
语义出版驱动的科学论文论证结语义建模研究
2021-12-21 13:58曲佳彬欧石燕
现代情报 2021年12期
曲佳彬 欧石燕









DOI.10.3969/j.issn.1008-0821.2021.12.005
[中图分类号]G254 [文献标识码]A [文章编号]1008-0821(2021)12-0048-12
科学论文是科研工作者研究成果的固化,是知识传播和科学交流的载体。随着科学研究的不断推进,科学论文发表数量与日俱增。海量的科学论文造成信息过载,科研人员需要花费大量的时间查找和阅读相当于原来几倍数量的文献。如何精确且快速查找所需文献并进行有效阅读成为每个科研人员所要面临的问题。在此背景下,对科学论文内容进行语义表示和组织,实现论文内容的模块化、结构化、语义化和关联化显示与发布变得尤为重要。
随着数字出版的不断发展,牛津大学的Shot-ton D于2009年首次提出了语义出版概念,其实质是利用语义网和关联数据技术,通过语义标记注释和丰富出版物的内容。语义出版作为一种新型的出版模式和知识表示模式,对科学论文结构和内容进行细粒度语义表示,以结构化和模块化的方式呈现科学论文的内容,能够有效提高科研人员的阅读效率。在语义出版发展过程中,从早期对论文外部特征(如题录信息、参考文献等)的语义描述,正逐渐深入到论文内容层面的语义表示,如实体、概念、科学结论、图表等。
现有研究多是从篇章结构角度对科学论文的内容结构进行解析和知识表示,多是在章节和段落层面进行,缺少对科学论文内容细粒度的知识表示和知识关联。科学论文是一种论证性文本,是对科学观点和科学结论的论证。从科学论证角度对科学论文的结构进行解析,对其中细粒度的论证元素和论证关系进行语义表示,能够更加精确地表示科学论文的内容。因此,本研究旨在从论证角度构建一个科学论文论证结构本体,对科学论文中的论证元素(如研究问题、研究方法、研究结论等)及其论证关系进行语义表示,实现对科学论文细粒度内容的语义出版,从而帮助科研人员快速理解科学论文内容并定位特定信息,促进知识传播和科学交流。
1相关研究
对科学论文内容进行语义描述的目的是将论文中的知识显性化、结构化和形式化表示。当前研究主要是从科学论文的篇章结构出发对其进行描述。篇章结构是指论文的功能结构,其规范定义了科学论文各部分的顺序和功能,譬如科学论文中某段文字的作用是介绍“研究背景”或阐述“研究方法”。依据描述粒度的不同,大致可以分为两种描述方式:第一种是粗粒度的论文篇章结构,主要对论文章节等文献组成部件、题录信息及参考文献的描述:第二种是细粒度的论文篇章结构,专门用于对论文中研究目标、假设、论据、方法、试验及结论等功能元素进行描述。
针对粗粒度的篇章结构,目前主要有IMRaD模型和ABCDE模型两个代表性模型。IMRaD模型是目前最具影响力的论文写作框架,将论文的正文内容划分为4个具有语义功能的模块,即介绍(In-troduction)、方法(Method)、结果(Result)和讨论(Discussion),被广泛应用于实证型或实验型论文。ABCDE模型由荷兰乌特列支大学计算机科学系的Waard A D等提出,主要用于计算机领域会议论文的标注。