
基于数据融合驱动和DLSTM网络的轴承RUL预测
2021-12-14 01:28段桂英姜洪开
计算机应用与软件 2021年12期
段桂英 姜洪开
1(山东艺术学院公共课教育部 山东 济南 250014)2(西北工业大学航空学院 陕西 西安 710072)
0 引 言
滚动轴承作为转子机械设备的核心元件,被广泛应用于航空航天、工业生产及电力系统,轴承发生故障将会导致巨大的经济损失,甚至造成灾难性后果。因此,对轴承进行可靠的剩余寿命预测能够有针对性地进行维修保养,从而在保证安全的前提下提升设备的使用效率[1-2]。
现有的RUL预测方法可以分为三类[3],即基于模型的方法、数据驱动的方法和混合方法。其中,数据驱动方法与其他两种方法相比更易于实现,也能够更加全面地进行分析。文献[4]描述了一种针对自动变速器离合器基于卡尔曼滤波器(Kalman filter,KF)的RUL预测方法。文献[5]提出了一种使用支持向量回归(SVR)的直接RUL估计方法,该方法避免了估计退化状态或阈值设置故障。文献[6]采用回波状态网络模型,使用时间序列数据对燃料电池进行RUL预测等。但是这些方法通过映射监视信号和RUL值之间的关系可以实现RUL预测,但是没有考虑反映健康状态微小变化的不同时间序列信号的相关性。
循环神经网络(RNN)作为上述问题的一种解决方案,可以跨时间步长从先前处理的序列数据中提取有用的重要信息,并将其集成到当前的单元状态中以对序列数据进行建模[7]。但是训练中梯度消失或爆炸的问题限制了传统RNN的广泛应用。文献[8]创建了一种改进的名为LSTM的RNN结构来缓解此问题,通过引入一组记忆神经元,LSTM在学习鲁棒性和敏感数据方面表现出了卓越的能力。但是该方法仅分析振动信号,而未考虑多传感器数据的融合处理,无法体现数据驱动的全面性,导致预测精度不高,而且由于网络结构的限制,引入深度学习对预测精度提升的效果不佳。
为解决上述问题,本文结合AMEA及网格搜索策略,提出了一种基于多传感器信号融合的DLSTM网络剩余寿命预测模型。
1 长短期记忆网络
与常见的神经网络不同,RNN具有独特的结构,即隐藏层的输出将作为输入反复返回,这意味着隐藏层在一段时间内与其自身具有自连接特性。因此,RNN在处理时序相关数据方面具有很强的能力。其在时间t处的隐藏层的输出描述为:
ht=φ(whx+whhht-1+bh)
(1)
式中:whx和whh分别是隐藏层神经元的输入数据ht和先前输出ht-1的权重系数;bh表示偏差。
