
基于强化学习的新型列控系统区间行车间隔控制方法
2021-12-23 04:38:24付文秀吕继东李丹勇
北京交通大学学报 2021年5期
付文秀,李 亚,吕继东,李丹勇,李 洋
(1.北京交通大学 电子信息工程学院,北京 100044; 2.中国铁路济南局集团有限公司,济南 250001)
随着城市地铁的快速发展,地铁客运量呈逐年增加的趋势,地铁运力不足问题逐渐凸显.由于地铁列车编组长度受车站站台长度的限制,因此在不改变列车编组的前提下通过提高线路上列车行车密度可以有效增加地铁运力,而提高列车行车密度的关键在于缩短列车之间的行车间隔.
目前国内外在列车行车间隔控制方面多采用相对位置追踪的控车方式,从闭塞制式上可划分为固定闭塞和移动闭塞两种,固定闭塞制式下轨道从物理上被划分为不同的闭塞分区并采用分级速度控制来保证行车安全,列车追踪过程中以前车所在闭塞分区入口为移动授权终点(End of Authority, EOA),中国列车运行控制系统(Chinese Train Control System) CTCS-0级、CTCS-1级、CTCS-2级和CTCS-3级以及欧洲列车运行控制系统(European Train Control System)ETCS-1级和ETCS-2级均采用这种闭塞控制方式[1].移动闭塞突破了传统轨道电路的限制,以前车车尾作为EOA采用速度-距离控制方式,大大缩短了列车行车间隔[2-3],基于通信的列车运行控制系统(Communication Based Train Control System,CBTC)采用这种闭塞控制方式.以上两种闭塞方式都是以列车运行线路上的固定点作为EOA,通常前行列车在正常行驶的情况下不可能由高速运动状态瞬间变为静止状态[4],因此采用闭塞制式来对列车进行间隔控制没有最大限度地发挥线路运行能力.近年来随着基于车-车通信的新型列车运行控制系统(Vehicle Based Train Control,VBTC)的研究和发展[5-6],采用相对速度追踪的控车方式成为主要的发展方向.新型VBTC系统中前后列车采用车-车通信的方式进行车间信息交互,两列车的追踪间隔由两列车的实际位置和运行速度共同决定,相较于传统的列车运行控制系统可实现列车间的动态追踪,能够进一步缩短列车行车间隔提高行车效率.
目前,国内外很多学者针对列车控制和间隔控制做了大量的研究和实验.文献[7]为了提高ETCS-2级列控系统的安全性提出了MA+(Movement Authority plus)的新型列车保护措施,采用车-车通信和车-道岔通信在原有的固定闭塞基础上增加了系统冗余,提高了系统的可用性和可靠性.文献[8]提出基于PID(Proportion Integration Differentiation)控制器和单神经元PID控制器的列车速度控制算法来保证列车安全平稳的运行.文献[9]针对城轨列车运动数学模型的非线性和不稳定问题提出了CMAC-PID(Cerebellar Model Articulation Controller-PID)列车控制算法,克服了常规PID算法易超调以及收敛不佳等缺陷.文献[10-11]针对列车控制系统复杂、多目标和非线性等问题,将模糊预测控制技术运用于列车自动驾驶系统(Automatic Train Operation,ATO)中提高了系统的鲁棒性和列车的舒适性及安全性.文献[12]提出一种基于车车通信的虚拟连挂小编组列车控制方案,在小编组范围内后车通过不断检测环境状态信息来制定控制策略来与前车保持一个动态的安全距离.在汽车车队间隔控制方面,文献[13]设计了带有跟踪-微分器的车辆跟驰纵向距离滑膜控制系统,通过获取汽车间相对速度来实现汽车间距离控制.但这些算法都有各自的局限性,如基于PID的控制算法需要建立复杂的数学模型,基于模糊控制的算法模糊规则及隶属函数的设计需要专家的经验.
近年来,人工智能技术的迅速发展为控制领域提供了新的途经.强化学习作为人工智能的核心算法之一,在解决复杂非线性控制、自动驾驶和机器人控制方面有着巨大优势.文献[14]基于强化学习提出了多目标车辆跟随决策算法,首先对跟车过程进行马尔科夫建模,然后通过对基于深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)进行改进得到了模型的最优决策策略.文献[15]将强化学习与神经网络算法相结合用来解决机器人防碰撞问题,通过机器人与环境的不断交互来训练神经网络,降低了机器人发生碰撞的概率.文献[16]将强化学习应用到多车协同碰撞中,车辆通过传感器周期性地采集环境信息,当监测到有发生碰撞的潜在危险时系统将会自动规划避障路线.于是本文提出将强化学习运用于新型列控系统,实现区间内列车之间的间隔控制.
强化学习中蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)是一种基于模拟搜索的算法[17],即智能体通过模拟与环境的交互得到样本数据来获得最优动作策略.它在解决部分可观测、大空间、复杂非线性问题有着良好的学习性能.2016年谷歌的AlphaGo以4-1打败了人类围棋高手,该程序的主引擎就是将机器学习与MCTS算法相结合来制定最优策略[18].文献[19]基于飞机避碰系统提出了一种有效的自适应压力测试,即一个采用MCTS算法寻找失败事件最可能路径的模拟器框架.本文作者采用MCTS算法生成列车速度调整序列,对该序列运用动态规划(Dynamic Programming,DP)算法求解控制策略以实现列车实时间隔控制.