ABCDE模型将科学论文的结构划分为:标注信息(Annotations)、背景(Background)、贡献(Contribution)、讨论(Discussion)和实体(En-tities)共5个模块,其中,标注信息指科学论文的外部题录信息,如题名、作者、出版日期等,实体指科学论文中的人名、地名、研究方法名和模型名等。此外,在IMRaD模型基础上,一些论文内容本体被提出,主要有篇章元素本体(Discourse Ele-ments Ontology,简称DEO)、文档组件本体(Document Components Ontology,简称DoCO)、修辞块本体(Ontology of Rhetorical Blocks,简称ORB)。这些本体都是将论文中粗粒度的篇章、文本块或段落,按不同语义功能进行分类,并采用形式化语言来描述。
对于细粒度篇章结构的描述主要有AZ-J/AZ-Ⅱ模型、CISP模型、核心科学概念框架。1999年英国剑桥大学的Teufel S等以计算语言学领域的论文为研究对象,提出了AZ-Ⅰ模型。该模型将论文的篇章划分为7个类别,包括研究目标(Aim)、背景(Background)、相關研究(Other)、研究起点(Basis)、对比分析(Contrast)、作者研究(Own)和篇章结构描述(Textual)。随后,Teufel S等人又提出了改进版的AZ-Ⅱ模型,在其中增加了支持性研究(Support)、中立比较(Codi)、研究空白(Gap_Weak)和矛盾比较(Atisupp)等情感和论证性的描述。2007年,英国威尔士大学的Soldatova L等分析了生物学领域论文篇章结构,认为科学论文是一项包含核心信息的科学调查研究内容表示,构建了科学论文核心信息(The Core Information About Scientific Papers,简称CISP)本体,定义了科学调查研究中的8个核心概念,主要包括调查目标(Goal of Investigation)、调查动机(Motivation)、调查对象(Obiect of Investigation)、研究方法(Research Method)、实验(Experiment)、实验观察(Observa-tion)、调查结果(Result)和调查结论(Conclu-sion)。2012年,Liakata M等以CISP本体为基础进行了扩展,添加假设(Hypothesis)、模型(Mod-el)和背景(Background)3个概念,将该模型定义为核心科学概念(Core Scientific Concepts,简称Co-reSCs)模型。此外,一些国内学者开展了科学论文内容标注框架的研究。2017年,秦春秀等通过分析CNKI、万方、维普数据库中的科技论文的内容和结构,提出了一种基于知识元的科学论文标注框架,该框架包括了13类知识元(研究背景知识元、问题知识元、方法知识元等)及31个子类。王晓光等设计了科学论文功能单元标注框架,以句子级为标注对象将论文内容定义为28个类(背景、主题、缘起、已有研究、假设、方法、数据、结果等),并定义5个属性来描述类的属性,譬如知识类型、时态、来源、情感倾向和确定程度。