然而,由于在模型训练期间反向传播过程中存在梯度消失问题,RNN无法获取数据中的长期依存关系。因此,在LSTM网络结构中,LSTM神经元通过取代传统的RNN隐藏神经元来构建LSTM层。每个LSTM神经元都有三个精心设计的门函数,即遗忘门、输入门和输出门。这种结构确保LSTM神经元具有发现和记忆长期依赖性的能力。
LSTM神经元中的三个门函数为控制信息的输入和删除提供了良好的非线性控制机制。输入门决定了将进入神经元状态的信息,遗忘门决定了神经元状态中需要丢弃的信息,输出门决定从神经元状态导出什么信息。LSTM神经元的计算过程可以用数学公式表示为:
gt=φ(wgx+wghht-1+bg)
(2)
it=σ(wixxt+wihht-1+bi)
(3)
ft=σ(wfxxt+wfhht-1+bf)
(4)
ot=σ(woxxt+wohht-1+bo)
(5)
st=gt⊗it+st-1⊗ft
(6)
ht=φ(st)⊗ot
(7)
式中:wgx、wfx、wix和wox是输入数据xt的权重;wgh、wih、wfh和woh是LSTM神经元先前输出的ht-1的权重;bg、bf、bi和bo表示输入节点、遗忘门、输入门和输出门的偏差;gt、ft、it和ot是输入节点、遗忘门、输入门和输出门的输出;σ(·)和φ(·)表示S型和tanh函数;st和st-1是LSTM神经元在时间t和t-1时的状态;⊗表示逐点乘法。
2 RUL预测模型
深度学习作为人工神经网络的扩展,可以通过多层网络结构来自适应地捕获数据中的潜在特征[9]。从结构的角度来看,DLSTM包含多个隐藏层,这是深度学习的一种形式。本文构建了一个DLSTMN模型,以实现多传感器数据的自动融合和RUL的准确预测。

图1 预测模型结构图
输入数据的输入由输入神经元控制,因此输入神经元的数量等于所选传感器信号的数量。传感器时间序列信号数据分为不同部分,分别用于网络模型训练、验证和测试。输入数据被构造成二维矩阵。矩阵中的行数和列数为k和T,k代表所选传感器个数,T代表采样点的个数。最终将多传感器数据融合到RUL值。
多个LSTM层堆叠在构造的DLSTM模型中,实现了多传感器数据的深度挖掘和融合。不同的LSTM层在空间上相连,数据从上层输出到下一层的神经元,相同的LSTM层与时间有关,LSTM层的先前输出将作为输入循环到该层。每个LSTM层中都包含许多LSTM神经元以捕获传感器数据的长期依赖性。在每一层LSTM神经元之间形成信息交换,实现跨时间的自连接。此外,每个神经元的输出不仅在下一刻循环进入自身,而且还与其他神经元共享。
