
基于随机森林的高性能混凝土抗压强度预测
2021-12-30 08:22:06崔晓宁王起才张戎令代金鹏
兰州交通大学学报 2021年6期
崔晓宁,王起才*,2,张戎令,2,代金鹏,2,谢 超
(1. 兰州交通大学 土木工程学院,兰州 730070;2. 兰州交通大学 道桥工程灾害防治技术国家地方联合工程实验室,兰州 730070)
高性能混凝土是一种新型高技术混凝土,采用常规材料和工艺生产,根据需要掺入改善混凝土性能的外掺料,使得混凝土结构具有所要求的各项力学性能,增加高耐久性、高工作性和高体积稳定性[1].得益于高性能混凝土的优异性能,高性能混凝土被广泛的应用于建筑行业各个领域.经过养护的混凝土28 d抗压强度是钢筋混凝土结构设计的关键参数,也是衡量高性能混凝土工程性能的重要指标.因此,对于混凝土抗压强度的研究具有较高的科研价值[2].
近几年,随着人工智能技术的迅猛发展,各个行业都在结合人工智能新技术进行自我赋能[3-4].基于机器学习、深度学习的工程类研究也在如火如荼的进行[4-7].许多机器学习理论已经应用到混凝土相关研究中,主要包括:人工神经网络[8],支持向量机[9],集成算法[10]等.Daneshvar等[11]使用随机森林算法,建立了沥青混凝土的动弹模预测模型,预测结果精度可达94.62%.周双喜等基于深度学习理论研究混凝土孔成像分析[12]以及氯离子在混凝土中的扩散模型[13].Ren等[14]基于计算机视觉技术,提出了一种适用于裂缝语义分割的卷积神经网络,为隧道的健康监测提供新方法.Cui等[15]将注意力机制引入混凝土裂缝的语义分割任务中,并提出一种Att-Unet的卷积神经网络,实现了裂缝的准确语义分割.Chun等[16]基于随机森林算法,开展钢筋混凝土结构内部损伤研究,并取得了准确的预测结果.汤志立等[17]基于9种机器学习算法对岩爆进行分类,分类结果表明机器学习算法具有较高的分类精度,其预测结果与现场监测结果有较好的一致性.
基于机器学习的混凝土相关研究已经开展并取得一定成果,但对于混凝土抗压强度的预测研究仍在发展阶段,且应用机器学习算法的研究尚有不足,主要表现为:现有研究多采用单一机器学习算法进行预测,而对于多种算法在同一数据上的适用性对比研究较少[18].针对现有研究的不足,基于随机森林、支持向量回归分析以及多层感知机3种机器学习算法进行混凝土抗压强度预测研究,通过多特征输入构建机器学习模型数据集,以训练、测试、对比不同模型在应用于高性能混凝土抗压强度预测的精度,甄选适用于混凝土抗压强度预测的最优模型.
1 数据
科学合理的数据集选取是实现混凝土抗压强度准确预测的关键.加州大学欧文分校机器学习实验室提供的混凝土公共数据集涵盖了混凝土配合比设计中常见的八种变量且数据集样本数量能够满足机器学习的需求,因此,使用该数据集进行混凝土抗压强度的预测研究[19].该数据集共有1 030个数据,每个数据都包含八个变量和混凝土抗压强度实测值,为提高机器学习的泛化能力与预测精度,在进行机器学习模型建立和训练过程中将八个变量全部作为模型的特征输入.其中八个特征变量输入为:水泥用量,龄期,水,粗骨料,细集料,高效减水剂,粉煤灰,矿粉.输出结果变量为混凝土的抗压强度值.数据集的数值特征统计如表1所列.Q1,Q2,Q3分别表示下四分位数,中四分位数,上四分位数.