除了从篇章结构角度出发来描述科学论文的内容,也有学者从论证结构角度出发来描述论文的论证过程,构建本体或其他语义模型来描述论文中各篇章单元间的论证关系。博洛尼亚大学的Vitali F等于2011年提出了论证模型本体(The Argument Model Ontology,简称AMO),该本体以图尔敏模型为原型,采用OWL2DL语言对该模型中的论证元素(主张、保证、根据、限定词、支撑、例外)和相互问的论证关系进行了语义描述。此后,哈佛医学院的Clark T等提出微出版模型(Mirco-publication,简称MP),主要用于描述科学论文的论证结构,定义不同的论证元素,比如数据、方法等概念,来证明科学论断,并通过各种语义关系来关联论文中的各类知识,如研究结论、事实等。美国波士顿马萨诸塞综合医院的Paolo C等提出SWAN(Semantic Web Applications in Neuromedicine)本体,主要用于描述阿尔茨海默病领域论文的外部元数据及其内容,并将其与其他生物医学资源库中的知识相关联。该本体定义了3个主要论证元素:研究声明(Research Statement)表示科学论断或假设、研究问题(Research Question)和评论(Com-ment),并通过一致(ConsistentWith)、不一致(In-consistentWith)、讨论(Discuss)和替代(Alternative-To)语义关系来关联各个论证元素。2020年,王晓光等参考AMO本体、微型出版物模型对科学论文论证过程的基本结构进行了表示,并复用DEO和CoreSCs模型构建了论证本体,该本体包括7个核心类、13个扩展类和15种关系,其中7个核心类基本为图尔敏模型的论证元素,13个扩展类比如事实、相关研究、研究问题等。
总体来说,现有的论文内容描述框架多以篇章结构为基础,从粗粒度和细粒度层面对论文内容组成部分进行表示和建模。但是这种关联关系仅是篇章结构问显性的关联,面对海量的科学论文,科研人员迫切希望了解深层次的知识产生过程。因此,本研究从论证的角度,分析科学论文包含不同功能元素的句子、句子中的实体及句子的语境,借助图尔敏论证结构模型,构建深入、全面地揭示科学论文内容信息的论证结构本体。
2科学论文论证结构分析
2.1波普尔知识增长理论
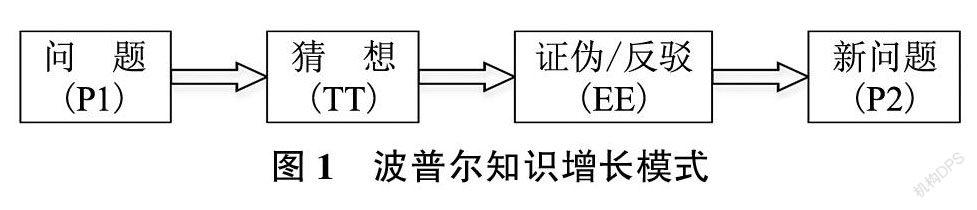
对于科学知识的产生与发展,20世纪著名的科学哲学大师卡尔·波普尔提出了知识增长理论。该理论认为,科学知识的增长不是静止的,而是一个动态发展的过程,这个过程对应着一个动态研究模式,如图1所示。
上述研究模式可以看出,波普尔强调知识增长始于问题(P1),科学问题是科学研究的最初发源地;问题出现以后,学者会提出一些针对性的解决方案,被称为猜想或试探性理论(TT),这些理论是对科学问题的试探性答复。理论之间经过激烈竞争和相互批判,并通过一些决定性的试验排除错误的知识,即进行证伪(EE),最后得出一个相对满意的理论,进而提出新问题(P2),如此以往不断循环深入,使科学知识呈螺旋式增长。
2.2科学研究过程及构成要素分析
