
湘西苗文词性标注知识库系统的构建
2021-12-18 12:40莫礼平胡美琪唐琰
电脑知识与技术 2021年31期
关键词:语料库
莫礼平 胡美琪 唐琰

摘要:为了解决词性标注技术研究过程中所涉及的词性标注语料及词性标注规则等知识的管理问题,以系统功能、词性标注语料库、词性电子词典、词性标注规则库和词性标注规则自动获取方法的设计与实现为重点,构建了一个湘西苗文词性标注知识库系统。测试情况表明,该系统不但具备词性标注语料及词性标注标注规则的常规管理功能,而且支持用户从语料库自动提取词性标注规则,并对测试语料进行词性自动标注,能够满足湘西苗文词性标注技术研究的基本需求。
关键词:词性标注;知识库系统;语料库;规则库
中图分类号:TP391.1 文献标识码:A
文章编号:1009-3044(2021)31-0009-04
The Construction of the Knowledge Base System for Part-of-Speech Tagging in Xiangxi Hmong
MO Li-ping*, HU Mei-qi, TANG Yan
(College of Information Science & Engineering, Jishou University,Jishou 416000, China)
Abstract: To solve the problem of knowledge management such as part-of-speech (POS) tagging corpus and POS tagging rules involved in the research process of POS tagging technology, a knowledge base system for POS tagging in Xiangxi Hmong is constructed by focusing on the design and implementation of system functions, POS tagging corpus, POS electronic dictionary, POS tagging rule base, and automatic acquisition method of POS tagging rules. The test results show that the POS tagging knowledge base system not only has the regular management functions of POS tagging corpus and rules, but also supports users to automatically extract POS tagging rules from the corpus and automatically tag corpus, which can meet the basic needs of the research on the technology of part-of-speech tagging in Xiangxi Hmong.
Key words: part-of-speech tagging; knowledge base system; corpus; rule base
1 引言
词性标注是自然语言处理领域的基础课题之一,在语义理解、机器翻译、文本语音转换等自然语言处理应用中起着至关重要的作用。词性标注相关研究始于上世纪 60 年代初对世界最早的机读语料库—Brown语料库中的英文语料的词性标注工作[1]。历经近60年的发展,英文词性标注技术已趋于成熟,国外面向意大利文、阿拉伯文等文字的词性标注技术也发展迅速[2-3]。国内面向汉字、藏文、维吾尔文、蒙古文等文字的词性标注研究工作起步较早且成果丰硕[4]。面向汉、藏、维、蒙的词性标注技术当前已同深度学习模型紧密结合,取得了比传统词性标注方法显著优异的词性标注效果[5-8]。然而,国内面向苗文的词性标注相关研究工作刚刚起步,前期仅有周潭等[9]从词性标记集的设计,Li H C等[10]从基于隐马尔可夫模型(Hidden Markov Model,HMM)的苗汉混合文本词性自动标注等方面开展了一些尝试性研究工作。
