
中文药品知识库的研究与构建
2022-01-01 13:10:50张坤丽任晓辉昝红英张维聪穗志方
中文信息学报 2022年10期
张坤丽,任晓辉,庄 雷,昝红英,张维聪,穗志方
(1. 郑州大学 计算机与人工智能学院,河南 郑州 450001;2. 北京大学 计算语言学教育部重点实验室,北京 100871;3. 鹏城实验室,广东 深圳 518052)
0 前言
随着医药技术的快速发展,各类新药不断上市并进入医院药房,使临床医师掌握所有药品的用法用量、不良反应、禁忌症等信息具有一定的难度[1]。且新药存在名称繁多、用法复杂等情况,对临床用药的安全性和有效性具有较大的挑战[2]。与此同时,医药学数据具有质量控制困难、内涵丰富等特点,因此面对海量的医药学数据,亟需构建医药学知识库,高效准确地发现知识,为医学方面的研究和临床决策提供充分可靠的依据,最终实现精准预防、精准诊断和精准治疗的目标[3]。
近年来许多学者在医学知识库的构建方面进行了研究,如解放军医学图书馆与重庆维普咨询有限公司合作研发了一个主要面向临床医药学专业人士的中国疾病知识总库(China Disease Knowledge Total Database, CDD)[4],由疾病库、药品库、辅助检查库和循证医学库4个知识库组成。侯丽等[5]构建了基于本体的临床医学知识库,其中包含疾病库、药物库、检查库3大医学知识库。除了构建的各种综合知识库外还有各类专科专病的药品知识库,如葛彩霞等[6]建立了一个药物与不良反应对应关系的知识库,为药物不良反应的监测以及药物不良反应研究提供一个在线资源。徐帆等[7]构建了药品属性分类知识库,为实践数据驱动的药事管理模式提供参考。张丽等[8]构建了消化系统用药知识库,利用该知识库,可为医师在确定用药方案时提供用药前拦截、用药中警示、用药后提示等信息。除此之外,目前也出现了众多的主流医学综合网站,如丁香园(1)丁香园网址:http://www.dxy.cn/是中国最大的面向医生、医疗机构、医药从业者的专业性社会化网络[9],其中收录了数千种药品说明书。MENET(2)MENET网址:http://www.menet.com.cn/作为医药健康信息领先平台,其中包括医保药品、参比药物及上市药品和低价药品等。
