
短边顶点回归网络:新型自然场景文本检测器
2021-12-13 02:04游洋彪石繁槐
哈尔滨工业大学学报 2021年12期
游洋彪,石繁槐
(同济大学 电子与信息工程学院,上海 201804)
近年来,自然场景图像中的文本检测成为了计算机视觉领域的一个研究热点。自然场景图像文本检测在图像检索、定位导航、盲人辅助、数据录入等领域具有重要的实用价值。自然场景图像背景千变万化,并且自然场景图像文本具有大小和长宽比变化剧烈、多方向等特点;此外,与一般目标检测不同的是,文本目标框可能使用水平矩形、四边形、旋转矩形,甚至是多边形等形式进行精确表达,所以自然场景图像文本检测一直是一个难点问题。
通用目标检测(generic object detection)[1],定位图像上预先定义类别的目标实例的位置,检测结果通常以外接矩形框的形式呈现,不同于专用目标检测只适用于一种或一些类别,通用目标检测适用于广泛的类别,典型方法有Faster R-CNN[2]、SSD[3]等。随着深度学习技术的迅速发展,通用目标检测性能得到了显著的提升。很多学者在通用目标检测方法的基础上提出了许多自然场景文本检测方法。这些方法可以大致分为两类:间接回归方法与直接回归方法。间接回归方法,通常借鉴Faster R-CNN[2]、SSD[3]等目标检测方法,预先设定一些锚(anchor)或先验框(default box),利用卷积神经网络判定它们是否与文本区域高度重叠并调整它们的大小和位置以准确定位文本。然而自然场景中的文本方向多变,大小、长宽比变化剧烈,为了使预设的锚或先验框能与文本区域高度重叠,很多方法增加了多种方向、多种大小及多种长宽比的预设框,但这无疑增加了方法的复杂度与计算量。
为适应文本的特性,Liao等[4]、Zhong等[5]分别在Faster R-CNN、SSD的基础上增加了不同尺寸与长宽比的预设框。Ma等[6]、Liu等[7]为检测多方向的文本设置了多方向的预设框。为了能够输出四边形的检测结果,Liu等[7]、Liao等[8]直接预测预设框与文本边界四边形4个顶点的坐标差;Jiang等[9]通过预测两个顶点坐标与一条边长得到旋转矩形的检测结果;Zhu等[10]通过预测多个文本边界上的点得到多边形的检测结果。
直接回归方法不需要预设框,相比于间接回归方法,它更加灵活简便。直接回归方法借鉴了DenseBox[11]的思想,这类方法通常采用全卷积网络[12](fully convolutional network,FCN)的架构,在分割出文本区域中的候选点的同时在每个点处预测对应的文本区域边界。为了得到四边形的检测结果,He等[13]在分割出文本区域中像素点的同时预测该点与四边形边界顶点的坐标偏差。为了降低复杂度,Zhou等[14]预测文本区域中的点到文本外接旋转矩形4条边的距离与旋转矩形的角度。Xue等[15]则在此基础上还分割了文本的边界区域以助于区分文本实例。
上述基于回归的文本检测方法或是通过调整预设框得到文本的外接四边形,或是在每个点处直接预测文本的外接四边形,都是直接预测文本的整个边界框。这些方法能检测到目标尺寸与网络的感受野大小成正相关,当检测更长的文本目标时,网络需要更大的感受野。在面对长文本时,由于感受野大小有限,并且相应感受野内背景干扰可能更多,这些直接预测整个文本边界的方法难以得到理想的结果。
针对直接预测整个文本边界的方法在检测长文本时的缺陷,本文设计了一种短边顶点回归网络,该网络不再直接预测文本区域的所有边界。具体来说,本文方法在直接回归方法的基础上,分割出文本的两条短边附近的区域以及中间区域。不同于其他直接回归方法中文本区域中的点需要预测文本整个边界框,本方法中,文本边界框顶点由短边附近区域中的点来预测,并且一条短边区域内的点只预测其附近短边的两个顶点,而不需预测另外一条更远短边的顶点。在检测长文本时,相应感受野内背景干扰相对更少,同时对感受野大小的要求更低,所以检测结果更为准确。为了将预测的两组短边顶点结合,本文设计了一种新的后处理方法,利用中间区域与两短边区域相邻或两短边区域直接相邻的特点将文本的两个短边区域组合,两组预测的短边顶点随之结合,便能得到精确完整的文本检测结果。本文所提方法在多个自然场景文本检测数据集上均取得了不错的效果,结果超过了目前绝大部分方法,并且本方法更快速高效。
1 短边顶点回归网络的文本检测方法
图1为本文方法的原理流程图,本方法采用了全卷积与多层特征融合的网络架构。图像输入网络后,网络输出3种像素级分类结果,即文本中间区域像素、文本左短边区域像素、文本右短边区域像素。文本短边区域是指文本短边边界附近的区域。如图1的区域分割结果所示,其中蓝色、绿色、红色区域分别为文本中间区域、左短边区域与右短边区域。在分类短边区域像素的同时,网络还在该点处预测附近一条短边两个顶点的坐标。最后通过后处理,本方法将左短边顶点与右短边顶点的预测结果结合起来,得到最终的检测结果。

