
复杂场景下基于YOLOv5的口罩佩戴实时检测算法研究
2021-12-22 13:18桂方俊杨彦琦吕晨阳
计算机测量与控制 2021年12期
于 硕,李 慧,桂方俊,杨彦琦,吕晨阳
(1.北京服装学院 基础教学部,北京 100029;2.中国矿业大学(北京) 机电与信息工程学院,北京 100083)
0 引言
自2019年遭受新型冠状病毒肺炎(COVID- 19)疫情[1]袭击以来,我国一直采取强有力的抗疫、防疫措施。目前疫情态势趋好,抗击新冠肺炎取得较大成功,但不能因此松懈,而应该更加科学地对抗疫情、更加重视公共卫生工作。现阶段有效降低人员间交叉感染风险、严防疫情反弹的有效措施之一就是在公共场所正确佩戴口罩,在对民众日常行为规范做出考验的同时,也对口罩佩戴的监督和管理检测技术提出了一定要求。目前的口罩佩戴检测装置受特定时刻待检人数激增、人员间相互遮挡等复杂环境的影响而出现误检,同时由于待检目标小可能导致漏检,因此复杂场景下提高口罩佩戴检测的精度与速度十分必要。
伴随卷积神经网络的兴起,基于深度学习的目标检测算法在人工智能、信息技术等诸多领域均有广泛应用[2-3],该算法主要分为两类,一类是两级式(two-stage):检测方式是区域提议结合检测,以R-CNN系列[4-6]为代表,这类算法精准度高但时效性较低;另一类是单级式(one-stage):检测方式是无区域提议框架,即提议和检测一体,以SSD[7]系列、YOLO[8-11]系列为代表,这类算法检测速度快但精准度较差。疫情前目标检测已应用在生产生活等诸多方面,但专业的口罩佩戴检测较少,因此疫情后的急需吸引了国内外众多学者参与研究。M.D.Pramita等[12]提出基于深度学习的图像分类模型,使用卷积神经网络从私有数据集中学习印度尼西亚人脸特征,实时检测人员是否戴口罩。B.Xue等[13]结合口罩佩戴检测算法、口罩标准佩戴检测算法和人脸识别算法提出基于改进的RETINAFACE算法,在实现口罩佩戴检测的基础上判断口罩是否正确佩戴。黄林泉等[14]在YOLOv3中融合SPPNet和PANet提高算法特征融合的质量,并且结合DeepSort目标跟踪技术以提高检测实时性。张路达等[15]提出在YOLOv3基础上引入多尺度融合进行口罩佩戴检测。
为达到更好的检测效果,本文在上述研究基础上利用YOLOv5网络模型进行复杂场景下口罩佩戴实时检测算法研究。经验证,本算法在口罩佩戴实时检测中兼顾了检测精度和速度,说明具有较好的实用性。
1 YOLOv5网络模型介绍
YOLOv5在结构上可分为4部分:输入端、主干部分Backbone、Neck和Prediction,其网络结构如图1所示。

图1 YOLOv5网络结构
YOLOv5的输入端将图像进行一定的数据处理,如缩放至统一尺寸然后送入网络中学习。Backbone包含Focus、CSP及SPP结构。CSP中的CSP1_X 、CSP2_X结构分别应用于Backbone、Neck中。SPP(Spatial Pyramid Pooling,空间金字塔池化)分别采用5、9、13的最大池化,再进行concat融合,提高感受野。这些结构有效避免了对图像区域剪裁、缩放操作导致的图像失真等问题,也解决了卷积神经网络对图像重复特征提取的问题[16]。Neck部分采用FPN、PAN结合的结构,得到一系列混合和组合图像特征的网络层,并将图像特征传递到预测层,加强了信息传播,具备准确保留空间信息的能力。输出端Bounding box损失函数为GIOU_Loss,NMS对目标最后的检测框进行非极大值抑制处理以获得最优目标框。
YOLOv5的4个模型YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x在结构上一致,区别在于模型的深度、宽度设置不同。如图2所示,在对比YOLOv5各版本性能后,本文选用模型大小较适宜、速度较快、精确度较高的YOLOv5m为基础模型,该模型的宽度、深度控制如图3所示。
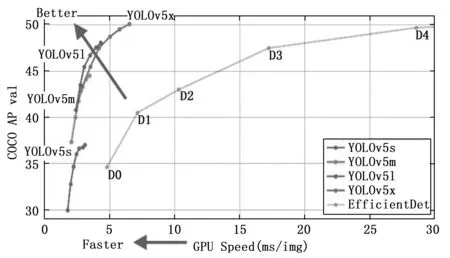
图2 YOLOv5性能对比