虽然目前国内的医药学资源很多,但是分析后发现,面向专科专病的药品知识库包含的药品知识存在一定的局限性,无法有效地了解多方面的药品信息,而医学综合知识库中的药品库虽然包含各种药品信息,但是各自具有独特的知识表示方式,例如药品的分类体系和描述体系就各有不同。不同的医药资源在药品数量、药品知识描述中的药品属性、详细程度等方面都存在差异性,并且其中的药品知识多为非结构化描述,没有直接将药品与疾病、症状等建立结构化关联,不便于临床应用时快速准确地对症治疗,而且难以与现有的知识图谱及资源建立联系。例如利用自然语言处理与文本挖掘技术研发的中文医学知识图谱 (Chinese Medical Knowledge Graph,CMeKG),CMeKG的构建参考ICD[10]、SNOMED-CT[11-12]、MeSH[13]等权威的国际医学标准以及规模庞大、多源异构的临床指南等医学文本信息[14],其中包含1万多种疾病、近两万种药物、1万多个症状的结构化知识描述,缺点是非结构化的药品知识无法与CMeKG直接建立结构化连接。
药品的详细信息对于辅助临床医生合理用药、提高医疗质量[14]等至关重要,在一定时间内高效地了解多种药品的详细信息对于提高临床决策的效率等也尤为重要,因此信息完整的药品库可为临床医生、护士在处理医嘱,合理选择、使用药物方面提供及时的服务[15],本文以有效辅助临床应用,提高临床决策效率为目的构建了多来源的中文药品知识库(Chinese Medicine Knowledge Base,CMKB),其中针对药品知识和表示方式的差异性,构建了满足多来源情况的知识描述体系和分类体系。CMKB的构建过程可以分为模式层构建、数据层构建和建立药品与多实体间知识关联三个部分。
模式层构建主要分为两步(图1),第一步是进行知识描述体系构建,第二步是进行分类知识体系构建,即通过分析多来源的数据形成CMKB的概念架构。数据层则是在自动清洗和筛选后所形成的具体药品信息基础上,对非结构的药品知识描述采用深度学习的方法自动抽取疾病、症状等实体,构建了药品与多种实体之间的结构化知识关联。
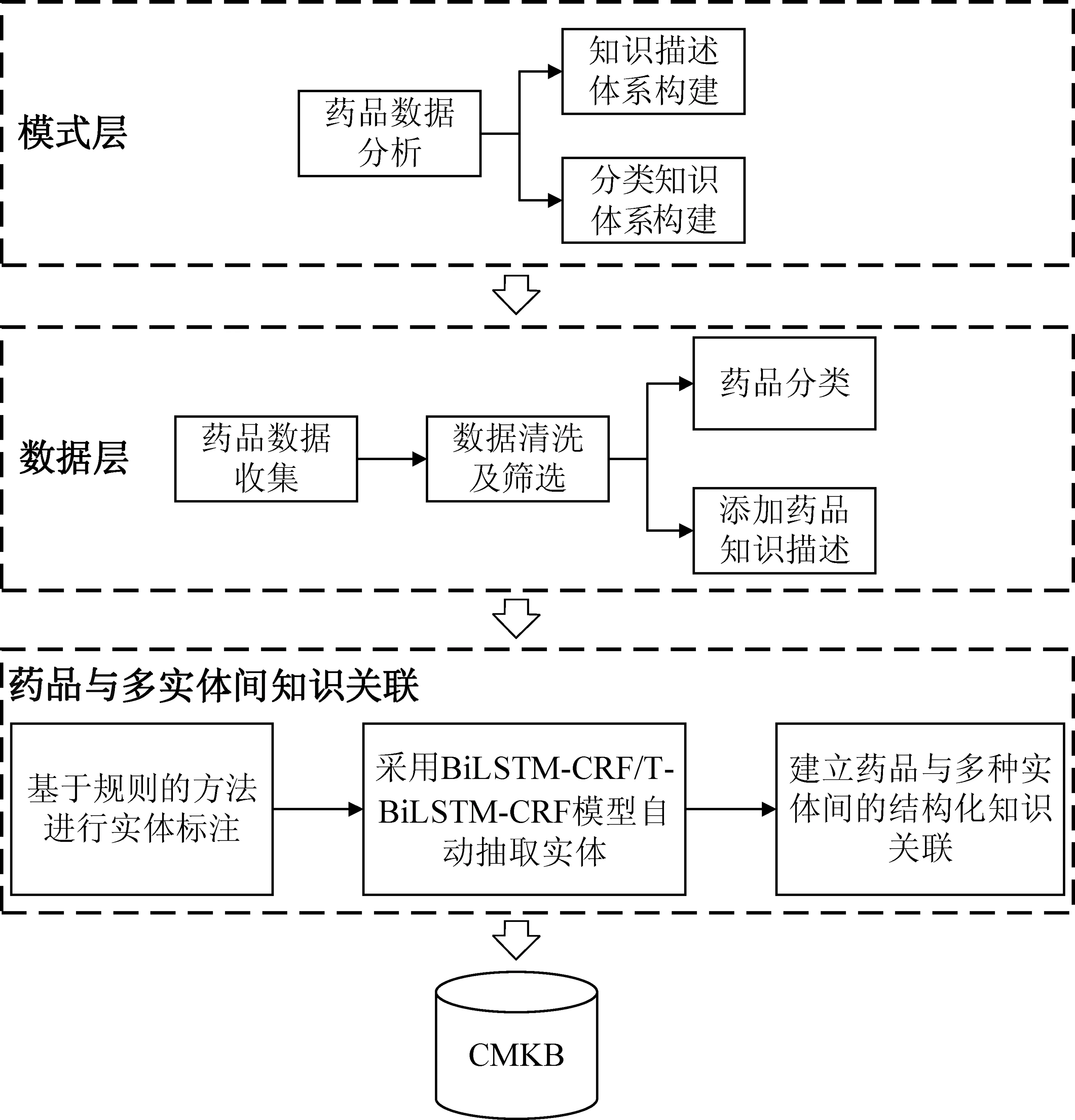
图1 CMKB的构建过程示意图
1 CMKB的知识描述体系构建