输出层采用完全连接的密集层,在该层中将LSTM层的输出信号送入其中,最终将多传感器数据融合到RUL值。采用均方误差函数作为机器学习中常用的损失函数,以使预测的RUL和RUL标签之间的误差最小。在测试阶段,将在线传感器数据依次发送到经过训练的DLSTM中,并获取预测的RUL。
3 模型优化
3.1 模型结构
DLSTM模型结构的大小,包括LSTM层数和每个LSTM层的神经元数,需要人为确定。这些是DLSTM模型中两个重要的参数,用于控制网络的体系结构和拓扑。许多文献提出了DLSTM的参数优化方法[10],且取得了较好的效果,但优化过程却极其复杂。由于DLSTM网络结构的复杂性和长的训练过程,DLSTM与这些优化方法相结合必然会对计算资源提出更高的要求。
DLSTM将网格搜索用于网络配置探索,原理简单明了,算法容易实现,计算资源要求低。LSTM层数和各层神经元数的候选构成一个二维网格,并验证网格中各节点参数以选择最佳的网络结构参数。最后,将具有最佳验证预测性能的参数视为最优参数,并用于在线RUL预测中。
3.2 损失函数的优化
损失函数的优化算法将直接影响DLSTM训练的效率和时间,本文DLSTM模型采用AMEA代替传统的随机梯度下降(Stochastic gradient descent,SGD)优化算法,使DLSTM的损失函数最小。在SGD算法中,保持固定的学习速率(Learning rate,LR)来更新所有的权值,这意味着LR在训练中保持不变。AMEA通过分析梯度的一阶矩估计(FME)和二阶矩估计(SME),针对不同的参数设计独立的自适应LR[6]。因此,AMEA具有较高的计算效率,但需要较少的配置资源。用AMEA更新网络参数的过程表示为:
(8)
mt=β1mt-1+(1-β1)gt
(9)
(10)
(11)
(12)
(13)
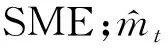
3.3 引入主动丢弃法
通常神经网络的训练更加耗时,因此随着网络层数增加,过拟合成为一个严重的问题[11]。过拟合会导致预测模型在训练数据中表现出色,但在测试数据中表现不佳。为了解决该问题,DLSTM模型采用了主动丢弃法来防止重复捕获相同的特征。