图3 YOLOv5m深度、宽度控制
模型深度由CSP结构控制,在YOLOv5m模型中第一个CSP1使用了2个残差组件,因此是CSP1_2;第一个CSP2使用了2组卷积,因此是CSP2_2,此时随着网络不断加深,其网络特征提取和特征融合的能力也在不断增强。同时模型在不同阶段的卷积核数量不同,直接影响特征图的厚度,进而影响模型宽度,即卷积核数量越多说明网络宽度越宽,网络提取特征的学习能力也越强,其中第一次卷积操作时将原始图像640*640*3接入Focus结构,通过切片变为320*320*12的特征图,再经过48个卷积核变为320*320*48的特征图,如图4所示,该操作为后续的特征提取保留了更完整的图片下采样信息。

图4 Focus结构图
2 检测算法优化
本文主要从数据处理、损失函数及检测框的选择方面对网络进行优化。
2.1 数据处理
在一般目标检测任务中,数据集的图片尺寸不尽相同,常用的处理方法是训练及测试时都将原始图片缩放至统一的标准尺寸,再送入网络中[17]。但由于复杂场景下待检测目标小等原因导致实际检测难度大,采用传统数据处理方法效果并不理想,因此本文算法选择在输入端采用自适应锚框计算、Mosaic数据增强、自适应图片缩放等数据处理方式。
由于网络训练前已经设定好了基础锚框[116,90,156,198,373,326]、[30,61,62,45,59,119]、[10,13,16,30,33,23],网络模型将基于此锚框训练得到的预测框与真实框进行比较,根据其差值反向更新、迭代调整网络模型参数[18]。
Mosaic数据增强就是把4张图片,通过随机缩放、随机裁减、随机排布的方式进行拼接,处理过程如图5所示。这种数据处理的方式不仅丰富了待检测图片的背景,也在一定程度使待检测目标变小进而扩充小目标,此时将处理好的图片送入网络中训练,相当于每次计算4张图片的数据,这样单GPU即可以达到比较好的效果。

图5 Mosaic数据增强
本算法数据处理时的操作如下:训练时,采用Mosaic数据增强结合自适应图片缩放,既对原始图片进行了拼接处理又给图片添加一定程度的灰边,然后将图像缩放至同一尺寸640*640*3送入网络进行训练,如图6(a)所示。测试时,仅使用自适应图片缩放,对原始图像自适应地添加最少的灰边以减少冗余信息,然后再传入检测网络以提高实际检测时的推理速度,如图6(b)所示。

图6 图片处理
2.2 改进损失函数
IoU[19]被称为交并比,是一种评价目标检测器性能的指标,其计算的是预测框与真实框间交集和并集的比值。GIoU[20]则是在IoU基础上引入惩罚项以更准确地反应检测框和真实框相交情况。二者计算公式如下:
(1)
(2)
其中:A表示检测框,B表示真实框,C代表包含检测框和真实框的最小外接矩形框,|C-(A∪B)|表示惩罚项。
如图7(a)、图7(b)所示可知,当A、B两框不相交时GIoU能衡量两框的远近程度;由图7(c)、图7(d)可知,GIoU亦能反映两框的相交方式,即相比于IoU来说,GIoU可以较好地区分检测框和真实框之间的位置关系。但当检测框和真实框之间出现包含这种特殊情况时,C与A∪B相等,那么GIoU中的惩罚项会变为0,即GIoU会退化成IoU,此时GIOU优势消失。

图7 位置关系
因此,本文选用CIoU_Loss[21]作为边界框损失函数使预测框更加贴合真实框。CIoU计算过程如下:
(3)
其中,如图8所示,b和bgt分别表示预测边框和真实边框的中心点,d=ρ(b,bgt)表示两框中心点间距离,c表示预测框与真实框的最小外接矩形的对角线距离。