图1 基于短边顶点回归网络的文本检测方法流程
1.1 网络结构
本方法的网络结构可以大致分为3个部分:特征提取、特征融合以及分类回归。特征提取部分使用Resnet 50[16]的框架,去除Resnet 50后面的全连接层,图1中绿色模块为Resnet 50特征提取部分。相比于经典的VGG16/19[17],Resnet 50参数量更少,计算存储花销更小,而且Resnet 50使用了残差结构,能够有效缓解训练时发生梯度消失的情况。
自然场景图像中文本具有尺度变化剧烈的特点,特征提取网络越深,提取到的特征语义范围越广,越有利于大尺度文本的检测,而检测小的文本需要靠浅层局部的特征。为了能够检测不同大小的文本,本方法参考U-Net[18]的架构将Resnet 50提取到的多层特征进行融合。具体来说,高层的特征首先进行上采样,与低一层的特征的长宽维度保持一致,然后沿通道方向将上采样特征与低一层特征进行连接,最后使用一个1×1与一个3×3的卷积操作将特征进行融合。融合后的特征继续融合更低层特征,直至融合的特征长宽为原图像的1/4。
对于最小外接矩形长宽比接近于1的文本区域,它的中间区域、左短边区域、右短边区域会有部分重叠。所以在网络输出的结果中,同一个像素可以同时属于中间区域、左短边区域、右短边区域。在最后分类时,中间区域、左短边区域、右短边区域均与背景进行二分类,这样能够避免类间的竞争。具体来说,在最后融合的特征上分别使用一个1×1的卷积操作与一个sigmoid非线性函数来预测每个像素点属于中间区域、左短边区域、右短边区域的概率。
1.2 训练样本标签生成
短边顶点回归网络的目标之一在于分割文本的中间区域、左短边区域及右短边区域。文本短边区域是文本短边边界附近的部分区域,在确定文本左、右短边区域前,首先需要规定文本的左短边及右短边。由于文本目标大多使用四边形进行标注,而四边形的两条对边不一定为最短的两条边,所以在此通过寻找四边形最小包围矩形的左短边及右短边来确定文本边界四边形的对应短边。
如图2(a)所示,黄色四边形是文本区域原始的标注,红色的矩形是该四边形的最小包围矩形R。矩形R顺时针旋转直至长边与水平轴平行,假设此时底部长边为w,转过的角度为矩形R的倾角θ。当θ≤45°时,R旋转后,位于w右侧的短边对应的是R的右短边,位于w左侧的短边为R的左短边,例如图2(b)中的R1、R2、R3;当θ>45°时,R旋转后,位于w左侧的短边对应的是R的右短边,位于w右侧的短边为R的左短边,例如图2(b)中的R4、R5、R6、R7、R8。图2(b)中矩形R绿色短边为左短边,红色短边为右短边。文本四边形的左、右短边与其最小包围矩形R的左、右短边一一对应。
在确定文本的左短边与右短边后,再精确定义文本的中间区域、左短边区域、右短边区域。首先定义四边形Q={q0,q1,q2,q3},其顶点qi(i=0,1,2,3)的参考长度为
li=min(hi,(i+1)mod4,h(i+3)mod4,i)
(1)


