
基于并行关联规则的话题演化跟踪方法
2021-12-23 04:35王奕文张如玉张琼声田红磊
计算机工程与设计 2021年12期
王奕文,张如玉,刘 昕,张琼声,田红磊,曹 帅
(中国石油大学(华东)计算机与通信工程学院,山东 青岛 266580)
0 引 言
近年来,借助时序信息实时跟踪话题的动态演化趋势的研究方法主要包括以下两种[1-3]。第一种方法把文本的时间信息当作其话题属性参与到特征计算的过程中,建立动态演变的话题模型。例如:徐会杰等引入回复加速度实现对突发性热点话题快速发现与跟踪[4];赵旭剑等建立了增量式计算模型,该模型考虑了话题特征,能很好地挖掘出新闻话题演化各个阶段的信息[5]。第二种方法将时间信息与概率话题模型结合,通过计算时间信息与话题、文档、词项的概率分布,实现对潜在话题的生成与演变过程的追踪[6-8]。例如:Kalyanam等提出一种基于社交情景信息的话题演化模型[9];陈兴蜀等提出一种基于OLDA的热点话题演化跟踪模型[10];王奕文等对关联规则算法进行了改进,并将其应用于热点事件时序分析中[11,12]。
目前,在话题的动态演变跟踪领域,各种话题模型均能够很好地考虑到话题结构与演化的特征,但是大部分研究采用相似度来衡量不同话题内容的相关程度,很少考虑各阶段话题关键词的关联关系在话题演变过程中的影响。
为了解决上述问题,本文引入时间窗口和关联规则[13,14],提出一种基于并行关联规则的话题演化跟踪方法。该算法有两个优点,一是提高了计算效率,缩短了关联规则算法寻找频繁项集所需的时间,能够更快地发现数据之间隐藏关系;二是结合时间信息与关联规则能够发现关键词在话题演化过程中随时间推移的潜在关联关系,从而深度分析话题演化的具体细节。
1 基本概念
本文提出的基于并行关联规则的话题演化跟踪方法涉及到以下相关概念。
定义1支持度(support)。一个关键词集在数据集中出现的频率。支持度越高代表着该关键词集出现的频率越高、热度越大,说明规则越有用。支持度的计算公式为
(1)
关联规则是形如a⟹b的蕴含式。s(a⟹b)为{a,b}这个关键词集的支持度;P(a∪b)为数据集中事件a,b同时发生的概率(0≤P(a∪b)≤1);n(a∪b)为数据集中事件a,b同时发生的次数;n(dataset)为数据集中记录的总条数。
定义2置信度(confidence)。在事件a发生的集合中,事件b发生的概率。置信度衡量了关键词集中各关键词的关联关系强弱,置信度的值越大说明其对应的关联规则越可信。置信度的计算公式为
(2)
c(a⟹b)为关键词集的置信度;P(b|a)为在数据集中关键词集{a}发生的情况下关键词集{a,b}也同时发生的条件概率(0≤P(b|a)≤1)。
定义3k_项频繁关键词集。包括k个频繁关键词的集合,其中每个频繁关键词的支持度均大于等于支持度阈值。lk[i]={wx[i]}表示第i个k_项频繁关键词集,其中的第x个关键词表示为wx[i],(x=1,2,…,k)。则Lk={lk[i]}为由全部lk[i]组成的集合,(i=1,2,…,t),t为Lk中包含的k_项频繁关键词集的数目。
