
基于YOLOv5 的移动机器人目标检测算法的研究
2021-12-21 08:14周裔扬邓三鹏祁宇明李丁丁
装备制造技术 2021年8期
周裔扬,邓三鹏,祁宇明,王 振,陈 伟,李丁丁
(1.天津职业技术师范大学机器人及智能装备研究院,天津 300222;2.天津市智能机器人技术及应用企业重点实验室,天津 300352)
0 引言
移动机器人目标检测是机器人对抗、军事侦察和物料搬运等领域的关键技术。移动机器人通过所部署的视觉传感器了解周围的复杂环境,识别周围的目标,并对其进行定位。近年来,基于深度学习的目标检测算法在检测效果方面取得了进展,同传统方法相比,在复杂环境下的准确率和检测速度有着质的飞跃。深度学习检测算法在语音识别、图像识别和自然语言处理等领域得到应用,基于卷积神经网络的移动机器人检测算法具有广泛的应用前景和重大的实用价值[1]。卷积神经网络是一种通过对现有的大量数据进行训练从而搭建一个具有特定特征的模型来进行特征学习的机器学习方法,目前为止已经有R-CNN,Faster R-CNN,Fast R-CNN 和YOLO 等检测算法。YOLO 采用彻底的端到端的检测方法,不需要区域建议寻找目标,具有检测速度快,背景误判率低等优点[2]。目前经过几年的更新迭代,已经更新到YOLOv5。
1 基于改进YOLOv5 网络模型及识别原理
1.1 YOLOv5 的网络结构
Yolov5 目标检测网络中有Yolov5s、Yolov5m、Yolov5l 和Yolov5x 一共四个版本。Yolov5s 网络是Yolov5 系列中深度最小,特征图宽度最小的网络,是其它3 种的基础。鉴于研究的检测目标是移动机器人,根据检测的目标大小,为了保证检测目标的速度和精度以及后续的研究目的,由此选择Yolov5s 作为主干网络。Yolov5s 的网络结构如图1 所示。
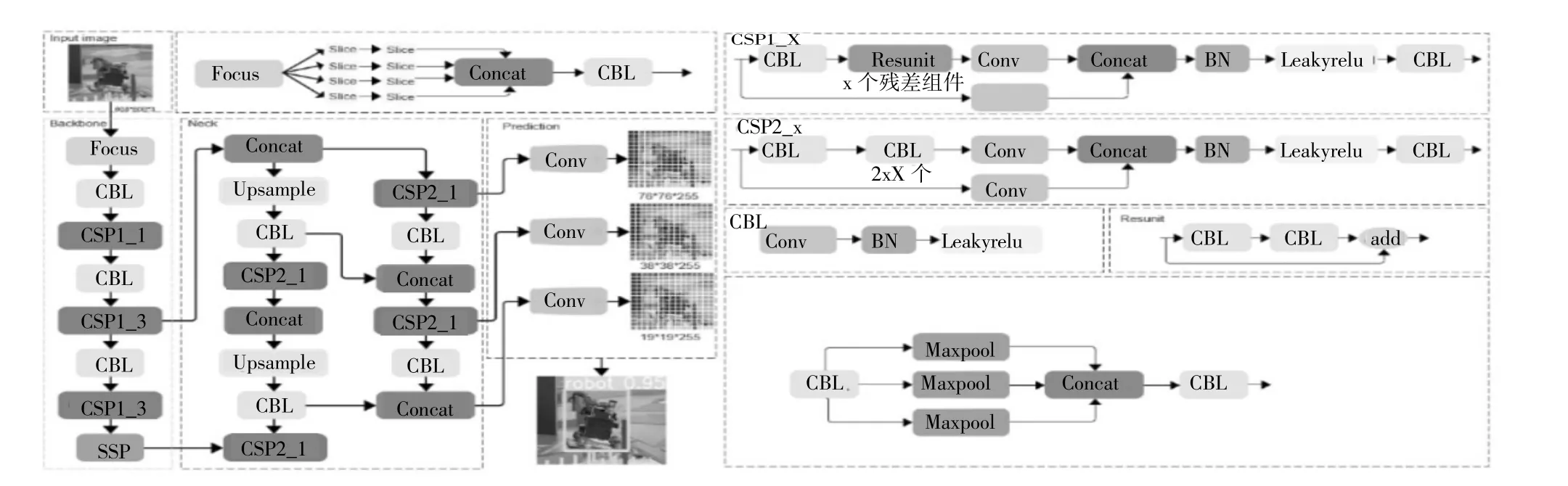
图1 YOLOv5 的网络结构
YOLOv5 核心的运行流程为:
(1)输入端部分:输入端首先使用Mosaic 数据增强的方式对数据集进行随机缩放、随机裁剪、随机排布,通过选取4 张图片进行拼接后投入训练,这样的方式丰富了图像的背景,同时也增强了网络检测小目标的能力,大大提高了网络的鲁棒性[3]。在YOLO算法中,根据数据集的差异,初始都会有设定长宽的锚框。在训练过程中,网络会在初始锚框的基础上,先输出预测框然后同真实框ground truth 进行比较,计算出双方的差距,再反向更新锚框,迭代网络参数,这样就可以获取训练集中最佳的锚框值。
(2)骨干网络部分:骨干网络部分包括Focus 结构和CSP 结构。Focus 结构指的是输入608×608×3的图像,随后进行切片操作,从而得到304×304×12的特征图,随后再经过一次32 个卷积核的卷积操作,最后输出304×304×32 的特征图[4]。在Yolov5s中,含有两种CSP 结构,其中,Backbone 主干网络使用CSP1_X 结构,Neck 则使用CSP2_X 结构。