图2 左短边、中间、右短边区域标签生成
1.3 损失函数
本方法是基于直接回归的文本检测方法,所以设计损失函数时参考了其他同类的方法[13-15]。本方法损失函数为:
L=Lcls+Lreg
(2)
Lcls=α1Lm_cls+Ll_cls+Lr_cls
(3)
Lreg=Ll_reg+Lr_reg
(4)
式中:L为最后总损失;Lcls为3类区域的分类损失和;Lreg为短边区域顶点回归损失和;Lm_cls、Ll_cls、Lr_cls分别为中间区域、左短边区域及右短边区域的像素分类损失;Ll_reg为左短边顶点回归损失;Lr_reg为右短边顶点回归损失。由于中间区域起着确定文本实例的作用,相对更加重要,实验中其分类损失权重α1设置为4。
在自然场景图像中,文本区域往往只占很小一部分,如果分类损失函数使用交叉熵类型的损失函数,很可能由于正负样本不平衡,导致最后分类结果倾向于背景。本方法采用D(dice coefficient)函数[19]作为分类的损失函数,分类损失为:
Lcls=α1D(Pm,Gm)+D(Pl,Gl)+D(Pr,Gr)
(5)
(6)
式中:Pm、Pl、Pr分别为中间区域、左短边区域、右短边区域的分类得分预测值;Gm、Gl、Gr为分类得分真实值;Px,y、Gx,y分别为点(x,y)分类得分的预测值与真实值。

(7)
(8)

(9)
(10)
(11)

1.4 后处理
从网络的输出中不能直接得到文本区域的检测结果,还需要进行后处理才能得到完整的结果。对于点(x,y),用Sm、Sl、Sr分别表示该点属于文本中间区域、左短边区域、右短边区域的分类得分。Tm、Tl、Tr分别表示中间区域、左短边区域、右短边区域的分类阈值。当Sm>Tm,Sl
整个后处理的流程如图3(a)所示,具体如下:
1)寻找有效区域。遍历所有的像素点,找到所有的有效中间区域、有效左短边区域及有效右短边区域,分别如图3(c)中蓝色、绿色、红色区域所示。同时记录下各有效区域的相邻区域。当某个有效区域的点与其他有效区域的点相邻或重叠时,则这两个有效区域相邻,如图3(d)所示。
2)确定文本实例及其边界顶点。遍历所有的有效中间区域,当该有效中间区域相邻的有效左短边区域、有效右短边区域数目均不小于1时,则3种区域共同构成一个文本实例。若相邻的有效短边区域数大于1,只选最大的有效短边区域。遍历所有的有效左短边区域,当该有效左短边区域相邻的有效中间区域数为0,相邻的有效右短边区域数大于0时,则两种短边区域同样构成一个文本实例。在确定文本实例后,综合计算左、右短边顶点坐标,计算方式为
(12)
式中:xi为由单个有效短边区域点预测的短边顶点坐标;si为该有效短边区域点的短边区域分类得分;n为该短边区域有效点数;x为最后综合计算的短边顶点坐标结果。
3)去除重复。当同一个连通区域内有多个重叠的检测结果,去除面积较小的。