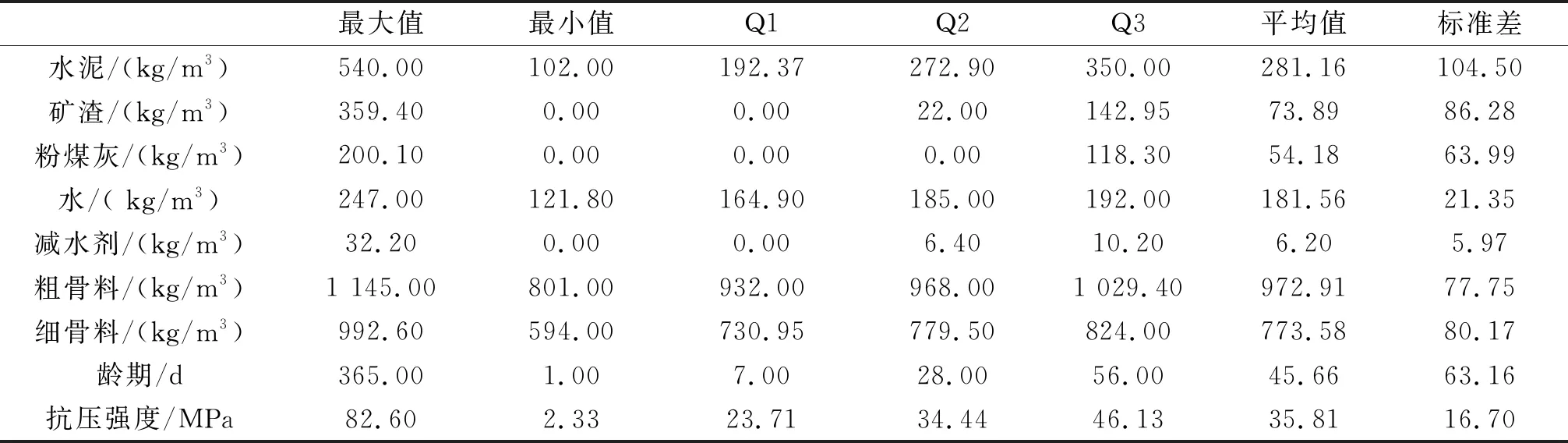
表1 数据集特征统计
2 多特征输入算法研究
2.1 多层感知机(MLP)
多层感知机由感知机发展而来.通常情况下,多层感知机由三部分组成,即:输入层、隐藏层、输出层,多层感知机神经网络模型的原理如图1所示.假设输入样本个数为m,每个样本有n个特征,对于特征输入层X∈Rm×n,以具有h个神经元的隐藏层为例,隐藏层的权重及偏置可表示为Wh∈Rn×h、bh∈R1×h,输出值有q个特征,则输出层的权重及偏置分别为WO∈Rh×q、bO∈R1×q.输入层到隐藏层的激活函数为σ1,隐藏层到输出层的激活函数为σ2.于是多层感知机神经网络模型参数设定如表2所列.
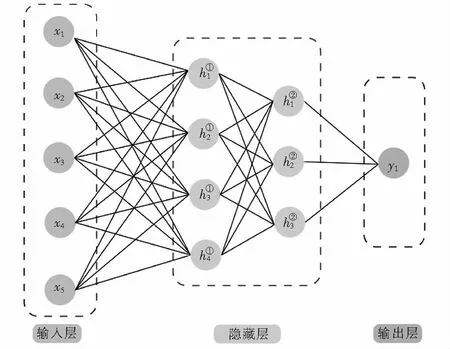
图1 多层感知机原理

表2 神经网络参数汇总表
根据表2的模型参数设定可得:
输入层到隐藏层:
(1)
h=σ1(net1),
(2)
隐藏层到输出层:
(3)
(4)
损失函数取:
(5)
基于前文的模型设定,多层感知机模型的计算步骤为:
1) 初始化神经网络模型中的权值和偏置项
2) 参数向前传播,得到各层输出和损失函数的期望值
(6)
3) 根据损失函数,计算输出单元的误差项和隐藏单元的误差项.
输出单元的误差项,即计算损失函数关于输出单元的梯度值.根据链式法则有:
(7)
(8)
隐藏单元的误差项,即计算损失函数关于隐藏单元的梯度值.根据链式法则有:
(9)
(10)
4) 更新神经网路中的权值和偏置项
输出单元参数更新:
(11)
(12)
隐藏单元参数更新:
(13)
(14)
5) 重复步骤2)~4),直到损失函数小于模型设定的阈值或迭代计算次数,输出此时的参数即为模型最佳参数[20].