图8 CIoU相关图示
式(3)中,α是做trade-off的参数,v衡量长宽比一致性[22],计算公式如式(4)和式(5)所示:
(4)
(5)
其中:w和wgt分别表示预测边框与真实边框的宽度,h和hgt分别表示预测边框与真实边框的高度。CIoU_Loss计算公式为:
CIoU_Loss=1-CIoU
(6)
2.3 DIoU-NMS代替NMS
在经典的NMS中,得分最高的检测框和其它检测框逐一算出对应的IoU值,并将该值超过NMS threshold的框全部过滤掉。可以看出在经典NMS算法中,IoU是唯一考量的因素。但是在实际应用场景中,当两个不同物体很近时,由于IoU值比较大,经过NMS处理后,只剩下单一检测框,这样容易导致漏检的情况发生。而DIoU-NMS不仅考虑到预测框与真实框重叠区域还考虑到中心点距离,即两框之间出现IoU较大、两框的中心距离也较大的情况时,会认为是两个物体的框并同时保留,从而有效提高检测精度。基于此,本文算法选用DIoU-NMS代替NMS。
3 实验及结果
3.1 数据集
实验数据集4 930张均来自线上收集,较全面的概括各类场景的图像,涵盖了单一人员佩戴、未佩戴口罩以及复杂场景下多人佩戴、未佩戴口罩等情况,按照8∶1∶1的比例划分其用于训练、验证及测试,数据集示例如图9所示。

图9 数据集示例
数据集采用PASCAL VOC格式,使用LabelImg对图片进行标注使用,包括face_mask、face、invalid 3种类别,其中face_mask表示待检测人员已正确佩戴口罩; face表示未佩戴口罩; invalid表示未规范佩戴口罩。并且通过对数据集进行分析,得到可视化结果如图10所示,可知数据集中已经标记部分小目标,可以一定程度上模拟复杂场景下待检目标小的情况。
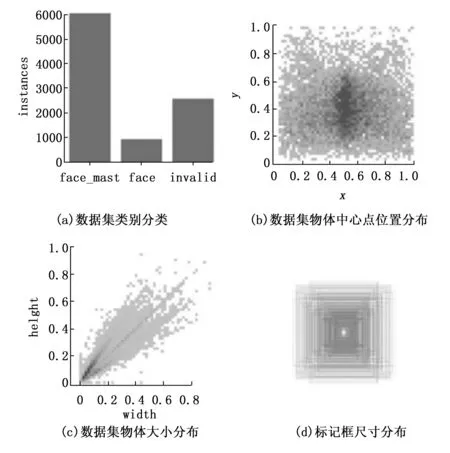
图10 数据集分析
3.2 实验环境与模型训练
本实验配置如表1所示。
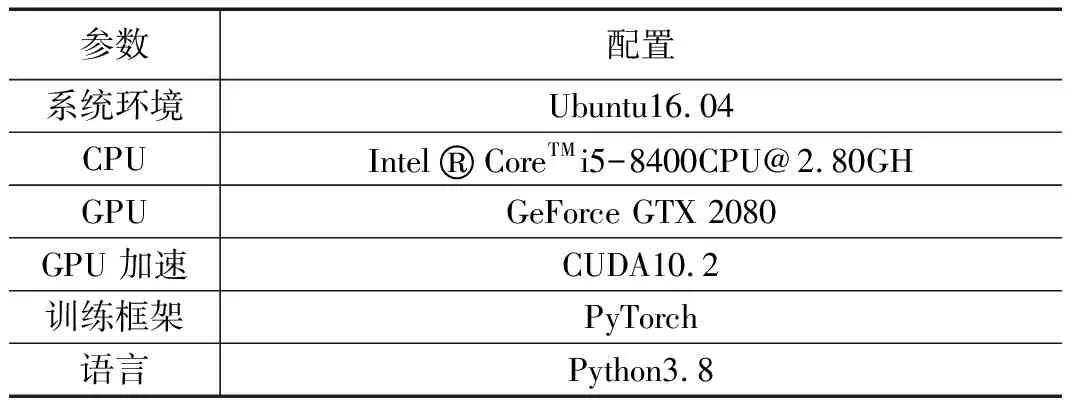
表1 实验环境配置
训练参数设置如下:输入图像尺寸为640*640,在训练过程中对学习率采用动态调整策略;初始学习率为0.01,学习率周期为0.2,学习率动量为0.937,权重衰减系数为0.000 5,若模型连续3个epoch的损失不再下降,学习率减少为原来的4/5。训练批次大小为16,最大迭代次数设置为600。
由公式(7)可知,YOLOv5的损失值由3个类别损失构成,分别是表征物体位置、物体类别及是否包含目标物体的损失。
Loss=box_loss+cls_loss+obj_loss
(7)
图11所示为训练600个Epoch的损失值收敛曲线,可知模型达到了较好的拟合效果。

