
中文文本主题聚类算法研究综述
2021-12-24 13:37徐菲菲陈赛红
上海电力大学学报 2021年6期
徐菲菲, 陈赛红
(上海电力大学 计算机科学与技术学院, 上海 200090)
在网络日渐发达的背景下,各式各样的信息交流平台随之出现,比如微博、微信朋友圈、今日头条、网易、腾讯等,人们可以通过这些网络平台了解各类主题信息,并发表自己的观点。这些大量的信息数据以文本形式为主,人们急需计算机机器对这些庞杂的文本信息进行高效分析。在此背景下,自然语言处理研究热潮应运而生。聚类算法无疑可作为处理庞杂信息所带来的问题的有效手段。与文本聚类相比,文本分类需要大量的训练集进行训练,并在分析训练集内容的基础上根据已有的类别给测试集分配一个或多个类别。文本聚类则依据文本内容和结构关系确定该文本属于哪个类别,该过程称为文本聚类中的文本分析和文本标记。文本分析和文本标记有利于挖掘文本内部信息,可以作为一种消除歧义的文本预处理步骤[1]。文本聚类算法可以节省检索成本,协助用户得到感兴趣的信息,进而提高文本检索的精度和效率[2]。文本聚类可用于图书馆服务的文档自动整理[3-4],也可用于发现并跟踪网络热点话题,诊断出网络中存在的病毒,对加强网络安全具有重要意义[5]。
文本主题检测旨在不浪费人工成本的前提下获取文本阐述的核心主题、多个主题间的关系以及界定主题的外延等。它是很多文本处理领域中的重要组成部分,比如文本理解、语言建模、信息检索、文本分类和聚类等[6]。当前的研究工作大多集中于英文文本,原因在于两个方面:一是计算机对于英文文本的研究处理先于中文文本;二是目前英文数据语料库相对完整且易于采集。中英文存在着较大的差异,这导致中文文本研究方法无法直接引用英文文本研究中成熟的理论知识和关键技术。本文系统整理了当前中文文本主题检测方法,尤其关注主题模型、聚类方法及其存在的缺陷,并提出了未来的研究方向。
1 国内外研究现状
在国外,学者们对话题检测的研究已经取得了很多成就。文献[7]提出了一种崭新的近似算法,将其运用于话题检测的实际问题中,并利用分阶段算法对其进行了分析。文献[8]为了改善实验过程中的运行速度,在指标Precision(准确率)的基础上提出了一种新颖的挖掘话题的算法。文献[9-10]对相关检测算法进行了优化改进,并运用博客上的网络文章进行热点话题的挖掘。文献[11]第一次将实时性列入识别话题算法的评判指标,对话题的实时性作出了相关的实验证明。该评判指标后期得到了广泛应用。文献[12]研究了实时Twitter流的事件检测技术,将Twitter和微博等各种社交网络的文章用于话题检测。文献[13]将关联性强的节点作为话题词,并将话题词作为关键词挖掘出了网络平台上的相关文章。文献[14]提出了基于改进的Single-Pass聚类(单遍聚类)的MC-TSP算法发掘话题,并采用词位置信息TF-IWF-IDF方法表示博客文章内容向量,最后在博客数据集上验证了改进算法的准确性和效率。文献[15]提出了基于动态概念划分的问答系统的话题追踪与分析的算法,并在文本语料库上证明了该算法适用于动态文本数据流。文献[16]采用有监督学习算法抽取文本关键字,将关键字作为结点构建词图,利用图的分割技术将图分成子图并从子图中抽取话题词,再按照文本的话题词对文章进行聚类,最后插入Story Forest系统中。文献[17]利用Twitter流数据在线检测话题子事件,使用卡尔曼滤波器、高斯过程和概率主成分分析3种统计方法,将话题子事件识别过程定义为异常检测问题。文献[18]利用Twitter流的时间顺序并考虑其序列性质,将社交媒体流中的话题子事件检测问题构造为序列标记任务,其本质上是根据上下文内容对线性序列中每个元素进行分类。