2.2 支持向量回归(SVR)
支持向量回归(SVR)算法的建立基于两点原则:1) 模型允许预测值f(x)与真实值y之间存在ε的误差;2) 当f(x)与y绝对值大于ε时,模型的损失函数才进行参数更新.因此,SVR模型以f(x)为中心,以±ε为带宽,构建了一个模型参数不更新区域带,SVR的原理示意如图2所示.在图2中,橙色区域表示允许误差范围内,即参数不更新区域,蓝色实心点表示落在±ε的参数不更新区域条带中,橙色空心在误差允许值之外.SVR的优化目标函数式为[20]
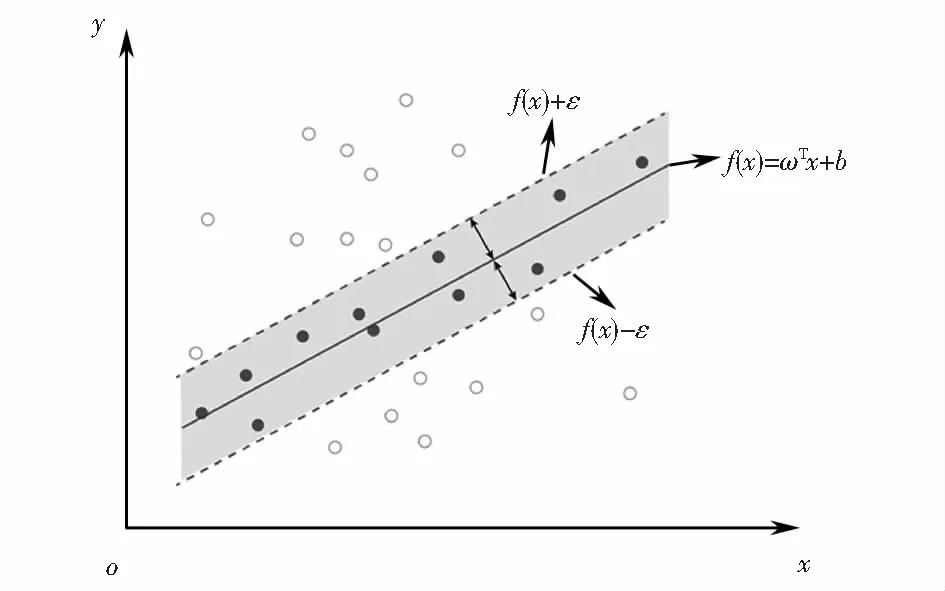
图2 支持向量回归示意
(15)
式中:ω为法向量;C为正则化常数;L为模型优化目标函数;f(xi)为模型的预测值;yi为数据真实标签值.
2.3 随机森林(RF)
Bagging算法是并行集成算法的代表,对于给定的N个样本原始数据集,每次进行有放回的采样,得到一个由m个样本组成的数据集,同样的取样流程进行k次,得到k个训练集,进而基于每个训练集训练一个基学习器.Bagging算法通过训练k个独立的基学习器得到每个基学习器的预测结果,进而对k个基学习器的预测结果进行加权得到整个集成算法的预测结果.
本文的Bagging集成算法采用随机森林(RF)对数据集进行回归分析.RF是Bagging集成算法的一个变种改良模型.RF以决策树为基学习器,通过对若干决策树的集成搭建随机森林模型,同时RF在决策树的训练过程中引入特征属性的随机选择,基于这一机制,RF继承了Bagging集成算法的样本扰动优点,同时在此基础上进行改良,引入属性随机选择的扰动策略.因此,对于同一数据集,随机森林的双重随机性使其具有更好的泛化能力和抗过拟合能力,随机森林的算法原理如图3所示.

图3 随机森林算法原理
2.4 数据集划分与模型参数设定
文中所用混凝土抗压强度数据集包含1 030个数据点,将数据集按照7∶3的比例划分成训练集与测试集,其中训练集用来训练和优化机器学习模型的参数,测试集用来评估机器学习模型的最终预测精度.为排除模型参数设置不合理引起的模型次优化现象,在机器学习模型训练与评估之前,先利用GridSearch[21]方法对不同机器学习模型进行参数优化设定.
3 模型评价与结果
3.1 模型评价指标
为对比分析多层感知机(MLP)、支持向量回归(SVR)以及随机森林(RF)三种机器学习算法在混凝土抗压强度数据集上的表现,选取四个常用的机器学习模型评价指标:R2,MAE,MAPE,RMSE.其中MAE、MAPE、RMSE都是衡量模型误差的评价指标,三者互为补充,用不同类型的误差来衡量模型的预测精度,其值越小,模型的预测精度越高;R2是相关系数,表征模型预测值与数据真实值之间的接近程度,R2越接近于1,则表示模型的预测精度越高.R2,MAE,MAPE,RMSE数学表达式如公式(16)~(19)所示.
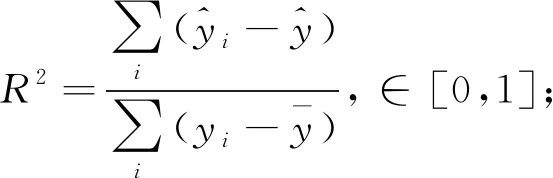
(16)
(17)
(18)
(19)
式中:y为抗压强度真实值;y′为抗压强度模型预测值.