1 新型列控系统动态间隔控制原理
1.1 基于车-车通信的新型列控系统概述
新型VBTC系统包含中心设备、车载设备和轨旁设备三大部分,如图1所示.

图1 新型列控系统总体框架Fig.1 General framework of the new column control system
与传统以地面设备为核心的CBTC系统相比,其在系统结构和通信方式上有很大的不同,新型VBTC系统更加注重以列车为核心,采用多模通信网关支持多种通信方式,能够保障车-地、车-车之间实时大容量信息交互.列车运行过程中可根据列车计划和进路状态自主选择进路,列车车载设备可根据前方列车位置、进路状态、区间方向等信息实时计算MA.其中车载列车自动防护系统(Automatic Train Protection,ATP)根据列车实际运行速度、制动性能和前方列车位置,动态计算与前车之间的安全距离.车载ATO设备在车载ATP的防护下实现列车自动驾驶,本文研究的列车间隔控制方法实质上是一种ATO控车算法.
1.2 新型列控系统的间隔控制方案
在列车间隔控制方面,传统CBTC系统中采用相对位置的追踪间隔控车方式,追踪过程中视前车为静止状态,以前车车尾或前车所在闭塞分区入口作为固定目标追踪点.然而,列车实际运行过程中不可能瞬间由高速运动状态变为静止状态[4],所以基于相对位置追踪的CBTC系统无法最大限度地提高线路的运行能力.而在VBTC系统中,列车之间通过实时大容量的信息交换可实现相对速度追踪,追踪过程中将前车车尾视为具有一定速度的动态追踪目标点,能够进一步缩短行车间隔.这种追踪方式下存在理想的最小追踪间隔如下
D=Lb2-Lb1+Lsafe+Ltrain
(1)
式中:Lb1、Lb2分别代表在紧急情况下前后车均采取紧急制动时的实际制动距离;Lsafe代表列车的安全防护距离;Ltrain代表前车的实际车长.
基于相对位置追踪的CBTC系统和基于相对速度追踪的VBTC系统在两车间隔趋近于最小理想间隔且前车采取紧急制动的情况下,追踪模型见图2.两种列车追踪方式对比可知,基于相对速度追踪的控车方式相较于基于相对位置追踪的控车方式采取紧急制动的时间更加靠后,最小追踪间隔更短,同时在相同线路状况条件下触发紧急制动的频率也将更低.
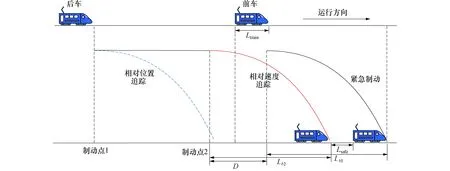
图2 基于相对位置和相对速度的列车追踪模型Fig.2 Train tracking model based on relative position and relative speed
2 MCTS算法概述
机器学习作为人工智能的核心问题之一,是以知识的自动获取和重新组织为研究目标的一门交叉性学科.机器学习分为有监督学习,无监督学习和强化学习3种.强化学习是将环境状态映射为动作来实现数值化收益最大化的方法.强化学习不同于有监督学习需要监督者提供的带标记数据集,也不同于无监督学习去寻找未标记数据的隐含结构,而是通过学习者不断地与环境交互和试错,利用评价性的反馈信号实现决策优化[17].
在强化学习中Agent作为一个学习者,它会根据系统当前环境的状态和自身的学习经验来制定动作策略如图3所示.动作策略作用于系统后将会引起系统状态的变化,动作对系统的影响由奖励函数进行评估.动作的评估结果将作为Agent的学习经验被记录下来,强化学习的最终目标是获得长期收益的最大化,Agent正是通过这种与环境的多次交互提升学习质量.
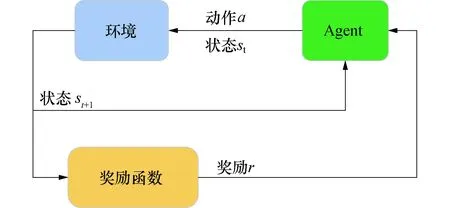
图3 强化学习基本原理Fig.3 Fundamentals of reinforcement learning
马尔科夫决策过程(Markov Decision Processes,MDP)是强化学习中的一种重要的数学模型[17],是指Agent周期地观察具有马尔科夫性的随机动态系统,并根据系统当前的状态做出相应的决策.马尔科夫决策过程的目标是找到当前状态下收益值最高的策略π*(s)
(2)
式中:Q代表状态s下系统执行动作a后的收益.
一个马尔科夫决策过程可由一个四元集合构成M={S,A,T,R},其中:S代表一组系统状态的集合,系统初始状态s0∈S;A代表一组动作的集合;T代表状态转移概率,T(s′|s,a)是指在状态s下系统执行动作a后转移到状态s′的概率;R代表奖励函数,R(s′|s,a)是指在状态s下系统执行动作a转移到状态s′后得到的奖励.
