
基于Beta分布和半监督学习的非确定性知识图谱嵌入模型
2022-01-01 13:18:58何世柱
中文信息学报 2022年10期
徐 遥,何世柱,刘 康, 张 弛, 焦 飞, 赵 军
(1. 中国科学院 自动化研究所,北京 100190;2. 中国科学院大学,北京 100049;3. 国网天津市电力公司电力科学研究院,天津 300384;4. 中国电力科学研究院有限公司,北京 100192)
0 介绍
知识图谱是人工智能领域的重要资源,其以实体、关系等符号描述了世界中的丰富知识,这类结构化的知识表示对问答系统、推荐系统等应用具有重要价值[1]。近年来,知识图谱在工业界和学术界均得到了广泛的研究,但是符号化的知识表示不利于知识推理、知识问答等应用。为此,人们提出并研究知识图谱嵌入(Knowledge Graph Embedding,KGE)技术,它旨在将实体和关系映射到低维向量空间的同时保留它们的语义信息,这类数值化的知识表示方式更便于高效的语义计算[2]。
目前,面向确定性知识图谱的嵌入技术研究较多,在知识图谱补全等任务中取得了较好效果。但是,现实世界中大量知识是具有不确定性的,例如,在常识知识图谱ConceptNet[3]中,事实“(dog, CapableOf, bark)”(狗能叫)的确定性远大于事实“(dog, UsedFor, guard a house)”(狗可以用来看家)。根据是否考虑事实的不确定性,知识图谱可以分为确定性知识图谱和非确定性知识图谱。相比确定性知识图谱,非确定性知识图谱中每条事实都拥有一个置信度,它用来表示该事实成立的可能性[3]。例如,ConceptNet中事实“(dog, CapableOf, bark)”和“(dog, UsedFor, guard a house)”的权重分别为16.0和2.0。
近年来,虽然面向确定性知识图谱的嵌入模型在各种任务中取得了长足的进展,但是如何设计和训练面向非确定性知识图谱的嵌入模型仍然是一个重要挑战。实际上面向非确定性知识图谱的嵌入模型具有重要意义[4],一方面,在知识应用方面,不确定性事实的建模能够辅助模型辨识不同置信度的知识,进而增强知识图谱驱动应用的效果;另一方面,不确定性是世界知识的常态现象,使用不确定性的知识训练模型更符合人类的思维模式。具体来说,知识图谱中知识内容(事实)的不确定性主要有以下两个来源: ①知识图谱构建和自动抽取过程中产生的噪声; ②知识内容本身存在不确定性,尤其是在医疗、金融等领域,大量知识不是确定性的,其成立与否与具体环境密切相关。
虽然TransE[5]、DistMult[6]等模型在确定性知识图谱上取得了很好的效果,但是它们难以直接应用于非确定性知识图谱,主要原因包括: ①数据存在噪声,由于存在大量低置信度三元组,非确定性知识图谱中的噪声含量更多。例如在CN15K中,有7%的三元组置信度小于0.2,这些低置信度三元组很有可能是噪声。传统的知识图谱嵌入模型认为所有三元组都是正确的,因此在高噪声环境下会学习到不准确的图谱表示,从而给出错误的推理结果。②置信度难以计算,确定性知识图谱嵌入模型一般采用Margin Loss[5]作为损失函数,旨在使正负例得分差异尽可能大,但可能导致不同关系类型对应着的三元组的得分差异较大,而且得分范围一般不在[0,1]范围内,因此确定性知识图谱嵌入模型无法直接计算三元组的置信度。③开放世界假设(Open World Assumption,OWA)[7],在该假设下,不存在于知识图谱中的事实,也有可能是正确的。非确定性知识图谱因为存在大量低置信度事实而更加稠密,故负采样常常会引入更严重的假负样本问题,也就是在训练过程中将知识图谱缺失的正确事实错误地当作置信度为0的负例。而现有的非确定性知识图谱嵌入模型UKGE[4]结构较为简单,只能处理对称关系,无法很好地处理假负样本问题。