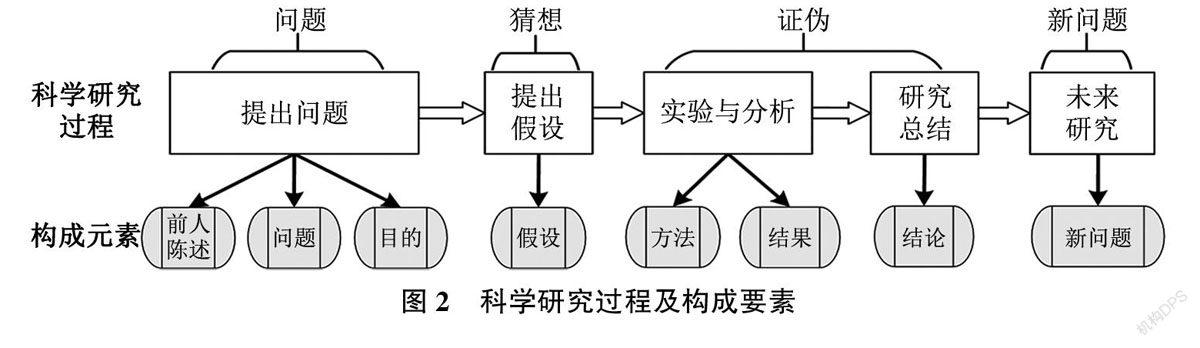
科学论文是科研工作者对科学研究过程及其科学发现进行规范性描述的文本,其主要目的是实现科学交流和知识传播。科学论文报道了科学知识的产生过程,符合波普尔的知识增长理论。基于波普尔知识增长理论,本文对科学研究过程及构成要素进行梳理和归纳,将科学研究过程划分为:提出问题、提出假设、实验与分析、研究总结和未来研究5个阶段,如图2所示。
从图2可以看出,科学研究中的不同阶段包含不同构成要素:提出问题阶段是在已有研究基础上通过分析和查漏补缺发现新的研究问题,由“前人陈述”“研究问题”和“研究目的”3个要素构成:猜想与假设阶段是对科学问题的解决方案的大胆猜想,即“假设”:实验与分析阶段由“研究方法”和“研究结果”构成:研究总结阶段表现为科学“结论”:未来研究设想阶段则在科学“结论”的基础上扩展为“新的研究问题”。针对科学研究过程中包含的这8种要素,本文对其进行了详细定义,如表1所示。
上述分析表明,科学研究有一套系统、规范的流程,在不同阶段由不同类型的要素构成。科学论文是科研工作者对科学研究过程及其科学发现进行规范性描述的文本,其中蕴含了对科学研究各阶段构成元素的描述。因此,从科学论文中抽取出这些构成要素能够重现科学研究的整个过程,反映科学研究的关键环节。
2.3科学论文论证结构模型
科学论文中包含的各要素并非扁平化的罗列,通常要遵循一定的论证结构,只有这样才能说服读者接收作者的科学观点或科学发现,达到科学交流和知识传播的目的。在针对自然语言論证的非形式逻辑中,最具有代表性的论证模型是20世纪50年代英国哲学家和教育学家史蒂芬·图尔敏(Stephen Toulmin)提出的“图尔敏模型”,如图3所示。
通过图3可知,图尔敏论证模型由6个元素构成:理由(Grounds)、保证(Warrant)、主张(Claim)、支援(Backing)、模态限定词(Modality)和例外(Re-buttals)。其中,“主张”是所要论证的命题,“理由”是论证命题的证据,“保证”是用来连接“主张”和“理由”之间的原则、规则或推论许可证,这3个是论证的基本要素,在每个论证中都会出现,构成论证的基本模式,即从理由(Grounds)出发,通过保证(Warrant)推出主张(Claim)。此外,该模型还包含“支援”“模态限定词”和“例外”3个补充要素,其中“支援”是对“保证”的支持,“模态限定词”是对“主张”确定程度的修饰,“例外”是指反例,这3个要素不是必须的,可以根据论证情况有选择地使用。
本文基于图尔敏模型来表示科学论文中各元素间的论证关系,形成科学论文论证结构模型,如图4所示。在科学论文中,论文的“结论(Conclu-sion)”即为要论证的“主张(Claim)”:在关于“结论(Conclusion)”的陈述中,往往包含了反映其确定程度的副词,譬如结论句“All of the Above Re-sults Suggested that Disturbed Cholesterol Homeostasisin Young Rats May Underlie the Deleterious Effects of Lead Induced Early