
基于BERT的端到端中文篇章事件抽取
2022-01-01 13:11:04张洪宽王舒怡
中文信息学报 2022年10期
张洪宽,宋 晖,徐 波,王舒怡
(1. 东华大学 计算机科学与技术学院,上海 201620;2. 上海市计算机软件评测重点实验室,上海 201100)
0 引言
近年来互联网快速发展,网络媒体每天产生大量的新闻、公告等非结构化信息。信息抽取技术研究如何从海量的信息中快速有效地捕获有价值的信息,以帮助人们针对特定信息做分析、决策。事件抽取是信息抽取的分支,旨在从非结构化的自然语言文本中抽取出用户感兴趣的事件信息并以结构化的形式展示[1]。事件抽取在很多领域均有广泛应用,如构建事件知识图谱、信息检索、自动问答以及辅助其他自然语言处理任务等。
事件抽取分为开放域事件抽取和限定域事件抽取[2]。开放域事件抽取研究通常没有领域范围限制,事件类型及事件的框架结构未知,主要利用无监督方法从文本中发现事件[3-5]。限定域事件抽取往往针对特定领域(如医疗、金融、司法等)的数据进行建模,识别用户感兴趣的信息。与开放域事件抽取相比,限定域事件抽取有清晰的事件类型定义及对应的事件框架,能够获得具有实用价值的信息,近年来成为研究和应用的热点。
事件抽取从文本粒度上也可分为句子级别事件抽取和篇章级别事件抽取。句子级别事件抽取研究从单个句子中识别所关注的内容,目前主流方法为基于深度学习的方法。首先采用深度神经网络,如动态多池化卷积神经网络[6]、结合LSTM和CNN的卷积双向LSTM神经网络[7]等方法将句子进行嵌入(Embedding)表示,然后识别其中的事件元素和角色。事件及其元素识别通常采用管道式方法,用两个子任务实现,这类方法忽略了任务之间的联系,容易导致错误级联传播问题。针对管道式模型存在的问题,Li等[8]和 Nguyen等[9]采用联合模型捕获实体与事件之间的语义关系,同时识别事件和实体,提高了事件抽取的准确率。
篇章级的事件抽取旨在从整篇文档中识别事件并提取出相应的事件元素,相比于句子级事件抽取,其挑战在于文档中可能存在多个事件,事件元素分布在不同句子中,多个事件之间存在元素重叠(图1)。