近几年,国内学者也进行了相关研究。李倩[19]在原始单遍聚类算法的基础上提出了相应的改进算法,在微博数据集上进行话题识别。万越等人[20]提出一种基于数据时序性的动态增量模型,在模型中将用户的行为看成特征,以此检测微博中突发事件的解决方案。李新盼[21]将改进后的Single-Pass聚类(单遍聚类)与传统的层次凝聚聚类算法相结合,在微博数据集上验证了该算法的可行性。林丹等人[22]提出了一种新型算法——文本关联算法,利用传统的文档主题生成模型(LDA模型)[23]挖掘舆论关心的热点,对LDA模型得到的话题词进行聚类分析,并对实验结果提出了优化调整的想法。周楠等人[24]提出了一种基于语言模型的PLSA算法,经过Wiki数据集上的实验证明,所提出的算法比基线算法更有优越性。王圣[25]提出了一种基于细粒度文本的话题检测算法,在大规模的网络数据中筛选出需要的话题信息并获取其他话题信息,以此掌握所有次话题分布情况。谭梦婕等人[26]在新闻数据集上提出了一种基于时间切片的文本数据流算法,依据前后文本的句子含义提取文本关键词,利用K近邻算法和层次凝聚聚类算法获取话题簇。张瑞琦[27]利用关键词作为文本特征进行聚类分析,进一步生成了排名前N名的热点话题。陈笑蓉等人[28]提出了一种基于距离的文本聚类重构算法,对非正常和相似集群分别进行调整及合并,最后用实验证明了算法的合理性。田诗宵等人[29]在二维主成分分析法的基础上提出了一种适用于文本聚类的算法,并在海量数据集上实现文本聚类的并行处理。周炜翔等人[30]建立了IDLDA模型,将隶属于同个话题的内容归类至同一个集合,利用改进的字符串编辑距离方法建立模型以获取内容摘要和核心特征,然后将核心特征词变成话题短语,最后结合短语和摘要来阐述文本话题。
综合国内外研究现状,很多研究人员在中文长文本或者短文本进行主题检测,并取得了相应的成果,但在中文长短文本共存的形式下,还有很大的研究空间,值得进一步探索。
2 主题检测聚类相关技术
2.1 文本处理
(1) 文本采集与清洗。利用Python中Requests,Selenium,BeautifulSoup,Scrapy等爬虫工具将所需要的文本信息爬取到目标文件中。爬取到的内容中可能包含干扰信息,对文本内容没有任何解释作用,如链接等,类似于这种干扰信息被称为噪声。因此,在清洗阶段需要使用相关技术删除噪声内容,只保留有用信息,如发布信息、文本标题和正文等。
(2) 文本分词。与英文相比,中文中两个词之间有间隔,相应地,这两者的处理方式也存在着不同。英文文本在该阶段称为词性还原,而中文文本在该阶段称为文本分词。为了让机器能够识别中文词语,必须对文本进行分词预处理。中文分词方法事先设置一个词典,然后对照文本与词典,最后实现文本分词。Jieba,Pkuseg,LTP,THULAC,SnowNLP,CoreNLP,HanLP等是当今较为主流的分词库。