为了解决上述问题,我们首先提出了一个用于训练非确定性知识图谱嵌入模型的统一框架,该框架通过使用基于多模型的半监督学习方法可以很好地处理假负样本问题。该框架主要包含以下两个模块: ①半监督样本置信度估计模块,该模块结合多个训练好的模型的预测结果给半监督样本(通过受限负采样得到三元组)估计一个合理的置信度,而不是直接视其为错误的,从而解决假负样本的问题。②置信度计算模块,该模块为所有确定性知识图谱嵌入模型提供了统一的分数映射函数,即对原有分数进行统一的线性变化和映射,使原来的得分函数转化为置信度计算函数,从而将已有的确定性知识图谱嵌入模型转化为面向非确定性知识图谱的嵌入模型。同时,为了解决半监督学习中半监督样本噪声过高的问题,我们使用蒙特卡洛Dropout(Monte Carlo Dropout)[8]根据多个模型的多次预测结果计算出模型对预测结果的不确定度,并根据该不确定度有效过滤半监督样本中的噪声数据。
此外,为了更好地表示非确定性知识图谱中实体和关系的不确定性以处理更复杂的关系,本文还提出了基于Beta分布的非确定知识图谱嵌入模型UBetaE(Uncertain Knowledge Graph Beta Embedding)来对非确定性知识图谱进行嵌入,即将实体、关系均表示为一组相互独立的Beta分布,并通过概率分布的相似度来表示非确定性知识图谱中的不确定性。
我们在公开的ConceptNet数据集上进行了大量的实验,实验结果表明,本文所提出的UBetaE模型明显优于UKGE等当前最优的非确定性知识图谱嵌入模型。在结合UBetaE模型和半监督学习后,不仅能极大缓解传统方法中存在的假负样本的问题,还使得置信度预测的均方差损失(Mean Sguare Error,MSE)值从8.61下降到7.20(MSE值越小越好,降低了16.4%)。
综上,本文的主要贡献包括:
(1) 本文设计了一个用于训练非确定性知识图谱嵌入模型的统一框架,该框架能够方便地将已有的确定性知识图谱嵌入模型转化为面向非确定性知识图谱的嵌入模型。
(2) 本文提出了一种基于Beta分布的非确定性知识图谱嵌入模型UBetaE,它能更好地表示非确定性知识图谱中实体和关系的不确定性以处理更复杂的关系。
(3) 本文提出使用半监督学习方法训练非确定性知识图谱嵌入模型,通过使用蒙特卡洛Dropout过滤半监督样本中的噪声数据,该方法能有效缓解假负样本问题。
(4) 我们在公开数据集上进行了大量实验,结果表明UBetaE模型和半监督学习方法都能有效提升非确定性知识图谱嵌入性能。
1 相关工作
1.1 确定性知识图谱嵌入模型
近年来,确定性知识图谱嵌入模型得到了大量研究,它们旨在将实体和关系映射到低维向量空间中,并把关系定义为对实体的代数运算。KGE模型可以被分为平移距离模型和语义匹配模型[9]。
