
基于集成学习的凝汽器真空度预测
2021-12-12 11:32:24杨子江
山东电力技术 2021年11期
路 宽,翟 勇,李 军,高 嵩,杨子江
(1.国网山东省电力公司电力科学研究院,山东 济南 250003;2.山东鲁能软件技术有限公司,山东 济南 250001;3.山东科技大学电气与自动化工程学院,山东 青岛 266590)
0 引言
凝汽器作为火电机组热力循环的冷源,将低压缸的排汽凝结成为凝结水,通过这种方式使凝汽器内维持一定的真空度,保证汽轮机出力[1-2]。因此,其性能将直接影响机组的安全运行以及热经济性。此外,凝汽器真空系统还影响机组运行的安全。为了提前预判火电厂凝汽器真空度的稳定性,确保机组在经济的区间内安全运行,必须对真空度进行预测,并时掌握机组真空的真实状态。
在凝汽器真空预测方面,权学森[3]采用K-means聚类算法将辅机设备相关运行参数划分成相似的工况簇建立预测模型,进行相关设备的运行状态分析;余昶[4]通过对比3种模型后发现,组合灰色预测模型和BP 神经网络的模型得到了较好的预测结果;李建强等[5]应用粒子群算法(Particle Swarm Optimization,PSO)与支持向量机(Support Vector Machine,SVM)相结合的算法建立了凝汽器真空预测模型,使模型具有一定的有效性和泛化性;葛晓霞等[6]提出改进的果蝇优化算法(Improved Fruit Fly Optimization Algorithm,IFOA)优化SVM 的方法来建立凝汽器真空预测模型,使算法在迭代后期具有较强的局部寻优能力;葛晓霞等[7]提出了基于果蝇优化的广义回归网络(Fly Optimization Algorithm based Generalized Regression