本文结合苗文信息化的实际需要,探讨湘西苗文词性标注知识库系统的设计和实现方法,以期为湘西苗文的词性自动标注和智能处理技术研究奠定基础,并为武陵山片区湘西民族文化资源大数据的开发及利用提供工具支持。
2 湘西苗文语料收集处理及词性标记集设计
2.1 语料收集处理
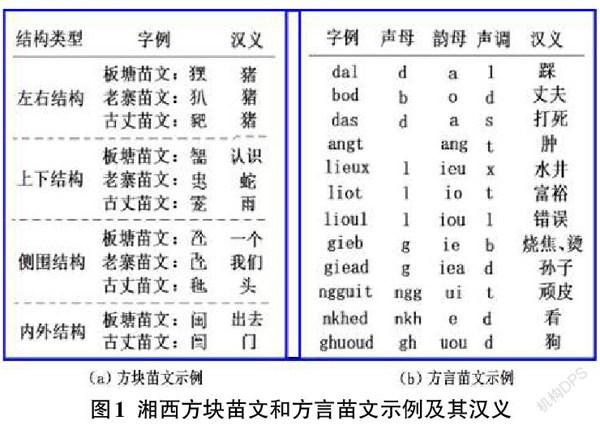
湘西苗文是指在武陵山片区湘西土家族苗族自治州苗民聚居地流行使用的苗文,分为图 1所示的方块苗文和方言苗文两大类。方块苗文是一种仿汉字结构的文字,是表意苗文的代表,共分为老寨苗文、古丈苗文和板塘苗文三套[11]。方言苗文(也称湘西新苗文)基于拉丁字母,是拼音苗文的代表。据文献[12],中国科学院1956年组织中国少数民族语言第二调查队详细调查了湘西苗语使用情况,根据调查结果创制了湘西方言的《苗文方案(草案)》,并从1958年开始在湘西花垣县和凤凰县试验推行新苗文,1961年因故中止,1983年得以恢復。推行期间,政府编印出版了大量新苗文读物,取得文字普及的良好效果,有力地推动了当地经济文化事业的发展。方言苗文又分为中东部土语苗文和西部土语苗文两类。前者分布在湘西自治州的泸溪、吉首、龙山等县,以龙山苗语苗文为代表;后者则分布在吉首、凤凰、龙山、凤凰、花垣等县,其代表是吉卫苗语苗文和矮寨苗语苗文。
通过学校图书馆民族文献借阅、网络文献检索、民间实地调查搜集等途径,我们已经搜集了大量记载苗文词汇、语句、民间故事、民歌民谣等湘西苗文相关手稿、书稿和其他类型的资料。在对这些资料进行整理归类的基础上,经拍照、扫描、图片加工等处理,借助国际音标输入法软件、“扫描全能王”文字识别软件,以及方块苗文输入法软件录入湘西苗文原始语料;然后,结合向日征编著的《汉苗词典(湘西方言)》和石如金编著的《苗汉汉苗词典》,设计语料数据库,制成了与汉语对等理解度的湘西苗文词级生语料。
2.2 词性标记集的设计
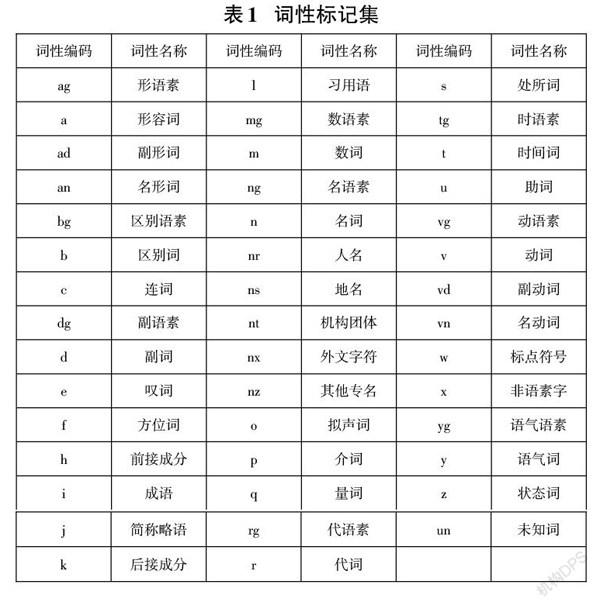
在根据生语料的统计分析结果确定湘西苗文词语的种类和词性的基础上,我们直接借鉴北京大学计算语言学研究俞士汶主编的《现代汉语语料库加工―词语切分与词性标注规范与手册》中的词性编码方法进行苗文词性标注符号、形式和风格的设计。通过对周潭等[9]设计的方块苗文词性标记集进行扩充,建立了如表1所示的较完整的湘西苗文词性标记集。
3 湘西苗文词性标注知识库系统的设计
下面从系统功能模块设计、苗文词性电子词典设计、苗文词性规则库设计,以及词性标注规则自动获取方法设计等几个方面来介绍湘西苗文词性标注知识库系统的设计方法。
3.1系统功能模块设计
湘西苗文词性标注知识库系统主要包括语料库管理、规则处理和词性自动标注三个重要模块。其中的核心子模块功能设计如下:
(1)语料库管理功能:湘西苗文词性标注知识库系统中的语料以文件形式保存,用户可以将已标注语料以文件形式导入或导出,也可以通过操作系统的资源管理器选择语料文件来查询、添加、修改或删除;
(2)规则手动导入功能:允许用户把事先手工编制的词性标注规则文件导入系统;
(3)规则自动提取功能:利用关联规则挖掘算法从已标注语料库中自动提取规则,并将规则保存在知识库系统的规则库中;
(4)规则管理功能:手动导入及自动提取的词性标注规则在湘西苗文词性标注知识库系统中均以条目形式进行保存,用户可以对相应规则进行增加、查询、修改或删除等常规管理;
(5)词性自动标注功能:用户可以利用规则库中存储的词性标注规则对语料测试样例进行词性标注,并对标注结果进行保存或输出处理;
(6)测试样例管理功能:用户可以从外部文件导入语料测试样例以供自动标注测试,并对测试样例进行查询、添加、修改、删除等操作。
3.2 苗文词性电子词典设计
湘西苗文词性电子词典结构按照汉语语法的传统用法来设计。首先,将苗文粗分为实词和虚词两大类;然后,再在这两大类的基础上根据词的语法功能进行细分,并对其进行详细地描述。电子词典的结构包括如下三部分:
(1)词性本身:名词、动词、副词、形容词等;
(2)语法功能:逻辑结构、功能描述、形式结构等;
(3)其他:习惯用法、词语搭配、语言色彩、解释说明等。
3.3 苗文词性标注语料库设计
首先依据苗文词性电子词典来手工标注湘西苗文词性,进而创建苗文词性标注语料库。语料库中手工标注的语料以“词性”为基础,对文本进行汉语翻译和分词后对每一个词语附上相应的词性标签。表2以方言苗文为例,给出了湘西苗文词性标注语料库的内容示例及附加说明。