多来源药品知识的描述体系有较大的差异,因此为了使药品库中的知识描述更加规范化,本文通过对多来源数据结构的分析,建立了CMKB的知识描述体系。本文选择CDD、丁香园以及MCDEX中国医师药师临床用药指南的药品数据作为参考来建立CMKB的知识描述体系。其中,MCDEX中国医师药师临床用药指南(简称MCDEX)是由卫生部合理用药专家委员会组织编写的临床用药参考书,包括国家基本药物、临床常用药物、国内外新上市药物等[16]。
药品的知识描述体系可由药品的适应证、用法用量及禁忌症等多种药品属性构成。不同的数据来源都根据药品属性对药品进行了知识描述。表1是统计三个来源中的药品属性得到的结果。
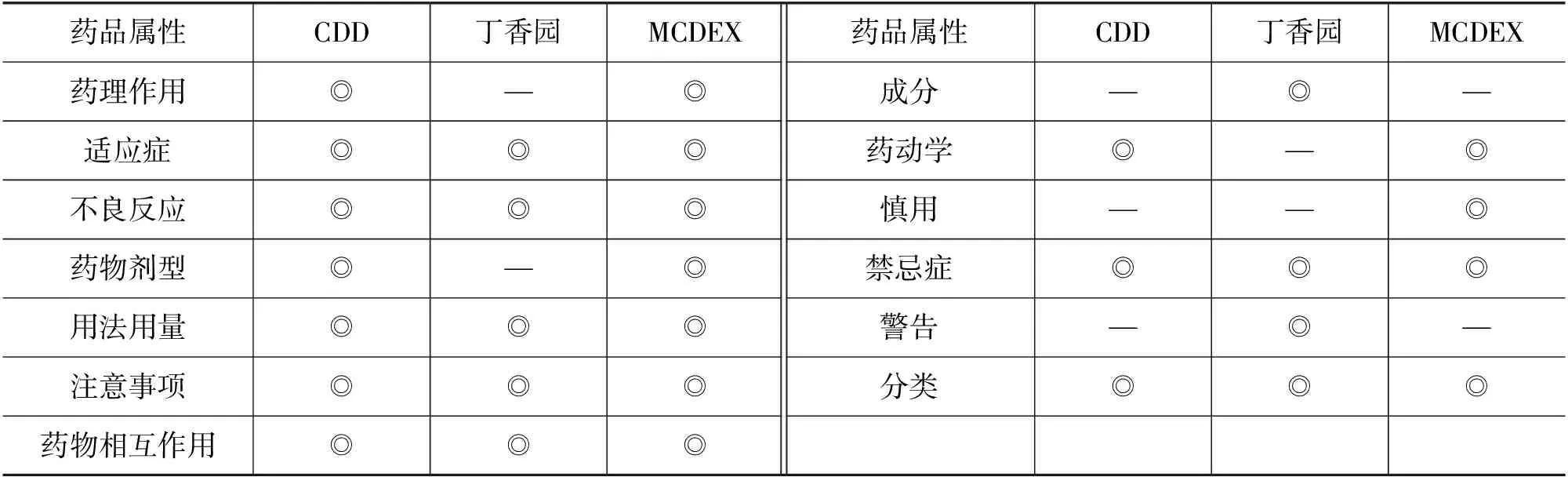
表1 不同来源的药品属性
由表1可以看出,不同来源依据不同的属性对药品进行知识描述,但是在医疗活动中,疾病的种类繁多,一种疾病具有多种症状,且针对疾病的不同症状可能采用不同的用药方案,所以药品知识库需要涵盖针对病情合理用药时所必须了解的所有基本的药品属性。以“盐酸萘甲唑啉滴鼻液”为例展示CMKB最终确立的药品描述体系中的药品属性及相应的样例,如表2所示。
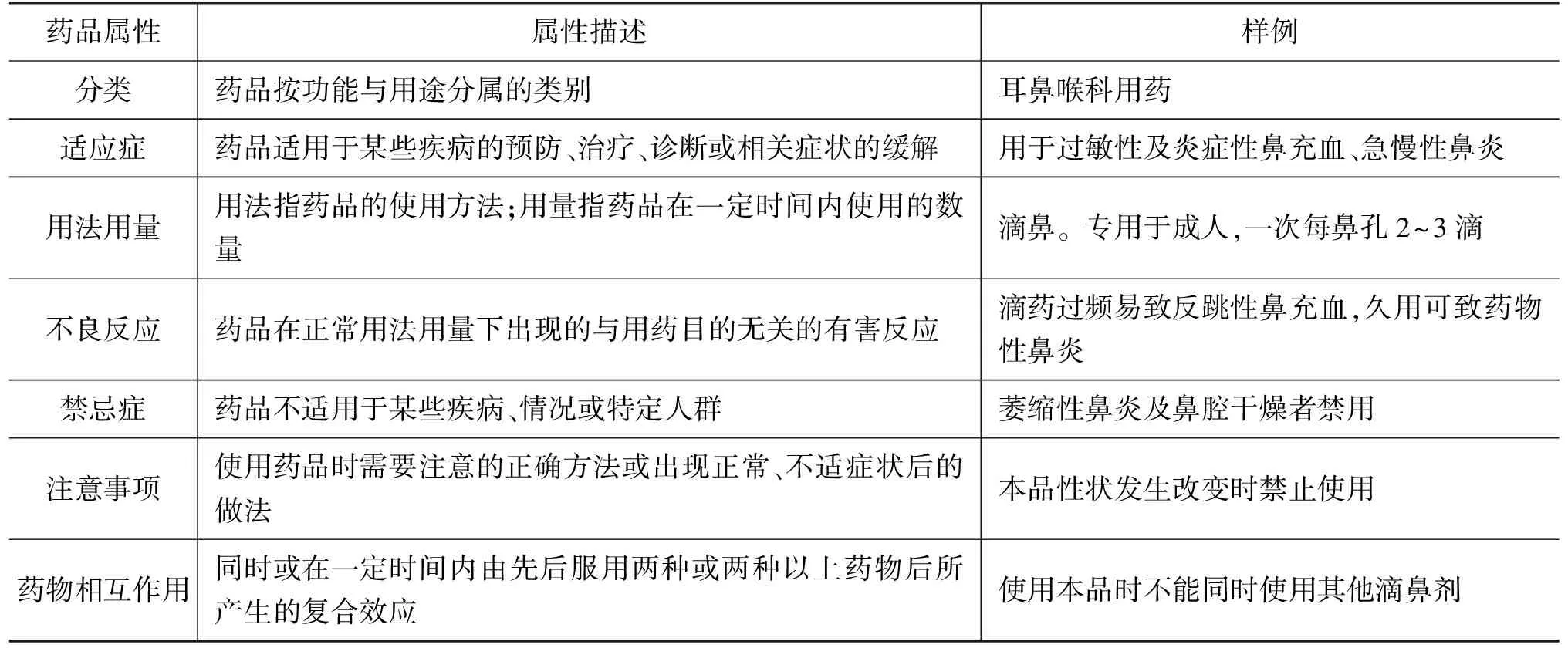
表2 “盐酸萘甲唑啉滴鼻液”为例的药品属性知识描述介绍
2 CMKB的分类体系构建
在构建了知识描述体系后,此时的各种药品仍处于散乱分布状态,不便于临床高效查询,因此需要构建一个标准的分类体系对药品进行整理。
分析CDD、丁香园、MCDEX以及MENET 4个来源的药品分类情况后发现,不同药品资源库的药品分类情况各有不同,并且不同的一级类别数远多于相同的一级类别数。
本文期望建立一个不仅能够涵盖多种药品分类情况,并且具有普遍认可度的分类体系。因此将各级医疗卫生机构配备使用药品依据的国家基本药物目录(2018年版)的分类标准与多个来源的药品分类情况进行分析后发现,国家基本药物目录中的分类标准虽然具有高度认可性,并且最多地涵盖多个来源的药品分类,但是仍然存在一些不在分类标准中的药品分类情况。
因此,本文构建的CMKB将国家基本药物目录的分类标准作为基本的分类框架,将4个来源的分类体系作为参考进行一定的调整,形成能适应多来源药品分类情况的药品分类体系。最终采用的分类体系总共包含了27种一级类别和119种二级类别。表3中列举了CMKB分类体系中的一级类别及其包含的二级类别数和二级类别样例。
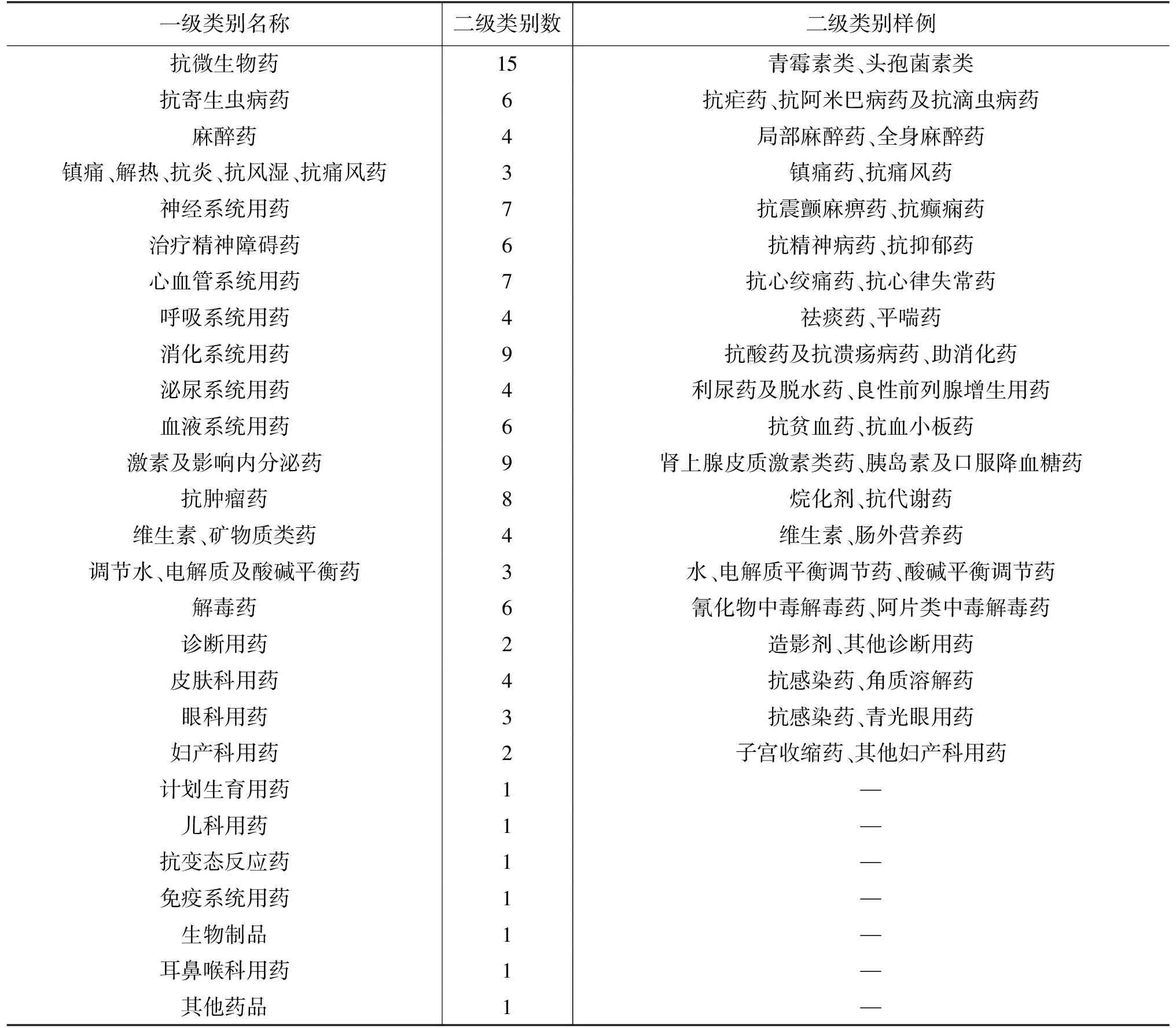