在强化学习中MCTS算法将树搜索的精度与随机抽样的通用性相结合,并基于MDP算法进行搜索树节点的扩展.它能兼顾广度与深度搜索,在解决搜索空间较大的问题方面有着巨大优势.该算法在人工智能方面有着广泛应用,特别是在游戏和策略规划问题方面.MCTS算法一次迭代更新包含选择、扩展、模拟和回溯4个过程[17]如下
▷输入:环境状态S0
▷输出:搜索树最优叶节点
1 function MCTS(S0)
2 create root node n0(S0,R0)
3 n←n0
4 while S of n not GoalState
5 node←SelectNode(n0)
6 n(Sj,Rj)←ExpandNode(node)
7 reward←Simulate(n(Sj,RJ))
8 BackUp(n,reward)
9 return n
10 function SelectNode(node)
11 if node not fully Expanded
12 node←UCT(node)
13 return?SelectNode(node)
14 else
15 return node
16 function ExpandNode(node)
17 create node child niwith state Si
18 Ri←0
19 return ni
20 function Simulate(node)
21 Ri←Reward(node)
22 return Ri
23 function BackUp(node,reward)
24 while node not null
25 node(Si,Ri+reward)
26 node←parent of node
算法执行步骤如下:
1)选择:根据Agent学习生成的搜索树,从根节点开始遍历寻找一个目前最值得探索的节点(该节点既没有达到终止状态也没有被完全展开).
2)扩展:将第一步中选择好的节点进行扩展,并对新节点进行初始化操作.
3)模拟:节点扩展完成后,系统实现了状态转移并得到了一条新的完整动作序列,通过对系统当前状态进行评估得到当前扩展节点的收益值.
4)回溯:将节点得到的收益值依次向上累加到其父节点上,不断地更新各个父节点的收益值,直到累加到搜索树的根节点回溯过程结束.
蒙特卡洛搜索树通过不断的迭代更新逐渐长大,并向最优解所在的子树倾斜,在找到最优解后搜索树将完成更新并返回最优动作序列.MCTS算法在节点选择上不同于传统的贪心策略,在节点选择上采用上限置信区间算法(Upper Confidence Bounds for Trees,UCT)[17],如下
(3)
式中:v′代表当前节点;v代表当前节点的父节点;N代表节点被访问的次数;c为常数,其值越大越偏向于广度搜索.加号右边代表探索度,左边代表平均收益,在节点访问次数较少时右边权重更大,随着节点访问次数增加左侧权重占据主导.该式可以兼顾节点探索和利用,避免搜索陷入局部最优解.
3 基于MCTS的列车间隔控制算法
3.1 列车间隔控制算法原理
针对VBTC系统下解决列车追踪间隔控制的问题(本文中“间隔”特指“列车距离间隔”),构建列车间隔控制系统模型,如图4所示.列车在区间运行过程中主动与前车建立无线通信,并实时向前车发送位置、速度等状态请求信息.前车在接收到后车发送的状态请求后将自身的状态信息发送给后车.后车根据采集到的列车运行状态信息来实现实时列车追踪间隔监测,在判定运行安全的情况下基于MCTS算法生成列车速度控制策略.
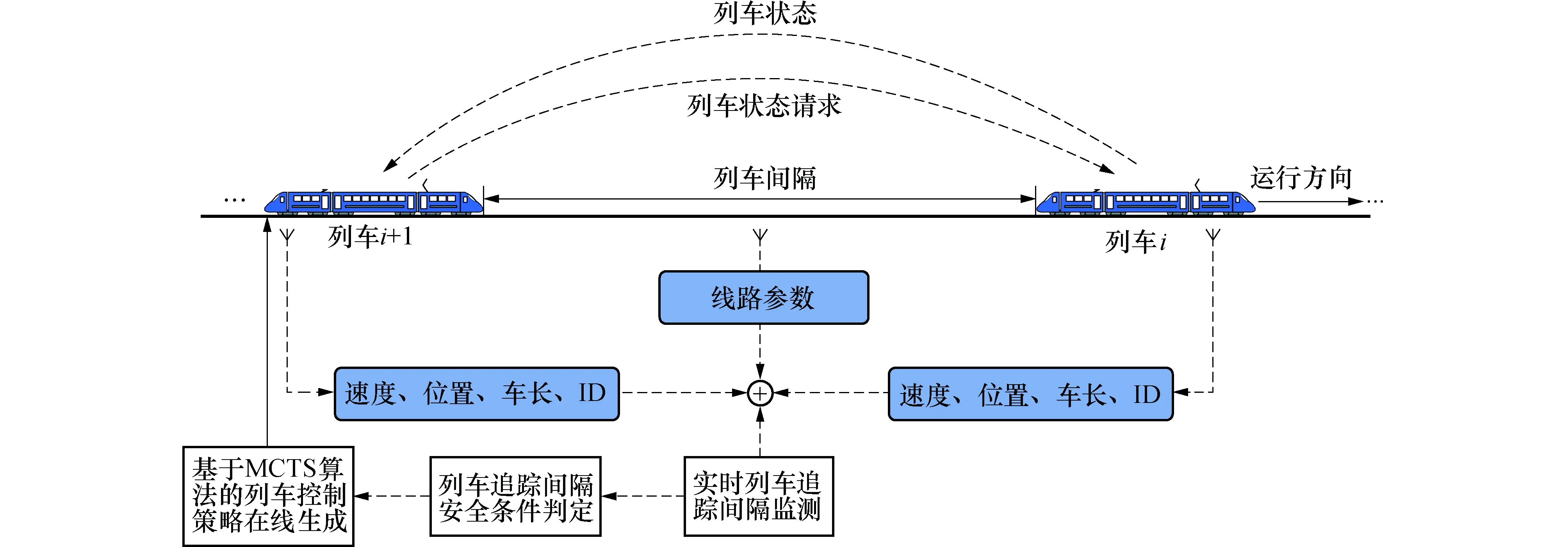
图4 列车间隔控制系统模型Fig.4 Train spacing control system model
列车运行过程中间隔控制系统根据两车之间的信息交互,计算处理得到环境状态信息,并将该状态信息传递给MCTS算法作为其初始状态输入,如图5所示.MCTS算法根据初始状态信息进行搜索树的搜索和扩展,运算结束后将会返回一条当前最优的预测速度调整序列L=[v0,v1,v2,…,vn].将离散的预测速度调整序列转化为曲线如图5中速度-时间曲线所示.采用DP对离散速度调整序列进行运算处理生成列车速度控制策略,从而提高速度控制的精确度保证列车平稳运行.