图1 文档中存在“临时停牌”与“复牌”两个事件,且共享事件元素“N华盛昌(角色为证券简称)”和“本所(角色为执行方)”。
目前篇章级的事件抽取大多采用管道式方法,如Yang等[10]基于句子抽取结果及文本特征发现核心事件,采用元素补齐策略得到篇章级别的事件信息;仲等[11]在句子级抽取结果的基础上利用整数线性规划进行全局推理,融合共指事件的元素,实现篇章级事件抽取。由于管道模式前序建模产生的错误会传导至后续模型中,研究人员开始探讨端到端的方法。Yang等[12]提出通过采用联合因子图模型来联合学习每个事件内部的结构化信息、篇章内不同事件间的关系和实体信息,但是该工作使用了大量人工特征,不利于领域泛化。
Zheng等[13]采用端到端模型首先识别句子级别的事件元素,再利用二分类策略判定事件类型,然后将元素角色识别转化为有向无环图的生成过程。该方法能够较好地处理单事件单实例和单事件多实例的样本,但在元素分布较分散且存在元素重合的多事件多实例样本上性能略差。针对以上问题,本文在已有篇章级的抽取研究工作基础上,针对限定域的中文文档,提出了基于BERT[14]的端到端事件抽取模型DLEMC(Document-Level End-to-end Model in Chinese),该模型无须将文章按句子分割分别处理,尽可能保留完整的文本,减少信息损失;在事件元素识别中引入了事件类型嵌入增强文本特征,并在元素角色分类中利用注意力机制引入事件类型和实体嵌入表示,以便准确识别事件元素及其在不同事件中的角色。
DLEMC模型分为4层: 输入编码层、事件检测层、事件元素识别层以及元素角色识别层。输入编码层接收输入的文本信息并输出对应的嵌入表示;事件检测层采用多个分类器对同一个文本特征向量进行多标签事件分类;事件元素识别层通过引入事件特征学习不同事件中元素的语义信息,进行事件元素的识别;元素角色识别层利用注意力机制来提高模型对确定事件中每个元素特征的关注度,判断其在对应事件中扮演的角色。最后基于事件的嵌入表示计算余弦相似度,进行主从事件划分及融合共指元素,得到篇章级结构化事件信息。实验证明,DLEMC模型的性能与现有工作相比具有明显的提升。
本文的主要贡献总结如下:
(1) 依据金融领域上市公司公告组织了一个篇章级的事件抽取语料集,并针对该语料定义了事件及事件表示框架。
(2) 提出了篇章级的事件抽取模型,该模型采用端到端方式进行联合学习,同时对事件检测、事件元素识别及元素角色识别进行训练,实验证明了该模型的有效性。
(3) 在事件元素识别中引入事件类型特征,以提高不同类型事件下的元素识别能力。为了更准确地识别多事件文档中的元素角色,我们将事件检测层输出的事件类型及事件元素的嵌入表示作为注意力引入模型的角色分类层,以提高不同事件类型下元素角色识别的准确率。
1 事件定义及表示
随着金融科技的发展,在金融领域每天都有海量的数据产生,金融事件抽取研究能够帮助人们进行金融风险监控、辅助投资决策、大数据分析等。目前该领域的中文事件抽取研究缺乏数据支持,已有相关领域的研究大多没有公开数据集,论文中涉及的事件类型比较集中且类别较少(Yang等[10]4类,Zheng等[13]5类,去掉重复后共5类),为扩充金融领域事件研究的数据,本文组织构建了一定规模的金融领域中文篇章事件抽取数据集,并依据自动内容抽取(Automatic Context Extraction,ACE)定义的事件抽取任务,说明如下。
事件(Event): 在某个时间点或时间段,一个或多个机构的金融产品的状态主动地或被动地发生了变化。
实体(Entity): 语义类别中的一类或一组对象,本文讨论的实体包括命名实体、金融产品、时间和数值。
事件元素(Event argument): 在事件中具有特定作用的实体。
元素角色(Argument Role): 事件元素在事件中承担的角色。
针对本文研究的金融公告信息,事件定义为: event=def(T,O,F,D,N)。
其中T为事件类型,共计11类,O、F、D、N为事件中的4类角色,分别表示组织机构、金融产品、时间、数值,每一类下有若干小类,共计22类事件角色。
(1) 事件类型,事件所属的类别,如“临时停牌”“复牌”“上市交易”等。
(2) 组织机构,参与事件的一类实体,如“东沣科技集团股份有限公司”。
(3) 金融产品,金融领域中的相关产品,如“证券名称”“证券简称”。
(4) 时间,指事件发生的具体时间点或者事件持续发生且产生作用的时间间隔,如“10时00分01秒”。
(5) 数值,衡量事件中某一属性具体量的多少,如“票面利率4%”“标准交易单位10张”等。
其中,事件类型、组织机构、金融产品和时间的实例在事件文本中一定会出现,数值实例不一定会出现。
2 事件抽取模型DLEMC
篇章级事件抽取研究识别文档中存在的事件和相关元素,并判断元素在事件中扮演的角色。给定文档集doc={s0,s1,…,sNs},每篇文档包含标题句s0和内容句{s1,…,sNs},Ns为句子数量。模型DLEMC首先对文档标题和内容分别进行事件检测,得到文档包含的事件类型{t0,t1,t2,…},其中t0为标题中的事件,其他为内容中的事件,然后识别出文档内容中每类事件的相关元素{e1,e2,…}及每个元素对应的角色{role1,role2,…}。
DLEMC模型由4部分组成(图2),包括输入编码层、事件检测层、事件元素识别层和元素角色识别层。
输入编码层基于BERT对输入的句子进行编码,得到句子对应的向量以及句子中每个token的向量。
事件检测层将编码层输出的句向量作为输入,预测该句中包含的事件,一个句子中可能存在多个事件。
事件元素识别层识别句子中参与事件的实体。将句子的token向量与事件类型对应的向量进行拼接作为输入,预测每个token对应的BIO标签,从而识别出事件元素对应的实体。
元素角色识别层对上一步识别出的确定事件类型下的实体进行角色分类。将事件类型t和实体e对应的嵌入表示求平均之后作为注意力的查询向量,重新计算token的向量表示,再对每个事件元素的角色进行识别。
模型训练时分别计算事件检测层、事件元素识别层以及元素角色识别层的损失,并将三者求和作为模型最终的优化目标。
2.1 输入编码层
本文采用预训练语言模型BERT对文档进行编码,考虑BERT模型的有效位置编码序列长度以及实际训练的模型规模,我们设置最大序列长度max length。对于给定的文档,将标题作为独立的句子;对于文档内容,若文本序列长度大于max length,则依据中文标点符号将其切分成多个句子,反之则将整篇文档作为一个句子。
经过以上处理,本文将一篇文档表示为一系列句子集合doc={s0,s1,…,sNs},Ns为句子总数,sj为文档中第j个句子,s0为文档标题句。每个句子表示为 {tok1,j,tok2,j,…,tokNw,j},Nw为句子中token序列的长度,tok1,j为第j个句子中的第1个token,每个句子经BERT编码后得到的token向量序列为Htok={h1,j,h2,j,…,hNw,j},其中,hi,j为第j个句子中第i个token对应的向量,维度为d,句子向量序列为{h0,h1,…,hNs},h0为标题句向量表示,hj为文档中第j个句子的向量表示,维度为d。
2.2 事件检测层
事件检测的目的是检测句子中包含的事件,本文的数据集样本中可能存在多个事件,受Liu等[15]启发,我们将事件检测建模为多标签分类任务。事件检测样本的标注形式如表1所示。