表3 CMKB的中文药品知识库的分类体系
3 CMKB的数据层构建
在分析数据构建了CMKB的模式层后,接下来就是进行数据层的构建,主要工作分为药品数据收集与处理、药品分类并完善药品信息,下面将具体进行介绍。
3.1 药品数据收集与处理
本文收集了CDD、丁香园和MCDEX中的药品数据,依据已经建立的药品知识描述体系,从中抽取出所有药品的7种属性信息,包括药品的适应证、禁忌症等。
由于药品数据是多来源的,所以需要对收集到的药品数据进行处理。但是此时的数据存在以下问题:
(1) 本文构建的CMKB针对的是化学药品,但是收集的药品数据中存在混入的中成药或者民族药。
(2) 对于相同的药品,属性数据中存在以下问题: ①个别符号差异,造成数据重复; ②知识描述上存在文字差异,造成内容相似度很高; ③知识描述差异较大。
(3) 不同来源的药品名称存在形式不同的情况,有的将“化学成分”作为药品名称,例如“氨苄西林”,有的则将“化学成分+剂型”作为药品名称,例如“氨苄西林胶囊”。
针对以上问题,第一步是进行数据清洗。依据多个医药资源中的“中成药”和“民族药”对收集的数据进行清洗,确保药品归属于“化学药品”的准确性。然后清洗所有由于符号差异生成的重复数据。
第二步要对剩余的药品数据,进行数据筛选。首先根据数据相似性进行筛选,依据最长字符序列匹配算法对每一种药品筛选出相似度在80%以上的数据,并在差异较大的数据之间选取字符串最长的数据作为保留的药品知识描述。之后针对药品名称形式不同的问题,本文暂时忽略它们之间的从属关系,将相应的药品数据都保留下来。
3.2 药品分类并完善药品信息
数据经过处理后,接下来就要开始进行数据层的具体构建工作,主要分为两步。第一步,根据分类体系对多来源的药品知识进行整理,其中针对不同的类别问题采用的处理方法如下:
(1) 所有药品首先依据国家基本药物目录的药品分类情况进行规整。由于基本药物目录中的药品名称均以化学成分的形式列举,因此对于其他来源中化学成分+剂型的药品,依据字符串匹配的方法进行药品名称的匹配,例如,“阿莫西林”匹配出“阿莫西林颗粒”和“阿莫西林片”等,最终都以国家基本药物目录中的分类“青霉素类”为准。