3.4 苗文词性标注规则库设计
词性标注规则是规则类词性自动标注方法进行词性标注的依据。湘西苗文词性标注规则库中存储的规则通常设计为形如“if … then …”的产生式规则。例如,“if(Word1,Tag1) then(Word2,Tag2)”和“if(Word1,Tag1) and(Word2,Tag2) then(Word3,Tag3)”的产生式规则分别表示前1-2个词或词性的组合对当前词的词性影响的规则。由于同一个词语在不同上下文环境中可能拥有不同词性,使得根据不同规则来确定同一词语的词性时可能发生冲突,为了提高标注的准确率,每一条规则定义一个置信度来表示该规则的准确程度。进行词性标注时,优先选择置信度较高的规则作为标注依据。
湘西苗文词性标注规则库中存储的规则既包括结合苗文词性电子词典和词性标注语料库手工编制的词性标注规则,又包括应用关联规则挖掘FP-Growth算法从词性标注训练语料库中自动获取的词性标注规则。
3.5 基于FP-Growth算法的词性标注规则自动获取方法设计
湘西苗文词性标注知识库系统涉及到的核心算法是用于自动获取词性标注规则的FP-Growth算法。该算法过程主要包括计算候选模式集、提取频繁模式集和生成关联规则三个阶段。FP-Growth算法应用于词性标注规则自动获取的方法设计如下:
(1)以词性标注训练语料库作为事务数据库;
(2)采用FP-Growth算法扫描事务数据库,构建模式前缀树FP-tree来存储候选模式集,从训练集的句子中提取不同长度的模式,用以生成候选模式集;
(3)构建条件模式基FP-tree,并根据用户给定的最小支持度,从候选模式集中挖掘大于最小支持度的各种长度模式的频繁模式集;
(4)针对各个频繁模式,生成形如“a1a2,...,ak-1ak=>(wk,ak)”的关联规则;
(5)如果得到的关联规则满足用户给定的最小置信度,则将规则改写成形如“if(Word1,Tag1) then(Word2,Tag2)”或“if(Word1,Tag1) and(Word2,Tag2) then(Word3,Tag3)”的产生式规则,将其加入规则库。
4 湘西苗文詞性标注知识库系统功能界面的实现
下面以语料库管理、词性标注规则处理、自动标注三个功能为例来介绍湘西苗文词性标注知识库系统主要功能界面的实现。
4.1语料库管理功能界面
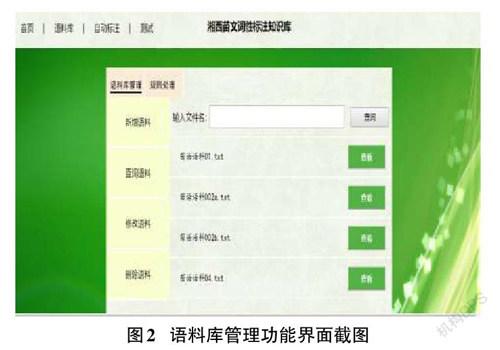
湘西苗文词性标注知识库系统中的语料主要来自于吉卫苗语苗文、湘西矮寨苗语苗文和龙山苗语苗文,以及三套方块苗文。前期,我们已针对《苗文课本》(1-4册)、《吉卫苗语研究》《龙山苗语实录与导读》《苗族语言与文化》《湘西矮寨苗语》等书籍内容,在进行人工录入、检验、分词和标注等工作的基础上,建立了湘西苗文词性标注语料数据库。数据库中存储的语料既包含手工标注语料,也包括前期采用隐马尔科夫模型方法自动标注的语料。湘西苗文词性标注知识库系统提供了对这些语料进行添加、查询、修改和删除的功能。语料库管理功能界面运行效果如图2所示。
实现语料库管理功能界面的关键源代码如下。
<div class="bgai" id="fun1" style="display: none;">
<div class="leftm">
<div class="opt" onclick="location.href='input_rule.html'">新增语料</div>
<div class="opt">查询语料</div>
<div class="opt">修改语料</div>
<div class="opt">删除语料</div>
</div>
<div class="topseek">
<div class="tip">输入文件名:</div>
<input type="text" id="edt" onclick="" />
<input type="button" id="btn" value="查询" onclick="" />
</div>
<div class="btmlist">
<div class="item"><div class="itemtext">吉卫苗语例句STD.txt</div><button>查询</button></div>
<div class="item"><div class="itemtext">苗语语料002a.txt</div><button>查询</button></div>