表1 事件检测数据标注实例
其中,s为句子,t1、t2为不同的事件类型,标签为1表示句子s中包含事件t1,标签为0则表示句子s不包含对应的事件。
对于给定文档的句子向量表示{h0,h1,...hNs},我们依次将文档中的句子向量作为全连接层的输入,如式(1)所示。
Hed=Wedhj+bed
(1)
其中,Wed为参数矩阵,bed为偏置,hj为第j个句子sj的隐层向量表示。对所有事件类型使用sigmoid分类器进行分类,式(2)给出了对某类事件预测的计算方法。
(2)
此层的预测错误使用交叉熵作为损失函数,如式(3)所示。
(3)
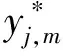
2.3 事件元素识别层
本文将事件元素识别建模为序列标注任务,使用BIO标签模式(Begin: 字段开头,Inside: 字段内部,Outside: 其他字段)为每个token赋予一个实体标签。
对于给定文档中的句子sj,首先通过事件检测层预测得到对应的文档标题事件和文档内容事件,然后依次识别文档内容中每个事件的相关元素。为提高不同事件类型下实体的语义表示,本文在实体识别部分引入事件特征。具体做法如下: 为每种事件类型定义d维(与token向量维度相同)的向量,通过查表的方式得到事件类型对应的向量tvec,我们将句子中的每个token向量与事件类型向量tvec进行拼接作为最终的特征向量,式(4)为计算某token的特征向量。
hvce.i=hi,j⊕tvec
(4)
hi,j为第j个句子中第i个token的向量表示,hvce.i为句子中第i个token最终的特征向量,⊕表示拼接,将特征向量hvce={hvce.i,hvce.2,…,hvce.Nw}作为全连接层的输入,使用softmax分类器预测每个token对应的标签,如式(5)所示。
P=sofmax(WnerHvec+bner)
(5)
Wner为参数矩阵,bner为偏置。使用交叉熵计算该部分的损失,如式(6)所示。