Neural Network,FOAGRNN)构建凝汽器真空预测模型,并且为了简化网络模型,通过计算平均影响值(Mean Impact Value,MIV)筛选出对凝汽器真空影响较为重要的变量;夏琳琳等[8]借助核主成分分析算法(Kernel Principal Component Analysis,KPCA)构造了BP 网络、径向基RBF(Radial Basis Function,RBF)和Elman 网络的软测量模型,实现了基于Dempster 组合证据的凝汽器真空度多网络融合预测;初广宇[9]分析了机组正常运行期间与凝汽器真空的关系,加深了对真空预测业务的理解;王雷[10]提出了采用SVM 时间序列预测法来预测凝汽器清洁系数,取得了较好的预测精度和泛化能力;王建国[11]以聚类法的RBF 网络为主,采用PSO 算法寻找RBF 模型中的基宽和输出层权值,建立了凝汽器真空软测量模型,证明了模型有效性。上述研究多采用预测算法和参数优化算法相结合的方式进行建模,部分采用了多模型组合的方法,在一定程度上提高了预测的泛化能力。但是一方面,已有的研究没有把外部环境气象条件作为影响因素纳入建模过程中,从而使模型无法利用天气预报信息达到真空预判的效果;另一方面,建模过程中没有引入集成学习,使模型在复杂工况条件下的预测泛化能力提升受限;最后,上述研究由于采样样本较少,缺少对大数据场景下的数据清洗和异常数据识别方法应用与研究,导致建模实用性有限。
将外部气象因素与机组工况数据相结合,建立基于集成学习的火电厂凝汽器真空度预测模型。首先,运用iForest[12]完成数据的异常值识别和清洗。其次,使用集成学习中的Xgboost 方法进行建立预测模型;按照是否考虑温度、气压差分值两种方式,进行模型测试。最后,选取山东省内某机组运行数据对两种模型进行对比分析。