应用于DLSTM模型的信号主动丢弃方法的示意图如图2所示。其中,深色圈是隐藏层中的神经元,它们在DLSTM的训练过程中,根据一定的概率暂时从网络中丢弃。由于丢弃是随机发生的,所以在每个小批量中训练不同的网络。因此,信号丢弃可以有效地缓解DLSTM的数据过拟合问题。需要指出的是,信号丢弃只在训练过程中起作用,在测试过程中被禁用,这意味着所有隐藏的神经元都在测试过程中起作用。本文测试了所有候选遗漏值,将最优值应用到DLSTM中。

图2 主动丢弃法应用于DLSTM模型
4 实 验
4.1 数据集描述
用于评估本文方法的数据集是由CMAPSS提供的NASA涡扇发动机转子轴承数据集,可变地输入不同转速,以模拟转子轴承中的不同故障和退化过程。在实验过程中,转子轴承开始在良好的状态下运行,并出现了一些故障,这些故障会导致性能下降,直到出现事故为止。
CMAPSS提供A组-D组四个数据集。每个数据集都包括训练集和测试集。训练集会保存整个寿命周期的信号,而测试集仅包含多个传感器数据,这些数据在轴承故障和RUL需要预测之前的某个时间终止。训练集和测试集都由一系列循环组成,每个循环包含26列,分别指轴承序号、循环索引、3个操作设置和21个传感器测量值。
由于轴承具有明显的健康退化过程,本文采用了A组和C组两组数据集。A组只有一种故障模式,而C组有两种故障模式。此外,A组和C组都包含100个训练轴承和100个测试轴承。
实验中所有方法都是在Anaconda和Python 3.6上执行的。计算设备是一个具有Intel Core i5- 4460(3.20 GHz)CPU、16 GB RAM的计算机。
4.2 性能评价指标
本文提出的方法采用指标得分(Score)、均方根误差(RMSE)和RUL误差范围三个指标来评估RUL预测性能。
数据创建者提供的指标得分表示为:
(14)

RMSE计算如下:
(15)
Score和RMSE都用来评估预测RUL和实际RUL之间的差异,较小的Score或RMSE值代表较好的预测效果。然而,这两个指标之间存在微妙的差异,如图5所示。可以看出,比起早期的预测,Score对晚期预测的惩罚更大。
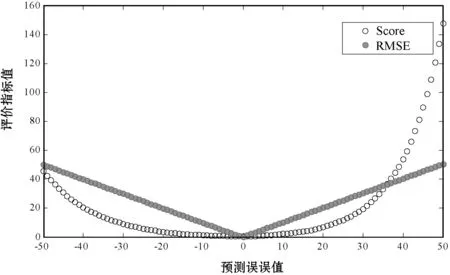
图3 Score和RMSE之间差异的图示
指标RUL误差范围代表所有RUL预测值的误差范围。RUL误差范围越小,预测方法的有效性和稳定性越高。
4.3 多传感器数据预处理