(6)
N为样本总数,K为标签类别总数,第i个样本预测为第K个标签的概率为Pi.k,第i个样本真实的标签为yi.k。
2.4 元素角色识别层
元素角色识别的目标是为确定事件类型下的实体赋予预定义的事件角色,本文将角色识别建模为多分类任务。为更好地区分实体扮演的角色,将利用注意力机制来增强文本的特征表示,依次判断每个实体在事件中扮演的角色。
实体往往包含多个token,对于给定句子sj中识别出的实体集E={e1,e2,…},其中每个实体包含该句中的第i至第k个token,[toki,j,…,tokk,j]。本文取实体中的所有字符向量的均值作为该实体的嵌入表示c,维度为d,采用这种均值向量可以有效避免模型过拟合问题[16]。计算如式(7)所示,hi,m为第m个句子中的第i个token。
(7)
然后,我们将Evec中的第m个实体的向量表示cm与包含该实体的事件类型对应的向量表示tvec进行相加再求平均得到维度为d的注意力机制查询向量q,如式(8)所示。
(8)
最终得到查询向量集合Q={q1,q2,…},使用q与当前句子sj中的每个token向量计算得到注意力值αk,计算如式(9)所示。
(9)
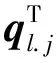
V=a*Htok
(10)
将V作为全连接层的输入,使用softmax分类器进行分类,如式(11)所示。
y*=softmax(WrtV+brt)
(11)

(12)
2.5 模型训练
我们将事件检测、事件元素识别以及元素角色分类同时进行训练,模型的训练目标是综合3部分的损失达到最小,训练时分别计算事件检测层的二分类交叉熵损失Led,以及事件元素识别层与元素角色分类层的多分类交叉熵损失Lner与Lrt,我们将3个损失求和作为模型最终的优化目标:Lfinal=Led+Lner+Lrt。
模型训练时采用Adam[17]作为优化器,通过验证集选择最好的模型进行预测。
3 主从事件识别
文档中包含多个事件时,将根据标题事件进行主从事件划分,然后对同指事件元素进行融合,从而得到篇章级事件抽取结果。文档标题往往能概括一篇文档的主要内容,故本文将文档标题中的事件作为主事件,其他事件作为从事件。
对于文档中的事件集Events={e0,e1,e2,…},其中,e0为文档标题预测出的事件,其他的均为文档内容预测出的事件。事件类型以及事件元素使用从DLEMC模型中获得的嵌入表示,基于余弦相似度计算两个事件的相似程度,如式(13)所示。
obj=sim(e0,ei)
(13)
obj为相似度得分,用于衡量e0与ei两个事件的共指程度,我们取最高得分对应的那组事件作为文档的主事件,其他事件为从事件。
主从事件融合的目的是对同一个文档里多个事件之间的共指事件元素进行合并,从而得到规范的篇章级事件信息。本文通过计算不同事件中事件元素的语义相似度来衡量它们的共指程度,具体规则为: 语义相似度超过设定阈值γ的事件元素作为共指元素,否则为非共指元素。两个事件中不同元素的相似度基于余弦相似度计算,如式(14)所示。
score=sim(t1,i,t2,j)i,j∈{1,2,…}
t1,i,t2,j∈(T,O,F,D,N)
(14)
其中,t1,i与t2,j分别表示事件e1的第i个元素与e2的第j个元素,score为计算得到的语义相似度的得分,若该得分大于阈值γ,就将该项对应的两个事件元素合并。
4 实验
4.1 数据集
本文将从互联网上搜集的上市公司公告作为实验数据集。共有文档总数23 067,其中5 056个文档中包含多个事件,占比21.9%,将总文档按照8:1:1划分成训练集、验证集和测试集,数据集中标注的实体类别包括NUM(Number,数值)、ORG(Organization,组织机构)、FIN(Finance,金融产品)、TIM(Time,日期、时间)。事件分为11类: 上市交易、临时停牌、停牌、复牌、摘牌、名称变更、支付利息、债券转让、暂停上市、终止上市、到期兑付。各类样本数如表2所示。

表2 数据集样本统计
为了验证远程监督标注事件的质量,我们从每类事件中随机选取20个样本进行人工标注,作为真实值,再用远程监督方法标注它们作为预测值,依据4.2节中的评价指标进行验证,如表3所示,远程监督方法标注的语料具有较高的精确率,以及不错的召回率和F1值,可以作为人工标注的一种替代方法。