1 影响因素分析与数据预处理
1.1 影响因素分析
结合前述的参考文献,提取了机组负荷、低压缸排汽温度(发电侧/调门侧)、凝汽器热井出水温度、循环水(进/出)水温度6个工况参数作为工况输入变量。此外,由于环境气象条件会对凝汽器真空度产生影响,同时气象预报数据还能够对凝汽器真空走势产生预判作用,因此还引入了地区大气温度、气压、湿度和风速4 个气象因素,作为模型的气象输入变量。表1给出了模型输入、输出参数的名称。
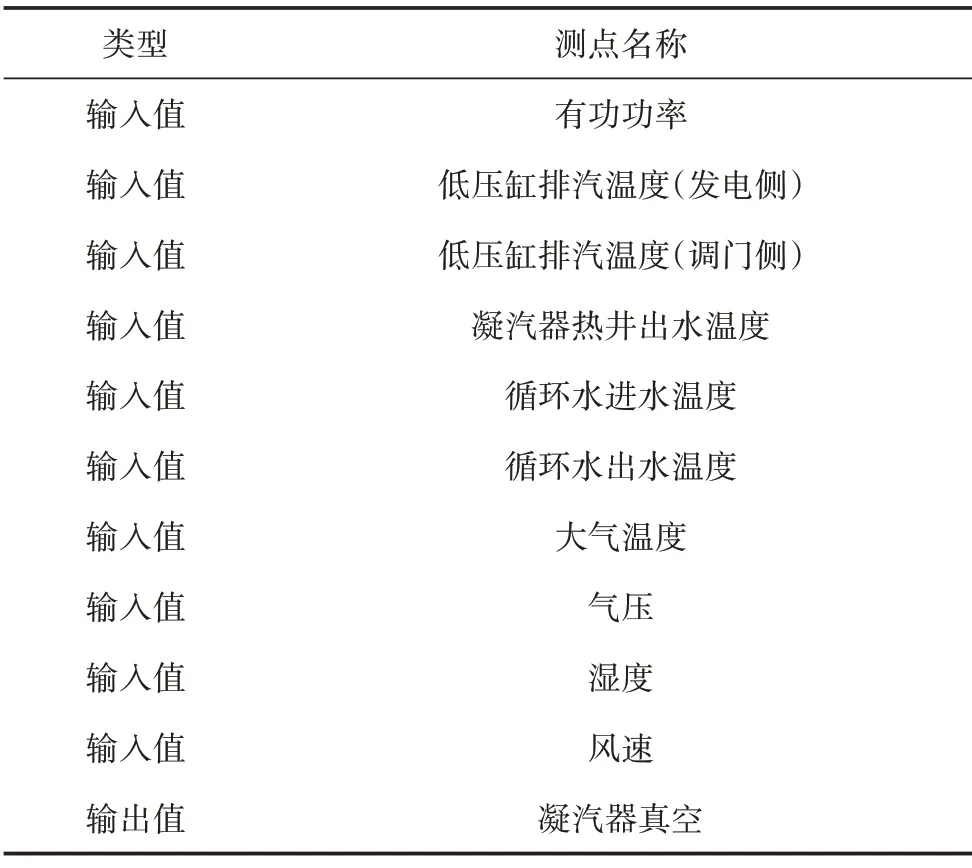
表1 模型主要参数
1.2 iForest方法
iForest 是一种基于集成学习的异常数据快速检测方法,具有线性时间复杂度和高精准度。该方法中的森林由大量的二叉树构成,其构建过程是一个随机特征剖分的过程。组成iForest 的基分类器被称为孤立树(Isolation Tree,iTree),iForest 算法将异常点看成容易被孤立的离群点,即分布稀疏且离密度高的群体较远的点,其算法过程主要有如下两个阶段。
阶段一:训练出t棵iTree。步骤1:令D={d1,…,dn}为给定的数据集,n为样本的数 量;∀di∈D,di=(di1,…,dim),m为数据的维度。从D中随机抽取φ个样本点构成D的子集D′放入根节点。步骤2:从m个维度中指定一个维度q,在当前数据中随机产生一个切割点p,满足:
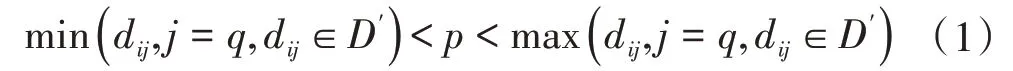
步骤3:此切割点p生成了一个超平面,将当前数据空间划分为两个子空间,指定维度小于p的样本点放入左子节点,大于或等于p的样本放入右子节点。步骤4:重复步骤2、步骤3,直至所有的叶子节点都只有一个样本点或者iTree 已经达到指定的高度。重复上述步骤1至4直到生成t个iTree。