AD-related Pathology”中的副词“May”,这些副词即为对“主张”的“模态限定词(Modality)”;为了证明所提出的“结论”,科学论文中的“方法(Method)”和“结果(Results)”构成了论证中的“理由(Grounds)”,而科学论文中的“前人陈述(PriorStatement)”“问题(Problem)”“目标(Goal)”和“假设(Hypothesis)”则是由理由推出结论的“保证(Warrant)”。
因此,根据图尔敏模型,可以将科学论文的论证结构表述为:首先提出研究问题,并在已有事实或理论基础上进行合理的假设:然后通过实验和分析,得出有价值的结论,该结论可能有限定因素。通过上述分析可以看出,采用图尔敏模型来构建科学论文论证结构,不仅能够细粒度展示科学论文包含的不同元素,而且能清晰地刻画出论文内容的逻辑结构,提升科学知识的可信性。
3科学论文论证结构本体模型构建
3.1论证结构本体概览
上节中构建的科学论文论证结构模型只是一个抽象模型,本节采用OWL本体语言对其进行形式化表示,规范定义模型中的论证元素及其关系,最终生成一个立体化、细粒度的科学论文论证结构本体,如图5所示。
相较于MP本体和王晓光等构建的论证本体,本文构建的论证结构本体更全面、更细粒度地揭示了论文的论证结构,主要从语句、实体及语境3个层面来描述论文的论证结构:论证元素的粒度为句子级;陈述型论证元素(前人陈述、结论和结果)采用“实体—关系—实体”三元组来表示:以“确定程度”为对象属性来描述结论,增加其语境信息。
科学论文论证结构本体主要复用了DEO、Nan-opublishing、AMO和MP这4个本体中的部分词汇。DEO本体是由Shotton D等和Peroni S于2015年构建的语义出版与参考本体(Semantic Publishing and Referencing Ontologies,简称SPAR本体)家族中的一员,用于描述科学论文中的修辞要素,包括介绍、方法、材料、结果、参考文献等。Nanopublishing本体是由概念网络联盟于2005年提出的纳米出版模型的OWL本体版,用于对科学论文中的结论或观点进行语义化描述,以“主—谓—宾”三元组形式表示最小无歧义的知识单元。AMO本体其实是图尔敏模型的OWL本体版,由Vitali F等于2011年采用OWL2DL语言對图尔敏模型进行语义化重构后生成。MP本体是哈佛医学院的ClarkT等提出微出版模型(Mircopublication)本体,用于对论文中的论证元素及其关系进行语义描述。除了复用上述本体中的类和属性之外,科学论文论证结构本体中还包含了自定义的类和属性,采用前缀spsao(http:∥www.example.com/spsao#)表示。下面将对该本体中的主要类和属性(关系)进行详细介绍。
3.2论证结构本体的主要类和关系
科学论文论证结构本体中的主要类如表2所示,主要属性如表3所示。