<div class="item"><div class="itemtext">苗语语料002b.txt</div><button>查询</button></div>
<div class="item"><div class="itemtext">苗语语料04.txt</div><button>查询</button></div>
</div>
</div>
4.2 词性标注规则处理功能界面
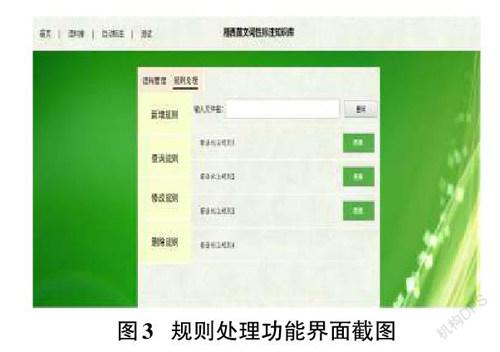
湘西苗文词性标注知识库系统中的词性标注规则以条目形式进行保存。用户可以将事先手工编制的词性标注规则文件导入到系统的规则库中,也可以利用关联规则挖掘FP-Growth算法从已标注语料库中自动提取规则,并将提取的规则保存到系统的规则库。用户使用系统提供的规则管理功能对规则库中的规则进行新增、查询、修改或删除等常规管理。规则处理功能界面运行效果如图3所示。
实现规则处理功能界面的关键源代码如下。
<div class="bgai" id="fun1" style="display: none;">
<div class="leftm">
<div class="opt" onclick="location.href='input_rule.html'">新增规则</div>
<div class="opt">查询规则</div>
<div class="opt">修改规则</div>
<div class="opt">删除语料</div>
</div>
<div class="topseek">
<div class="tip">輸入文件名:</div>
<input type="text" id="edt" onclick="" />
<input type="button" id="btn" value="查询" onclick="" />
</div>
<div class="btmlist">
<div class="item"><div class="itemtext">苗语标注规则1</div><button>查询</button></div>
<div class="item"><div class="itemtext">苗语标注规则2</div><button>查询</button></div>
<div class="item"><div class="itemtext">苗语标注规则3</div><button>查询</button></div>
<div class="item"><div class="itemtext">苗语标注规则4</div>button>查询</button></div>
</div>
</div>
4.3 语料自动标注功能界面
湘西苗文词性标注知识库系统提供了词性自动标注功能,允许用户利用规则库中存储的词性标注规则对语料测试样例进行词性标注,并把结果进行保存或输出。用户可以从外部文件导入语料测试样例以供自动标注测试。同语料库管理功能一样,系统也支持对测试样例的增加、查询、添加、删除等操作。自动标注功能界面运行效果如图4所示。
实现语料自动标注功能界面的关键源代码如下。
<div class="bgai" id="fun2">
<input type="text" value="语料库>语料B.txt" />
<input type="button" value="手动输入测试样例" />
<input type="button" value="从语料库中选择" />
<div id="inputarea">输入预览</div>
<textarea></textarea>
<div id="outputarea">标注结果</div>
<textarea></textarea>
<div id="out">导出结果</div>
</div>
5 结束语
构建湘西苗文词性标注知识库系统之后,我们根据重新收集整理得到的湘西苗文语料,对系统中词性标注语料库和词性标注规则库的内容进行了补充丰富。然后,对经上述处理后的湘西苗文词性标注知识库系统进行了较全面的运行测试。测试结果表明,该系统基本到达预期目标,具备湘西苗文词性标注技术研究所需要的基本功能。