定义4关联规则集。关联规则集由置信度数值不小于设定阈值的关联规则构成。如果蕴含式a[y]⟹b[y]代表第y个关联规则,那么关联规则集则表示为Rules={a[y]⟹b[y]},(y=1,2,…,r),r为该关联规则集中包含的关联规则数目。
2 并行关联规则的基本流程
为了提高计算效率,本文将频繁关键词集的获取任务分为N个获取频繁关键词子集的子任务。首先对时间窗口的大小进行设置,并将数据集中的文本数据按照时序信息划分到不同窗口中来;然后获取各时间窗口对应的一项频繁项集L1;最后使用并行关联规则算法获取各个时间窗口对应的关联规则集,具体流程如图1所示。在已经获取的L1基础上,进行任务分配并实现Lk-1到Lk的迭代,任务合并形成全局Lk,在此基础上获得关联规则集;最后通过对所有时间窗口的关联规则集进行筛选和组合形成不同时间话题关键词。

图1 单个时间窗口的并行关联规则算法流程
2.1 1_项频繁关键词集获取
k_项频繁关键词集是在已知1_项频繁关键词集L1的基础上计算得出的,1_项频繁关键词集L1的获取分为3个步骤:
(1)因为各社交网站的话题信息均使用设定的TOP关键词进行收集,因此我们把各TOP关键词作为1_项频繁关键词集L1的候选关键词。
(2)从各社交网络页面上收集的数据根据时序信息划分到不同时间窗口中,形成不同的数据集。在各时间窗口对应的数据集中,统计各TOP关键词出现的次数,记为n(top[i])。由支持度的计算公式知,TOP关键词的支持度s_top[i]为
(3)
(3)设置支持度阈值s_min。若s_min≤s_top[i],则将s_top[i]对应的TOP关键词保留,记为l1[j];反之舍弃。由此得到L1={l1[j]},j≤i。
2.2 k_项频繁关键词集获取
k_项频繁关键词集Lk由L1与Lk-1进行合并操作得到。Lk的获得分为5个步骤:
(1)对Lk-1进行数据分割成N个互不交叉的子集,每个k-1_项频繁关键词子集分配给一个子任务。
(2)将各子任务的Lk-1与L1进行合并操作,得到k_项关键词集。该k_项关键词集为Lk的候选关键词集之一,第i个k_项关键词集记作k_keywords[i]。
(3)在时间窗口对应的文本数据集中,对各k_项关键词集出现的次数进行汇总,记作n(k_keywords[i])。由支持度计算公式知,k_项关键词集的支持度s_k_keywords[i]为
(4)
(4)当s_min≤s_k_keywords[i]时,则将s_k_keywords[i]对应的k_项关键词合并入Lk,并记为lk[j]。则Lk={lk[j]},j≤i。
(5)将各个子任务得到的Lk进行合并与删减操作,得到全局Lk。
2.3 形成关联规则集
在上一步得到的全局Lk基础上通过计算得到关联规则集,关联规则集的获得分为4个步骤:
(1)获取每个Lk中k_项频繁关键词集的关联规则,每个k_项频繁关键词集能产生的关联规则数目均不少于1。定义由第i个k_项频繁关键词集lk[i]中的s个关键词组成的关键词集为lk[i[s]](1≤s≤k),由lk[i]中去掉s个关键词后的k-s个关键词组成的关键词集为lk[i[k-s]]。
(2)计算关联规则的置信度。若将lk[i]的支持度表示为公式s_lk[i],则lk[i[s]]的支持度可表示为s_lk[i[s]]。由式(2)可知,关联规则lk[i[s]]⟹lk[i[k-s]]的置信度为
(5)
(3)筛选关联规则。c_min为设定的置信度阈值,如果c_min≤c(lk[i[s]]⟹lk[i[k-s]]),则关联规则lk[i[s]]⟹lk[i[k-s]]被保留,反之,对应的关联规则lk[i[s]]⟹lk[i[k-s]]被舍弃。
(4)将步骤(3)筛选出来的关联规则进行合并和约简操作,得到关联规则集。
3 话题演化跟踪方法
算法1:基于并行关联规则的话题演化跟踪算法
输入:从各个社交网站上爬取的所有与待分析事件有关的文本数据
输出:各时间段对应的话题关键词
(1)从各社交网络页面上获得的数据根据时序信息划分到不同时间窗口中,形成不同的数据集。
(2)在各时间窗口的文本数据集中,对各TOP关键词出现的次数进行汇总,支持度大于s_min的TOP关键词作为1_项频繁关键词集L1,此时k=1。
(3)令k=k+1,将集合Lk-1分为N个互不相交的k-1_项频繁关键词子集,并为每个子集设定一个独立子任务,将各子任务的Lk-1与所有的L1进行合并操作,各子任务独立生成满足支持度阈值s_min的Lk。
(4)将N个子任务获得的Lk结果合并后去重,得到全局Lk。
(5)迭代进行步骤(3)和步骤(4),当得到的k+1_项关键词集合为空时停止迭代,将频繁关键词集存在的最大项集数记作n。
(6)在全局Lk(2≤k≤n)基础上通过计算得到满足置信度阈值c_min的关联规则,对获得的所有关联规则合并并删减,得到关联规则集。
(7)通过以上6个步骤得到全部时间窗口对应的关联规则集,通过对关联规则集进行筛选与组合操作,得到各时间段对应的话题关键词。
4 实 验
4.1 实验数据
本文用到的实验数据均通过网络爬虫技术爬取获得,设定关键词“华为,犯罪,孟晚舟”,从新浪微博收集时间范围为2020年1月20日到2020年6月6日的舆情数据,共收集到36 245条相关的言论,日均230条左右。本文使用Ansj技术从收集到的微博言论中挖掘关键词,从同一条微博言论中挖掘到的关键词彼此互不相同,从不同的微博言论中挖掘到的关键词数量也互不相同。
4.2 参数设置及实验结果
4.2.1 支持度阈值设置
关联规则集在1_项频繁关键词集L1的基础上获得,L1中的关键词将会对整个话题演化跟踪的准确率产生影响,因此支持度阈值的设定尤为重要。恰当的支持度阈值可以使算法获取到各时间窗口对应的尽可能多的高价值关键词,对2020年1月20日的数据设置不同的支持度阈值,得到不同的L1见表1。