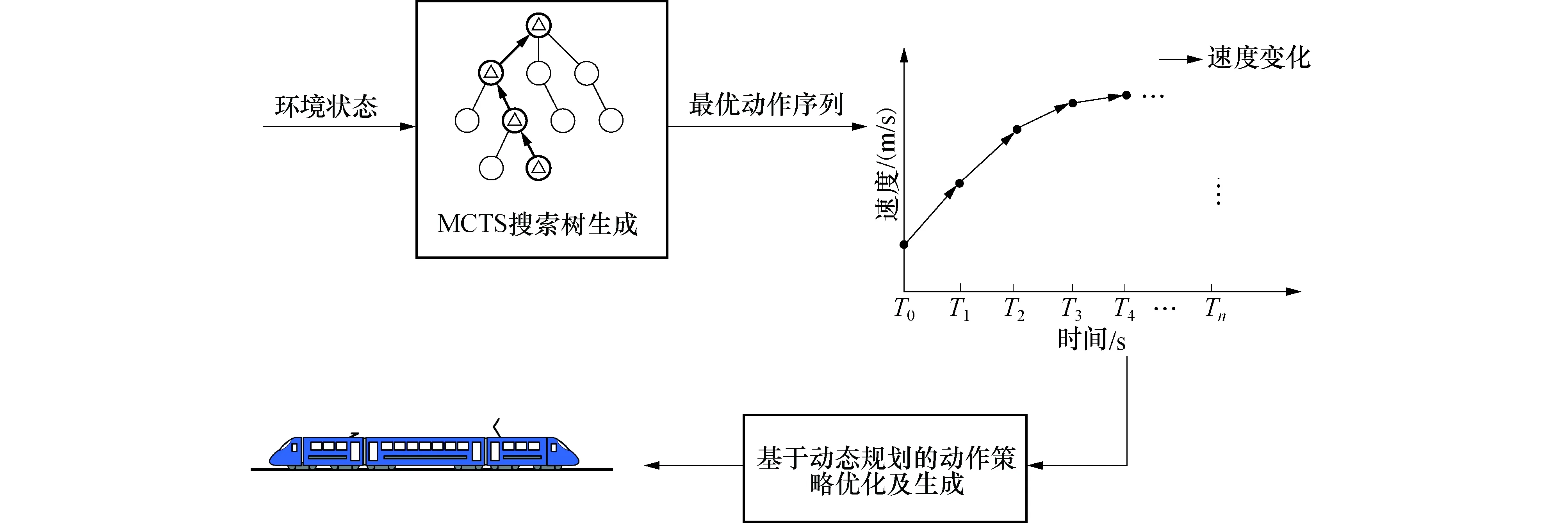
图5 基于MCTS算法的列车速度控制策略生成Fig.5 Train speed control strategy generation based on MCTS algorithm
3.2 基于MCTS的列车间隔控制算法实现
1)状态定义.
列车间隔控制系统的状态是指在某一时刻被追踪列车(前车)和追踪列车(后车)所处的空间状态及列车自身的运动参数,包括列车速度、位置等.由于列车运行在特定的轨道上按照既定的路径行驶,所以运用一维空间便可对列车建立动力学模型.本文重点研究两列车之间的间隔控制,系统状态信息用一个4维向量S=[d1,v1,d2,v2]表示,其中d1、v1代表前车当前时刻所处的位置和运行速度,d2、v2代表后车当前时刻所处的位置和运行速度,系统状态如图6中节点所示.

图6 系统状态转移Fig.6 System state transfer
2)动作定义.
动作被定义为系统在状态转移过程中所采取的控制策略,如图6中触发状态转移的因素.列车运行过程中通过控制列车速度实现列车间隔控制,本文为了方便描述将动作定义为Δv,即在周期T内以加速度a运行时速度的变化量如下
(4)
对于列车而言其加速度受天气,轨道坡度,自身重量等多方条件的制约,因此加速度存在最小下界和最大上界.A代表动作空间,动作空间越大运算结果越精确,但过大的动作空间将会导致算法复杂度的增加,所以动作空间维数n的选取应采取适度原则.
3)奖励定义.
奖励是对所采取动作引起系统环境状态变化的评估,对学习具有重要的指导意义.奖励分为正面奖励和负面奖励,奖励函数设计的优劣直接决定了强化学习效果的好坏,奖励函数设计如下
(5)
式中:常数r是对积极动作的一个奖励常数;惩罚因子α是用来限制被追踪列车与追踪列车之间因速度差过大所导致的间隔控制波动问题.常数d是对消极动作a因背离控制目标而给出的惩罚,由用户自己定义.列车间隔控制的理想状态是列车间隔逼近目标间隔且两列车的速度差趋于零,如下
(6)
式中:vf分别代表当前时刻后车的运行速度;df代表当前时刻后车所处的位置;dgoal为目标间隔距离.
4)控制策略生成及优化.
由于MCTS算法生成的是速度调整序列,如何根据该序列生成控制策略,文献[17]中提出了两种解决方法:1)采用蒙特卡洛树根子节点中收益值最大的节点所对应的动作策略.2)采用根子节点中访问次数最多的节点所对应的动作策略.