轴承获得的多传感器数据存在较大的随机波动和噪声干扰,可能影响RUL预测的性能。采用指数平滑算法去除噪声,减弱传感器数据的随机波动,其表达式为:
(16)
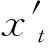
α的大小直接决定了轴承振动传感器数据的平滑效果,从而间接影响RUL预测的精度。图4展示出了与A组中的原始传感器数据相比具有不同α值的传感器2的预处理传感器数据。传感器数据平滑使用了三个不同的α值,分别为0.25、0.5和0.75。可以看出,与原始传感器数据相比,平滑的传感器数据的波动减小,并且平滑的传感器数据能够很好地反映原始传感器数据的趋势。通过一系列对比实验发现,α值为0.25的预处理传感器数据波动较小,这意味着数据平滑效果更好。因此,本文实验将α设置为0.25。
综上所述,从21个传感器获取的信号包含在CMAPSS数据集中。然而,并不是所有的传感器都能很好地表示退化过程。为了得到准确的RUL预测,需要选择传感器。合理的传感器信号与健康退化过程具有良好的相关性,表现出单调递增或递减的趋势[12]。因此,通过分析信号数据的单调性(Mon)和相关性(Corr)来实现传感器的选择。
为了测量轴承数据的趋势,首先提取轴承数据的平均趋势特征:
(17)
式中:f(t)是时间t处传感器信号的趋势值;fU(t)和fL(t)分别表示传感器信号的上、下包络。
对传感器信号的Mon和Corr进行分析,分别定义如下:
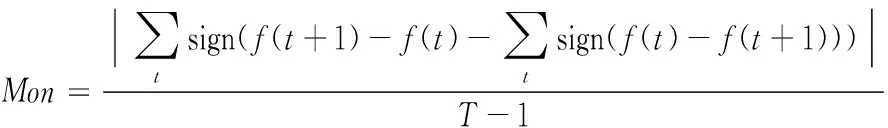
(18)
式中:T表示信号样本的数量。
接下来,通过Mon和Corr的组合找到一个复合选择标准(CSC),其表示为:
(19)
式中:Ω表示所有候选传感器信号;ωi表示加权系数。由式(19)可以看出,CSC与Mon和Corr呈线性正相关,即CSC指数越高,传感器越能反映变化趋势。为了选择更好的特征,将阈值设置为0.75。
图5展示了A组和C组中传感器的分类CSC值,从图5(a)可以看出,A组中的21个传感器(S1-S21)的CSC被排序。S2、S3、S4、S7、S8、S11、S12、S13、S15、S17、S20和S21的CSC大于阈值,因此它们被选中。在图5(b)中,选择传感器S4、S7、S11、S12、S15、S20和S21的数据来构建C组中的训练数据集。

图5 传感器的CSC排序值
RUL标签值对预测性能有显著影响,RUL标签被假定在初始阶段是恒定的,然后线性下降。根据文献[13],早期的采样点用一个恒定的RUL值进行标记,综合考虑将其设置为125。