(3)多尺度特征融合模块[5]部分:多尺度特征融合模块使用的是FPN(Feature Pyramid Networks,特征金字塔网络)+PAN(Pyramid Attention Network,金字塔注意力网络)结构。FPN 是通过由上而下的方式将顶端的特征信息与骨干网络的特征信息相融合,传递强语义特征信息,随后PAN 再通过由下而上的方式进一步实现强定位特征的传递。两者相结合构成了多尺度特征融合模块部分,加强网络的特征信息。
(4)预测端部分:预测端输出3 个尺度的特征图,分别为19×19、38×38 和76×76 的网格,对应检测大目标、中目标、小目标。在最后,使用非极大值抑制(NMS)的方法,筛选掉重复冗余的预测框,保留下置信度最高的预测框信息,完成预测。
1.2 改进的YOLOv5 的网络
使用Varifocal Loss 替换原先的Focal Loss 来训练密集目标检测器来预测IACS(置信度和定位精度的IoU 感知分类评分)[6]。Varifocal Loss 源自于Focal Loss。在密集目标检测器训练中,常常会有前景类和背景类之间及其不平衡的问题,所以我们常常会使用Focal Loss 在解决此类问题。Focal Loss 定义为:
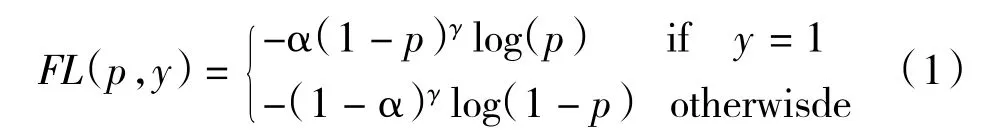
其中y∈{±1}为ground truth 类,而p∈[1,-1]则为前景类的预测概率。如公式所示,调制因子(为前景类和为背景类)的作用是减少简单样例的损失贡献,同时相对增加误分类样例的重要性。
因此,Focal Loss 防止了训练过程中大量的简单负样本淹没检测器,并将检测器聚焦在稀疏的一组困难的例子上。
在训练密集目标检测器时,通过借鉴Focal Loss的加权方法来解决在对连续IACS 进行回归时类别不平衡的问题。但与此同时,不同的Focal Loss 处理的正负相等,存在不对称的对待。这里Varifocal loss也是基于binary cross entropy loss,定义为:
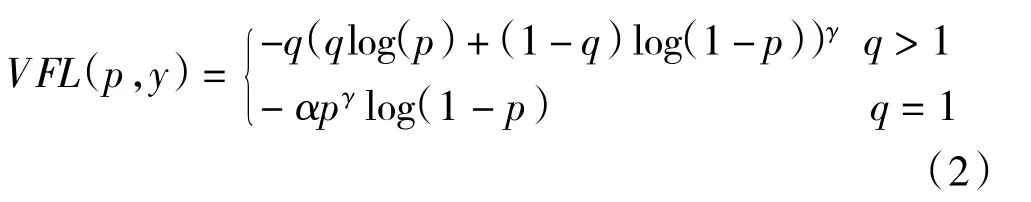
其中p为预测的IACS,代表目标分数。对于前景点时,将其ground truth 类q设为生成的边界框和它的ground truth(gt_IoU)之间的IoU,否则为0,在对于背景点时,所有类的目标q为0。
如公式所示,使用q的因子缩放损失后,Varifocal loss 仅减少了负例(q=0)的损失贡献,并没有以同样的方式降低正例(q>0)的权重。因为positive 样本相对于negatives 样本非常罕见,由此保留它们的学习信息。另一方面,受PISA 的启发将正例与训练目标q加权。如果一个正例的gt_IoU 比较高,则它对损失的贡献就会比较大。因此需要把训练的重点放在那些高质量的正面例子上,高质量的正面例子同低质量的例子相比,其可以获得更高的AP,对训练也更为重要。
2 实验及分析
2.1 移动机器人数据集选择
移动机器人数据集包含了医疗机器人、巡逻机器人、防爆机器人、消防机器人、物流机器人等各个机器人功能领域,并在不同的移动机器人移动视频中截取了一部分图片作为数据集,在数据集选择方面涵盖了绝大部分主流的移动机器人,同时也涵盖了各种移动机器人工作场景,具有丰富的多样性和优秀的泛化能力。
2.2 移动机器人硬件平台搭建
实验设计的整体框架流程图如图2。