阶段二:评估每个样本点的异常值分数。对于每一个数据点di,令其遍历每一颗iTree,计算点di的路径长度h(di),h(·)为从iTree 的根节点到叶子节点所经过的边的数量。对所有点的h(·)做归一化处理。异常值分数的计算公式为
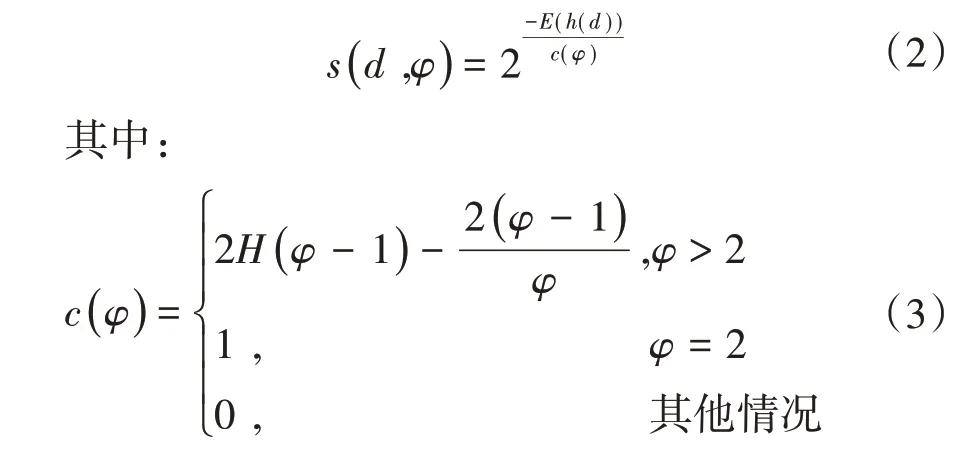
式中:H(·)为调和数,它近似等于ln(·)+γ,其中:γ=0.577 815 664 9,为欧拉常数;E(h(d))为孤立森林中h(d)的平均值。若样本di的异常值分数s接近1,则其被识别为异常数据;若s小于0.5,则其被识别为正常数据;当s介于0.5 与1 之间时,则不能被识别为明显的异常数据。
1.3 数据清洗
通过山东省网源监督服务技术平台提取了山东省某电厂的凝汽器运行工况数据和电厂所在地区天气数据,数据时间段选为:2020 年3 月18 日00:00:00至2020年10月8日23:59:59,数据周期为10 min。图1、图2 给出了凝汽器工况数据在使用iForest 方法进行数据清洗前后的对比情况。在使用iForest 方法以后,原始数据中的异常点被识别出来并完成了剔除。
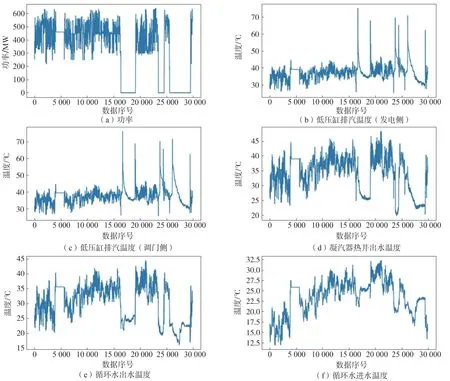
图1 凝汽器工况原始数据
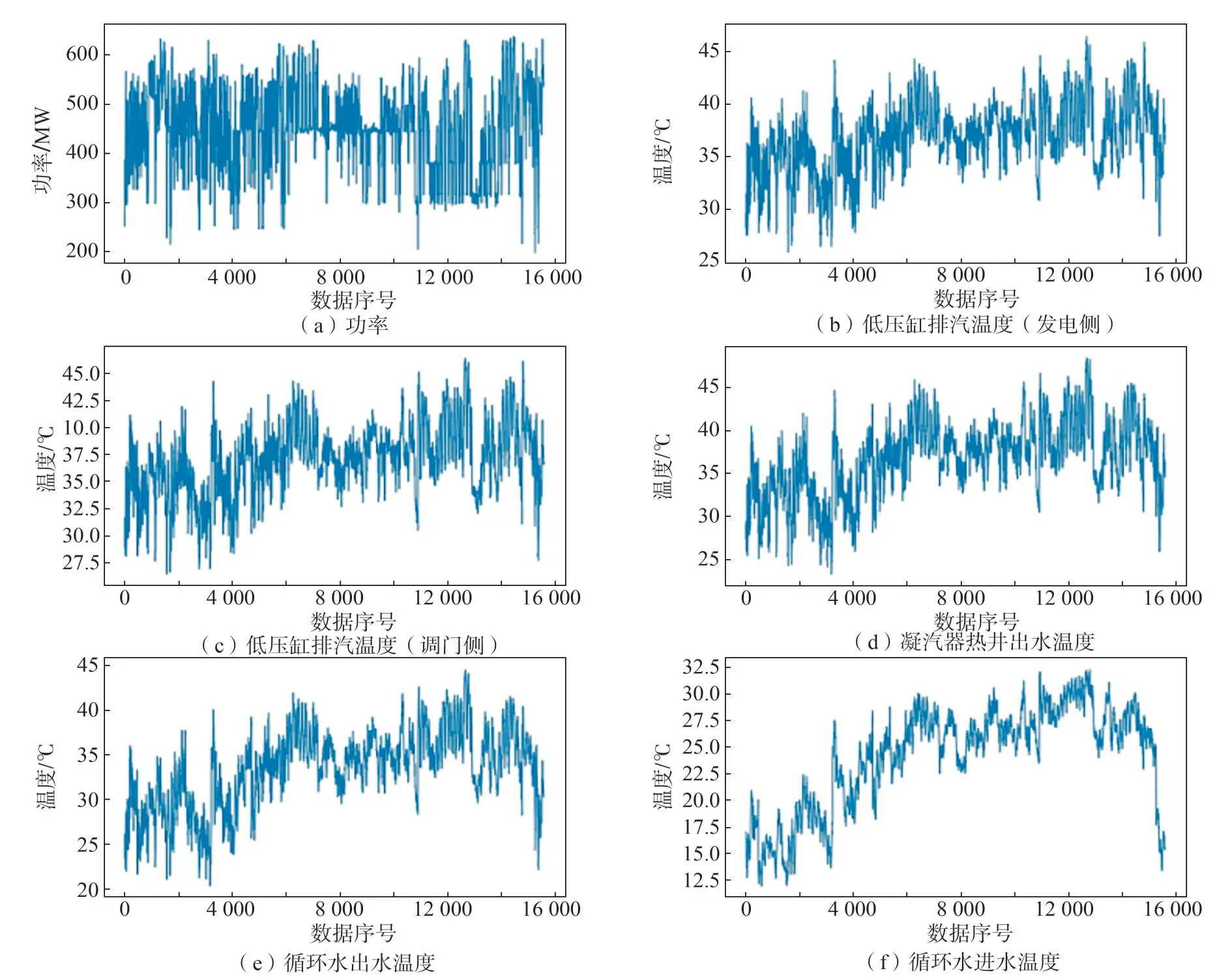
图2 凝汽器工况清洗后数据
2 凝汽器真空预测模型
2.1 梯度增强与随机森林
梯度增强GBDT(Gradient Boosting Decision Tree,GBDT)[13]作为一种集成算法,属于提升算法(Boosting)中的一种。提升算法以一种高度自适应的方法顺序地学习这些弱学习器,并按照某种确定性的策略将它们组合起来。虽然通过Boosting,模型的学习偏差将达到逐步降低,但是也存在诸多缺点,主要是:由于弱学习器之间存在依赖关系,难以并行训练数据;高维数据导致计算量加大,不适于大数据应用场景。
