
基于Siamese循环神经网络的泰文句子切分方法*
2021-12-23 06:18线岩团张志菊王红斌文永华
计算机工程与科学 2021年12期
线岩团,张志菊,王红斌 ,文永华
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.昆明理工大学云南省人工智能重点实验室,云南 昆明 650500)
1 引言
泰文很少使用标点符号,句子间没有明显的分隔符,为泰文词法分析、句法分析和机器翻译等自然语言处理任务带来了额外的困难。
泰文也有标点符号,Unicode甚至提供了特殊的零宽度空格符ZWSP(Zero-Width SPace)用于分隔泰语词。然而,与英语不同的是,在实际应用中泰文很少使用标点符号,词语间通常也不用分隔符,而是用空格符分隔句子、短语和特殊词语,如称谓和姓名之间、标号和内容之间、括号和内容之间等[1]。所以,泰文句子切分不能依靠标点符号,而必须充分考虑段落的上下文信息。
目前,针对泰文句子切分的研究工作比较少,相关工作主要有基于规则的方法和基于统计机器学习的方法。早期基于规则的方法,利用上下文中出现的动词和连接词定义切分规则完成句子切分,但效果并不理想[2]。基于统计机器学习的方法,通过从句子中抽取的特征构建分类器实现句子切分。Mittrapiyanuruk等人[3]以词性的三元组作为特征,利用viterbi算法实现泰语句子切分。词性三元组方法的主要缺点是只考虑了上下文中的词性特征,没考虑词组搭配特征。基于Winnow算法的方法,利用上下文窗口中左右2个词及其词性作为句子切分特征,获得了更好的切分效果[4]。Slayden等人[5]以上下文中的词和词性作为特征,构建最大熵分类器,通过扩展训练语料取得了更高的空格符精确率space-correct。Tangsirirat等人[6]结合泰语语法规则进行了泰语句子边界识别研究,但仅使用了简单的范畴文法特征。
以上这些方法大多以空格前后的词语、词性和句法等作为特征,构建二分类器实现句子切分。这类方法存在明显不足。首先,分类特征设计需要依赖于语言专家,而且面临特征选择与组合的问题。其次,词性标注和句法分析等预处理的错误可能影响句子切分的效果。最后,人工设计的特征难以表征空格前后的上下文语义信息。
近年来,神经网络方法在图像处理和自然语言处理方面都取得了很好的效果。在自然语言处理方面,神经网络方法在自动分词[7]、词性标注[8]、情感分析[9]和机器翻译[10]等多种自然语言处理任务中取得了很好的效果。神经网络方法将词语表示为低维稠密的向量,能有效表示词语和句子的隐含语义特征。
泰文句子切分依赖于上下文语义,本文通过神经网络学习泰语词语和句子的隐含语义用于泰文句子切分。泰文句子切分需要考虑段落中空格符前后词序列的特征和语义。为了使神经网络模型学习到的前后词序列具有可比较性,并减少模型参数的数量,本文提出了以Siamese神经网络结构为基础的泰文句子切分方法。该方法利用共享权重的循环神经网络分别学习空格前后词序列的向量表示,然后通过综合前后词序列的向量表示构建分类器来实现泰文断句。
Siamese网络最初是一种相似性度量方法,通过相同的2个子分支网络学习图像或文本的特征表示,接着利用学习到的特征向量距离度量计算输入样本的相似度。Siamese网络在签字认证识别[11]、人脸识别[12]、图像特征降维[13]和句对建模[14]中获得了很好的应用。
与以往的泰文句子切分方法相比,本文提出的泰文句子切分方法以词序列作为输入,无需依赖词性标注、句法分析等复杂自然语言处理工具。此外,通过词嵌入和循环神经网络学习词序的特征表示,避免了人工设计特征的问题,也有助于捕获句子中的隐含语义,从而提升句子切分性能。
2 泰文句子切分模型
本文提出的基于Siamese神经网络的泰文句子切分模型可以看作是一种Siamese神经网络的变种。该模型通过共享的神经网络分支模型,分别学习候选句子切分空格前后的词语序列编码向量表示,然后通过综合该空格前后的词语序列的编码向量构建分类器来实现句子切分。
2.1 模型结构
本文提出的句子切分模型包含5层,分别为:输入层、词嵌入层、循环网络层、隐含层和输出层,网络结构如图1所示。
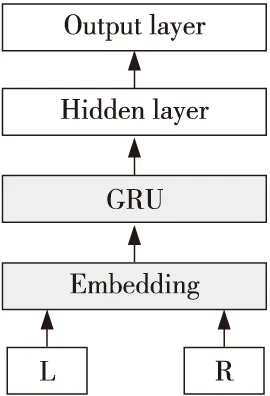
Figure 1 Architecture of Siamese model for Thai sentence segmentation图1 Siamese 循环神经网络泰文句子切分模型