表1 不同支持度下的L1结果
支持度设置为14.6%~14.9%时,L1包括当前时间窗口全部有价值的关键词信息;支持度设置为14%时,L1不仅包括当前时间窗口全部有价值的关键词信息,还包括一些与事件主题无关的信息,如“弹劾、港股、英特尔、洛桑、冬奥”;支持度设置为15.0%时,筛选出的关键词数目较少,部分较为重要的关键词信息被漏掉,如“伊朗 欺诈 制裁 律师”,无法通过挖掘到的关键词信息获得事件起因。由分析可知当前时间窗口的支持度阈值设置为14.6%,使用以上方式获取所有时间窗口的支持度阈值。
4.2.2 置信度阈值设置
话题相关的关键词信息在已有关联规则集的基础上获得,关联规则集中的关联规则会对话题演化跟踪的结果造成巨大影响,而关联规则集中的关联规则又受到置信度阈值的直接影响。故此处将时间窗口设为1天,使用该时间 窗口对应的包含约230条微博言论或新闻报道的数据集,对支持度、置信度阈值与新闻报道的数目之间的关系进行分析,如图2所示。

图2 支持度阈值与置信度阈值关系趋势
由图2可知,数据点集中分布在s_min∈[12%,19%],c_min∈[85%,93%]区间范围内。即,当微博言论约230条时,支持度与置信度阈值有较大几率落在以上区间内。因支持度阈值较大时,关联规则算法会将一些重要的话题相关关键词信息过滤掉;支持度阈值较小时,则会获取到大量的冗余话题相关关键词,比如:当s_min=14.4%时,c_min=89.9%;当s_min=14.2%时,c_min=91.0%。所以,在微博言论的数目已经确定的前提下,设定的置信度阈值整体上会随着设定的支持度阈值的升高表现出下降的趋势。
4.3 热点跟踪实验及结果
本实验将时间窗口设为1天,图3为各时间窗口使用并行关联规则算法获取的部分关联规则集结果。
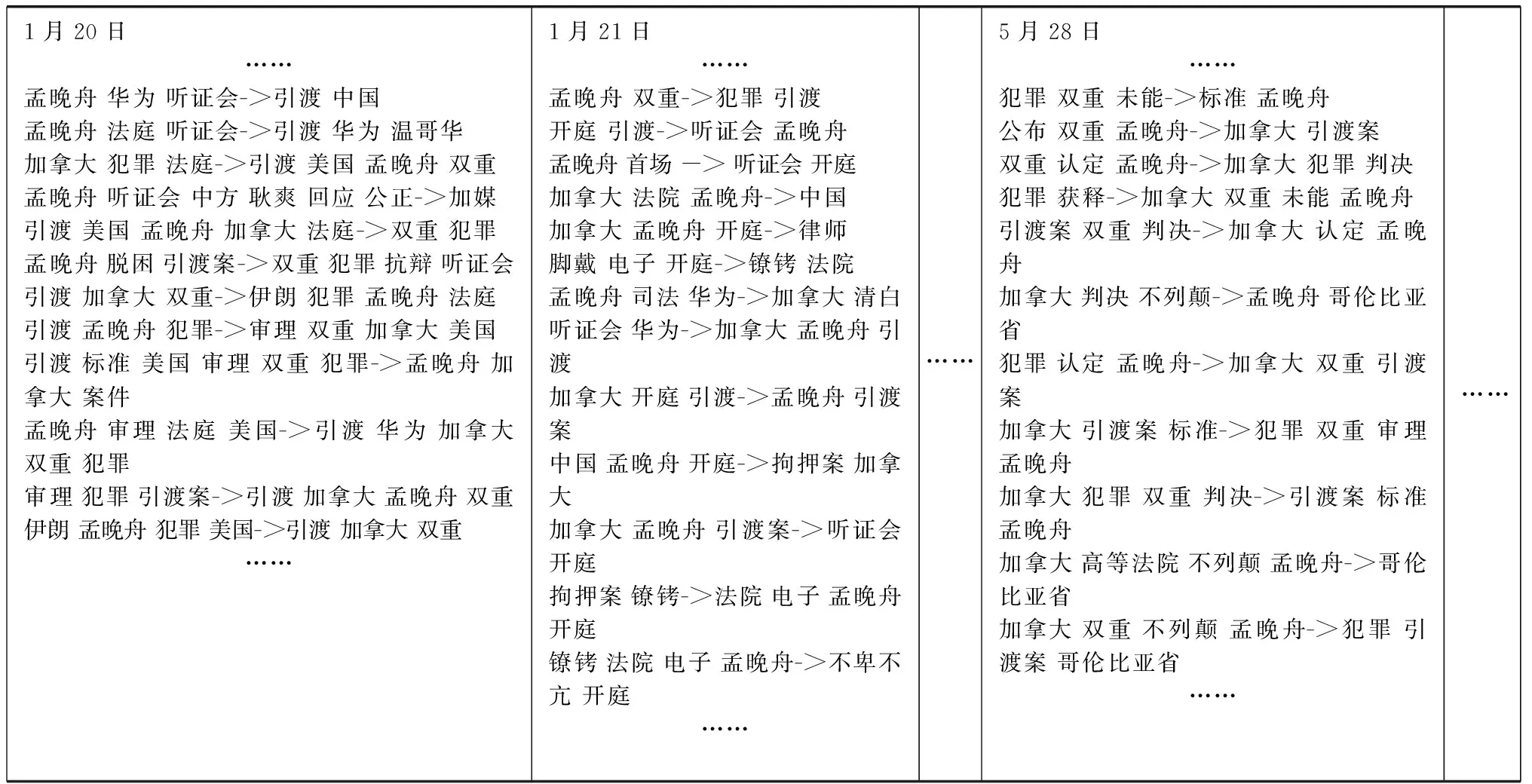
1月20日……孟晚舟 华为 听证会->引渡 中国孟晚舟 法庭 听证会->引渡 华为 温哥华加拿大 犯罪 法庭->引渡 美国 孟晚舟 双重孟晚舟 听证会 中方 耿爽 回应 公正->加媒引渡 美国 孟晚舟 加拿大 法庭->双重 犯罪孟晚舟 脱困 引渡案->双重 犯罪 抗辩 听证会引渡 加拿大 双重->伊朗 犯罪 孟晚舟 法庭引渡 孟晚舟 犯罪->审理 双重 加拿大 美国引渡 标准 美国 审理 双重 犯罪->孟晚舟 加拿大 案件孟晚舟 审理 法庭 美国->引渡 华为 加拿大 双重 犯罪审理 犯罪 引渡案->引渡 加拿大 孟晚舟 双重伊朗 孟晚舟 犯罪 美国->引渡 加拿大 双重……1月21日……孟晚舟 双重->犯罪 引渡开庭 引渡->听证会 孟晚舟孟晚舟 首场 -> 听证会 开庭加拿大 法院 孟晚舟->中国加拿大 孟晚舟 开庭->律师脚戴 电子 开庭->镣铐 法院孟晚舟 司法 华为->加拿大 