图3 后处理流程图及中间结果示例
2 实验比较与分析
为了验证本文方法的效果,本文将在常用的3个公开的自然场景文本检测数据集及一个长文本数据集上进行测试比较。
2.1 数据集与评价指标
1)长文本数据集。根据主观经验,当一个文本实例长边与短边之比大于7时,认为该文本实例为长文本。从MLT数据集[20]中选取742张含有长文本实例的图片作为长文本数据集。该数据集的文本实例均为英文。该数据集均为测试集。
2)MSRA-TD 500[21]。MSRA-TD 500包含500张图片,其中训练集有300张,测试集有200张。该数据集包含中文与英文两种类型文本,标注的目标为文本行,标注的类型为旋转矩形。该数据集中的文本具有大小变化剧烈、长宽比变化剧烈、多方向的特点。该数据集中含长文本的图像占40%,长文本实例占总文本实例的27.3%。
3)ICDAR 2015[22]。该数据集来自于ICDAR 2015鲁棒阅读竞赛。该数据集包含1 500张图片,训练集有1 000张,剩余的500张为测试集。该数据集包含的文本为英文,文本实例标注是英文单词的边界四边形。与MSRA-TD 500相比,该数据集的文本同样具有多方向的特点,但大小、长宽比变化相对较小。该数据集中长文本实例只占1.5%。
4)ICDAR 2013[23]。该数据集一共有462张图片,训练集有229张,测试集有233张。该数据集的文本为英文,对每一个词进行标注,标注类型为轴向矩形。其中长文本实例占6%。
当一个文本实例的检测结果与真实目标交占比大于0.5时,该检测结果被认为是正确的检测结果,否则为一个错误的检测结果。文本检测的评价指标有3个,召回率(r,recall),准确率(p,precision),综合得分(f,f-score),其计算方式为:
(13)
(14)
(15)
式中:|TP|为正确的检测结果数目;|GT|为真实的文本实例数目;|DT|为检测结果数。
2.2 实验实施细节
由于各个数据集训练集规模都较小,本方法参考了多种文本检测方法[6,8-9,13-14,24-28]通过加入其他数据与仿射变换的方式增大训练数据量,提高模型的泛化能力。HUST-TR 400数据集是使用文本行标注,与方法[6,13-14,25-27]一样,将该数据集加入到MSRA-TD 500训练集中。参考方法[8-9,13-14,24-28],在ICDAR 2013训练集中加入其他训练样本,将部分MLT数据集加入到ICDAR 2013训练集中。本方法使用缩放、旋转、随机截取3种方式进行数据扩充。对于ICDAR 2013与ICDAR 2015训练集,在保持长宽比不变的条件下,图片长边被随机缩放到[640,2 560]之间。然后在[-10°,10°]之间随机旋转图像。最后随机截取512×512大小的图像块作为训练样本。对于MSRA-TD 500数据集,图片长边被随机缩放到为原始长度的[0.5,2.0]倍,最后随机截取1 024×512的图像块作为训练样本。
本方法使用Adam[29]作为网络训练优化器,学习率设置为0.000 1。使用多步调整为学习率调整策略,每经过10 000次迭代,学习率衰减为原来的0.94倍。使用在ImageNet[30]上预训练的Resnet 50模型初始化本网络中特征提取部分的模型参数,其余新加入层的参数使用符合均值为0,方差为0.01的高斯分布的随机数进行初始化。
在测试时,将3类区域的分类阈值均设置为0.9。实验的硬件环境是Intel Core 7700 CPU,16 GB RAM,Nvidia GTX 1080显卡,操作系统为Ubuntu 16.04。
2.3 结果及分析
表1为各方法在长文本数据集上测试结果。表中各方法均是在ICDAR 2015训练集上进行训练,在长文本数据集上进行测试。由于训练集与测试集存在一定差异,所以总体指标数据均不高。但是本方法在准确率与召回率均高于其他方法,综合得分至少高于其他方法5%。这充分表明了本方法在长文本检测方面的优势。
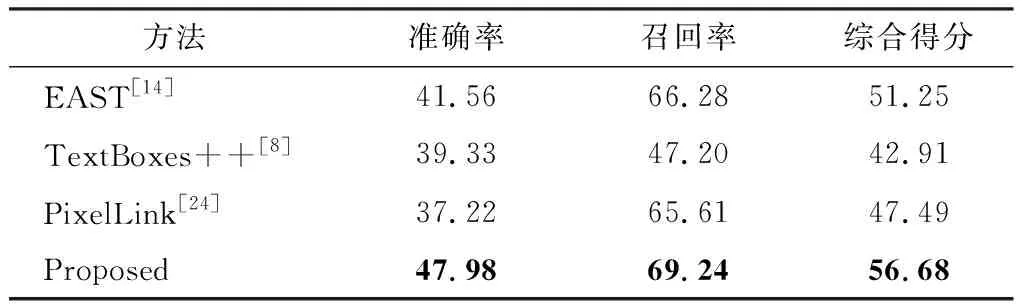
表1 各方法在长文本数据集中测试结果比较
图4(a)、(b)分别是一种间接回归方法TextBox++[8]与一种直接回归方法EAST[14]检测一个较长文本的效果示例。图4(a)中品红色的虚线框为预设框,黄色框为最后检测结果,TextBox++[8]只能检测到长文本的一部分。图4(b)中品红色的四边形是EAST[14]在文本区域中右侧某像素点处预测的检测结果。该点距离文本区域的左侧边界较远,由于该点处的感受野不足导致其预测结果中左侧两个顶点的定位精度非常差,而该点距离右侧边界较近,右侧边界定位较为准确。
图4(c)为本文方法检测长文本结果,其中黄色框为最后检测结果,绿色、红色及蓝色区域分别为文本左短边区域、右短边区域及文本中间区域,左短边区域内像素点只预测文本左短边的两个顶点,右短边区域内的点只预测右短边的两个顶点。与其他两种方法比较,在预测文本边界框顶点时,本文方法只需要关注文本短边附近一小块区域,而不用关注整个文本区域,对网络的感受野要求较低。所以在检测长文本时,本文方法检测精度要明显优于预测整个文本边界的方法。