表3 远程监督事件标注质量 (单位: %)
4.2 模型评价
本文采用精确率(Precision,P)、召回率(Recall,R)和F1(F1-score,F1)值作为评价指标,一个事件类型与某一事件元素及其角色为一个统计项。在事件类型预测正确的前提下,若事件元素及其对应的角色均与标注相同则视为正确,否则视为预测错误,若事件类型预测错误则将所有的元素与角色均视为预测错误。具体计算如式(15)~式(17)所示。
(17)
4.3 超参数设置
本文的实验基于BERT_base模型来初始化词向量,维度为786,dropout的比率为0.4,batch size为16,模型学习率为3e-5,训练10个epoch,最大文本序列长度max length为200,
事件类型向量随机初始化生成,维度为768。
4.4 结果分析
为验证本文方法的有效性,我们和一些基准方法进行了比较。它们分别是DCFEE[10]和Doc2EDAG[13],以及基于BERT的管道模型BERT-P。在BERT-P中事件检测部分与本文提出的方法DLEMC相同,但在实体识别任务中未增加事件特征,在角色分类任务中未利用事件和实体特征注意力,DLEMC-P为DLEMC的管道模式。我们将DCFEE、BERT-P和Doc2EDAG作为本文的baseline,在包含全部11类事件的测试集上进行各项测试。
(1) 为验证本文的模型DLEMC在事件类型检测上的有效性,我们在测试集上对模型进行了评价,实验结果如表4所示。

表4 事件类型检测评价结果 (单位: %)
表4中看出,利用序列标注识别事件触发词DCFEE模型效果比较差。通过分类模型检测事件的BERT-P、DLEMC-P、DLEMC、Doc2EDAG模型在各项指标上均优于DCFEE,其中端到端联合学习模型DLEMC、Doc2EDAG在各项指标上均优于管道式模型。本文提出的DLEMC模型在准确率上略低于采用二分类策略的Doc2EDAG模型,但召回率和F1值均优于Doc2EDAG,其中F1提高了0.2%,实验表明,多标签分类模型在多事件检测中有较好的表现。
(2) 为验证模型在篇章事件元素识别和角色分类时的有效性,我们在测试集上对模型进行了评价,实验结果如表5所示。

表5 篇章级别事件抽取评价结果 (单位: %)
由表5可以看出,基于预训练语言模型BERT词向量表征的事件抽取模型BERT-P明显优于使用Word2Vec[18]的DCFEE模型。本文提出的DLEMC模型则在P、R、F1等3个指标上都优于BERT-P,其中F1值提升了4.1%。
DLEMC-P保留增强的文本嵌入表示,但采用管道式方法完成事件抽取的子任务,实验表明其在准确率上有提升,但是召回率上大幅下降,但F1值仍然比直接基于管道的BERT-P提升了1.5%。端到端模型Doc2EDAG和DLEMC在准确率上略低于DLEMC-P,但召回率和F1值较管道式方法均有大幅提升。得益于DLEMC在实体识别部分加入事件类型特征,在角色分类部分加入事件类型与实体注意力特征,本文的DLEMC在各项指标上均优于Doc2EDAG。
(3) 为了验证DLEMC在处理多事件时的有效性,我们将数据集划分为单事件(S-Event)与多事件(M-Event)两个子集,并分别用这两个子集对模型进行评价,实验结果如表6所示。

表6 单事件与多事件评价F1值与平均值 (单位: %)
表6中的实验结果表明,DCFEE中的基于核心事件进行元素补全策略存在局限性,不能较好地处理多事件样本。而BERT-P以及DLEMC-P基于优秀的词嵌入方法,提高了特征表达能力,在单事件和多事件样本上性能均有较大改善,但由于管道模式不可避免地将前序任务中的错误信息传递至后序任务,模型的整体性能低于端到端的模型Doc2EDAG和DLEMC。实验表明,对于被分割的样本,DLEMC有效增强了文本中的事件特征表示,提高了在同一类型事件的多实例和不同类型事件的多实例情况下的性能,其在单事件和多事件评价上均优于Doc2EDAG。
为得到完整的结构化篇章事件信息,我们在DLEMC事件抽取结果的基础上对包含多个事件的文档进行了主从事件划分和主从事件元素融合,实验结果如表7、表8所示。

表7 主从事件划分评价结果 (单位: %)