(3) 去停用词。文本数据集通常会含有没有表达意义但出现的频率较高的词语,如嗯、哦、么等。这些高频率词的出现会增加文本间的相似度,给后续的发掘主题关键词和文本聚类带来一定的困难。因此,该阶段需借助停用词表进行删除操作。停用词表通常包含实词和虚词两类,实词在句子中有实在意义且能独立充当句子成分;虚词在句子中没有任何的表示意义且不能充当句子成分,如介词、副词、连词等。
2.2 文本表示
经过上述过程之后,文本集形成了碎片化的文本信息,但是计算机无法识别这些文本信息,因此人们需要作进一步的处理使得这些信息能够让计算机识别。构造文本表示模型的目的是将一个无规律无序的文本结构转换为一个有规律的结构模型,并从文本主题、文本语义结构等方面表示文本内容,其在文本处理领域中占据重要地位[31]。常用的文本表示模型主要有向量空间模型、统计语言模型和主题模型,前两者主要研究主题检测过程,未充分考虑文本的语义,影响了主题检测的准确性。随着主题模型研究的深入,很多研究人员聚焦于主题模型以实现主题建模,主要是通过主题语义信息,将文档映射至主题语义空间,从而生成语义特征表示[32]。
2.2.1 向量空间模型
向量空间模型(Vector Space Model,VSM)是将文本转换为空间向量运算模式,通过向量在空间上的相似度表示词语间的相似度,其主要思想是将某篇文章通过词袋模型表示为很多独立的词。这些词通常保存至词典D中,因而可将其转换为N维向量(N表示词典的大小)[33]。D中词语数量值作为向量的维度,维度的大小通常表示某个特征词在文档中的权重,权重的大小反映了该特征词在文档中的重要性。向量空间模型中特征向量可表示为
V(d)=(ω1,t1(ω);…;ωm,tm(ω))
(1)
式中:ωm——词典中第m个词;
tm(ω)——ωm的权重,即ωm在文档中的重要程度。
目前TF-IDF方法被视为具有一种最常用的对词语权重进行计算的研究形式。该方法可通过计算tm(ω)提取文本特征。
TF-IDF,也称为词频-逆文档频率,是一种用于数据挖掘的统计学方法。TF-IDF由TF和IDF共同决定,即为TF-IDF=TF×IDF。其含义为:某词W在某篇文章中出现得很频繁,但在数据集的其余部分中出现的次数较少,则说明该词在文本聚类中的重要程度较大。
(2)
(3)
式中:TF——某个词语W在该篇文章中出现的次数,即频率;
IDF——度量词W的重要性程度,由总文件数目除以含词W的文件数目,再取10的对数即可得到。
2.2.2 主题模型
VSM模型虽然思想简单易懂,但忽略了词语间的语义关系,在处理大规模文本数据时,词典D的大小会随着数据量的增加而增加,从而扩大文本向量的维度,给文本挖掘带来诸多不便[34]。
主题模型是基于无监督学习形式的具有潜在语义结构实施文本聚类的统计学模型[35]。LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为三层贝叶斯概率模型[23],通过文档-词共现来发现话题,并在文本话题检测领域有不错的效果[36-37]。其过程如图1所示。
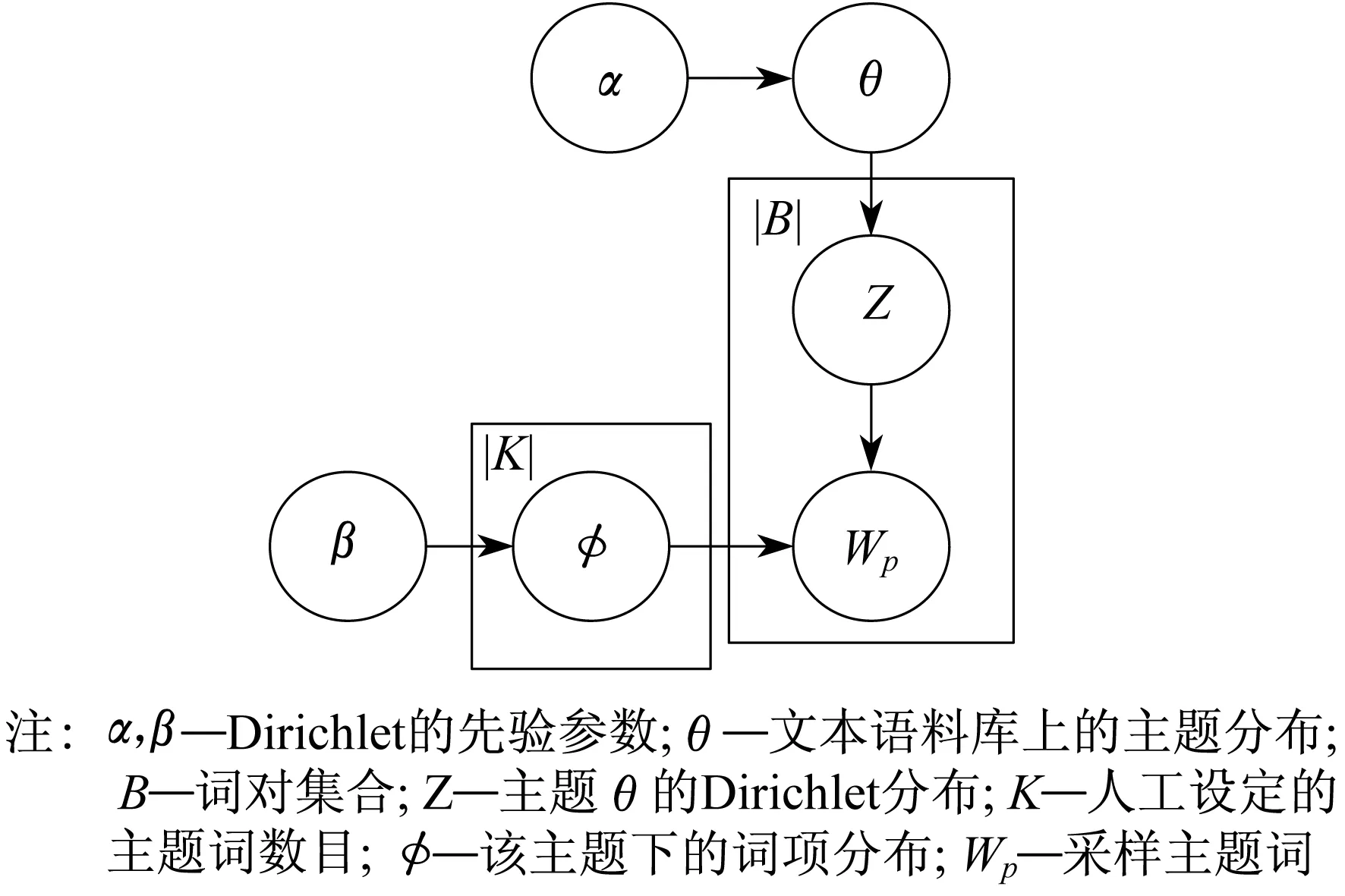
图1 LDA模型
针对LDA模型在处理短文本中都会面临特征稀疏的缺点[38],YAN X H等人[39]提出了BTM(Biterm Topic Model)模型,如图2所示。

图2 BTM模型