对文献[17]中提出的两种解决措施进行仿真实验对比如图7所示,其中两车初始距离间隔450 m,目标距离间隔300 m,前车运行速度变化如图7(a)中黑色曲线,后车速度调整策略采用方法1对应蓝色曲线,方法2对应绿色曲线.后车运行在15~45 s时,两方法制定的速度控制策略在27 m/s上下频繁波动不利于列车的平稳驾驶,所以亟需一种优化措施.
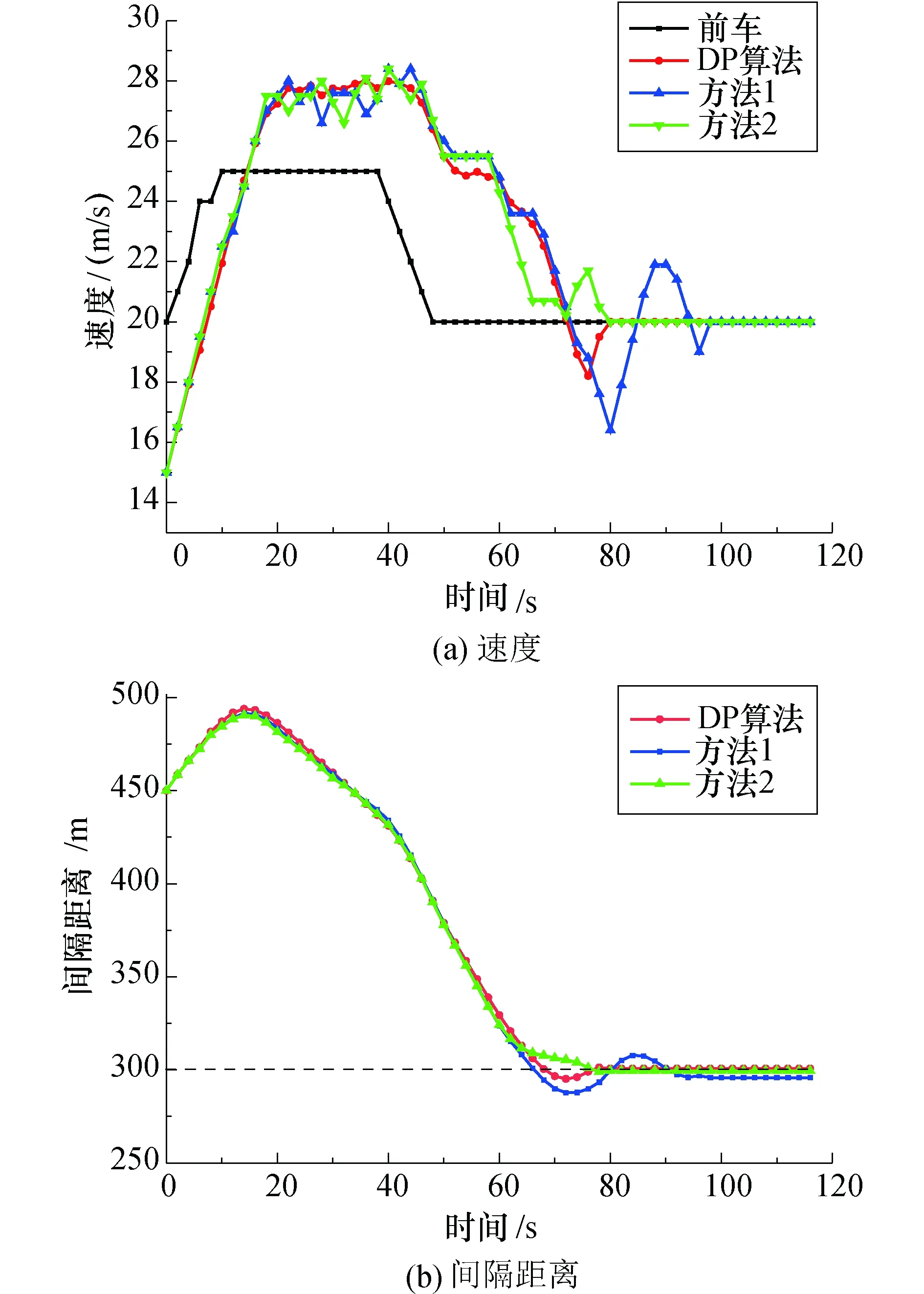
图7 不同速度调整策略波动对比Fig.7 Comparison of fluctuations of different speed adjustment strategies
在强化学习中,价值函数的计算过程中常采用DP算法来结构化地组织对最优策略的搜索.通过将贝尔曼方程转化成近似逼近理想的价值函数,递推更新公式如下
(7)
式中:v(s)代表在有限MDP中环境状态St=s时,当前节点最优价值函数的期望值;Rt+1代表t+1时刻的收益;参数γ为折扣率决定了未来收益的现值.在最优策略搜索过程中采用DP算法来更新价值函数,更多考虑了未来收益使得智能体更具有发展空间.
为了制定出更具远见性的速度调整策略采用DP算法进行优化,仿真结果如图7中红色曲线所示,相较于文献[17]提出的两种方法,采用DP算法生成的动作策略波动更小.基于DP算法设计出的贝尔曼方程如下
(8)
式中:at、at+1分别代表t时刻和t+1时刻的动作策略;通过该方程将t+1时刻的预测策略与t时刻的预测策略相结合,能够对t时刻动作策略进行优化.