3.2 模型结果对比分析
在各个模型的预测结果对比前,为使各个模型的预测结果更加准确,采用了GridSearch方法对各种模型的参数进行最优化.基于前文建立的模型评价体系,对各个模型的预测结果进行统计分析,其对比结果如表3所列.
分析表3可得:1) 总体而言,对于误差衡量指标(MAE、RMSE、MAPE),随机森林模型的预测结果为误差最小的模型,其次是多层感知机模型,预测误差最大的模型为支持向量回归模型.2) 就相关系数R2而言,随机森林模型达到了0.902,是三种模型中相关系数最高的,这说明对于多特征输入高性能混凝土抗压强度预测任务,随机森林表现出了较高的预测精度,可以为混凝土抗压强度的预测提供一定参考.
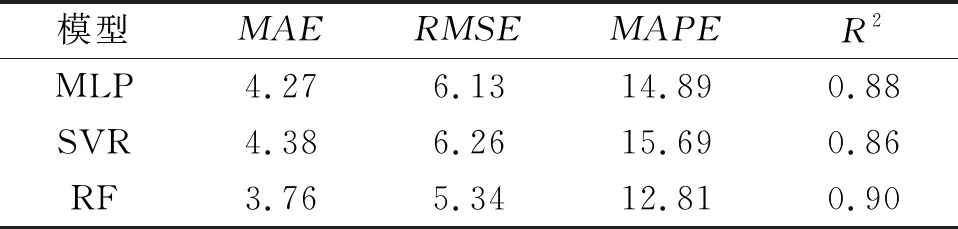
表3 三种机器学习模型对比分析
3.3 随机森林预测结果分析
随机森林模型的混凝土抗压强度预测结果与测试集实际抗压强度的统计结果如图4所示.从图4(a)可以看出:总体而言,对于混凝土不同抗压强度大小,随机森林模型的预测结果与测试集的真实值十分接近,随机森林预测误差标准差均值为3.78 MPa,误差百分比均值为13.73%,体现了随机森林模型用于多特征输入混凝土抗压强度预测的准确预测能力.从图4(b)可以看出随机森林的数据预测绝大部分在±15%误差以内,经过统计,测试集上共有309个样本,其中223个样本的预测结果在±15%以内,误差超过±15%的数据点共有86个.以15%为误差界限,对不同强度区间内的随机森林预测误差进行统计,统计结果如表4所列.从表4中可以看出:随着混凝土抗压强度的增大,超限点所占的比例逐渐减小,这说明随机森林模型对混凝土抗压强度较低时值预测误差相对较大,但随着预测强度的增大,随机森林模型的预测精度逐渐提升,当混凝土抗压强度达到50 MPa之后,随机森林模型预测超限点比例仅占14.41%.由此可见,随机模型对强度较高的数据点预测较为准确.
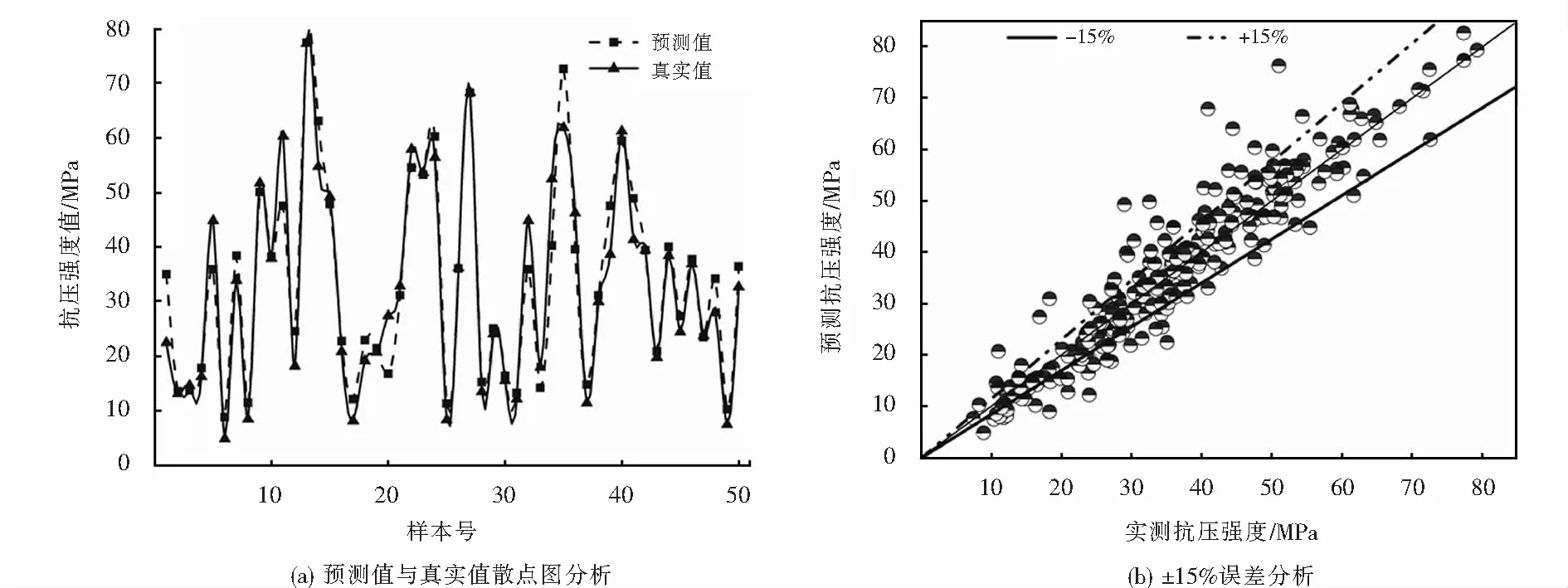
图4 随机森林模型预测结果分析

表4 随机森林预测结果超限统计
3.4 随机森林结果误差分析
为有效评价随机森林模型的预测误差,引入误差贡献率这一指标EC·EC的定义如公式(20)所示.以混凝土抗压强度小于30 MPa的集合为例,以误差±15%为误差界限值,则在该集合中总样本数为55,超限样本数为26,训练集总样本309,超限点总数86,该集合以17.80%的样本占有率贡献了整体模型30.23%的误差,误差贡献率达1.70,这说明随机森林模型在强度低于30 MPa的范围内预测误差相对较大.