(2) 不同来源的药品分类存在差异性,因此对相同药品进行分类名称的字符串相似度匹配。将相似性高的分类名称以已整理的药品分类为准,若差别较大,例如,“头孢地尼片”在丁香园中的分类为“胃肠解痉药及胃动力药”,但在MENET中分类为“全身用抗细菌药”。考虑到药品的多种疗效,所以也保留了差异较大的分类情况。
(3) 当药品数据无法确定具体的所属分类时,首先查看是否有正确的二级类别,若无,再根据相关的一级分类进行规整。其中由于儿科用药的特殊性,本文将所有儿科药品均以儿科的一级类别为先。
(4) 对于最后剩余的药品数据均归类在一级类别“其他药品”中,例如,“治疗肥胖症用药”“运动系统用药”等。
第二步为完成分类后的药品添加处理后的知识描述,形成初步的中文药品知识库,此时药品库中的数据以<药品名称-药品属性-药品知识描述>的三元组形式呈现,例如:<唑尼沙胺片-禁忌症-已知对盐酸氨溴索或其他配方成份过敏者不宜使用>,总计81 157条药品的三元组信息。
4 建立药品与多种实体间的知识关联
目前初步构建的药品知识库中的知识描述虽然便于医生全面并且详细地了解药品信息,合理使用药物,但是临床决策的高效性同样重要。因此,为了便于临床应用,下一步就要考虑CMKB如何在临床应用中更加高效准确地辅助医生针对具体的病情合理用药,在使用药物方面提供及时的服务。此时药品知识库中的药品信息大多是非结构化的知识描述,无法根据病人具体的疾病、症状快速有效地选择合适的药品进行对症治疗,并且医生在选择药品时也需要及时考虑与其他药品的相互影响,避免严重副作用的产生,因此建立起药品与疾病等其他实体之间结构化的知识关联显得尤为重要。
在分析药品的多个属性后发现,适应证、禁忌症和不良反应的药品知识描述中包含的疾病、症状信息最多,即在这些知识中药品与疾病、症状之间的结构化关联最为密切。同时发现在药物相互作用中存在药品与药品之间的影响作用,可形成药品间的结构化关联。因此本文选择采用这4种属性知识来进行药品与多种实体间知识关联的建立,可构建的以药品为中心的三种知识关联具体如下:
(1)药品-疾病的知识关联例如,“左氧氟沙星注射液”的适应证的知识描述:本品适用于敏感细菌所引起的急性支气管炎、弥漫性细支气管炎等,可形成三元组知识关联<左氧氟沙星注射液-适应证-急性支气管炎|弥漫性细支气管炎[疾病]>。
(2)药品-症状的知识关联例如,“左氧氟沙星注射液”的不良反应的知识描述:用药期间可能出现恶心、呕吐、腹部不适等症状,可形成药品与症状之间的三元组知识关联<左氧氟沙星注射液-不良反应-恶心|呕吐|腹部不适[症状]>。