平移距离模型的主要思想是将关系的嵌入表示为实体嵌入的转换或映射,得分函数计算映射后的头实体和尾实体在向量空间中的距离。这类模型的代表性工作如下: ①TransE[5],其将h,r,t均映射到同一个向量空间,把关系r看作是从头实体到尾实体的平移。虽然TransE计算复杂度低,但是它只能处理一对一关系。②TransH[10]针对TransE在处理复杂关系上的不足,提出让实体根据关系的类别有着不同的表示,即将头实体和尾实体投影到关系所对应的超平面上,再计算头实体平移后和尾实体之间的距离,因此在一定程度上能解决多对多关系。③TransR[11]为了使不同关系关注实体的不同属性,同时定义了实体空间和关系空间,先将实体从实体空间投影到关系空间中,再计算头实体平移后和尾实体之间的距离。④TransD[12]为了降低TransR的计算复杂度,使用两个向量表示实体和关系,将TransR中的投影矩阵分解为两个向量的乘积。
语义匹配模型的主要思想是基于实体潜在语义的相似度来计算三元组的合理性,这类模型中的代表性工作如下: ①RESCAL[13]利用满秩矩阵表示关系,向量表示实体,并定义得分函数fr(h,t)=hTWrt,其中矩阵Wr对实体潜在语义的交互作用进行了建模; ②DistMult[6]为了降低RESCAL的计算复杂度,将矩阵Wr限制为对角矩阵,并定义得分函数fr(h,t)=hTdiag(r)t。虽然减少了计算量和参数量,但是因为hTdiag(r)t=tTdiag(r)h恒成立,故该模型只能处理对称关系[14],如(A, isFriendOf B)⟺(B, isFriendOf A)。③ComplEx[15]为了能够同时处理对称和非对称关系,把DistMult扩展到复数空间中。以上模型均可通过我们的框架转化为面向非确定性知识图谱的嵌入模型。
1.2 非确定性知识图谱嵌入模型
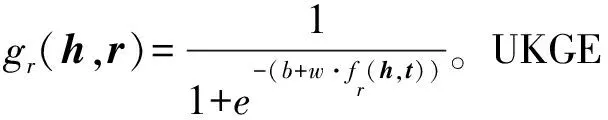
为了解决OWA带来的假负样本问题,UKGE采用手动生成的规则和概率软逻辑[16]来估计未见过的三元组的置信度。由于规则是人工手动生成,数量很少(每个数据集只有一两条),所以产生的新事实不仅数量少而且种类单一,故该方法存在一定的局限性。
针对UKGE只能处理简单关系的问题,本文提出了UBetaE用以处理多种复杂关系。本文提出的框架将UKGE对DistMult模型得分函数的处理通用化,可适配各种确定性知识图谱嵌入模型的得分函数,将原有的得分函数转化为置信度计算函数后用于非确定性知识图谱的嵌入,并使用半监督学习处理假负样本问题,不仅不需要人工制定规则,而且效果明显优于UKGE。
1.3 贝叶斯深度学习
虽然深度学习在很多任务中取得了最优成绩,但是它们却无法表示不确定度,即对于大部分任务,深度学习模型只能给出一个特定的结果,而无法给出对该结果的置信值(Confidence),而且置信值不等价于模型的置信度。Guo[17]等人的研究也表明,深度学习中存在严重的盲目自信(Overconfidence)问题,该问题也被称为模型的准确率和置信度不匹配(Miscalibration)。
为了捕获深度学习中的不确定度,研究者们提出了贝叶斯神经网络(Bayesian Neural Network,BNN),即使用先验概率分布代替模型中的参数。然而由于模型具有复杂的非线性结构和高维度参数,贝叶斯推理对于许多模型来说都是难解的。为了能更好地在深度学习中使用贝叶斯估计,一般采用蒙特卡洛Dropout方法(Monte Carlo Dropout,MC Dropout)[8],其思想是通过有限次采样来估计后验概率,为了使网络对于同一输入数据的多次运算结果不同,一般选择在测试阶段也开启Dropout。Gal[8]等人也在理论上证明了具有任意深度和非线性的神经网络,在每个权重层之前使用Dropout,在数学上等价于高斯过程中的贝叶斯近似(Bayesian Approximation)。本文使用蒙特卡洛Dropout计算模型对半监督样本估计的置信度的不确定度。
