
人脸表情识别综述
2021-12-24 13:37魏为民孟繁星
上海电力大学学报 2021年6期
魏为民, 孟繁星, 才 智, 刘 畅
(上海电力大学 计算机科学与技术学院, 上海 200090)
人脸识别技术作为生物特征识别技术的一种,以其安全便捷的特性得到了广泛应用。但是各种各样的类内干扰(如光照、年龄和表情等)使得人脸识别面临着非常大的挑战。人脸识别技术需要用户在未配合的状态下进行身份识别认证,就涉及到不同表情的干扰问题。近年来,越来越多的研究机构关注到了在表情干扰情况下的人脸识别技术,不仅在理论层面推动人脸识别技术的研究,也在应用层面推动人脸识别技术的普及推广。
自从20世纪60年代最早的人脸识别系统创建以来,人脸识别已经有将近60年的研究历史。文献[1]提出人脸识别发展主要经历了4个阶段。第1阶段主要包括基于几何结构的算法、基于模板匹配的算法等;第2阶段主要包括Eigenfaces特征法、隐马尔克夫法、奇异值分解法等;第3阶段包括基于局部二值模式(Local Binary Patterns,LBP)[2-3]、方向梯度直方图(Histogram of Oriented Gradient,HOG)[4]、尺度不变特征变换(Scale-invariant Feature Transfrom,SIFT)、支持向量机(Support Vector Machines,SVM)、稀疏表示法;第4阶段包括卷积神经网络(Convolutional Neural Network,CNN)、三元组损失函数和DeepID等。1971年,EKMAN P等人[5-6]对表情做了6种基本的分类,包括愤怒、惊讶、快乐、悲伤、厌恶和恐惧。传统的表情识别方法(例如HOG和LBP)主要采用手工提取特征的方法,然而手工提取特征的方法受到人为规则的约束,在某种程度上其识别的精度会受到影响。随着机器学习的发展,基于深度CNN的特征提取越来越受到人们的关注。通过深度CNN提取到的特征,信息表达更丰富,可以解决传统手工提取的弊端。深度学习已经成为人脸识别领域的热点,越来越多的新方法在性能上也逐渐超过传统的人脸识别方法。
1 人脸表情识别技术
文献[7]提出表情识别主要包括人脸图像、检测与定位、图像预处理、特征处理和人脸识别等步骤。图1是表情识别的主要流程。
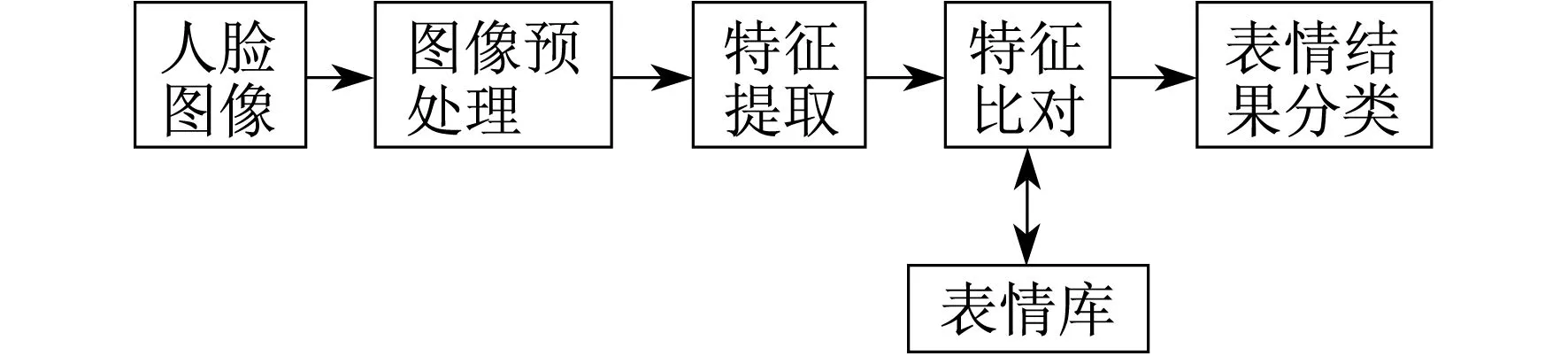
图1 人脸识别流程
人脸表情识别的第1步是进行图像采集,其中图像采集又包括动态采集和静态采集。动态采集主要是监控摄影机等拍摄的视频镜头,这种视频镜头获得的人脸图像相对更加完整;静态采集主要是通过照相机、扫描仪的方式获取人脸图像,这种图像相较于动态采集,质量较差。第2步是检测与定位,人脸的检测与定位是指在输入的图像中是否存在人脸图像以及人脸图像的数量等,如果存在人脸图像,那么就要对该图片进行人脸的定位,给出每个图片中人脸的具体位置、姿态以及大小等要素。第3步是对图像进行预处理,原始图像总会引入一些不可避免的噪声,预处理的目的就是将这些噪声尽可能地降低。第4步是特征提取出和人脸识别,通过特定的算法对预处理的图片提取关键的特征,然后对其进行分析。不同的人脸表征方法会提取出不同的人脸信息,例如基于几何特征的人脸识别算法会提取出人脸重要部位的几何关系作为特征点[8]。
2 常用表情数据库
在人脸表情识别中所有提出的新方法和技术都需要在表情数据集上进行实验验证,已经有许多数据集用于实验和比较。传统方法上,用2D静态图像或2D视频序列进行人脸表情的研究。现在表情识别研究成为了该领域的热点问题[9],对3D人脸图像的表情进行分析更有利于理解表情识别中的细微变化[10]。下面对应用于人脸表情识别的主流数据库进行总结。
2.1 JAFFE数据库
日本女性人脸表情数据库由213张女性表情组成,都是灰度图像。分为7种面部表情,包括6种基本的面部表情和1种中性面部表情。每张图片的原始尺寸都是256×256像素。该数据集的缺点是图片数量太少,不能用于要求较高的实验技术中,优点是囊括了人类的所有表情,即表情种类比较丰富。表1是 JAFFE数据库中各表情的数目分布情况。图2是JAFFE各表情部分样例展示。