将式(8)带入离散的速度调整序列得
(9)
式中:a*即为最终的速度控制策略.
构建基于MCTS的列车间隔控制算法伪代码如下
▷输入:环境状态S
▷输出:动作策略
1 function IntervalControl(S)
2 node←MCTS(S)
3 return DP(node)
4 function DP(node)
5 value←0
6 if parent of node is None
7 a←action of node
8 return (1-γ)×a
9 while parent of node not None
10 a←action of node
11 value←γ×value+(1-γ)×a
12 node←parent of node
13 return value
5)搜索树深度.
列车间隔控制属于持续性任务,即一个连续的控制过程且会不断发生.若MCTS算法以搜索达到控制目标作为运算结束的条件,则会出现算法时间复杂度过大的问题.由于列车控制策略的制定是基于速度调整序列,由式(9)可知对控制策略取决定性作用的是该序列的前段部分,而树深度的过度加深往往只是影响序列的后段部分,所以为了提高算法效率应对搜索树深度进行限制.
针对不同搜索树深度在相同运行场景下进行实验仿真如图8所示.当树深度为5时,算法拥有的知识有限,此时算法效率较高但控制策略并非最优.对比图8(a)中红色和绿色曲线速度控制策略基本相同,但图8(b)中树深度为10的算法效率较低.因此在列车间隔控制算法中,为了平衡MCTS算法的时间效率和速度控制策略的优劣,需对搜索树深度加以限制.
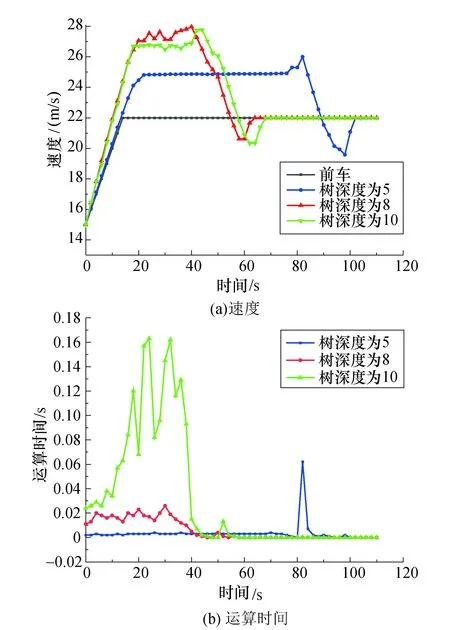
图8 搜索树深度对控制算法的影响Fig.8 Impact of search tree depth on control algorithm
4 仿真结果与对比分析
根据建立的列车追踪模型和基于MCTS的列车间隔控制算法,配置仿真参数为控制目标为|dgoal-d|≤7 m且|v1-v2|≤1 m/s.
动作空间维度A=7,搜索树深度限制为8,周期T为1 s, 动作值为-0.8 m/s≤Δv≤0.8 m/s,α为0.5,γ为0.3.其中奖励函数参数设置参考文献[19],并通过实验优化选取r=100,d=20 m.
实验选取3个不同的列车追踪场景进行仿真,各场景对应的列车状态及列车间隔距离如表1所示,其中列车按照运行的前后顺序进行升序编号.
列车追踪场景1:两列车追踪初始间隔距离小于目标间隔距离.仿真得到的列车速度和间隔曲线如图9所示,两列车初始速度差为5 m/s,调整初期列车2先与列车1保持一定的速度差行驶,调整后期列车2主动调整速度以减小与列车1之间的速度差,最终在30 s时完成间隔调整并协同继续向前运行.
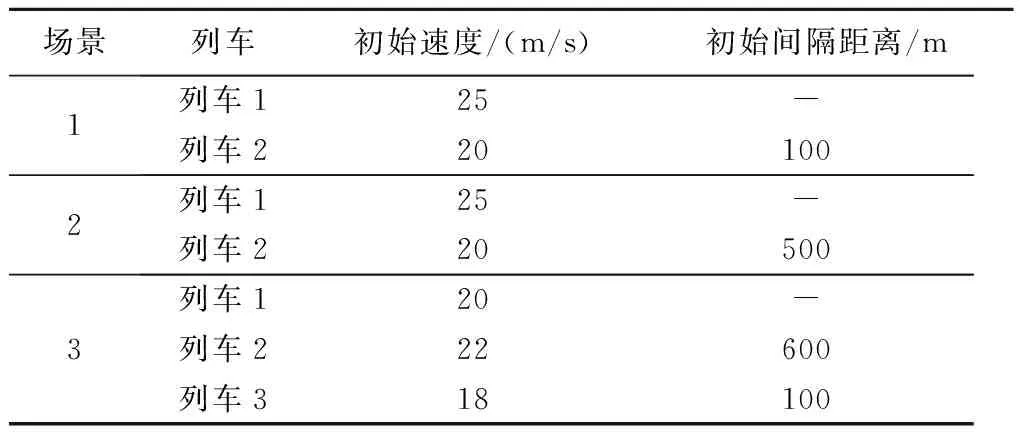
表1 列车不同追踪场景Tab.1 Different tracking scenarios for trains
列车追踪场景2:两列车追踪过程中初始间隔距离大于目标间隔距离.该运行场景下仿真得到的列车追踪速度和间隔曲线如图10所示.列车2初始速度小于列车1,且两车初始间隔距离较大,列车2先加速,然后与列车1保持一定的速度差并跟随列车1的速度变化轨迹运行,最终两车在88 s时完成列车间隔调节.