图11 训练损失下降曲线
3.3 实验结果分析
采用如下性能指标[23]评估本文算法性能:准确率(P, precision)、召回率(R,recall)、平均精度均值(mAP, mean average precision)以及每秒检测图片帧数(FPS,frames per second)。
准确率是精确性的度量,表示被分为正的示例中实际为正例的比例。召回率是覆盖面的度量,计算有多个正例被分为正例。公式如下:
Precision=TP/(TP+FP)×100%
(8)
Recall=TP/(TP+FN)×100%
(9)
其中:TP代表预测为正例实际也为正例的数量,FP代表预测为正例但实际为负例的数量,FN代表预测为负例但实际为正例的数量。
mAP是用以衡量识别精度,由所有类别的AP值求均值得到。其中通过计算不同召回率下最高的精确率可绘制P-R曲线,该曲线围成的面积即为该类别的AP值。
训练后模型的Precision、Recall、mAP_0.5、mAP_0.5∶0.95最高分别能够达到0.998、0.992、0.996、0.958,具体情况如图12所示。在数据集随机划分的493张测试图片上进行测试,本文改进的YOLOv5算法检测结果的P-R 曲线如图13所示。

图12 模型性能评价指标
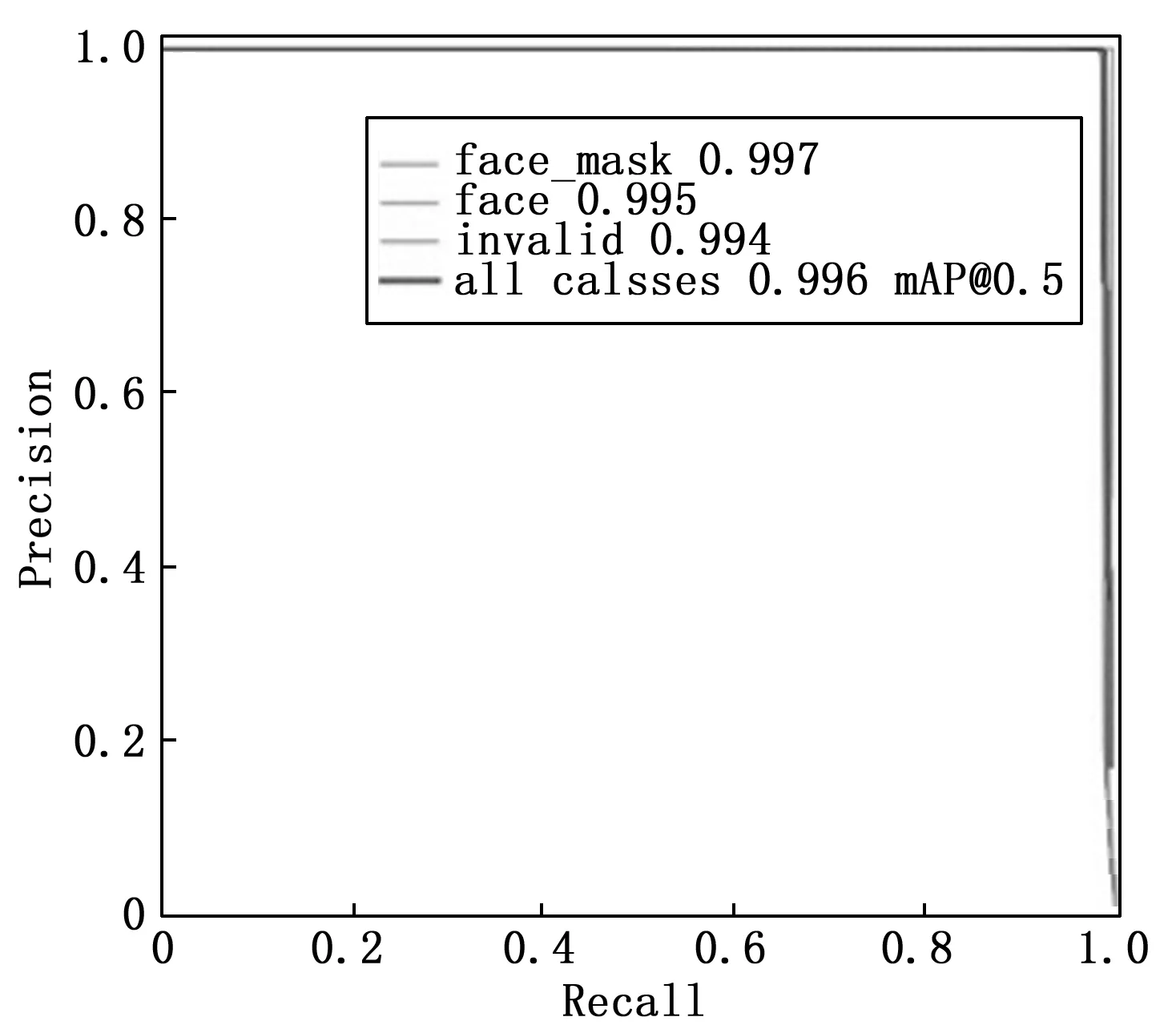
图13 改进算法的P-R曲线
FPS衡量的是每秒钟传输的图片帧数。由于人体感官的特殊结构,人眼所见画面之帧率高于16 FPS时,大脑就会认为是连贯的,这一现象也被称之为视觉暂留[24-25]。经验证,本文算法最高每秒检测图片的帧数最高可以达到30.0 FPS。
为进一步测试复杂背景下网络实时检测小目标的能力,将图片自适应放缩后又进行拼接,送入网络模型进行测试,仅需0.035 s得到结果如图14所示结果。