表8 主从事件元素融合评价结果 (单位: %)
由表7可看出,主从事件划分的效果是可接受的,由于主从事件划分依赖事件检测的结果,使得该部分仍具有较大提升空间。
表8给出了对正确识别且角色判定正确的事件元素进行同指事件元素融合实验的评价结果。事件元素融合的性能受到句子级事件抽取结果的影响,导致最终的性能指标偏低。
5 相关工作
目前事件抽取方法可以分为两类: 基于模式匹配方法和基于统计学习方法。模式匹配方法[19-20]在特定领域有较高的准确率,但是通常需要编写大量的人工模板,且普适性较差。统计学习方法可以分为两类:传统的基于特征工程的机器学习方法以及基于深度学习的方法。传统特征工程主要依赖自然语言处理工具获取有效的特征(如句法、词汇、词性等),然后利用传统的分类模型(如最大熵、支持向量机)进行分类[21-22]。基于深度学习的方法依靠神经网络自动提取特征,在事件抽取中取得了不错的效果,如吴[23]使用一种混合神经网络模型进行实体和事件的联合学习;Chen[6]使用一种动态多池化卷积神经网络来捕获多个特征,提升了事件抽取的性能。Zeng[7]使用一个卷积双向LSTM神经网络分别从词级别和字级别进行触发词和实体的识别。
事件抽取任务依据是否具有预定义的事件框架(事件类型及每类事件对应的角色)可以分为开放域事件抽取和限定域事件抽取,开放域事件抽取目标在于识别自然语言文本中的事件,一般没有领域限制,不需要预定义事件框架。限定域事件抽取会预先定义好要抽取的事件类型,如“袭击”事件、“审判”事件等,同时也会定义每类事件参与者的角色,如“审判”事件中包含“被审判人”“审判时间”“地点”等角色。
从文本粒度来看,目前事件抽取的相关研究主要集中在句子级,即识别句子中的事件并提取相应的事件元素[7]。句子级事件抽取主要有两种建模方式,管道方式和联合方式。管道式方法通常将事件识别和元素提取分为两个独立的任务,忽略了事件与元素之间的联系,导致效果不够理想。联合模型一般同时识别句子中的事件并提取相关元素,利用深度神经网络捕获事件与元素之间的语义联系,模型训练时能够互相影响并优化,性能一般要优于管道式模型。
现实中的文本信息往往是以篇章形式出现的,针对篇章级事件抽取能够获得更完整、规范的信息。篇章级的事件抽取研究方法通常首先对给定文档中的句子进行处理,然后再对句子级的事件信息进行合并,从而得到篇章级的事件抽取结果。目前篇章级的事件抽取大多采用管道式模型,如仲等[11]采用触发词和实体联合标注的方法同时抽取句子级的触发词和实体,然后使用多层感知机对实体进行角色分类,并利用整数线性规划进行同指事件的融合,实现篇章级的事件抽取。Yang[10]基于句子抽取结果以及文本特征发现主事件描述,并利用上下文元素补齐策略得到篇章事件结构化信息。
总体来讲,目前篇章级的事件抽取研究较少,且集中在特定领域,通常依赖大量人工规则,难以进行领域拓展。而句子级的事件抽取日趋成熟,应用领域更广,但得到的结果无法提供较好的篇章级事件信息。
6 总结与展望
本文针对金融领域篇章级事件抽取任务定义了事件表示框架,在该框架下提出基于深度学习的端到端模型抽取事件信息,模型用3层分别实现多标签分类的事件检测、基于融合事件类型特征的事件元素识别以及基于注意力机制的元素角色分类。对获取的多个事件,利用余弦相似度进行主从事件划分以及多事件的元素融合,得到篇章级事件结构化信息。我们构建了金融领域事件抽取语料对本文方法进行验证,实验证明本文方法明显优于基准方法。
由于事件元素之间存在较强的相似性,如“上市交易”事件中的“股份总数160 000 000股,其中40 000 000股自上市之日起开始上市交易”,模型可能会将“股份总数”与“上市股数”错误分类。如何提高相似元素的特征表示及其分类效果,从而提升篇章级事件抽取的整体性能,是未来的改进方向。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中国新闻周刊(2021年26期)2021-07-27 04:02:12
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中国外汇(2019年18期)2019-11-25 01:41:54
哲学评论(2017年1期)2017-07-31 18:04:00
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
信息安全研究(2016年4期)2016-12-01 06:06:54
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
新高考·高二数学(2015年11期)2015-12-23 18:17:44