表1 JAFFE数据库各表情的数目分布情况

图2 JAFFE各类表情展示
2.2 CK+人脸表情数据库
CK+人脸表情数据库[11]是由123名参与者的593张图片序列组成。这些参与者的年龄18至30岁,大都为女性,其中包括81%的欧美人种,13%的非裔美国人种,6%的其他人种。这593张图片序列每个都包含动作单元标签。其中有327张带有表情标签,包括自发表情和摆拍表情。这些图片的大小有两种,分别是640×480像素和640×490像素。
2.3 FER2013人脸表情数据库
FER2013人脸表情数据库[12]是Kaggle网站在2013年的人脸表情大赛中发布的人脸表情数据库。该数据库包括35 887张图片,所有的图片都是灰度图像,包括了7种人脸表情,而且还对这些表情进行了数字编号,编号如下:0为生气;1为厌恶;2为恐惧;3为快乐;4为悲伤;5为惊讶;6为中性。所有的图像均是48×48像素。图3为FER2013人脸表情数据集部分样例图。
图3 FER2013人脸表情数据库部分样例
2.4 BP4DSpontanous人脸表情数据库
BP4D-Spontanous人脸表情数据库[8]是一种3D视频数据库,由41位年轻人的表情组成,其中包括23位年轻的女性,18位年轻的男性;年龄18至29岁;11个亚洲人种,6个非裔美国人,4个西班牙人,20个欧裔美国人。该数据库为精细面部表情的三维空间的探索奠定了基础。
2.5 Yale人脸表情数据库
Yale人脸表情数据库由耶鲁大学创建,收集了15位志愿者的表情。这些图像是在不同的光照和姿态下拍摄的,每位志愿者都有11张人脸图像。该表情数据库的规模较小,适合像家居这种人脸存储量较少且环境场景较复杂的情况使用。每张图片均为100×100像素。
2.6 KDEF人脸表情数据库
KDEF人脸表情数据库[13]由瑞典斯德哥尔摩心理学系临床神经科学系Karolinska研究所的LUNDQVIST D,FLYKT A,ÖHMAN A 3人于1998年开发。该材料最初被开发用于心理和医学研究目的。更具体地说,材料被制成为特别适合于感知、注意力、情感、记忆和后向掩盖实验。因此,要特别注意创建柔和、均匀的光线,多角度的拍摄表情,使用统一的T恤颜色,在拍摄过程中使用网格使参与者的脸居中以及固定眼睛和嘴巴的位置。该集合包含70个个体,每个个体展示7种不同的情感表达,每个表达都从5个不同的角度进行了拍摄。
3 表情识别研究方法
3.1 传统方法研究
人脸表情识别技术主要有特征提取和特征分类两方面。传统方法对静态图像的特征提取主要有LBP特征、主成分分析(Principal Component Analysis,PCA)以及Gabor等,对于动态图像的提取主要包括光流法、模型法和几何法。ZHAO G等人[14]提出了利用LBP-TOP算法进行特征提取,并且和SVM相结合进行特征分类。SHAN C等人[15]利用LBP和AdaBoost对表情图片进行特征提取,再结合SVM进行分类,这种方法的效果显著。黄非非[16]对LBP做了改进,提出一种多尺度的LBP特征提取技术,这项技术对特征维数做了改进,在数据集上进行实验,效果良好,并且具有良好的鲁棒性。OLIVERIRA L等人[17]提出了使用二维主成分分析(2DPCA)算法提取图像表情特征,并使用基于多目标遗传的特征选择算法获取数据,有效地提高了识别率,并且也降低了计算的难度。邵洁和董楠[18]提出了一种基于人脸3D特征点的实时检测方法,建立了基于广义普鲁克分析(Generalized Procrustes Analysis,GPA)算法的特征归一化模型,采用SVM进行人脸表情特征匹配,不仅能够检测不同角度的人脸表情特征,而且具有实时检测的特点,但方法存在的不足是未引入纹理特征,若引入纹理特征那么检测精度将进一步提升。