清白听证会 华为->加拿大 孟晚舟 引渡加拿大 开庭 引渡->孟晚舟 引渡案中国 孟晚舟 开庭->拘押案 加拿大加拿大 孟晚舟 引渡案->听证会 开庭拘押案 镣铐->法院 电子 孟晚舟 开庭镣铐 法院 电子 孟晚舟->不卑不亢 开庭…………5月28日……犯罪 双重 未能->标准 孟晚舟公布 双重 孟晚舟->加拿大 引渡案双重 认定 孟晚舟->加拿大 犯罪 判决犯罪 获释->加拿大 双重 未能 孟晚舟引渡案 双重 判决->加拿大 认定 孟晚舟加拿大 判决 不列颠->孟晚舟 哥伦比亚省犯罪 认定 孟晚舟->加拿大 双重 引渡案加拿大 引渡案 标准->犯罪 双重 审理 孟晚舟加拿大 犯罪 双重 判决->引渡案 标准 孟晚舟加拿大 高等法院 不列颠 孟晚舟->哥伦比亚省加拿大 双重 不列颠 孟晚舟->犯罪 引渡案 哥伦比亚省…………
将图3中的所有关联规则集按照时间顺序组合后筛选,得到的热点话题的相关关键词结果见表2。其中,为了表格直观、清晰,实验中涉及的相同语义的关键词,如:中国和中方、加拿大和加方等,只选用一个关键词。

表2 各阶段热点话题的关键词结果
根据事件发展,“孟晚舟听证会”事件可分为7个阶段,每个阶段的话题相关关键词信息解析如下:
(1)1.20-1.28阶段:加拿大哥伦比亚省法院对孟晚舟案举行了引渡听证会,该听证会聚焦了华为首席财务官孟晚舟被起诉双重犯罪问题。孟晚舟脚戴电子镣铐,不卑不亢出席,其被指控引导汇丰银行违反美国对伊朗的制裁,且在加拿大犯有欺诈罪。中方发言控告美加两方滥用引渡条约,侵害了中国公民权益,希望能早日释放孟晚舟。庭审法官表示将延期判决。
(2)2.13-2.16阶段:美国对华为的打压升级,司法部公布了一份联邦起诉书,指控华为犯有敲诈勒索罪,并密谋窃取美国公司的商业机密,非法与朝鲜伊朗等国家合作。被告包括华为及其4家子公司和华为首席财务官孟晚舟。
(3)2.23-2.26阶段:近日华为开始了反击,向纽约法院递交了一封信,这封信揭露了美国串通汇丰银行诬陷华为的事实,以及其引渡孟晚舟的意图。
(4)3.30-4.3阶段:周一,加拿大卑诗省最高法院举行视频会议审理孟晚舟向美国引渡案。美国称华为涉嫌伊朗商业交易有关的银行欺诈指控,因受疫情影响,下次案件管理会议延后至4月27日,且短期内不再就是否符合“双重犯罪”原则公布裁决。
(5)4.28-5.2阶段:受疫情影响,在加拿大卑诗省最高法院以电话会议的方式举行了听证会,该听证会聚焦了华为首席财务官孟晚舟被起诉双重犯罪问题。
(6)5.22-5.27阶段:加拿大哥伦比亚省最高法院将于5月27日就孟晚舟引渡案做出关键裁决。如果判决不符合美加引渡条件,孟晚舟将摆脱持续了500多天的被软禁状态,重获自由。5月26日,加拿大总理表示加方司法独立,孟晚舟判决情况将不受政治干预。中国外交发言人赵立坚回应称,美加两国滥用引渡条约致使中国公民的合法权益受到侵害,希望能切实纠正错误,早日释放孟晚舟。