在科学论文论证结构本体中,最核心的类是spsao:Conclusion(结论),表示科学论文的最终结论,是AMO本体中amo:Claim(主张)类的一个子类。结论类具有属性spsao:hasQualifier(确定程度),描述结论的确定程度,其值域是spsao:CerntainLev-el(确定程度)类。该类是AMO本体中amo:Qualifer(限定词)类的一个子类,是一个枚举类,只有Weakly(弱)、Moderately(中)和Strongly(强)3个值。同时,spsao:CemtainLevel(确定程度)类具有属性amo:forces(对…强调),描述该类的强调对象,其值域为结论类。结论类还具有对象属性amo:hasEvidence(具有证据…),描述支持该结论的证据,其值域是DEO本体中的deo:Result(结果)类。该类和deo:Method(方法)类均是AMO本体amo:Evidence(证据)类的子类,而且方法和结果之间是amo:supports(支持)关系。
spsao:PriorStatement(前人陈述)类、spsao:Problme(问题)类、spsao:Hypothesis(假设)类和spsao:Goal(目标)类4个类为AMO本体amo:War-rant(理由)类的子类,它们都是支持结论类的正当理由。其中,假设类为可缺省类,即论文中可能不包含假设这一论证元素。前人陈述和问题之间是amo:leadTo(引发)关系,问题和目标之间是spsao:produces(产出)关系,目标类具有对象属性amo:leadTo(引发),其值域为spsao:Conclusion(结论)类;问题和假设之间是spsao:produces(产出)关系,假设类也具有对象属性spsao:produces(产出),其值域为spsao:Conclusion(结论)类。
此外,spsao:PriorStatement(前人陈述)类和spsao:CurrentStatement(当前陈述)类均是MP本体中mp:Statement(陈述)类的子类,该陈述类具有对象属性rdf:subject(主语)、rdf:predicate(谓语)和rdf:object(宾语),值域为spsao:Entity(主语、宾语实体/概念)和rdf:Property(关系类)。
3.3语义描述实例
基于构建的科学论文论证结构本体,以科学论文“Genetically Elevated Gamma-glutamyhransferaseand Alzheimer’s Disease”为例,采用手工方式对该论文中包含的论证元素及其关系进行语义标注,结果如图6所示。
本文构建的实例命名空间为“@prefix ex:ht-tp:∥www.example.org/.”。案例论文从两个前人陈述出发,发现了研究问题“γ-谷氨酰转移酶和阿尔茨海默病之间的关系尚不清楚”,然后提出假设“脑胆固醇代谢紊乱是铅暴露导致早期AD相关结果的发病机制中的一个候选病因”,通过一系列的实验方法得到实验结果,最后得到最终的研究结论,即“研究结果不能证实γ-谷氨酰转移酶(GGT)对阿尔茨海默病(AD)风险的任何因果关系”,其包含的实体—关系—实体为“γ-谷氨酰转移酶(GGT)—不能影响(cannot_effect)—阿尔茨海默病(AD)”,限定词是“Strongly”表示论文得出的结论非常确定。
