
基于神经网络模型压缩技术的目标检测算法研究
2021-12-28 10:47:26魏志飞宋泉宏杨擎宇王爱华
空天防御 2021年4期
魏志飞,宋泉宏,李 芳,杨擎宇,王爱华
(上海机电工程研究所,上海 201109)
0 引 言
近年来,计算机视觉领域的专家学者在目标检测领域[1]所做的工作逐渐增多,使得卷积神经网络(convolutional neural network,CNN)应用在该领域获得了非凡的成果;随着网络模型层数、结构、体积不断提升,模型的计算量也随之增加,所依赖的计算资源也在不断提高。卷积神经网络的实际应用场景变得越来越广泛,但在许多实际应用中,部署深度卷积神经网络很大程度上受计算资源限制,深度学习模型因无法达到实时性效果难以在嵌入式设备中部署。针对深度学习模型在嵌入式系统中计算资源相比较于服务器资源有限的难题[2],本文开展了基于神经网络模型压缩算法的目标检测算法研究。
网络模型在嵌入式设备中部署主要受限于3个因素;①模型体积,CNN 模型中包含着数以百万计的训练参数,这些参数以及模型结构等运行过程中的相关信息都需要储存在磁盘当中,这些参数对存储资源有限的嵌入式设备来讲是非常大的挑战;②运行时所需内存,模型在前向传播过程中,即便设置批量大小为1,运行过程当中可能会产生非常庞大的中间参数,或许会比存储模型的参数还要多,这对于许多内存有限的设备而言是无法承受的运算载荷;③运行时的计算量,在图像上进行卷积操作,该过程计算量是非常庞大的,这可能导致高性能的深度学习算法模型处理单张图片就需要几十秒甚至几分钟的运算时间,那么将该算法应用于嵌入式设备是不切实际的。
模型压缩算法有很多,如低秩分解、参数量化等,需要为其编制特定的软件和设计相关的硬件方案来实现加速。而通过模型剪枝对网络进行模型压缩,无需特定的软件及硬件设计,就可对模型进行优化,是一种非常有效、便捷的方案。本文采用的是一种基于通道因子对网络模型进行结构剪枝的方法,这是一种简单而有效的压缩策略,它可以解决在资源有限的条件下应用网络模型所面临的问题,可以在保证算法精度损失较小的情况下提高网络模型的运行效率。
1 YOLO算法
YOLO 算法一共有五种系列,分别为YOLOv1~YOLOv5。YOLO 算法是基于单阶段的目标检测算法,将特征提取、锚框回归和分类融合在一个模型当中,与两阶段目标检测算法相比,有着运行速度快的优点。
YOLOv1(you only look once)算法,只需一次神经网络的前向传播运算就可以进行目标检测任务。YOLOv1 算法的主要思想是先把输入图像分成S×S个网格单元,每个单元承担对落入该区域内目标进行检测的任务;每个单元分别预测B个包围框(bounding boxes)、包围框的置信度及C种类别的概率。
YOLOv2 算法引入了R-CNN 算法中锚框(anchor boxes)的策略,采用锚框来提高目标定位的准确度,同时,采用ImageNet 分类数据集和COCO 检测数据联合训练的方式,来提高算法的分类和检测性能。
YOLOv3 算法为了让检测性能得到进一步提高,在YOLOv2 的基础上,借鉴了ResNet 中的残差结构的思路,使得网络的深度进一步得到加深,将原来的Darknet19 网络结构优化成Darknet53 网络结构,这样可使网络模型能更好地提取高层结构中的语义特征,同时,该算法采用了特征金字塔网络(feature pyramind network,FPN)算法的策略,生成3 个不同维度的特征张量,进行多尺度预测,从而使得该算法适应于不同尺度大小的目标检测任务。
YOLOv4 算法在YOLOv3 的基础上采用了CSPDarknet53 和空间金字塔池化(spatial pyramid pooling,SPP)结构,提高了检测器的检测精度能力。
YOLOv5 算法采用了Focus、PANet 等模型结构,同时采用了自适应特征池化的方法,用于聚合多特征层上的信息路径,从而提高了模型预测的准确性。
就算法主体的网络构建而言,YOLOv3 算法与YOLOv4/YOLOv5 算法基本相同,算法的核心思想没有太大变化;就参数量而言,YOLOv3 算法参数量相对较少,具有运算速度更快的优势,故本文选择对YOLOv3算法进行相应的改进和优化。
2 神经网络的模型优化
本文主要是在YOLOv3 算法网络基础上进行两方面的优化和改进,如图1 所示。第一,采用Kmeans++聚类算法对训练集的先验框进行聚类,使得深度学习算法训练速度更快,便于网络模型收敛;第二,对YOLOv3 算法网络结构,采用模型压缩算法中的模型剪枝技术进行裁剪,使得网络能够在不损失较大算法精度条件下,提高算法的运行速率。
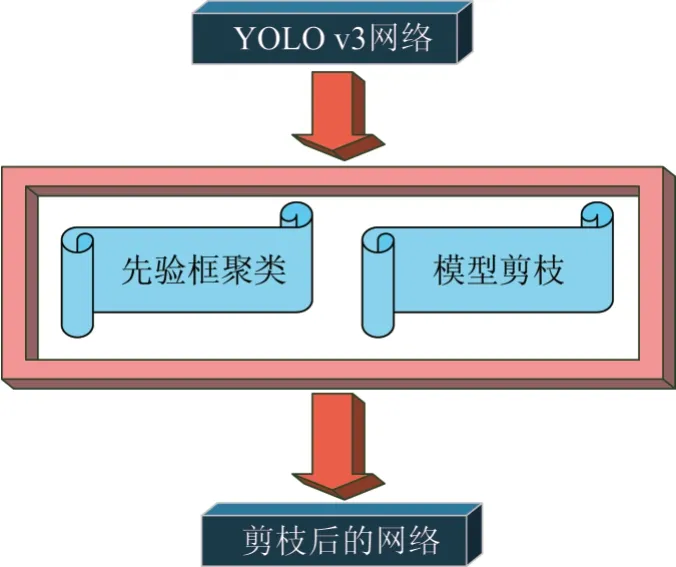
图1 YOLOv3的模型优化Fig.1 Optimization of YOLOv3
2.1 先验框的聚类算法
在Faster R-CNN 算法[3]当中,锚框的初始值是人为设定的,而初始值会影响算法训练的收敛效果,所以根据应用场景中的目标尺寸来设定网络模型中锚框的初始值是非常必要的。因此,针对锚框的初始值设定,使用聚类算法对数据集当中的目标相关信息进行锚框聚类,以便获取比较好的初始值设定。
聚类算法[4],是一种无监督的策略,一般而言,数据的聚类中心选择得越好,算法训练效果就越佳。本文使用K-means++算法进行数据集的聚类。聚类数据为目标的检测数据,数据格式为(xj,yj,wj,hj),j=1,2,…,N,其 中(xj,yj)是锚框的左下角坐标值,(wj,hj)是锚框的宽度和高度,N是锚框的数量。
首先,随机选取k个样本点数据,由于锚框的坐标值是确定的,因此本文采用锚框的宽度和高度作为样本数据,接着计算其他数据从而获取其他聚类中心。
在初始化样本点以后,计算其他点到聚类中心的距离,选取距离最近点成为自身的聚类中心,所有点分配完成以后,对样本点形成的簇重新更新聚类中心,更新的计算形式为Wi=∑wi Ni和Hi=∑hi Ni,其中Ni为第i簇的样本点个数;不断迭代上述计算过程,直到值的改变量几乎不变的时候,便获取到最终的聚类中心,进而确定锚框的初始大小。
聚类算法中,样本点间的距离一般使用欧氏距离来评估,数据集中目标尺度的大小可以分为:大尺度、中尺度和小尺度。采用欧氏距离计算时,会使得大的锚框比小的锚框误差更大。因而采用锚框和真实框有更大的重叠度(intersection over union,IOU)来评估样本点之间的间距,从而避免受到锚框大小的影响,所以算法改进时采用Jake 距离,可适应不同目标的尺度,如式(1)所示。