(3)药品-药品的知识关联例如,“盐酸左氧氟沙星注射液”的药物相互作用的知识描述:联合应用喹诺酮类抗生素和抗糖尿病药物的患者可能出现血糖紊乱,可形成药品与药品之间的三元组知识关联<盐酸左氧氟沙星注射液-药物相互作用-喹诺酮类抗生素|抗糖尿病药物[药品]>。
本文以建立药品与疾病之间的知识关联为例,基于根据概念架构整理的药品数据,具体介绍关联的构建过程,主要分为三个步骤。第一步,针对未经标注的知识描述,采用基于规则的方法对疾病信息进行命名实体识别,具体使用MeSH词表、ICD-10以及CMeKG中的疾病数据进行疾病名称的字符串规则匹配,从而实现初步的疾病标注文本,并且为了保证疾病标注的正确性,之后进行了人工校对,对一些错误信息进行数据清洗。
第二步,为了验证本文构建的中文药品知识库中药品语料的有效性,以及对疾病标注语料进行一致性评价,本文将药品的非结构化知识描述作为原始语料,采用基于深度学习的方法对语料进行疾病实体的命名实体识别,从而实现多来源药品知识描述中疾病实体的自动抽取。
为了实现疾病实体的识别和自动抽取,本文采用经过处理后的适应证、禁忌症和不良反应的药品知识描述等近3万条进行实验,包含训练集数据23 000条,测试集数据6 000条,并将药品知识描述作为原始语料,其中针对上一步已知的疾病信息采用BIOE的标注方式对知识描述语料进行标注,之后分别送入BiLSTM-CRF模型和T-BiLSTM-CRF的模型进行学习,最终实现对语料中的疾病实体的命名实体识别。其中实验使用的T-BiLSTM-CRF模型是在BiLSTM-CRF模型的基础上加入迁移学习的思想,使用BiLSTM模型在非医学领域的Resume数据集上进行训练,获得含有非医学的关键知识的模型参数,之后将这一阶段得到的模型参数作为目标网络S-network中医药学数据集上进行训练的BiLSTM+CRF模型的初始化数据,并进行调优,该模型通过融入外部非医学领域的资源的关键特征来提高BiLSTM-CRF模型的命名实体识别效果。T-BiLSTM-CRF模型的整体架构如图2所示。
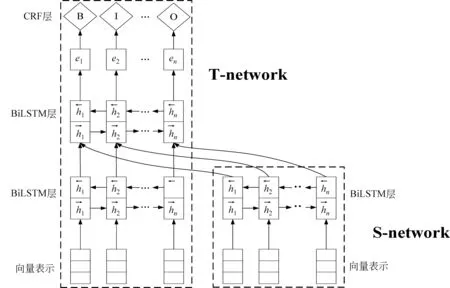
图2 T-BiLSTM-CRF模型的整体架构图