(7)5.28-6.6阶段:北京时间28日凌晨,加拿大法院公布孟晚舟引渡案的第一个判决结果,孟晚舟被加拿大法院认定符合“双重犯罪”标准,因此针对孟晚舟的引渡案将会继续审理。该事件引起中方的强烈不满,中方外交部发言人表示,加方在该事件中充当了美国帮凶,为了打压华为等高新企业,滥用引渡条约,损害了中国公民的合法权益。
4.4 对比实验及结果
实验选取文献[10]中的OLDA算法作对比。首先,按照时间信息使用OLDA算法对话题语料进行划分。然后,采用LDA模型通过对不同时间段对应的文本数据进行建模,最终实现话题演化分析,其中话题的先验知识是其历史分布。实验结果见表3。
对比表2与表3,使用本文方法获取的关键词个数为276个,比使用OLDA方法得到的关键词个数多了50个,且本文方法能获取到更详细准确的信息。如:1.20-1.28阶段“司法、公民、脚戴、镣铐、主权、汇丰银行、哥伦比亚省、延期”等关键词,2.13-2.16阶段“首席、民企、起诉书、民主、特朗普、任正非、5G、欧美、朝鲜”等关键词,2.23-2.26阶段“业务、手段、发声、违反、法院、正式、政府”等关键词,3.30-4.3阶段“伊朗、公布、开庭、欺诈、市场、双重、制裁、银行、会议、违反” 等关键词,4.28-5.2阶段“芯片、远程、损害、卑诗省、双重、违反、 会议、涉及、庭审” 等关键词,5.22-5.27阶段“高管、立场、银行、欺诈、伊朗、结束、500、法律、发言人、回应、合法权益、损害、律师、纠正错误” 等关键词,5.28-6.6阶段“交涉、自由、赵立坚、合法权益、打压、出卖、支持、发言人、大国、5G、采访、侵犯、原则、强烈不满” 等关键词。说明本文方法能够挖掘出事件具体细节相关的关键词,准确分析事态进展程度,有助于正确把握话题演化趋势。

表3 各时间片OLDA算法的结果
5 结束语
本文引入“时间窗口”的概念,首先对各个时间窗口采用并行关联规则算法获取关联规则集,进而发现话题与其后续事件的关联关系,从而跟踪话题发展演变的来龙去脉。实验结果表明,本文提出的算法能够更加完整有效地深入分析话题的动态演化细节。
本文只针对话题的内容进行跟踪,没有从话题强度分析话题的演化趋势,而且话题在发展过程中存在漂移的情况。因此,如何有效跟踪话题的漂移趋势,并结合内容和强度两方面跟踪话题的动态演化趋势将是今后研究的主要内容。
猜你喜欢
华声文萃(2022年6期)2022-07-05
文萃报·周五版(2022年16期)2022-04-28
核科学与工程(2021年4期)2022-01-12
环球人物(2021年3期)2021-02-22
中国外汇(2019年7期)2019-07-13
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
计算机应用(2018年5期)2018-07-25
海峡姐妹(2018年6期)2018-06-26
行政法论丛(2018年2期)2018-05-21