5 结果分析
5.1 案例一
对数据集A组进行分析,以验证本文方法。首先,在多传感器数据预处理完成后,利用100个滚动轴承的传感器数据建立训练数据集,其中随机选取90个滚动轴承进行DLSTM模型训练,其余10个轴承验证模型的有效性。其次,考虑数据集中监测信号的特性,建立了用于RUL预测的DLSTM模型,并对其参数进行了优化确定。利用网格搜索方法对模型进行训练,以探索最优的DLSTM结构。由LSTM层数和各层形式的神经元数构成二维网格,并将网格中的每个节点参数验证为候选参数。考虑到时间限制和计算复杂性,将LSTM层数设置为1到6,并且每个LSTM层中的神经元数设置为50至300。该网格中每两个参数组合用于构造一个新的DLSTM。采用10个验证引擎对每个模型结构进行验证,并利用RMSE对模型训练结果进行比较。图6展示了不同层数和神经元数的DLSTM的训练结果。可以看出,每个模型结构具有不同的性能,DLSTM模型具有5个LSTM层,每个LSTM层有100个神经元,达到了最优的性能。因此,在这种情况下,DLSTM模型由5个LSTM层和100个神经元构成。表1记录了部分参数组合情况下DLSTM的训练结果,其选择了6个参数组合,取得了较好的训练效果。通过对参数和训练时间的比较,发现DLSTM的训练时间随着LSTM层数和DLSTM层数的增加而逐渐延长。

图6 不同层数和神经元数的DLSTM的RMSE分布
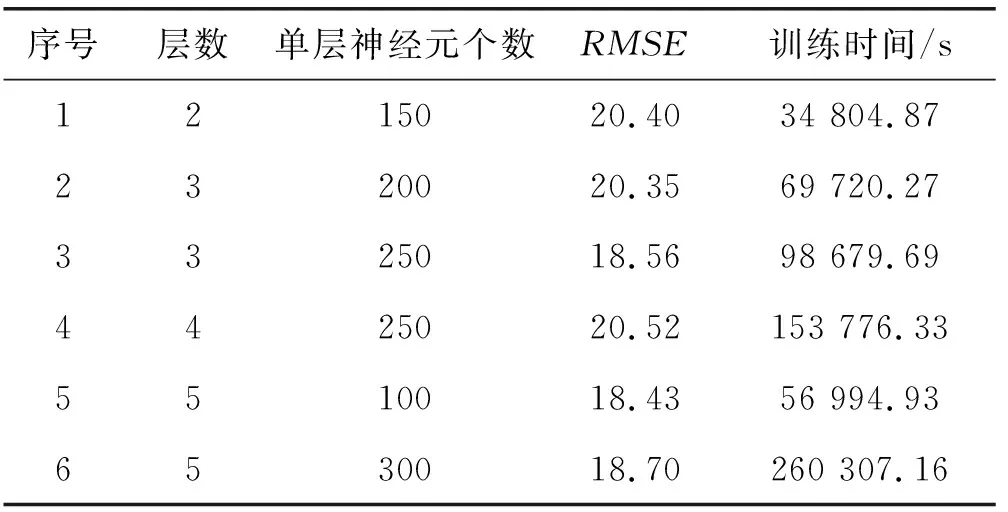
表1 部分参数组合情况下DLSTM的训练结果
为了减少DLSTM模型的数据过度拟合,采用了丢弃法。本文尝试用不同的丢弃率来确定构造的DLSTM的最佳值。图7展示了具有不同丢弃值的构造的DLSTM的训练结果,可以看出,当丢弃率为0.7时,DLSTM模型具有最小的RMSE值并获得最佳的训练性能。因此为了获得良好的DLSTM训练效果,本文将丢弃率设置为0.7。

图7 用不同的丢弃率训练DLSTM
为了使损失函数最小化,本文将不同的优化算法与AMEA进行了比较,包括SGD、均方根(RMSprop)、自适应梯度(Adagrad)和Adadelta。图8展示了使用不同优化算法训练DLSTM,可以看出,这四个优化器都可以帮助DLSTM在经过1 000个阶段后实现网络优化。尽管如此,与其他算法相比,DLSTM中的AMEA具有更高的效率和更好的收敛性。因此,AMEA在构造的DLSTM中用作损失函数优化器。
