式为:
(10)
式中:yi和f(xi)分别表示第i个样本的真实值和预测值;m为样本个数。
选用Adam[17]作为优化器,学习率设为0.0005,批大小(batch size)设置为4,然后将D-LinkNet网络在训练集上训练300个epoch。
对于观测值检验指标,我们采用的卫星训练数据是2017和2018超像素辅助人工标注图像201张。其他训练步骤与上文mIOU指标一致。
3.3 试验结果
使用基于D-LinkNet深度卷积神经网络的海雾识别模型对卫星数据测试集进行测试,最终在测试集上的mIOU为0.9436。图8中左边是测试集原图,右边是识别结果图,其中黄色矩形框中为海雾,黄色环形区为小块海雾。左右对比得出我们的海雾识别模型不但可以识别出大块海雾且对小块海雾也能较好地识别。

图8 2018年6月21号2:00(UTC)黄渤海区域测试集1,2,3通道原图(a)与识别结果图(b)
统计卫星测试数据结果与海上观测站数据结果,再根据本文3.1节中的雾区准确率,雾区识别率和检测正确率计算公式,计算得出雾区准确率为66.5%,雾区识别率为51.9%,检测正确率为93.2%。最终将数据记录在表3中。
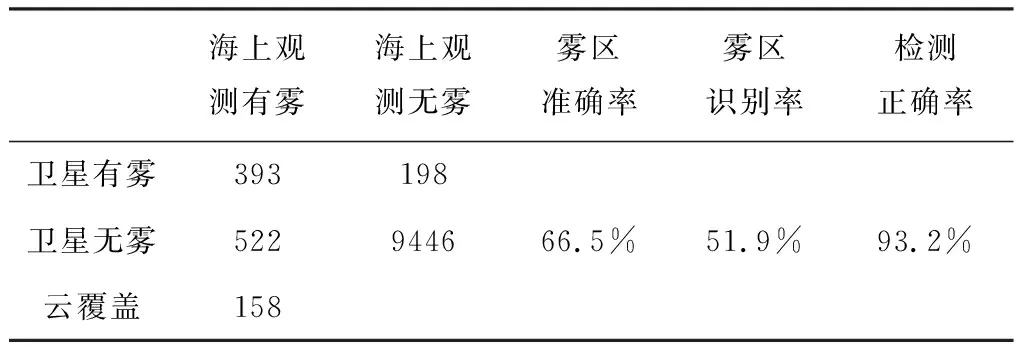
表3 卫星测试数据结果与海上观测站数据结果对比
4 结论与讨论
海雾无论在海上还是在沿岸地带,都因其恶劣的能见度对交通运输、海洋捕捞和海洋开发工程以及军事活动等造成不良影响,因此对于海雾的实时监测和预报就显得尤为重要。本文提出了基于深度学习的静止气象卫星多通道图像融合分割算法,使用基于D-LinkNet深度卷积神经网络的海雾识别模型,选择mIOU和观测值检验作为语义分割结果的评估指标。最终在卫星数据测试集上的mIOU为0.9436,并对比卫星数据测试结果与海上观测站数据结果,得到检测正确率是93.2%,结果表明本文提出的方法能为海雾识别提供一个可靠的参考。与传统阈值方法相比,深度学习方法优点是可以使用卫星16个通道数据作为输入,自动地学习数据特征,缺点是深度学习方法对数据物理意义的可解释性不如传统阈值方法。
综上,基于深度学习的静止气象卫星多通道图像融合分割算法对于海雾监测具有重要的科学意义和应用前景。
猜你喜欢
山东理工大学学报(自然科学版)(2022年5期)2022-08-18
科学导报(2022年39期)2022-07-04
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
优雅(2019年7期)2019-07-03
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
航空学报(2017年5期)2017-11-20
CHIP新电脑(2016年3期)2016-03-10
Coco薇(2015年11期)2015-11-09