该模型可以利用网络语料级别的词共现模式,通过聚类算法来解决上述文本稀疏的缺点,将语料看作是一组话题的混合,每个二元词组都来自于某个话题。计算一个二元词组隶属于某个话题的概率是由二元词组中两个词共同决定的。这样,不仅在微博短文本上具有明显优势[40-41],而且在其他各类文本处理中也优于其他主题模型[30]。
记Mult()为多项分布,Dir()为Dirichlet分布,具体操作步骤如下。
(1) 对于每个主题Z:计算特定主题的词分布φZ~Dir(β);计算整个语料库的主题分布θ~Dir(α)。
(2) 对词对集合B中每个词对b:计算主题分布Z~Multi(θ);绘制两个词Wp,Wq~Mult(φZ)。
按照上述步骤,一个词对b的联合概率可表示为
(4)
因此,整个语料库的可能性概率计算式可表示为
(5)
从上述步骤可以看出,BTM模型将单词共现(词对b)模式作为传达主题语义的单元。与LDA中单个单词的出现相比,词对可以更好地揭示主题,从而增强主题的学习能力。 为了更好地体现BTM模型的独特性,本文对比了LDA模型(图1)和BTM模型(图2)。图1中,LDA模型首先计算文档级主题分布θ,然后迭代采样文档中每个单词Wp的主题分布Z。由于每个单词的主题分布Z依赖于同一文档中的其他单词,因此LDA在推断单词主题分布时过分依赖本地观察,同时损害了主题分布θ的学习。与LDA不同,BTM模型通过从语料库级主题分布θ中计算主题分布Z,可同时捕获文档中的多个主题梯度。由此可以看出,BTM模型不仅克服了LDA的过分依赖问题,而且还保留词与词之间的关联性。
2.3 特征选择
由于文本数据集通常有数万甚至数十万级别的词组,因此会造成向量维数急剧增加的局面,相应地,计算机运算十分困难,会消耗较大的内存空间。为了降低问题的规模,同时提高算法的效率,算法应该选择最具有代表性的特征项。常用的特征选择方法有文档频率、信息增益、卡方校验、互信息等[39]。
2.4 文本相似度计算
经过上述步骤后,下一步要处理的是文本主题的跟踪并实现文本聚类。在聚类算法中,文本相似度计算广泛应用于主题检测等方面。因此,在各种不同的情况和任务中,有不同的文本相似度计算,主要有余弦相似度、欧式距离等[42]。
设di和dj表示两个文本矢量,di=(ωi1,ωi2,ωi3,…,ωin),dj=(ωj1,ωj2,ωj3,…,ωjn)。常用相似度计算公式如下。
(1) 欧式距离
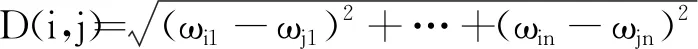
(6)
(2) 余弦相似度
(7)
式中:n——文本向量的维度;
ωik——第i个向量第k维的大小;
ωjk——第j个向量第k维的大小。
2.5 聚类算法
聚类算法作为一种无监督的机器学习方法,不需要大量的训练集,因此具有较高的灵活性。目前,聚类已成为一种对文本进行智能推荐、摘要和导航的重要手段,被很多研究人员所关注[43]。文本聚类主要依据:相同类别的文本具有更大的文本相似度,不同类型的文本具有较小的文本相似度[44]。基于划分的聚类算法、基于层次的聚类算法和基于密度的聚类算法是比较常用的3种聚类算法。
2.5.1 基于划分的聚类算法
基于划分的聚类算法的代表性算法是K均值聚类(K-Means聚类)。其基本思想是:首先随机选取K个点作为初始聚类中心,然后根据欧式距离计算公式,将距离聚类中心最近的数据对象,划分为一个簇,以此迭代,最后根据各类数据点平均值更新各簇的聚类中心,直至聚类中心不再变化。因此,该算法原理简单易懂。通过实际证明,对大规模的数据集,该聚类算法具有高效性,但是该算法对初始点的选取较为敏感,需要人为设定K值,结果易陷于局部最优,同时该算法容易遭到异样点的困扰而构成重大偏差[45]。