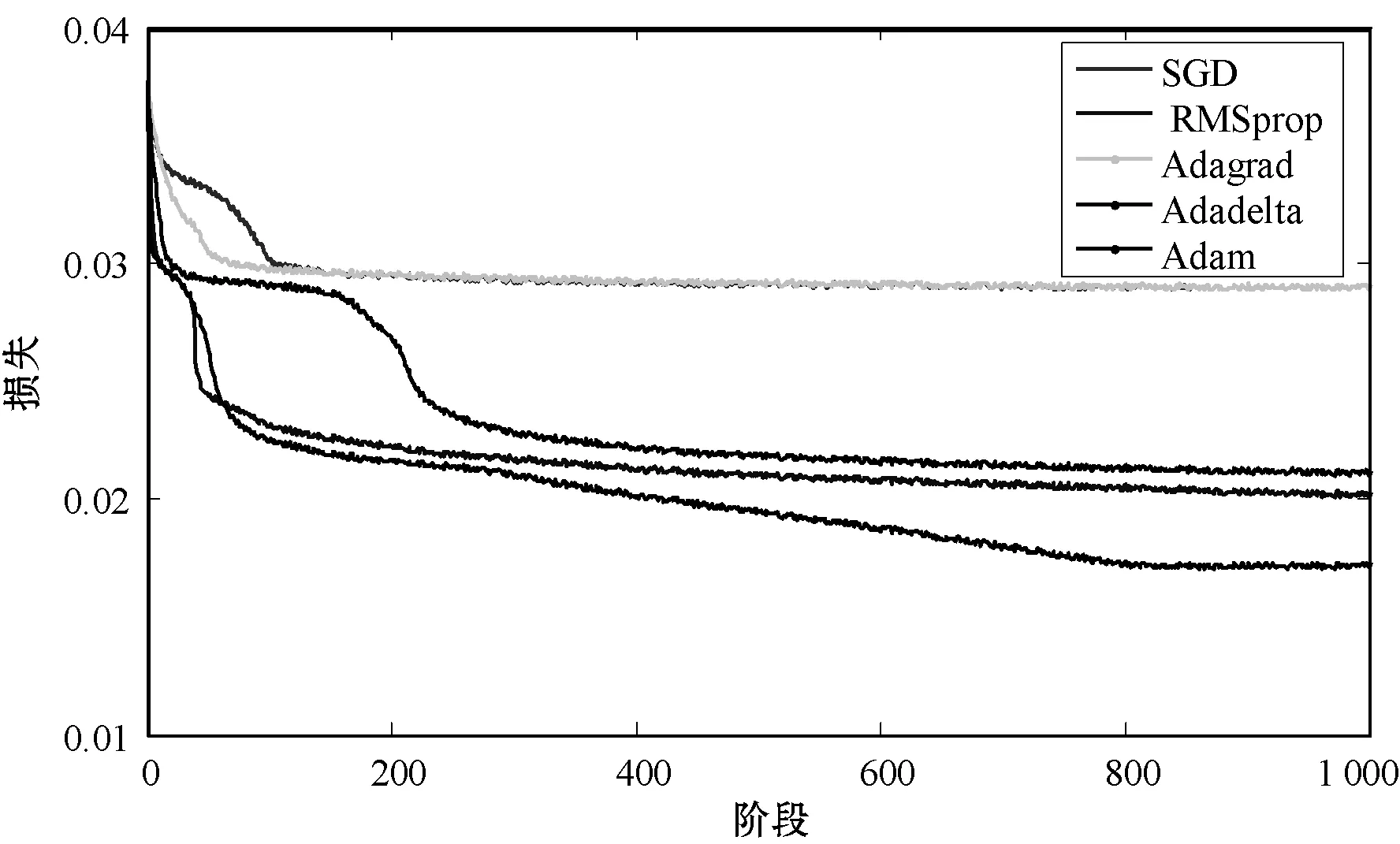
图8 用不同的优化器训练DLSTM
最后,建立了一个包含5层LSTM和100个神经元的DLSTM模型用于轴承RUL的预测。将丢弃值设为0.7,损失函数优化算法采用AMEA。表2显示了构建DLSTM模型的其他参数。

表2 本文DLSTM模型的其他参数
模型训练完成后,利用10个轴承对训练后的DLSTM进行性能验证。图9比较了10个轴承的预测RUL和真实RUL以进行验证,其中虚线代表预测曲线,实线表示真实剩余寿命。可以看出,这些预测能够很好地反映出10个轴承真实RUL的变化。
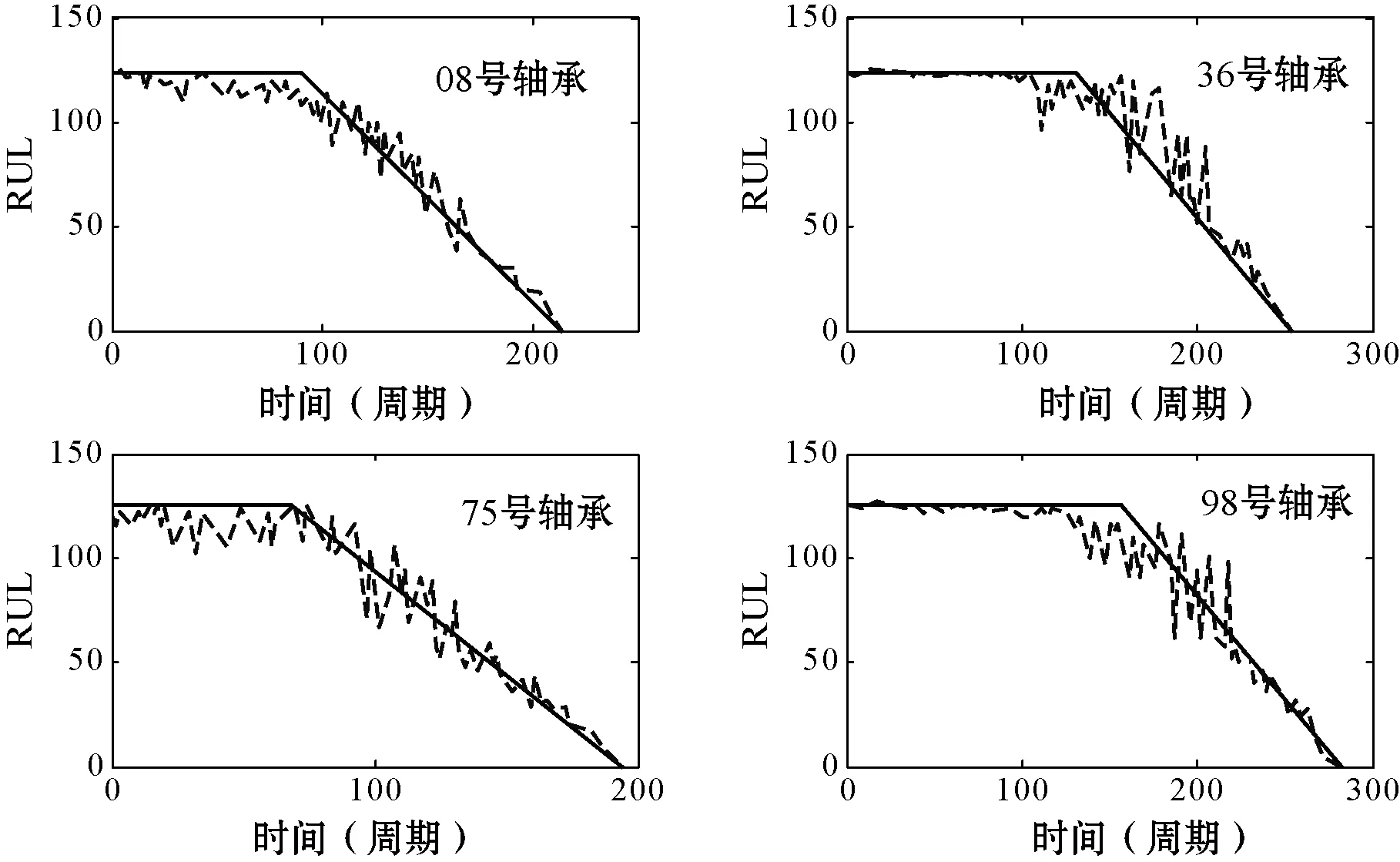
图9 4个轴承的验证预测结果
在线过程中,将测试轴承的监测信号依次输入DLSTM,得到预测的RUL。图10显示了A组中100个轴承的实际RUL与预测RUL。结果表明,两者非常吻合。
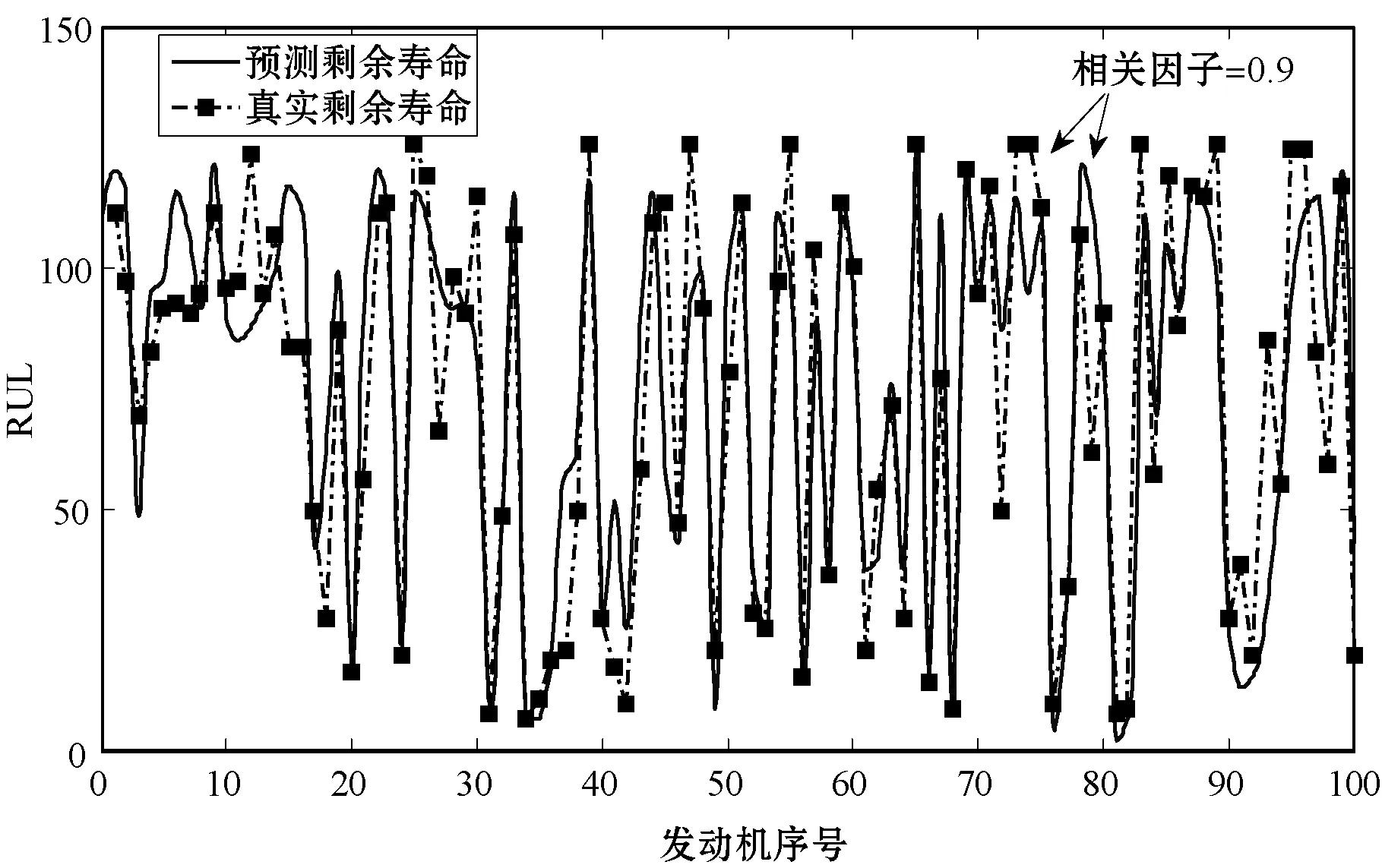
图10 100个轴承的实际RUL与预测RUL
本文使用了一些最新的研究成果与DLSTM进行了比较,包括MLP[14]、SVR[15]、相关向量回归(RVR)[6]、深卷积神经网络(DCNN)[9]、带模糊聚类的ELM(ELM-FC)[16]、支持向量机(SVM)[17]、具有KF的回波状态网络(ESN-KF)[18]和基于相似性的方法(SBA)[19]。表3展示了各方法的性能比较,其中NA表示信息不可用。表4比较了不同方法的关键参数,它们的得分Score、RMSE与RUL误差范围有关。可以看出,在这种RUL预测问题中,许多方法都显示了各自的优势,包括DCNN、ELM和SBA等。与其他方法相比,DLSTM具有最小的Score、RMSE和RUL误差范围。这意味着所提出的DLSTM具有最好的预测性能,验证了本文的DLSTM对该轴承预测问题的有效性。
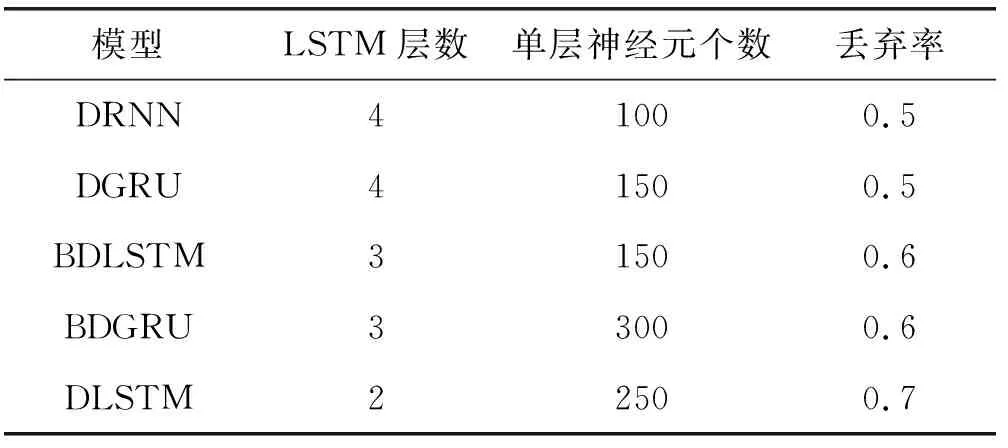
表4 所有方法的关键参数
5.2 案例二