2 研究方法
针对UKGE无法很好地处理假负样本的问题,我们提出基于半监督学习的非确定性知识图谱嵌入训练框架;针对UKGE无法处理复杂关系的问题,我们提出基于Beta分布的UBetaE模型。两者结合,即将UBetaE作为框架中的置信度计算模块,能够弥补UKGE的所有缺点,因此可以达到目前非确定性知识图谱嵌入的最优性能。
2.1 非确定性知识图谱嵌入框架
2.1.1 框架整体结构
目前已有KGE框架,例如OpenKE[18],只能用于确定性知识图谱的嵌入,为了方便对非确定性知识图谱的研究,本文构建了专门用于非确定性知识图谱嵌入的框架。
本文提出的半监督学习框架的思想类似于伪标签(Pseudo Label)算法[19],该算法主要包含两个核心步骤: ①使用训练中的模型预测未标注数据,得到该数据的伪标签(在本框架中伪标签即为估计的置信度); ②把带有伪标签的数据加入训练集一起训练。
该半监督学习框架的整体结构如图1所示,主要包含两个模块:置信度计算模块和半监督样本置信度估计模块。
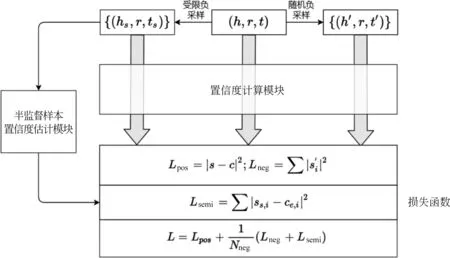
图1 半监督学习框架结构
2.1.2 置信度计算模块
置信度计算模块的作用是适配各种确定性知识图谱的嵌入模型的得分函数,并计算三元组(h,r,t)的置信度。该模块为距离平移模型和语义匹配模型提供了统一的得分映射函数,可以方便地将任何确定性知识图谱的嵌入模型转化为非确定性知识图谱嵌入模型,且不需要做过多修改。
平移距离模型的得分范围是(-∞,0],而语义匹配模型的得分范围是(-∞,∞)。虽然这两类模型的得分范围相差较大,但是实验结果表明只需要对线性变化偏置bias的初值进行适当调整,就能使用同样的线性变化和映射函数,使它们收敛到很好的结果。
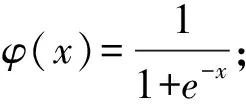
2.1.3 半监督样本置信度估计模块
半监督样本置信度估计模块是实现半监督学习的关键模块,该模块的作用是为半监督样本估计一个合理的置信度ce,这样不仅可以有效地解决假负样本问题,还能作为数据增强提高模型的鲁棒性。由于随机负采样得到的负例大部分都是错误的,为了提高半监督样本的质量,我们采用受限负采样的方法来采样半监督样本。受限负采样类似于域采样[20],即随机采样的实体必须在当前关系r的头或尾实体域中。
虽然伪标签算法使用半监督学习取得了较好的成绩,但是它仍存在局限性:伪标签中容易存在错误标签,尤其是在训练初期,并且这种错误会在半监督训练过程中累积,该现象称为确认偏差(Confirmation Bias)[21]。产生错误伪标签的一个重要原因是,深度学习模型只能给出一个特定的结果,而无法给出对该结果的信心值。
为了解决上述问题,我们采用基于多模型的蒙特卡洛Dropout[8]方法进行贝叶斯推理以及计算不确定性。具体方法如下: 使用多个已经训练好的模型在开启Dropout的情况下对同一半监督样本进行多次预测,取所有预测值平均值作为最终结果,取方差作为不确定度,并挑选出不确定度小于阈值μ的半监督样本以及它对应的估计置信度作为额外的训练数据。