在实验过程中本文将第一步经过人工校对后的标注语料作为实体识别的测试数据,最终得到的实验结果如表4所示。
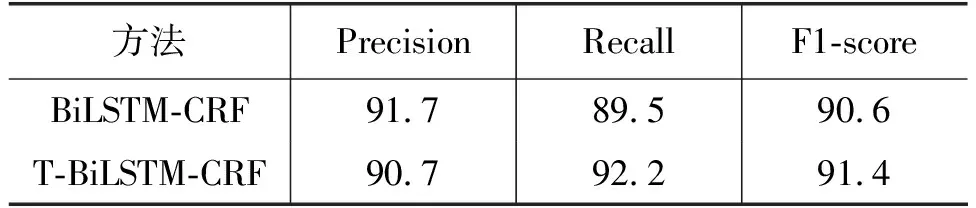
表4 实验结果 (单位: %)
本文使用F1值来对实体识别标注语料进行一致性评价,文献[19]指出,当F1值达到80%以上时,则可以认为语料实体标注的一致性是可信赖的。采用BiLSTM-CRF和T-BiLSTM-CRF模型进行命名实体识别实验,F1值分别达到了90.6%和91.4%,表明通过神经网络模型自动抽取出的疾病实体是可靠的,因此后面构建的中文药品知识库中的药品与疾病之间的知识关联是值得信赖的,最终从知识描述中抽取出的疾病共4 536种。
由于在收集到多来源药品数据的同时,也获取到了多种药品的半结构化信息,如已有的多种药品属性,而这些信息有助于构建相应实体间的结构化关系。因此本文将药品实体、已知的药品属性与自动抽取的疾病实体之间构建了实体间结构化关联的三元组数据,其中药品实体与疾病实体之间的关系是已知的,即适应证、禁忌症和不良反应三类。所以构建的药品知识库中可形成<药品-药品属性[适应证|禁忌症|不良反应]-疾病>的三元组知识关联形式。最终CMKB中包含的三元组知识关联数据总计235 810条,同样以“盐酸萘甲唑啉滴鼻液”为例形成的知识关联如表5所示。

表5 以“盐酸萘甲唑啉滴鼻液”为例的药品与疾病的知识关联
最终CMKB中形成了药品与疾病、药品与症状、药品与药品之间结构化的知识关联,有利于在临床应用时医生根据具体的情况快速选择合适的药品。与此同时,构建的药品库与中文医学知识图谱CMeKG有着相似的知识关联情况,其中CMeKG将疾病类实体作为中心,标注疾病与其他类实体之间的关系类型,形成实体之间广泛的知识关联[17][18]。因此本文构建的CMKB中建立的药品与多种实体之间的知识关联可以与CMeKG进行连接,提供快速的药品查询服务,并且为查询的药品提供CMKB中详细的药品知识描述,更加全面地了解药品信息,有效提高医疗质量。
本文所使用的深度学习模型针对文本中存在的嵌套实体时,准确率较低,如[感染性[心内膜炎]疾病]疾病,实验只识别出了“心内膜炎”而并未识别出完整的疾病实体“感染性心内膜炎”,因此后续计划采用具有更加广泛、专业的医学词典以及其他更优化的深度学习模型和算法进行更准确的实体识别。
5 CMKB的统计与展示