随机森林由Leo Breiman(2001)[14]提出,它通过自助法(Bagging)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。随机森林由于引入随机项而避免了学习过程中的过拟合,同时具有比较强的抗噪能力;同时,随机森林比较适于处理高维数据,且不需要进行人工特征预分析,大大简化了建模工作;最后,由于随机树可以进行并行计算,因此实践中往往可以引入GPU 硬件加速,从而使其能够在大数据场景下依然具有比较好的表现。但是随机森林算法也有明显的缺点,主要是由于没有做到以降低模型偏差为目标,因此在回归问题中的预测精度往往不高。
2.2 Xgboost算法
为了能够实现对GBDT 算法和随机森林算法的互补(见图3),凝汽器真空度预测采用了基于梯度增强的随机森林算法Xgboost[15]。Xgboost 每一轮训练一棵树,使得损失函数能够极小化。其损失函数不仅衡量了模型的拟合误差,还增加了正则化项,即对每棵树复杂度的惩罚项,来防止过拟合。

图3 GBDT、随机森林与Xgboost算法的关系
在Xgboost中,目标损失函数的计算公式为
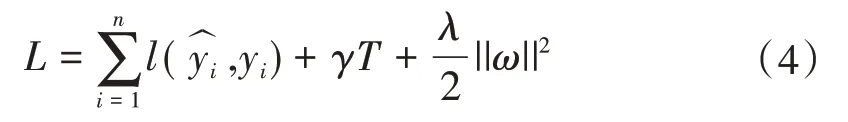
式中:l为衡量实际凝汽器真空度yi与预测量之间的差值;γT+为损失函数的惩罚项,它通过对模型的复杂度进行惩罚来提高模型的泛化能力,T为决策树的叶子数量,ω为决策树叶子的权值向量,λ与γ为系数。
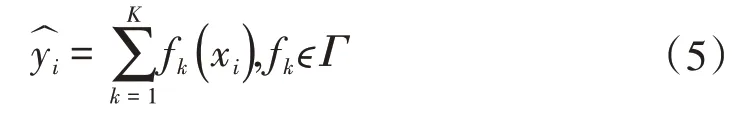