相比伪标签算法,本方法的优点如下: ①综合多个模型的预测结果,避免了单一模型引起的确认偏差; ②使用不确定度作为筛选标准,而不是使用模型的置信度,有效地过滤掉了大概率是噪声的高不确定度半监督样本。
半监督样本的损失函数如式(1)所示。
(1)
其中,Dsemi是半监督样本的集合,gr是置信度计算函数。最终的损失函数如式(2)所示。其中,Lpos和Lneg分别是正例和负例的损失。
(2)
2.2 基于Beta分布的非确定性知识图谱嵌入模型
Ren等人[22]提出使用Beta分布建模知识图谱上的一节谓词逻辑查询(First-order Logic Queries,FOL queries)。受到该工作的启发,我们提出了UBetaE (Uncertain Knowledge Graph Beta Embedding)来表示非确定性知识图谱中实体和关系的不确定性。
2.2.1 实体和关系的Beta嵌入
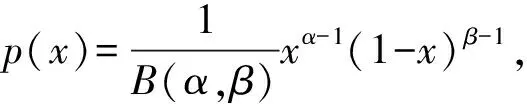
我们将实体和关系表示为一组相互独立的Beta分布,具体表示如式(3)所示。
h=[(α1,β1),…,(αn,βn)]
(3)
其中,n为超参,(αi,βi)表示实体或者关系的第i个Beta分布。在该定义下,h,r,t∈R2n。

(4)
其中,p表示h经过r对应变化后的Beta嵌入。
使用上述方法建模非确定性知识图谱的优势如下: ①概率嵌入能够更自然地表示实体和关系的不确定性; ②分布的交操作是闭包的,即两个Beta分布经过交操作之后仍然是Beta分布; ③相比高斯分布,Beta分布的差异性更大,因此更能反映出两个实体之间的差异。
2.2.2 得分函数
给定三元组(h,r,t),我们希望h经过r变化后得到的p和t的差别尽可能地小,并使p和其他实体分布的差异尽可能大。我们将p和t之间的距离定义为每个维度上两个Beta分布的 KL散度之和,具体如式(5)所示。
(5)
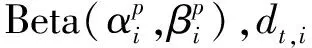
为了提高模型的表达能力,我们对所有KL散度进行加权求和,再将该结果经过线性变化和映射函数即可得到该三元组的置信度,最终UBetaE的置信度计算函数如式(6)所示。
(6)
其中,fr(h,t)为UBetaE 的得分函数,计算如式(7)所示。
(7)
本部分使用的损失函数和训练方法与2.1 节一致,此处不再赘述。
3 实验
3.1 实验设置
3.1.1 数据集
为了和UKGE[4]进行对比,我们使用了 CN15k 作为数据集,CN15k是常识知识图谱 ConceptNet[3]的子图,它包含15 000个实体和 241 158 条带有置信度的事实,平均候选尾实体数 (给定头实体和关系后候选尾实体的平均数量) 为 3.87,说明 CN15k 中一对多的现象普遍存在。
3.1.2 基线模型
我们选择 UKGE 中的UKGElogi和UKGEreat作为基线模型(Baseline),它们分别以 sigmoid 函数和有界整流函数作为映射函数,同时它们也分别是非确定性知识图谱中尾实体预测任务和置信度预测任务的SOTA。此外,我们还使用上文介绍的框架构建了 UTransE、URotatE。将上述模型与UBetaE模型进行对比。
3.1.3 实验设置
我们将数据集分为训练集、验证集和测试集,占比分别为85%,7%和8%。此外,为了验证模型区分正负例的能力,我们在测试集中加入了等量的负例,这些负例由随机负采样得到。