依据多来源的药品数据进行模式层和数据层的构建后,最终形成了构建的中文药品知识库CMKB。其中总共包含27种一级类别和119种二级类别,涵盖了14 141种化学药品。每种类别中包含药品数的分布情况如图3所示。

图3 不同类别的药品分布情况图
本文最终将通过适应证、禁忌症和不良反应建立的药品与疾病实体间结构化知识关联的结果以药品知识图谱的形式进行了可视化展示,以“左旋咪唑”为例的展示效果如图4所示。
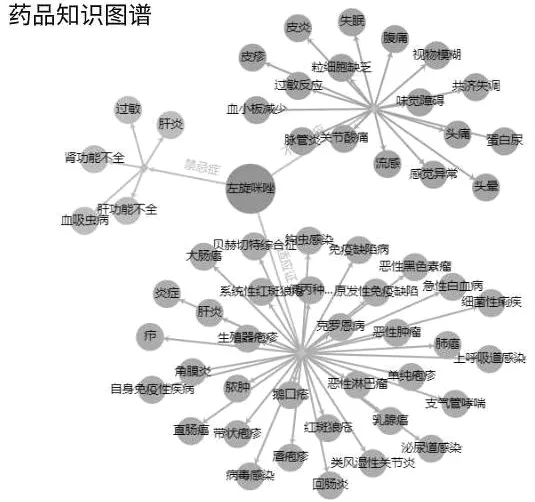
图4 “左旋咪唑”的药品与疾病知识关联的可视化展示图
6 结语
本文以有效辅助临床应用以及提高临床决策效率为目的,构建了一个多来源的中文药品知识库CMKB。首先针对多来源的药品数据进行知识描述体系和分类体系构建;之后根据建立的体系结构和数据处理后的药品信息进行数据层的构建,形成了初步的CMKB。同时为了实现临床决策的高效性,本文构建了药品与疾病、症状等多种实体间的结构化知识关联。CMKB中的药品知识能够提高临床用药的有效性和合理性,并且可以作为特征,加入到医疗问答在内的多种自然语言处理应用中。CMKB中建立的知识关联有助于完成多学科协作、贯通诊疗全过程的医疗临床决策支持系统,并且有助于辅助诊断和智能导诊。目前构建的CMKB所包含药品数目以及构建的多种知识关联的数量存在局限性,下一步将尝试利用半监督的信息抽取等新技术进行更广泛的药品知识的自动抽取,进一步扩大CMKB所涵盖药品知识的广度和深度。
猜你喜欢
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
当代陕西(2019年15期)2019-09-02 01:52:00
制造技术与机床(2019年6期)2019-06-25 10:17:46
学苑创造·A版(2018年11期)2018-02-01 06:29:20
读者(2017年5期)2017-02-15 18:04:18
中国交通信息化(2016年9期)2016-06-06 07:42:23
图书馆研究(2015年5期)2015-12-07 04:05:48
计算机工程(2015年8期)2015-07-03 12:20:35
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