如图6所示,通过基于科学论文论证结构本体的语义标注,可以将非结构化的科学论文文本转换为结构化的RDF数据。生成的RDF数据可以采用关联数据形式进行发布,以供读者浏览和查询。一方面可以帮助读者快速获得科学论文宏观的论证结构:另一方面可帮助读者精确定位细粒度的微观信息,如研究结论、研究方法、研究假设等。此外,还可以进一步探索其他相关论文的信息。
4论证结构语义数据的应用
4.1论证结构语义数据应用框架
为了验证所构建的科学论文论证结构本体,以5篇生物医学领域实验型论文为例,通过手工标注方式构建本体的实例数据,实现科学论文中论证要素及其论证关系的全方位语义关联。首先,从论文的不同部分分别抽取出相应的论证元素:从“引言”章节中抽取出前人陈述、问题、假设和目的4项论证元素:从“结果”章节中抽取出方法和结果2项论证元素:从“讨论/结论”章节中抽取出结论。接下来,基于构建的科学论文论证结构本体,将从论文中抽取出的论证元素转换为RDF格式,各元素的值均是自然语言文本。对于“前人陈述”“结果”和“结论”这3种关于科学观点或科学论断的陈述,则被进一步转换为“实体—关系—实体”三元组形式,“结论”的确定程度也被识别。
为了展示科学论文论证结构关联数据的应用,本文设计了一个应用架构,如图7所示。该架构在Windows环境下运行,采用Web浏览器/Web服务器/数据服务器3层架构,空心箭头为数据输入路线,实心箭头为数据输出路线。科学论文论证结构关联数据集存储在RDF三元组存储器JeanaTDB中,通过RDF查询服务器Jena Fuseki作为数据接口来接受外界的访问。Tomcat作为Web服务器负责用户请求的调度、SPARQL查询语句的构建和查询结果的格式转换,以及Web页面的发布。Web浏览器负责用户输入和关联数据查询与分析结果的展示。应用场景主要有两类:基于内容的语义查询和基于内容的知識可视化显示。
4.2基于内容的语义检索
语义检索主要是基于科学论文论证结构关联数据,有针对性地查询科学论文中的特定论证元素,如前人陈述、假设、目的或结论等。查询可以通过内置的SPARQL查询模板来实现。本节列举了以下3种主要的语义检索方式。
1)查询科学论文中的特定论证元素。通过查询论文中的特定元素,譬如,查询某一篇论文的研究结论,科研人员可以快速获得其感兴趣的信息,以提高查询和阅读论文的效率。
2)查询科学论文中的特定实体。前人陈述、研究结果和研究结论均为科学陈述,因此被进一步转换为“实体—关系—实体”的三元组表示形式。因此,可以查询包含特定实体的论证元素及其所在论文,譬如,查找在结果和结论中包含了“γ-谷氨酰转移酶(GGT)”实体的科学论文。
3)查询具有某种确定程度的科学论文结论。可以查询论文中具有不同确定程度(强、中、弱)的结论,以便获得精准的科学知识。
图8所示为查询具有某种确定程度的结论及其来源论文的SPARQL查询语句,矩形框内的值为结论的确定程度,可以是:Weakly(弱)、Moder-ately(中)和Strongly(强),用户可以根据自己的需求选择不同的查询限制。检索结果如图9所示,检索到的两篇科学论文的结论分别采用“might”和“maybe”这样的限定词,说明这两个结论的不确定性,从而帮助读者判断科学知识的准确性。