(20)
对随机模型测试集上预测结果的误差统计如图5所示,从图5的误差累积曲线可以看出,当模型误差累积到50%时,对应的混凝土抗压强度为28.93 MPa,在误差累积到50%之后,随着抗压强度的提高,误差累积曲线切线斜率逐渐减小.总体上说明,随机森林模型对低强度样本预测误差大,对高强度样本预测误差小.从图5的误差贡献率曲线可以看出:混凝土抗压强度在0~30 MPa时,误差贡献率较高,此时模型对于样本的预测结果误差相对较大,混凝土抗压强度在30~50 MPa时,模型的预测误差迅速下降,当强度达到50 MPa后,模型的误差贡献率趋于收敛,误差贡献率基本稳定在1.0~1.15之间,这说明模型在抗压强度低于30 MPa时具有较高的预测误差,随着抗压强度的增大,模型的预测精度逐渐提高.
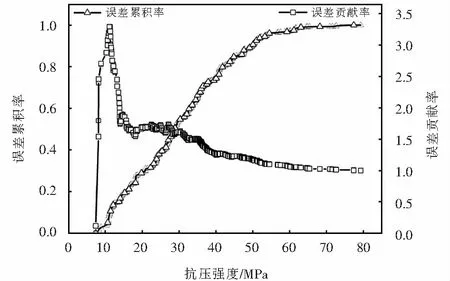
图5 随机森林模型误差曲线
4 结论
1) 将机器学习算法应用到了多特征输入高性能混凝土的抗压强度预测,并取得良好结果,研究结果可为机器学习在混凝土抗压强度预测相关研究提供一定参考.
2) 通过对比随机森林、支持向量回归、多层感知机三种机器学习算法在同一数据集上的表现能力,发现随机森林算法预测精度最高,随机森林算法预测标准差均值为3.78 MPa,误差百分比均值为13.73%,可以应用于高性能混凝土的抗压强度预测.
3) 随机森林算法对于混凝土强度在低于30 MPa的样本预测误差较大,误差贡献率为1.5~3.5,随着混凝土抗压强度的增大随机森林模型预测误差减小,即当混凝土抗压强度达到30 MPa以上时,模型具有较高的预测精度.
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
哈尔滨轴承(2020年2期)2020-11-06 09:22:26
今日中国·法文版(2020年7期)2020-07-04 02:53:48
中国特种设备安全(2019年1期)2019-03-13 01:06:26
电影(2018年8期)2018-09-21 08:00:06
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
作文大王·笑话大王(2016年7期)2016-08-08 11:28:43
山东青年(2016年2期)2016-02-28 14:25:41