列车追踪场景3:三列车运行过程中协同列车间隔控制.该运行场景下仿真得到的列车追踪速度和间隔曲线如图11所示.列车2对列车1进行追踪,同时列车3又对列车2进行追踪,列车3在追踪到40 s时与列车2之间的间隔调整完成,随后开始与列车2协同向前运行.列车2在对列车1追踪到90 s时间隔调整完成.在三车追踪系统中追踪时间最终取决于间隔距离调整最慢的那对列车所对应的调整时间,本质上三车追踪模型可以划分为两个两车追踪模型,所以两车追踪模型不仅可以拓展到三车追踪模型上还可以拓展到多车追踪模型上.
同时,本文分别采用基于MCTS算法和模糊控制两种控制方法进行对比分析.其中模糊控制算法基于文献[11]进行改进,采用双输入单输出的模糊控制方式.输入包含列车速度差x和间隔距离y,由x,y共同决定列车所应采取的牵引控制等级f,输出u为列车在周期T内采用牵引等级f对应的列车速度变化量Δv.覆盖变量x和y的模糊子集数目为7,输出u的模糊子集数目为9,采用三角形隶属函数.其中牵引等级f对应的输出u满足式(4)中的约束,取值范围与表2中动作值相同.模糊规则表、输入论域范围及其他参数可参照文献[11].
为方便两种控制方法进行分析比较,控制指标定义如下:
超调量:列车间隔峰值与目标间隔之差所占目标间隔的百分比.
(10)
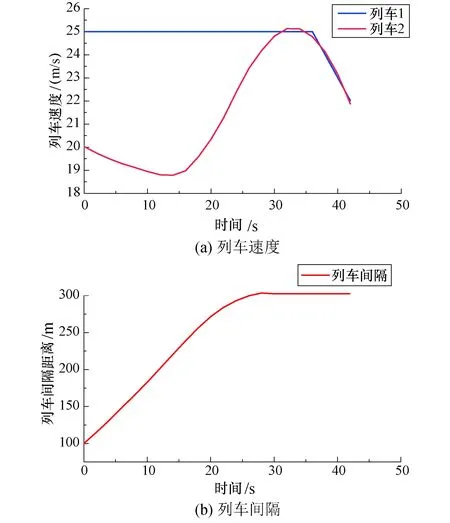
图9 场景1下的列车速度与 间隔随时间变化的曲线Fig.9 Variation curves of train speed and interval with time for Scenario 1
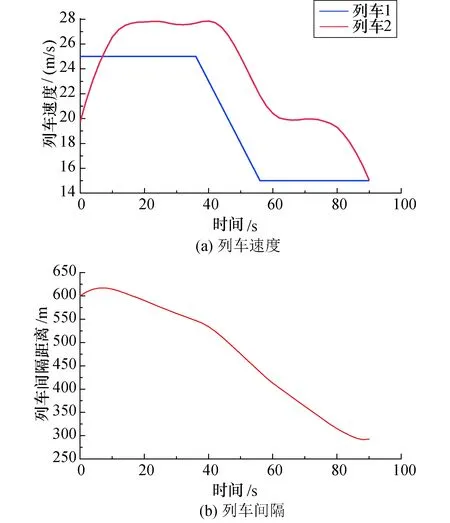
图10 场景2下的列车速度与 间隔随时间变化的曲线Fig.10 Variation curves of train speed and interval with time for Scenario 2
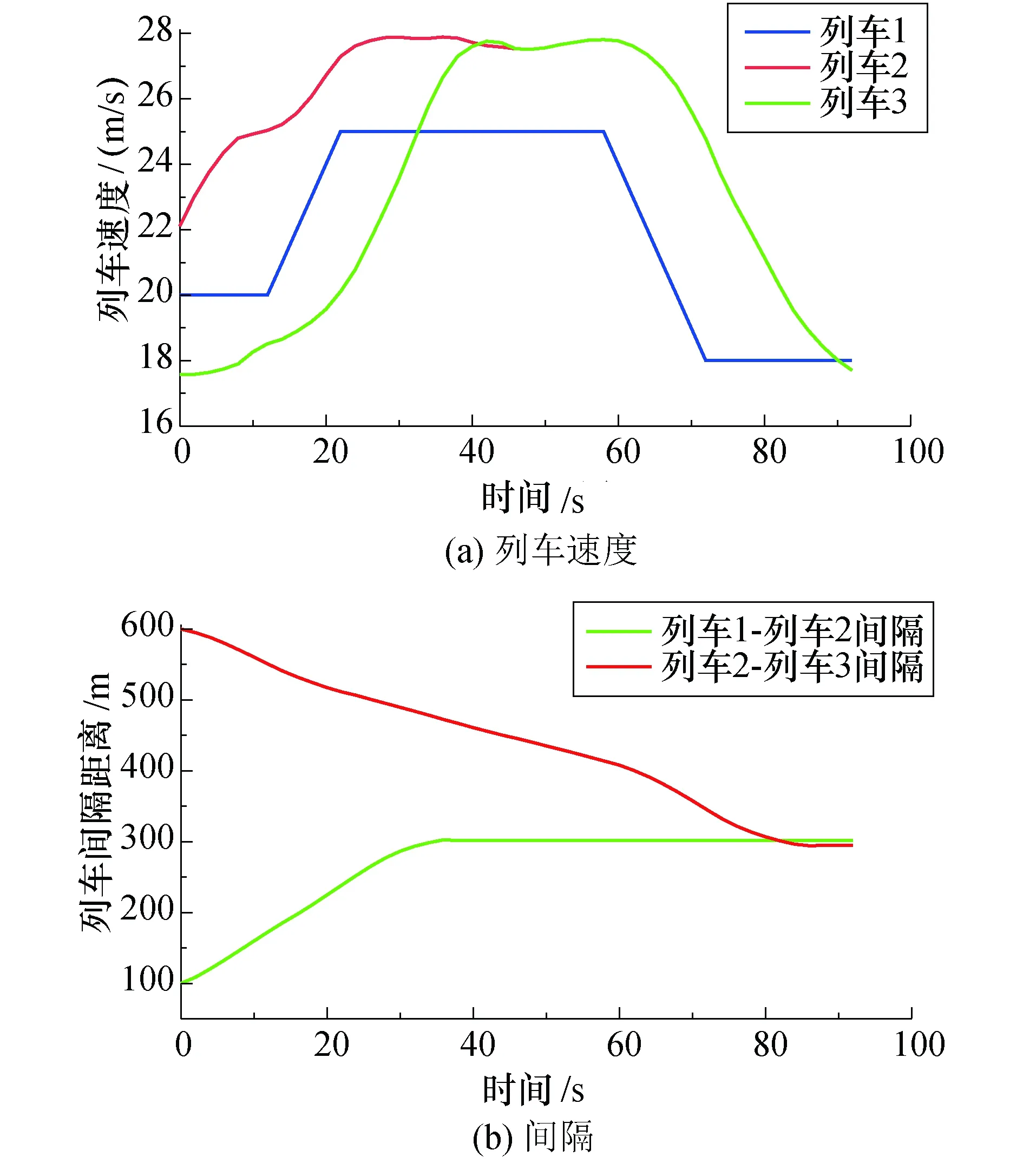
图11 场景3下的列车速度与间隔随时间变化的曲线Fig.11 Variation curves of train speed and interval with time for Scenario 3
调节时间:列车间隔开始调整至达到预期控制目标所耗费的时间ts.
速度调节误差:列车间隔调整达到预期目标时,列车速度与前车速度的差值.
ev=|vl-vf|
(11)
距离调节误差:列车间隔调整达到预期目标时,前后列车间隔与目标间隔之间的差值.
ed=|df-dl-dgoal|
(12)
在相同场景下采用两种不同控制方法对列车追踪模型进行仿真,列车追踪速度和间隔曲线如图12所示.

图12 基于MCTS与模糊控制的 列车间隔控制算法比较Fig.12 Comparison of train spacing control algorithms based on MCTS and fuzzy control