图4 长文本测试结果比较示例
表2为各方法在MSRA-TD 500数据集上测试结果,其中其他方法的结果来自各自的文献。本方法在MSRA-TD 500测试集上分别使用了单尺度与多尺度图像进行测试,单尺度图像长宽被缩放为原图像的0.6倍,多尺度图像分别被缩放为原来的0.25、0.50、1.00倍。表2中一些方法的准确率高于本方法的原因在于它们牺牲了一定的召回率。本方法最高综合得分为82.66%,高于文献[27]中的1%。MSRA-TD 500数据集检测目标是文本行,其中含有许多长文本。表2的结果再次表明了本方法在长文本检测方面的有效性。

表2 各方法在MSRA-TD 500数据集中测试结果比较
表3所示为各方法在ICDAR 2015数据集上的测试结果比较,其中其他方法的结果来自各自的文献。本方法测试图像大小为1 728×972。从表3数据可以看到,虽然文献[27]准确率高于本方法,但其召回率较低,所以综合性能落后于本方法。与综合得分为第2的方法RRD[26]相比,本方法的综合得分为85.44%,高于其1.6%。

表3 各方法在ICDAR 2015数据集中测试结果比较
表4所示为多种方法在ICDAR 2013数据集上的测试结果,其中其他方法的结果来自各自的文献。本方法在测试之前,将一些过大的图像缩小为原来的0.5倍。本方法单尺度测试图像大小基本为原图像大小。而多尺度测试时,对于较小的图像,所使用的尺度为0.5、1.0、2.0,对于较大的图像,所使用的尺度为0.25、0.50、1.00。不同于表4中一些方法,本方法能在获得较高准确率的同时,获得高召回率,所以本方法综合得分能达到90.1%,超过了表4中其他所有方法。

表4 各方法在ICDAR 2013数据集中测试结果比较
ICDAR 2015数据集、ICDAR 2013数据集的检测目标为词,长文本实例数目不多。相比于文本行,词相对较短,而本方法在这两个数据集上的效果依然超过了目前绝大部分方法。原因在于:1)词通常是以多个密集出现,短边区域能够将密集的文本实例分离开,缩小的中间区域能防止相邻的文本实例误连接;2)不再直接预测整个文本边界,短边区域内的像素点只预测与之邻近的短边的顶点,这样的任务相对更简单,所以能更精准地预测文本边界顶点。
图5为本方法在各个数据集上的单尺度测试的一些结果样例。1~4行分别为长文本数据集、MSRA-TD 500数据集、ICDAR 2015、ICDAR 2013数据集测试样例结果。

图5 本方法的测试结果样例
2.4 速度比较
表5所示为各方法运行速度测试结果。基本上所有基于深度学习的检测方法测试过程都可分为两阶段,网络前向推理阶段与后处理阶段,其中网络前向推理阶段占大部分时间开销,测试图像的大小对速度有直接的影响。各方法测试时,图像大小与实验设备平台不一样。

表5 各方法速度比较
表5列出了每种方法测试的图像大小与使用的GPU。在测试图像大小相近的条件下,EAST[14]只比本方法稍快一点,然而其测试所用GPU设备性能要大大强于本方法。本方法能够如此快速,原因在于:1)本方法网络为单阶段的全卷积网络;2)网络输出结果边长为原图的1/4,这不仅减少了特征融合部分的卷积运算量,还降低了后处理的运算量。
3 结 论
1)针对长文本难以有效检测的问题,本文提出了一种全新的短边顶点回归网络。本方法分割出文本的中间区域、左短边区域、右短边区域,左、右短边区域的点预测各自短边的顶点,再利用区域的相邻关系将两种短边区域连接组合起来,便可得到精确完整的文本检测结果。
2)在长文本数据集,MSRA-TD 500,ICDAR 2015及ICDAR 2013文本检测数据集上的实验测试结果表明本方法高速有效。
3)本方法目前主要适用于直线文本,在未来的工作中,将研究如何改善本方法使其具有更强的泛化能力。
猜你喜欢
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
成都信息工程大学学报(2021年3期)2021-11-22
中学生数理化(高中版.高考理化)(2021年5期)2021-07-16
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
意林(2011年10期)2011-05-14
中学生数理化·高一版(2009年6期)2009-08-31
岁月(2009年3期)2009-04-10