式中:Bbb为样本的锚框;Ccc为聚类中心;IOU(Bbb,Ccc)为锚框与聚类值的重叠度。IOU 如式(2)所示,表示预测的准确度。
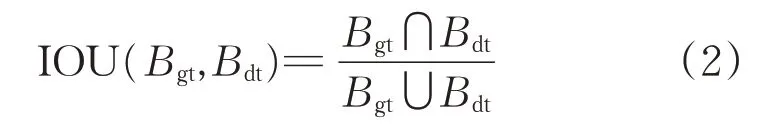
式中:Bgt表示真实框;Bdt表示预测框。
结合式(1)和(2),最终距离可由式(3)计算。

采用聚类算法以后,算法训练过程收敛变得更快。根据实际应用领域对所设计的网络进行重新聚类。
2.2 模型压缩算法优化
本文中,模型压缩算法主要采用模型通道剪枝[5]的方法,该方法分5 个步骤执行,如图2 所示。第一步,初始化网络,可选择高斯初始化或全零初始化等方案,本文采用随机初始化方案;第二步,基于通道稀疏正则化的方法进行训练,在网络中加入通道因子用于识别作用较小的通道(或神经元),这有利于在下面的流程中对网络进行通道级别的裁剪;第三步,裁剪网络,采用通道因子加入到网络层当中对网络结构进行剪枝,从而稀疏稠密的网络结构[6];第四步,微调网络,重新训练被裁剪后的网络结构中剩余神经元连接的权值,不断迭代训练,直到满足网络模型准确度等指标要求后,便得到最终压缩后的网络模型;最后,将压缩后的网络模型输出。