4.3基于内容的知识可视化分析
科学论文中的知识往往分散在论文不同章节之中,通过对科学论文论证结构进行语义表示,可以将论文中的知识结构化和显性化。在此基础上,可以采用可视化技术以图形化方式更加生动、形象地展示科学论文的知识,帮助用户更好地理解和利用语义数据,进一步发现其中隐含的规律。面向科学论文论证结构关联数据可视化方式主要有两种:①论文论证结构的可视化:从宏观角度出发,概览一篇科学论文整体的论证结构;②论文中实体—关系的可视化:从微观角度出发,展示一篇科学论文内部实体间的语义关系。
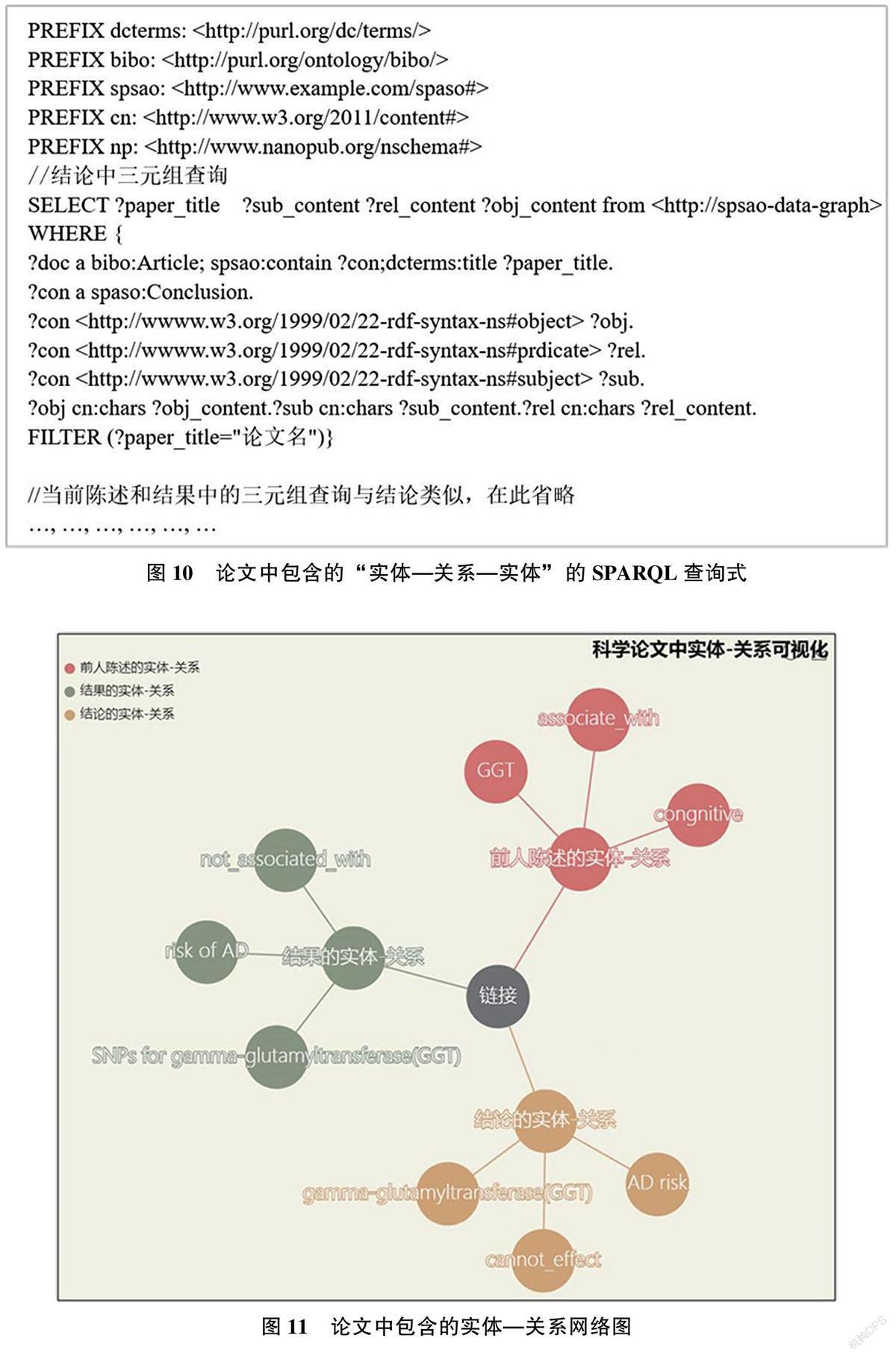
本节聚焦于实体—关系可视化方式,以实例展示一篇科学论文中包含的简单实体—关系网络。首先,查询一篇科学论文中陈述的实体及其关系,即“前人陈述”“结果”和“结论”这3个论证元素中包含的“实体—关系—实体”三元组,对应的SPARQL查询语句如图10所示。在分别得到这3个论证元素的RDF三元组数据后,将该数据转换为图形格式并返回给浏览器,在Web客户端以网络图方式展示实体—关系网络,如图11所示。从图中可以看出,该论文中“前人陈述”“结果”和“结论”这3个论证元素中包含的实体—关系构成了一个简单的研究逻辑,即前人研究过“γ-谷氨酰转移酶(GGT)和认知能力的关系”,而“认知能力”又与“阿尔茨海默病(AD)”相关,作者通过实验得出结果之一“GGT相关的26单核苷酸多态性与AD不相关”,最终得出结论“γ-谷氨酰转移酶(GGT)不能影响阿尔茨海默病(AD)”。
5结语
本文提出了一种面向科学论文内容的论证结构本体,该本体详细定义了科学论文中包含的多种论证元素、陈述型论证元素的实体—关系表示及论证关系,使科学论文的内容结构显性化、模块化,可以有效促进科学交流和科学研究。本文首先基于波普尔知识增长理论来解释科学研究的过程,从而总结出科学论文中包含的7种论证元素:前人陈述、问题、假设、目的、方法、结果和结论。然后,基于图尔敏模型对论证元素间的论证关系进行语义建模。在复用DEO、AMO、Nanopublishing等本体的基础上,采用OWL语言构建了科学论文论证结构本体模型,并通过一篇科学论文实例展示了该本体对论文中的论证元素及其论证关系进行语义描述的结果。此外,在语义描述的基础上,通过基于内容的语义检索、语义数据可视化等实验,展示了科学论文论证结构语义化表示的应用效果。在后续研究中,拟采用自然语义处理与文本挖掘技术自动识别科学论文中的论证元素及其论证关系,实现对科学论文内容及结构的自动语义标注,以期构建面向知识服务的科学交流系统。
(责任编辑:郭沫含)
猜你喜欢
哲学分析(2023年4期)2023-12-21
中等数学(2022年7期)2022-10-24
中国音乐学(2020年4期)2020-12-25
开放教育研究(2020年2期)2020-03-31
现代语文(2016年21期)2016-05-25
文学教育(2016年27期)2016-02-28
大连民族大学学报(2015年2期)2015-02-27
外语学刊(2011年1期)2011-01-22
小学生导刊(高年级) (2006年6期)2006-06-27