式中:k为决策树的数量;Γ为决策树的集合;fk(xi)为样本xi在第k棵树上的预测结果。
在训练的过程中,树的建立过程由计算公式(5)给出
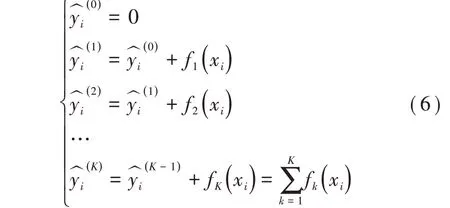
2.3 模型评估指标
模型评估采用MAE、R两个指标。MAE为平均绝对误差,其计算的是真实yi与预测值差的绝对平均值,具体公式为
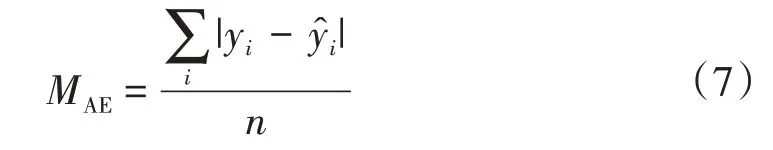
R为极差(Range)又称范围误差,是用来表示所有真实值yi与预测值误差中最大值与最小值之间的差距,计算公式为
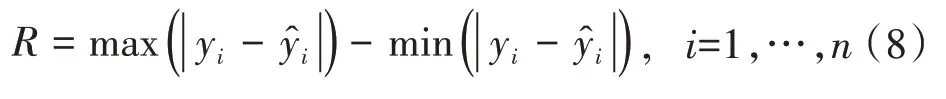
3 实际应用验证
在模型的验证过程中,数据集按照60%和40%的比例划分成训练集和测试集。考虑到数据量较大,使用了GPU进行模型训练加速。
模型验证的方式分成两种情况:一种是按照将前述清洗后的输入变量(包括工况数据与天气数据)原值直接输入真空预测模型;另一种是考虑到天气变量的变化可能对凝汽器真空的影响更显著,因此在预测模型的输入变量中又增加了气温与气压的差分。表2 给出了两种方法下,模型在训练集和测试集中的表现。
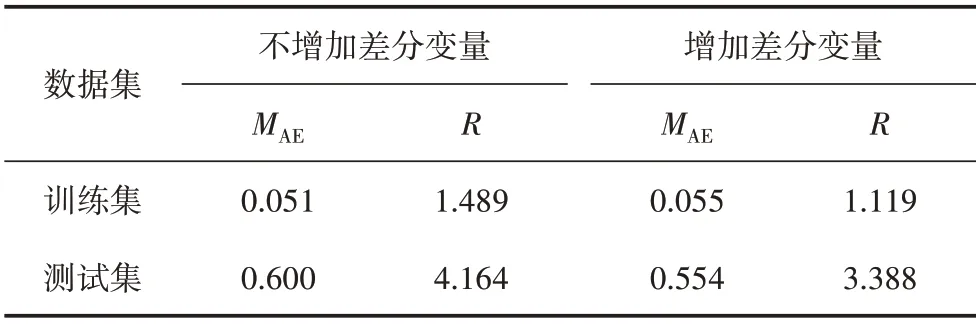
表2 模型在训练和测试过程中的表现
从表2 可以看到,增加差分变量以后,测试集在MAE和R均有10%的提升。图4、图5 给出了两种验证方法下,训练集和测试集预测曲线与实际曲线的对比。
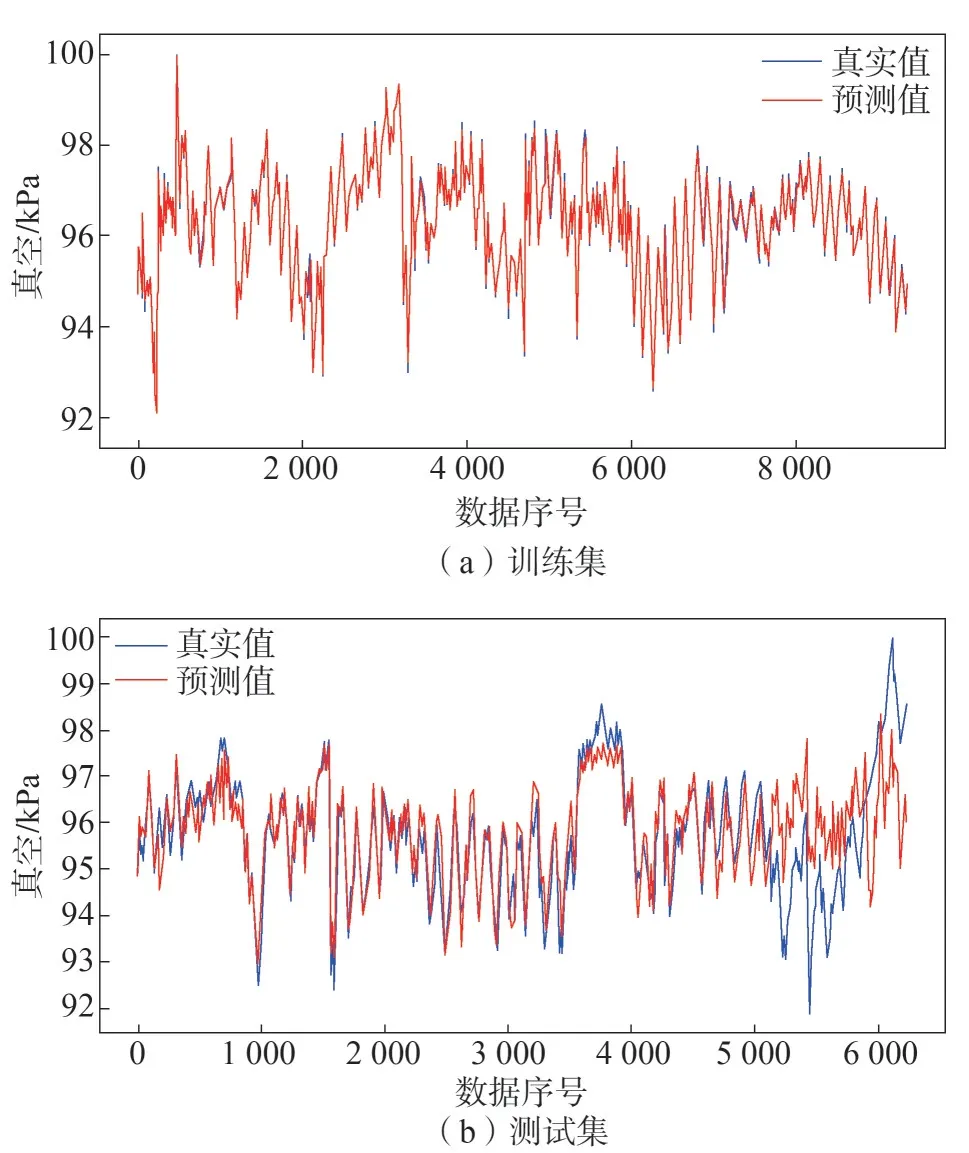
图4 不增加差分变量情况下模型的表现
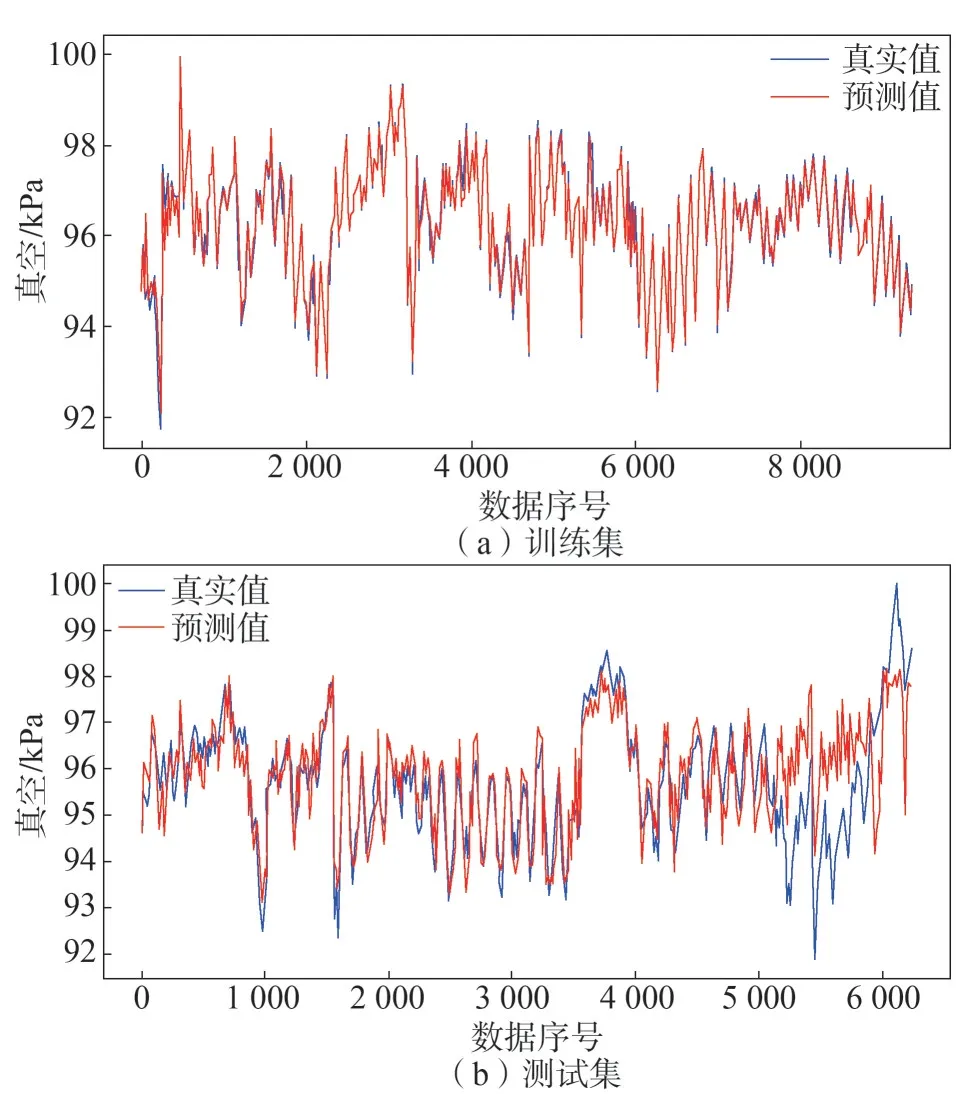