图2 模型剪枝流程Fig.2 Process of model pruning
这种方法的主要实现途径是对网络模型中的批量归一化(batch normalization,BN)层中的通道因子γ加入正则化约束[7]。
每个通道因子γ对应特定的网络层通道,通过L1正则化能够辩知作用较小的通道(或神经元)。这有助于开展后续模型裁剪。当作用较小的通道被裁剪的时候,可能会暂时使网络性能变弱,但后续可对裁剪后的网络进行微调用于弥补裁剪的影响。相比较于起始的网络结构,裁剪后的网络结构在模型大小、运行时内存和计算量等方面更加轻量化[8]。
图3 为通道裁剪示意图,当通道因子γ的值几乎等于0时,就断开网络层之间相应输入和输出的连接,反之,保留网络层之间的连接。如图3所示,当通达因子γ为橙色显示的极小值时,相关连接就被删除,而蓝色表示的网络连接就会被保留[9]。由于通道因子与网络权重是共同训练的,这就使得该策略能够在保留原模型性能的同时对通道进行裁剪。

图3 通道裁剪示意图Fig.3 Diagram of channel pruning
对模型中的通道进行裁剪,会降低网络模型的准确度,因此,需对训练后的模型进行微调[10]。采用整个数据集对裁剪后的模型再一次进行网络训练,恢复起始模型的准确度;最后,便产生了一个裁剪后性能基本不变的网络模型。
3 试验结果及分析
本文的试验环境为:①处理器型号,AMD Ryzen5 2600X@3.6GHz;②存储配置,16GRAM,512G SSD;③显卡配置,NVIDIA GTX1080Ti;④操作系统,Windows 10(64 位);⑤软件平台,Python3.5、Pytorch1.3.0(GPU版)。
本文采用KITTI 公开数据集,因此,需将该数据集标注的txt 数据格式转化为VOC 数据集XML 格式[11];然后,采用K-means++聚类算法对6 500 张训练集数据进行锚框聚类。聚类后的这九个锚框大小的结果从小到大为:(22,19),(46,29),(39,54),(86,52),(71,108),(139,86),(106,161),(231,130)和(289,188);接着,对锚框中的位置数据进行归一化处理,进而提升模型的训练效果。
在神经网络压缩的试验阶段中主要包括了模型的基础训练、稀疏训练、模型剪枝和模型微调4 个步骤[12]。
第一步是基础训练,主要是为获取一个高精度的初始化模型,它的精度和参数选择对后续阶段的训练有着至关重要的作用。第二步是稀疏训练,使用通道因子对网络模型的权重分布进行重新调整。第三步是通道剪枝,裁剪作用较小的通道或神经单元。第四步是模型微调,剪枝后的网络或许会导致网络模型的精度降低,因而对网络模型进行微调,从而复原起始的网络模型准确度。
图4 所示为训练效果,绿色线部分展现的是基础训练,红色线展现的是稀疏训练。在基础训练过程中,训练的图像批次数量(batch_size)设置为32 张,基础训练总次数(epochs)设置为100 次。稀疏化训练过程中,训练的图像批次数量设置为32 张,总训练次数设置为280 次。由图4 可以看出YOLOv3 模型稀疏化训练后模型mAP的变化趋势,模型的准确度在不断地上升,平均准确度mAP在0.8之后变化趋于平稳。

图4 基础训练和稀疏训练效果Fig.4 Results of basic training and sparse training
本文的裁剪率参数设定为80%,模型微调的训练参数中,训练的图像批次大小设为32 张,总训练次数设为100 次。表1 所示为模型裁剪前后的试验结果对比,可以看出模型的参数量、计算量都有着非常大的下降,而剪枝后算法模型的运行速率是未剪枝算法模型的2 倍左右,而网络模型的平均准确度mAP 没有太大的损失。试验结果显示,对网络模型进行网络剪枝,能保证原算法模型准确度不损失的同时,明显加快网络模型的运行速率。

表1 YOLOv3模型剪枝前后对比Tab.1 Comparison of YOLOv3 model pruning and unpruning
为了更直观验证,使用通道剪枝后的YOLOv3 算法对KITTI测试集上的图片进行场景内的物体测试,如图5所示。

图5 测试效果Fig.5 Test result
由图5 测试结果可以看出,采用通道剪枝后的YOLOv3网络模型依然拥有着较好的检测性能。
4 结束语
本文提出了一种基于神经网络模型压缩技术的目标检测算法。先采用K-means++算法对数据集的先验框进行聚类;接着采用基于模型通道剪枝的模型压缩算法对神经网络进行模型压缩;最后通过试验验证了使用模型通道剪枝裁剪YOLOv3 模型有良好效果。可以看出,本文在保持着高准确度的情况下,能减小模型的参数数量和模型体积,也能有效提高模型的运行速度。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
保健医苑(2022年5期)2022-06-10 07:47:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
建筑科技(2018年6期)2018-08-30 03:40:54
天津诗人(2017年2期)2017-03-16 03:09:39
中国交通信息化(2016年5期)2016-06-06 03:51:43
天津冶金(2014年4期)2014-02-28 16:52:58