本文从语料收集处理及词性标记集设计、系统的设计、系统主要功能模块的实现等几个方面阐述了湘西苗文词性标注知识库系统的构建过程,对于面向其他文字的词性标注相关知识库系统的设计和开发能够起到一定的借鉴作用。
参考文献:
[1] Leech G. The state of the art in corpus linguistics[A]. In K. Aijmer & B. Altenberg(eds. ). English CorpusLinguistics: Studies in Honor of Jan Swartvik [C]. London: Longman, 1991, 9-11.
[2] Bosco C,Tamburini F,Bolioli A,et al.Overview of the EVALITA 2016[M]//EVALITA.Evaluation of NLP and Speech Tools for Italian.Accademia University Press,2016:78-84.
[3] Abumalloh R A, Al-Sarhan H M, Ibrahim O, et al. Arabic Part-of-Speech Tagging[J]. J. Soft Comput. Decis. Support Syst, 2016, 3(2): 45-52.
[4] 中文信息处理发展报告(2016), 中国中文信息学会, 北京: 2016.
[5] 谢逸,饶文碧,段鹏飞,等.基于CNN和LSTM混合模型的中文词性标注[J].武汉大学学报(理学版),2017,63(3):246-250.
[6] Wang L L,Chen Z Y,Yang H W.TPOS tagging method based on BiLSTM_CRF model[M]//Communications in Computer and Information Science.Singapore:Springer Singapore,2019:490-503.
[7] 帕麗旦·木合塔尔,吾守尔·斯拉木,买买提阿依甫.基于混合模型的维吾尔文词性标注方法[J].计算机仿真,2019,36(1):268-273.
[8] 刘婉婉,苏依拉,乌尼尔,等.基于门控循环神经网络词性标注的蒙汉机器翻译研究[J].中文信息学报,2018,32(8):68-74.
[9] 周潭,莫礼平,曾虎,等.方块苗文词性标注集的设计[J].智能计算机与应用,2019,9(1):131-134.
[10] Li H C,Mo L P,Zhou K Q.A part-of-speech tagging approach for Chinese-Hmong mixed text[J].IOP Conference Series:Materials Science and Engineering,2020,864:012064.
[11] 赵丽明,刘自齐.湘西方块苗文[J].民族语文,1990(1):44-49.
[12] 魏忠.中国的多种民族文字及文献[M].北京:民族出版社,2004.
【通联编辑:唐一东】
收稿日期:2021-06-25
基金项目:湖南省语委语言文字应用研究专项课题(XYJ2019GB09);湖南省自然科学基金项目(2019JJ40234);湖南省教育厅科学研究重点项目(19A414);吉首大学本科生科研项目(JDX19031)
作者简介:胡美琪(1999—),女,本科生,主要研究方向:自然语言处理;莫礼平(1972—),通信作者,女,硕士,教授,主要研究方向:自然语言处理、智能计算及应用研究;唐琰(1998—),男,本科生,主要研究方向:自然语言处理。
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25
安顺学院学报(2019年2期)2019-07-04
广东蚕业(2019年3期)2019-05-14
湖南工业职业技术学院学报(2016年6期)2016-04-17
语言与翻译(2015年4期)2015-07-18
外语教学理论与实践(2014年4期)2014-06-13
外语学刊(2014年6期)2014-04-18
西南科技大学学报(哲学社会科学版)(2014年5期)2014-02-28
天津大学学报(社会科学版)(2013年2期)2013-03-11
当代修辞学(2011年3期)2011-01-23