图5 增加差分变量情况下模型的表现
通过上述测试结果分析,得到如下结论:1)模型最优的输入测点为:有功功率、低压缸排汽温度(发电侧/调门侧)、凝汽器热井出水温度、循环水进出水温度、大气温度、气压、湿度、风速、温度差分和气压差分;2)模型误差较大的部分出现在真空值局部波动较大的区域,增加差分变量以后模型在该区域的表现得到了提升。因此,可以认为气象因素的波动对凝汽器真空产生了比较明显的影响。同时,如果能够结合未来天气预报信息,则可以达到提前预判以及时调整机组运行情况的效果。
4 结语
运用集成学习的方法先后在数据清洗和模型建模环节采用了孤立森林和Xgboost 算法完成了对大数据场景下凝汽器真空度的预测。同时,在考虑到外部气象因素对凝汽器真空影响的情况下,还研究了气温和气压的波动对凝汽器真空的影响,给出了定量的结论。研究发现,集成学习由于能够同时降低模型的偏差与方差,因此具有较好的预测效果;气象数据的波动也能够在一定程度上解释凝汽器真空的波动。
猜你喜欢
江苏安全生产(2023年11期)2023-12-14 12:05:26
真空与低温(2022年6期)2023-01-06 07:33:20
设备管理与维修(2022年21期)2022-12-28 07:34:32
水泵技术(2022年2期)2022-06-16 07:08:18
能源工程(2020年6期)2021-01-26 00:55:18
中国奶牛(2019年1期)2019-02-15 07:19:46
电站辅机(2016年3期)2016-05-17 03:52:29
橡胶工业(2015年6期)2015-07-29 09:20:34
中国卫生(2014年11期)2014-11-12 13:11:20
发电设备(2014年4期)2014-02-27 09:45:31