我们选择Adam[23]作为默认优化器,并将β1和β2分别设置为 0.9 和0.999。对于每种模型,我们根据其在验证集上的表现选择最优参数,并使用最优参数下模型在测试集的性能作为最终结果。
对于每个模型,我们使用 grid search 搜索最优参数,各参数选择范围如下: 学习率lr∈{0.001,0.005,0.01};嵌入维度dim∈{256,512,800};batch大小batchsize∈{512,1024,2048}。所有模型训练 100 个 epoch,并根据在验证集上的 MSE 值设置提前终止。
为了提高模型的训练效率,我们的半监督学习训练方案如下:提前使用多个训练好的模型生成一定数量的半监督样本,之后新模型在训练过程中直接从这些半监督样本中采样,避免每次都对半监督样本进行置信度估计。
3.2 实验结果
我们采用两种任务来评测模型的性能,分别是置信度预测和尾实体预测。并通过进一步的实验来探究半监督样本的筛选阈值以及半监督样本的采样数对模型性能的影响。
3.2.1 置信度预测
置信度预测任务的目标是预测未见过事实的置信度。
评测指标该任务的评测指标为均方误差(MSE),计算如式(8)所示。
(8)
其中,si为预测置信度,ci为真实置信度,N为测试样本数。
结果实验结果见表1。*表示数据来自原论文,withwithout ss 分别表示使用不使用半监督学习。实验结果表明: ①我们提出的 UBetaE 模型在不使用半监督学习的情况下明显优于作为基线模型的 UKGElogi和 UKGErect,并且在所有模型中性能最高。②使用半监督学习后,所有模型的性能都得到了显著的提升,平均提升了 7.5%。结果表明,基于多模型的半监督学习能够有效地消除假负样本带来的噪声,并进一步提高对未见过事实置信度的预测精度。
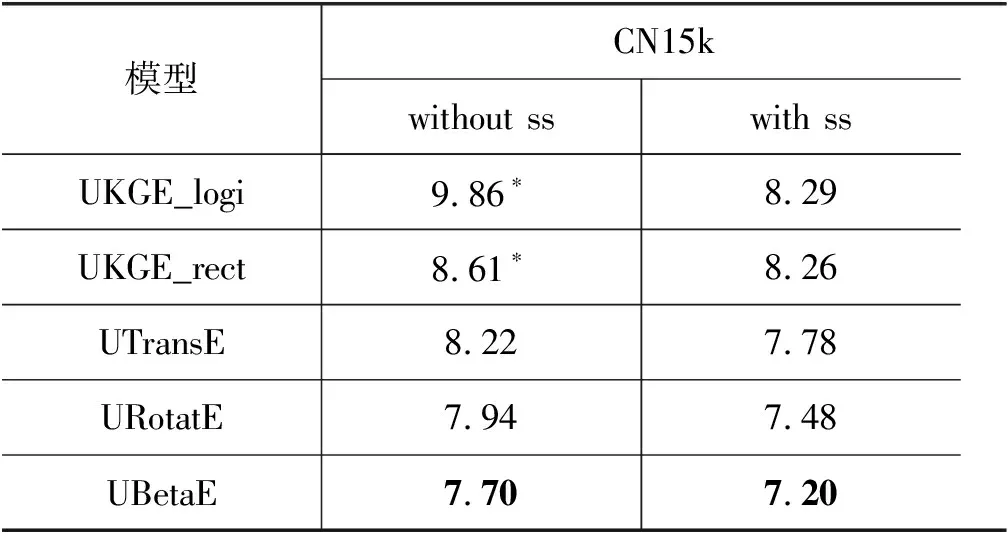
表1 置信度预测的MSE值(×10-2)
3.2.2 尾实体预测
尾实体预测目标是在给定头实体和关系的情况下预测尾实体, 即希望正确候选尾实体的排序在所有实体中尽可能靠前。
评测指标该任务的评测方法如下:将所有实体作为候选尾实体对象与给定的h和r组成候选三元组,对候选三元组根据得分进行排序,并使用归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG)评估排序性能。为了更好地测试模型性能,我们排除了来自训练集中的候选尾实体并在整个测试集上计算nDCG值,因此结果与 UKGE 原文不同。
结果实验结果如表2所示。①UBetaE 在尾实体预测任务上面明显优于其他模型,这表明 UBetaE 作为概率嵌入模型,能很好地表示实体和关系的不确定性,从而能够处理一对多这种复杂关系。②使用半监督学习之后,所有模型的尾实体预测能力都得到了提升,说明半监督样本能够有效地缓解假负样本问题。因为一旦引入假负样本,便会错误地把正确候选尾实体排在靠后位置,从而严重影响模型性能。
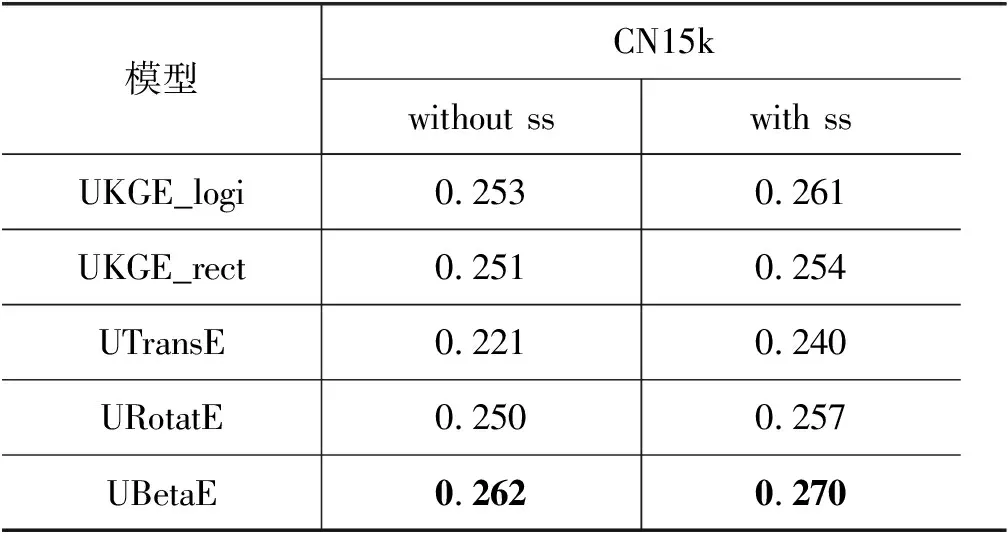
表2 尾实体预测的nDCG值
3.2.3 半监督样本的采样数对性能的影响
为了进一步探究半监督样本的采样数对性能的影响,我们采用 UBetaE 模型,在其他超参相同的情况下,采取不同的半监督样本采样数,表3展示了实验结果。其中“半监督样本采样数”表示每一个正例对应的半监督样本采样数。图2使用折线图更直观地展示了半监督样本采样数对 MSE 的影响。