2.5.2 基于层次的聚类算法
层次聚类(Hierarchical Clustering)依据所有数据点间的相似度构造一棵具备不同层次的嵌套聚类树。构造嵌套聚类树的方法有凝聚层次聚类(自下向上)和分裂层次聚类(自上向下)两种。凝聚层次聚类算法依据某两类数据点的相似度,兼并最为类似的两个数据点,并重复上述步骤直至满足终止条件。简言之,该算法是通过计算每个类别中数据点与所有数据点之间的间隔来确定它们间的相似性,距离越小,相似度越高,同时,兼并间隔最近的两个类别或者两个数据点,最后生成一棵聚类树[46]。分裂层次聚类首先将所有数据点视为一个簇,然后根据相似度计算方法分为两个簇,如此反复,直至各个数据自成一簇或者达到终止条件,最后建立一棵具有自上向下结构的层次聚类树。
由此可知,基于层次的聚类算法易发现各个形状的簇,适用于任何模式的相似度和间隔的表示方式,具备较高的灵活性;但该类算法的终止条件没有明确的规定,会引起算法的无限循环,不能及时终止。此外,该算法无法处理大规模的数据或者实时动态数据集。常见的层次聚类算法有BIRCH算法、CURE算法、CHAMELEON算法等。
2.5.3 基于密度的聚类算法
DBSCAN算法是基于密度聚类算法的典型代表,当数据中某个区域的密度满足某一前提时,将该区域划分为一个簇,并在空间数据库有一定噪声的条件下,发现任何形状的簇,簇的收缩性较强,最后得到的簇中数据点是密度相连的最大集合[47]。DBSCAN算法首先设定间隔阈值和密度阈值,目的是通过两个阈值来标注所有的数据对象;其次随机选择一个种子,该种子不属于任何一个类,找出与该种子密度可达的所有数据点集合(该集合可视为聚类的一个簇);重复上述步骤,直至所有数据分析对象都有其相应的类别。若由距离阈值确定的数据不在任何一个核心数据对象周围,则将该数据视为噪声点进行消除。
由此可看出,DBSCAN算法可自动确定聚类数目,适用于任何形状的簇,但是对于大型的数据集,需消耗较大的内存;同时,文本数据密度不均匀或者类别间的距离相差太大,都会影响聚类结果。
3 未来研究方向
在未来,研究工作可以从3个方面进行拓展:
(1) 调整聚类算法的参数,直至选择一个最优参数或者将聚类算法与优化算法相结合;
(2) 探索主题模型的优化方法,以挖掘出更有说服力的主题词;
(3) 进一步研究基于长文本和短文本共存的话题检测,如一篇新闻文章会有多个评论,新闻文章属于长文本,评论属于短文本,从短文本挖掘出主题补充说明长文本的主题,以确保整个话题更连贯,更全面。
4 结 语
本文梳理了主题检测的国内外研究现状,详细分析了主题检测的关键步骤和聚类算法的不足之处,并提出了未来的研究方向,以期为中文文本主题聚类算法的进一步发展提供参考。
猜你喜欢
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电脑爱好者(2017年7期)2017-05-06
雷达学报(2017年6期)2017-03-26
高中生学习·高三版(2016年9期)2016-05-14
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
新高考·高二数学(2015年11期)2015-12-23