输入层以空格前后的词序列作为输入,其中的每个词xi由一个Nw维的one-hot向量表示,Nw为词汇表的大小。
词嵌入层将one-hot向量表示的每个词表示为一个d维向量wi∈Rd,相应的词嵌入矩阵为Ew∈Rd×Nw。
wi=Ewxi
(1)
本文采用循环网络层对候选断句空格前后的词向量进行编码,学习句子切分特征。为了充分学习序列的语义特征,本文采用门控循环单元GRU(Gated Recurrent Unit)来实现循环网络层。同时,为了减少模型参数,并使前后词语序列的编码向量具有一致性,前后词序列共享相同的循环神经网络。
GRU采用门控机制跟踪序列的状态,而不使用单独的存储单元。在GRU中有重置门和更新门,这2个门共同控制信息如何更新序列的状态。GRU通过式(2)生成新的状态:
(2)
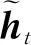
zt=σ(Wzxt+Uzht-1+bz)
(3)
(4)
其中,Wh和Uh是权重矩阵,bh是偏置向量,rt是重置门向量,它控制过去状态对候选状态的贡献。如果rt为零,则它将忘记过去的状态。重置门通过式(5)更新:
rt=σ(Wrxt+Urht-1+br)
(5)
其中,Wr和Ur是重置门的权重矩阵,br是偏置向量。
在获得空格前后的词序列的编码向量后,模型通过隐含层综合学习到的编码向量作为句子切分的特征。
h=relu(W11x1+W12x2+b1)
(6)
其中,W11和W12分别为编码向量x1和x2的权重矩阵,b1是相应的偏置。relu是修正线性单元ReLU(Rectified Linear Unit)激活函数。
本文采用Logistic输出层实现二分类,y是模型的输出结果:
y=sigmoid(W2h+b2)
(7)
其中,W2是该层的权重,b2是偏置。
2.2 模型训练和损失函数
由于句子切分是一个二分类问题,本文采用对数损失函数作为模型的损失函数。
L(θ)=∑-log(P(y|Xl,Xr))/M
(8)
其中,θ是模型的参数,包括词嵌入权重矩阵Ew,GRU循环网络层权重{Wz,Uzbz,Wh,Uh,bh,Wr,Ur,br},隐含层权重 {W11,W12,b1},以及输出层权重{W2,b2}。Xl和Xr是模型的输入,分别表示空格前后的词序列,M是训练样本的数量。
本文采用Adam(Adaptive moment estimation)算法[15]训练句子切分模型。Adam算法是一种自适应学习速率梯度下降优化算法,它根据损失函数对每个模型参数梯度的一阶矩估计和二阶矩估计来动态调整算法学习速率,与其他自适应学习率梯度下降算法相比,其收敛速度更快。
3 实验与结果分析
3.1 语料和评价方法
为了和已有的方法进行比较,本文采用Charoenporn 构建的ORCHID泰语语料库作为训练和测试数据[16],并采用十折交叉验证的平均值作为最终结果。
评价指标与对比方法一致,采用文献[17]提出的断句符召回率(sb-recall)、空格符精确率(space-correct)和断句符错分率(false-break)作为评价模型断句效果的指标,其计算方法如式(9)~式(11)所示:
sb-recall=CB/RB
(9)
space-correct=CS/RS
(10)
false-break=FB/RS
(11)
其中,CB是测试集中断句符正确预测的数量,FB是测试集中断句符错误预测的数量,CS是测试集中断句符和非断句符正确预测的数量,RB是测试集中断句符的总数量,RS是测试集中断句符和非断句符的总数量。
3.2 模型超参数
本文提出的泰语句子切分模型,称为SiameseGRU模型,包含了序列长度、词向量维度和GRU的隐状态维度等多个超参数,需要人工设定。
从语料中过滤掉出现频次小于2的词语后,词汇表规模为8 077个词。通过对语料的统计发现,ORCHID语料库中大部分的泰语句子长度为6~20个词,而且大部分的句子长度接近于15个词,所以本文选择15作为本文模型的词序列窗口大小。词向量维度、GRU的隐状态维度根据经验设为100。在本文后续实验中对比了不同维度对模型性能的影响。为了缓解训练过程中的过拟合问题,在GRU层和隐含层中引入了Dropout。本文模型中各层神经网络的参数如表1所示。

Table 1 Hyper parameters of our model表1 本文模型超参数
在实验中,本文提出的模型训练4轮,每批数据的 batch 大小为 128。
3.3 训练数据对模型的影响