图14 复杂背景下检测结果
同时为了验证本文算法的有效性,将其与RetinaFace[26]、Attention- RetinaFace[27]、YOLOv3、YOLOv4、YOLOv5[18]进行对比,结果如表2所示。
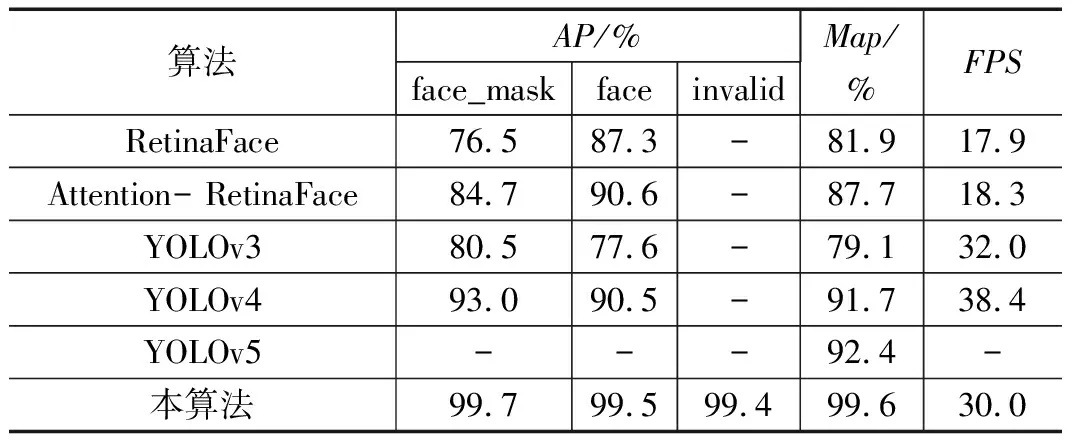
表2 算法性能对比
对于人脸目标检测而言,RetinaFace算法和Attention- RetinaFace算法均是专门用于人脸定位的单阶段检测算法,二者原理均是基于人脸对齐、像素级人脸分析和人脸密集关键点三维分析来实现多尺度人脸检测[27],因此它们的检测精度比较高。而YOLO系列算法中的YOLOv3、YOLOv4、YOLOv5虽不是专业的单阶段人脸检测算法,但将其应用于口罩佩戴检测上其检测精度方面已经可以与之比肩。本文算法作为基于 YOLOv5的改进算法,其AP值、mAP 值较前述算法均有显著提升,且FPS为30.0达到了实时检测目的。综上所述,本文的改进策略能够胜任复杂场景下的口罩佩戴实时检测。
4 结束语
综上所述,为了兼顾复杂场景下人员口罩佩戴检测精度和速度,本文提出了复杂场景下基于YOLOv5的实时口罩佩戴检测算法。经实验测试,本算法准确率、召回率等评价指标上均有较好表现,且能达到视频图像实时性要求,因此说明本文方法具有一定的优势,但需承认的是:在目标过多的视频样本中检测会出现帧率偏低的现象,且应对遮挡目标、小目标等特征信息不明显的情况时会存在一定程度的漏检,因此接下来将在这些方面做进一步研究和改进。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
汽车工程师(2021年12期)2022-01-18
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
意林(2020年9期)2020-06-01
海峡姐妹(2020年4期)2020-05-30
作文大王·笑话大王(2019年3期)2019-04-22
读者(2015年9期)2015-05-04