图2 整体框架流程图
首先在平台上训练好基于YOLOv5 的移动机器人模型,然后将训练好的模型部署在Jetson TX2 开发板上,移动机器人利用摄像头实时采集现场图像后传输到Jetson TX2 开发板中进行处理,Jetson TX2 开发板利用训练好的模型实时监测图像中是否含有移动机器人,最后将检测结果通过串口发送给终端STM32,STM32 控制移动机器人采取追踪,撤退等操作。最终搭建的机器人系统硬件如图3,RGB-D 相机固定在移动机器人前端,处理采集环境信息的开发板固定在移动机器人后端。二维激光雷达位于移动机器人最上方,其通过高速旋转的激光发射器和接受器来获得移动机器人周围二维水平面上的点云信息,帮助移动机器人获取自身的位置,为移动机器人自主导航提供支持。

图3 移动机器人硬件平台
2.3 模型训练与实验环境
实验中的运行环境:CPU 为Intel i7 9750H,GPU为NVIDIA GeForce RTX 2060,内存为16G,操作系统为windows 10,安装CUDA11.2 库文件,开发语言为Python,训练平台是Pycharm,训练采用的深度学习框架为pytorch1.8.1。训练选用的batchsize 为16,epochs为300,选用的权重为YOLOv5s。
图为改进后的YOLOv5 网络损失函数曲线,由图4 可以看出,训练模型迭代80 次后损失函数收敛。直到训练完成时,都未产生过拟合的现象,训练效果理想。

图4 改进的YOLOv5 损失函数曲线
2.4 结果分析
实验检测效果如图5 所示,各种类型的移动机器人可以被很好的检测出来。

图5 部分检测识别效果
在机器学习模型评估中,混淆矩阵解析法是评价模型准确度中最基本和直观的方法。混淆矩阵如图6 所示。

图6 混淆矩阵解析法
准确率(Precision)指的是所得数值与真实值之间的精确程度;预测正确的正例数占预测为正例总量的比率,一般情况下,准确率越高,说明模型的效果越好。准确率公式如下:

召回率(Recall):预测对的正例数占所有正例的比率,一般情况下,Recall 越高,说明有更多的正类样本被模型预测正确,模型的效果越好。召回率公式如下:
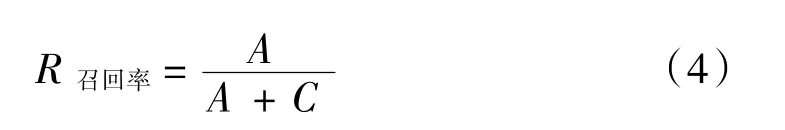
模型评估中,单一追求Precision 或者单一追求Recall 都会造成非常严重的错误检测,所以我们需要对模型的Precision 和Recall 两者进行结合,综合考量。由此我们使用mAP(mean Average Precision)对目标检测算法性能进行评价。AP指的是,利用不同的Precision 和Recall 的点的组合作图以后所围成图形的面积,这个面积就是某个类的AP值,而mAP就是所有的类的AP值求平均。
通过分析训练数据,并使用Python 绘制mAP图像,图像如图7。

图7 模型性能评估
通过数据结果,该模型的mAP达到了94.6%,检测效果优异,绝大部分的移动机器人样本都可以被该模型很好的检测出来。
为了验证YOLOv5 改进算法的性能,研究选取相同的数据集并在不同的算法上进行对比实验。对比实验包含的算法有SSD 算法、Faster R-CNN 算法、YOLOv5 算法和改进后的YOLOv5 算法,对比结果如表1。

表1 不同算法检测性能对比
分析数据可以看出,改进后的YOLOv5 目标检测算法相对于Faster R-CNN 算法和SSD 算法的各项模型评估指标都有显著提升。而比起改进前的YOLOv5目标检测算法在mAP上提升了1.69%,识别速度也达到了89 帧/秒。
3 结语
研究将YOLOv5 目标检测网络模型应用到移动机器人目标检测领域,使用训练集对目标检测网络模型迭代80 次后损失函数收敛。通过使用Varifocal Loss 替换原先的Focal Loss 来训练密集目标检测器来预测IACS 改进后的检测网络性能提升,目标检测模型mAP 达到94.6%,且对环境具有一定的鲁棒性,实现了移动机器人的目标检测精确度提升。但移动机器人种类较多,后续将在数据集完善、提高不同情形下的识别准确率等方面进一步研究。
猜你喜欢
黄河之声(2022年10期)2022-09-27
北京航空航天大学学报(2022年6期)2022-07-02
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
制造技术与机床(2017年3期)2017-06-23
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28