由于包含了更多的故障模式,使用C组数据集进行准确的RUL预测比A组数据集困难得多。本文利用C组数据集比较了DLSTM和其他RNN方法的RUL预测性能,包括深度递归神经网络(DRNN)、深门控递归单元(DGRU)、双向GRU(BDGRU)和双向LSTM(BDLSTM)。所有的方法都采用了网格搜索和丢弃的方法来获得最优模型,关键参数见表4。图11展示了五个模型的RUL误差的箱形图。五个模型100个轴承的RUL误差集中在0附近,与其他模型相比,DLSTM的RUL预测误差更为集中,说明DLSTM预测稳定性更好。

图11 五个模型的RUL误差的箱形图
表5根据三个评估指标和时间消耗比较了五个模型的预测结果,可以看出,所提出的DLSTM在Score、RMSE和RUL误差范围方面始终优于其他RNN模型。BDLSTM和BDGRU由于其独特的双向网络结构,能够更好地处理时间序列数据,因此,BDLSTM和BDGRU的评估指标略差于最优结果。由于DRNN结构最简单,与其他进化的RNN结构相比,DRNN的预测结果相对较差。在时间消耗分析方面,DLSTM与其他模型相比没有明显的优势,这是因为DLSTM具有相对复杂的网络结构。所有模型的在线平均计算时间均符合工业要求,因此DLSTM可以应用于工业系统的实际设备中。

表5 C组数据集上五个模型的性能比较
6 结 语
本文通过建立的DLSTM模型,提出了一种多传感器数据融合驱动的滚动轴承RUL预测方法,并通过实验数据进行了验证,得出如下结论:
(1) DLSTM模型能够通过DL结构捕获传感器时间序列信号之间隐藏的长期依赖性,从而充分地利用传感器数据,提升预测精度。(2) 多传感器数据融合驱动与建立的DLSTM相结合可以有效地提升剩余寿命的预测精度,并且具备良好的效率和收敛性。(3) DLSTM模型在线平均计算时间相对其他预测方法并未体现明显的优势,但是能够符合工业要求,验证了DLSTM可以应用于工业系统的实际设备中。(4) 该方法具有多传感器数据融合能力,方法本身具备一般性,可广泛应用于其他领域的不同类型设备。
猜你喜欢
小学科学(2022年8期)2022-09-07
舰船科学技术(2021年12期)2021-03-29
汽车维修与保养(2021年8期)2021-02-16
电子产品世界(2021年8期)2021-01-16
中国电气工程学报(2020年3期)2020-07-31
汽车与驾驶维修(维修版)(2019年7期)2019-09-10
时代英语·高一(2019年1期)2019-03-13
中国计算机报(2019年49期)2019-02-07
科技风(2018年23期)2018-05-14
中国新闻周刊(2017年36期)2017-10-21