表3 不同半监督样本采样数下的MSE值(×0.01)
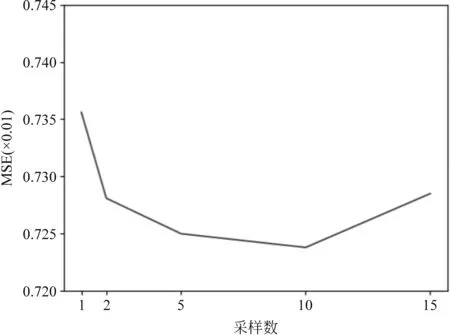
图2 半监督样本采样数-MSE
实验结果表明,在半监督样本采样数较小的时候,增加半监督样本采样数可以明显提高模型的性能,因为引入了更多训练数据。但是随着半监督样本采样数进一步增大,模型的性能会开始降低,因为大量半监督样本中包含的噪声影响了模型的训练。
3.2.4 筛选半监督样本的阈值对性能的影响
为了验证我们的 MC Dropout 方法能够有效地过滤半监督样本中的噪声,我们使用UBetaE 模型,在其他超参相同的情况下,采用不同的阈值μ,从所有半监督样本中筛选出部分低不确定度的半监督样本,即模型对估计的置信度更加自信的半监督样本。表4展示了实验结果,其中“筛选比例”表示筛选后的半监督样本占原半监督样本的比例,图3使用折线图更直观地展示了筛选比例对 MSE 的影响。

表4 不同筛选比例下的MSE值(×0.01)
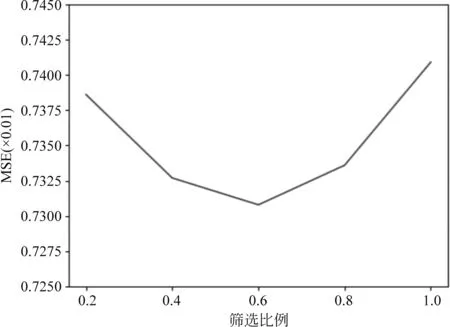
图3 筛选比例-MSE
实验结果表明: ①在不筛选的情况下 (比例为 100%),模型效果较差, 说明原半监督样本中含有较多噪声。②在筛选比例为 60% 的情况下,模型的效果最好,说明我们使用的MC Dropout 方法能够有效地反映出模型的不确定度,并能根据该不确定度过滤掉噪声样本,从而提高模型性能。③随着筛选比例的降低,模型的性能会先提高后下降,高筛选比例会引入较多的噪声,低筛选比例则会丢弃部分有价值的样本,这两种情况都会导致模型的性能降低。
4 结论
本文提出了一种基于 Beta 分布的非确定性知识图谱嵌入模型 UBetaE,它把实体、关系表示为相互独立的 Beta 分布组合,能更好地描述和计算实体、关系和事实的不确定性。此外,为了更好地处理假负样本问题,我们使用基于多模型的半监督方法训练非确定性知识图谱嵌入模型,并使用MC Dropout过滤掉了半监督样本中的噪声,从而进一步提高训练效率和模型性能。在公开数据上的大量实验表明: ①本文提出的UBetaE模型明显优于UKGE等当前最优的非确定性知识图谱嵌入模型; ②半监督学习对于非确定性知识图谱嵌入模型性能提升较大。在实验中,我们发现框架最后的线性层初始化方式对实验结果影响较大。在未来的工作中,我们会进一步研究线性层初值对模型性能的影响,并使用更直观的任务展示使用半监督学习在解决假负样本问题上的优越性。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
社会科学战线(2022年7期)2022-08-26 08:45:12
法律方法(2022年1期)2022-07-21 09:18:56
社会科学战线(2022年3期)2022-06-15 02:41:10
核科学与工程(2021年4期)2022-01-12 06:30:22
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
计算机应用(2018年5期)2018-07-25 07:41:26
社会科学(2016年6期)2016-06-15 20:29:09
轴承(2015年2期)2015-07-25 03:51:04