其中红色曲线代表前车运行速度,蓝色和绿色曲线代表采用不同算法的后车运行速度,后车以初始速度18 m/s初始间隔距离450 m对前车进行追踪,目标间隔距离为300 m.
对比两种控制算法曲线得到两种控制算法性能如表2所示,基于强化学习的MCTS控制算法在列车追踪开始阶段响应速度更快,在列车实际间隔距离快要接近目标间隔距离时前后列车相对速度差更小同时距离偏差也更小,而模糊控制算法在列车间隔调节中期波动控制更好,但在调节后期波动较大.由于基于MCTS算法的控制方法动作空间为7,而模糊控制输出u的子集个数为9,因此若基于MCTS算法选取的动作空间更大时该算法的优势将更加显著.
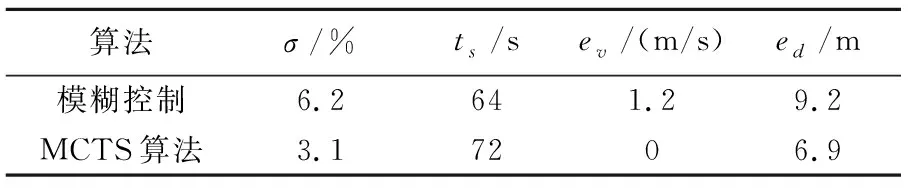
表2 基于MCTS算法和模糊控制算法的 列车间隔控制性能指标对比Tab.2 Performance index comparison of train spacing control based on MCTS algorithm and fuzzy control algorithm
5 结论
针对城市中地铁列车运力不足问题,介绍了新型列车运行控制系统的基本原理,提出了基于强化学习的新型列控系统区间行车间隔控制方法,得出的主要结论如下.
1)采用MCTS算法和动态规划算法相结合的方式实现追踪列车实时速度控制,MCTS算法用于生成实时速度调整序列,动态规划算法根据生成的速度调整序列确定最终的速度调整策略.本文提出的算法既不需复杂的数学模型也不需要监督者提供训练数据就可实现列车运行过程中速度的自适应调节,通过对不同场景的模拟结果显示该方法在列车间隔控制问题上具有较强的适用性.
2)对比模糊控制算法,基于强化学习的MCTS算法在间隔控制方面具有调节速度更快,波动更小等优点.
猜你喜欢
能源工程(2020年6期)2021-01-26 00:55:22
数学小灵通(1-2年级)(2020年11期)2020-12-28 00:41:14
山东冶金(2019年3期)2019-07-10 00:54:04
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:44
消费导刊(2018年10期)2018-08-20 02:57:02
制造技术与机床(2017年6期)2018-01-19 02:41:07
通信电源技术(2016年1期)2016-04-16 04:57:26
电源技术(2015年9期)2015-06-05 09:36:06
读写算·小学低年级(2014年4期)2014-07-24 22:42:55
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:54