由于ORCHID语料中用于句子切分的空格数量远少于其它用途空格的数量,其中正样本的数量为13 377,负样本数量为 63 604,负样本的数量大约是正样本数量的5倍。正负样本的数量极不平衡,会影响模型的效果。
为了缓解样本不平衡带来的问题,文献[4]通过收集更多文本扩充正样本数量,并将无段落信息的独立句子的句首和句尾拼接,人工构造断句上下文,并从中抽取句子切分特征。该方法的缺点是,构建的伪样本不是完整的句子,不利于模型学习隐含的切分特征。与该方法不同,本文从现有的ORCHID语料段落中,通过拼接不连续的句子构造伪样本。比如,假设段落中有3个句子〈s1,s2,s3〉,从中除了能获得〈s1,s2〉和〈s2,s3〉2个正样本外,本文将第2个句子移除获得伪样本〈s1,s3〉。通过这种方法获得了和原有正样本数量相当的伪样本。相比文献[5]中的方法,本文获得的伪样本句子完整,由于伪样本的句子来自同一段落语境一致,更接近真实语料。为了保证实验的准确性,伪样本只加入到训练样本中。
表2中的实验结果对比了本文模型在原始样本和加入伪样本后的性能指标,SiameseGRU+表示加入伪样本的模型。从表2的结果可以看出,加入伪样本后断句符的召回率有了很大的提升,幅度达13%,而空格符精确率和断句符错分率的效果也有一定的改进。实验结果表明,本文构造的伪样本有效缓解了训练样本类别不平衡带来的影响。

Table 2 Influence of pseudo samples表2 伪样本对本文模型性能的影响
3.4 模型参数选择
考虑到序列长度和词嵌入的维度对模型性能的影响,本文尝试了不同的模型参数。根据ORCHID语料库句子长度的统计,本文分别对比了不同序列长度和词嵌入维度对句子切分性能的影响。
从表3可以看出,在序列长度为5时,本文模型性能总体略低于其它序列长度的性能;而当序列长度足以涵盖大多数样本时,序列长度对句子切分性能影响不明显。

Table 3 Influence of sequence length on our model表3 不同序列长度对本文模型性能的影响
根据上述实验结果,本文将后续实验模型的序列长度固定为15,并在此基础上,对比不同词嵌入维度大小对模型性能影响。对比实验结果参见表4,从中可以发现,较高的词嵌入维度可以提升句子切分的性能,但同时也会增加模型的参数。
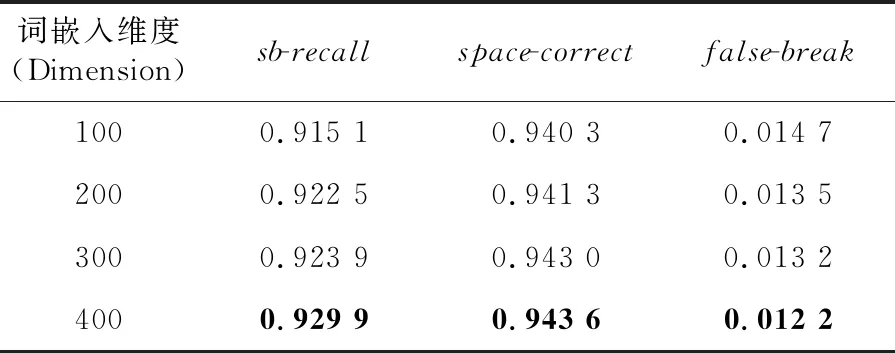
Table 4 Performances of our model with different sequence lengths on ORCHID表4 不同词嵌入维度对本文模型性能的影响
3.5 实验对比与分析
本文选择3种泰文句子切分方法进行对比,分别是以词及其词性为特征的Winnow切分方法[4]、基于最大熵分类器的方法[5]和利用范畴语法作为主要特征的方法[18]。各方法采用的训练数据统计和实验结果参见表5。

Table 5 Performances of different models on ORCHID表5 泰文句子切分方法对比
从表5的对比实验结果可以看出,本文提出的泰文句子切分方法SiameseGRU在断句符召回率(sb-recall)、空格符精确率(space-correct)和断句符错分率(false-break)上都优于其它3种方法,表明本文提出的方法能有效学习泰文的句子切分特征。
4 结束语
本文提出了一种基于双路循环神经网络的泰语句子切分方法。该方法不需要人工设计特征,也不依赖词性标注和句法信息。和已有方法相比,本文所提出的方法更加简单,句子切分效果也有了提升。由于实验语料限制,本文仅针对泰文进行了句子切分实验,但是该方法也可以应用于缅甸语、柬埔寨语等与泰语相似的语言,具有较好的通用性。另外,为了和已有方法对比,本文选择的ORCHID语料库规模较小,领域也比较单一。在下一步的研究工作中,将构建更广泛领域的句子切分语料库,以进一步验证本文方法的适应性;同时将该方法应用于缅甸语、柬埔寨语等更多语种的句子切分问题中。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
电子制作(2019年19期)2019-11-23
新世纪智能(语文备考)(2018年11期)2018-12-29
中华诗词(2017年3期)2017-11-27
高中生学习·高三版(2016年9期)2016-05-14
儿童故事画报(2016年2期)2016-04-18
重型机械(2016年1期)2016-03-01
新高考·高二数学(2015年11期)2015-12-23
大连工业大学学报(2015年4期)2015-12-11