2015年,LUO Y等人[19]提出了利用PCA算法提取表情图像全局特征,再利用LBP提取表情区域的眼睛和嘴巴的区域特征信息。这种方法是对LBP算法容易受到噪声、光照等因素影响的改进,并且改进了现有的融合算法的不足。2016年,KUMAR S等人[20]对传统的LBP进行了优化,使用加权投影的LBP算法提取特征信息,取得了较好的识别效果。李玉朵[21]提出了融合式的二维Gabor小波、Fisher线性判别和PCA,可以很好地解决小样本问题,同时避免了维数过高的问题。2018年,SAHA A等人[22]提出了一个使用特征空间算法和PCA从输入图像中识别人的面部表情的系统。该特征空间对已知面部图像之间的变化进行编码,并使用PCA来缩小面部图像的尺寸。该方法经过3个不同的数据集进行验证,效果显著。BOUGURZI F等人[23]提出结合使用PCA变换后的手工特征和深层特征,从静态图像中识别6种基本面部表情。介绍了金字塔多级(Pyramid Multi Level,PML)人脸表征在面部表情识别中的使用,通过PML获得手工制作的特征。通过CK+,CASIA,MMI数据库确定3个手工描述符(HOG,LPQ,BSIF)的PML功能的最佳级别,然后将它们与转换后的VGG层(FC6和FC7)结合在一起,以获得紧凑的图像描述符。该方法经过在CK+和CASIA数据库上测试,其结果优于其他静态方法。
为解决Gabor滤波器获取人脸特征数据存在冗余信息以及提取的表情特征单一的问题,文献[24]提出了基于LGRP和多特征融合人脸表情的识别方法。该方法首先提取表情图像的Gabor多方向和多尺度特征,并得到局部Gabor排序模式,然后,引入Haar小波和Otsu阈值分割法分别提取特征,最后使用SVM对人脸表情进行分类。
表2给出了不同特征提取方法在JAFFE数据库上的识别准确率。

表2 不同特征提取方法的识别准确率
光流法在模式识别、计算机视觉以及其他影像处理领域中非常有用,可用于运动检测、物件切割、碰撞时间与物体膨胀的计算、运动补偿编码,或者通过物体表面与边缘进行立体的测量等。早期的人脸表情识别算法多采用光流法提取动态图像的表情特征,主要在于光流法具有突出人脸形变、反映人脸运动趋势等优点。因此,该算法依旧是传统方法中用来研究动态图像表情识别的重要方法。光流法的优点是受光照不均的影响较小,反映了表情变化的实质,缺点是计算开销大。文献[25]将人脸关键点与金字塔光流相结合,提出了基于级联网络和金字塔光流的旋转不变人脸检测算法,主要解决的是视频中面部检测存在的平面旋转问题。该算法检测速度较快,并且很好地解决视频窗口抖动问题。文献[26]提出将主动表观模型与Lucas-Kanada光流法相结合的表情识别方法。利用高斯金字塔光流法跟踪表情帧中的表情特征点,将表情变化信息作为人脸表情特征,最后通过SVM进行表情分类。经过Cohn-Kanade+人脸表情数据集的验证,来显著提高表情识别的准确率。
在表情特征提取方法中,人脸表情的产生和面部的器官有很大联系,所以考虑到表情特征集中区域可能是在面部主要器官处,在面部器官区域标记特征点,计算特征点之间的距离和特征点所在曲线的曲率,就是几何法。文献[27]提出了基于几何和纹理特征的表情层级分类方法,更好地利用了特征自身分布的特性。所提方法在JAFFE和CK+数据库上的实验结果表明,比一般几何纹理的识别效果更好。
3.2 深度学习的表情研究方法
近年来,随着机器学习的发展,深度学习在人脸表情识别领域已经取得了突破性的进展,如采用CNN和递归神经网络进行模式识别、特征提取和任务分类。CNN的主要优点是实现端到端的学习[28],减少对人脸模型和预处理的依赖,已经被广泛应用于物体识别、人脸识别和表情识别等。
文献[29]主要回顾了基于CNN的面部表情识别的6种方法,并且比较了它们之间的不同,指出了现有的人脸表情识别性能的困难并确定了以后研究的大致方向。
为了解决现有算法需要依赖人工设计的缺点,文献[30]提出了基于深度时空域卷积神经网络的表情识别方法。使用新的卷积滤波器响应积替代了权重和,并且采用数据驱动的方式,自动提取时空中的动态特征和静态特征,通过比较得出该方法优于其他方法。
文献[31]提出了一种新的深度学习框架。该框架将CNN与长短期记忆网络(Long Short-Term Memory,LSTM)单元相结合,用于实时面部表情识别。该框架主要包括3个方面:一是采用两种不同的预处理技术来处理照明差异并保留每个图像的细微边缘信息;二是将预处理后的图像输入到两个单独的CNN架构中,可用于提取空间特征;三是将来自两个独立CNN层的空间特征图与LSTM层融合并集成。该LSTM层提取连续帧之间的时间关系。通过预处理,该模型具有良好的检测效果。
使用CNN方法识别表情的准确率要明显高于传统方法,可以解决不同姿态、不同光照以及不同背景的问题,具有良好的鲁棒性。但是CNN也有缺点,不仅需要占用大量的计算机内存空间,而且需要付出大量的计算开销,而且在使用CNN提取特征时,在不同的数据集上效果差别较大[11]。
2014年,牛津大学提出了简洁、实用的VGG卷积神经网络模型。VGG在AlexNet基础上做了改进,整个网络都使用了同样大小的3×3卷积核尺寸和2×2最大池化尺寸,网络结果简洁。在ILSVRC比赛中,VGG网络取得了良好的成果,TOP-5的准确率达到了92.3%[25]。
AlexNet中每层卷积层中只包含一个卷积,卷积核的大小是7×7。在VGGNet中,每层卷积层中包含2~4个卷积操作,卷积核的大小是3×3,卷积步长是1,池化核是2×2,步长为2。VGGNet最明显的改进就是降低了卷积核的尺寸,增加了卷积的层数。
文献[32]提出了一种基于cGAN和表情元素滤除的残余表情识别算法(DeRL),通过cGAN滤除人脸的中性成分,并使用MLP处理残存的表情元素,实现了表情的高精度识别。通过7种表情库的实验,验证了所提算法的有效性。但若优化残存表情识别网络,则会进一步提高识别准确率。
对几种深度学习模型在CK+数据库上的识别准确率进行了比较,结果如表3所示。

表3 深度学习模型在CK+数据库上的识别准确率
4 结 语
目前表情识别技术已经被广泛研究,但是我们所定义的表情只涵盖了特定种类的一小部分,主要是面部表情,实际上人类还有很多其他的表情。现有的表情识别技术还不能很好地解决光照变化、遮挡、非正面头部姿势等问题,虽然可以采用多摄像头技术、色彩补偿技术予以解决,但效果并不理想。表情识别的计算量有待改进,现在流行的CNN表情识别方法虽然识别精确度较高,但是计算开销却非常大。考虑到表情识别是一个数据驱动的任务,并且训练一个足够深的网络需要大量的训练数据,深度表情识别系统面临的主要问题是在质量和数量方面都缺乏训练数据。
随着机器学习的迅速发展,基于深度学习的表情识别技术更加完善,可以使用深度学习技术解决光照变化、遮挡、非正面头部姿势、身份偏差和低强度表情识别。不同的数据库之间的偏差和表情类别的不平衡分布是深度表情识别领域中要解决的另外两个问题。对于数据库之间的偏差问题,可以用深度域适应和知识蒸馏来解决。对于表情类别不平衡问题:一种解决方案是利用数据增强和合成来平衡预处理阶段中的类分布;另一种选择是在训练期间给深度网络增加代价敏感的损失层。
加强多信息技术的融合,面部表情不是唯一的情感表现方式,综合语音语调、脉搏、体温等多方面信息来更准确地推测人的内心情感,将是表情识别技术需要考虑的问题。
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
学生天地(2020年31期)2020-06-01
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2019年14期)2019-08-20
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
