
一种基于差分进化的鲁棒音频隐写算法
2021-12-10 07:59苏兆品沈朝勇张国富岳峰胡东辉
电信科学 2021年11期
苏兆品,沈朝勇,张国富,岳峰,2,胡东辉
一种基于差分进化的鲁棒音频隐写算法
苏兆品1,2,3,沈朝勇1,张国富1,2,3,岳峰1,2,胡东辉1,2,3
(1. 合肥工业大学计算机与信息学院,安徽 合肥 230601;2. 合肥工业大学工业安全应急技术安徽省重点实验室,安徽 合肥 230601;3. 合肥工业大学智能互联系统安徽省实验室,安徽 合肥 230009)
音频隐写是将秘密信息隐藏到音频载体中,已成为信息隐藏领域的一个研究热点。已有研究大多聚焦最小化隐写失真,却以牺牲隐写容量为代价,且往往被一些常规信号攻击后难以正确提取秘密信息。为此,基于扩频技术,首先,分析了隐写参数(分段隐写强度和分段隐写容量)与不可感知性和鲁棒性的关系,并构建了一种以分段隐写强度、分段隐写容量为自变量,以不可感知性和隐写容量为优化目标,以信噪比为约束条件的音频隐写多目标优化模型;然后,提出了一种基于差分进化的鲁棒音频隐写算法,设计了相应的编码、适应度函数、交叉和变异算子。对比实验结果表明,所提隐写算法能够在保证不可感知性和抗隐写分析能力的前提下达到更好的鲁棒性,可以有效抵御一些常规信号处理攻击。
音频隐写;隐写参数;差分进化;鲁棒性
1 引言
隐写术是利用人的感知冗余和数字载体的统计冗余,将秘密信息隐藏于公开载体之中而不损坏载体的质量,以“隐匿秘密和通信存在”的方式实现秘密信息的传递[1]。与图像隐写[2]不同,在辨别微小失真方面,人的听觉系统要比视觉系统敏感得多。因此,音频隐写显得异常困难,发展较为缓慢[3]。
已有音频隐写方法大多利用人类听觉系统的掩蔽效应,在音频信号的时域或频域进行隐写。常见的有最低有效位(least significant bit,LSB)、相位编码和变换域等。例如,邹明光等[4]首先比较音频每个采样点分组中振幅值之间的关系,然后基于振幅值修改实现秘密信息的写入。Liu等[5]根据加权能量自适应的选择宿主音频的小波包子带来嵌入秘密信息。Ahani等[6]利用离散小波变换(discrete wavelet transformation,DWT)和稀疏分解将秘密信息嵌入信号的更高语义层。Meligy等[7]基于提升小波变换系数修改和LSB对秘密信息进行嵌入。吴秋玲等[8]通过调节DWT的中高频系数来隐藏秘密信息。Kanhe和Aghila[9]利用语音信号的发声部分,通过离散余弦变换(discrete cosine transform,DCT)和奇异值分解(singular value decomposition,SVD)的级联实现隐写。Bharti等[10]在嵌入之前对秘密音频的幅度位进行函数转换,然后将转换后的幅度嵌入载体音频的幅度中,将秘密音频信号嵌入载体音频的LSB。Ali等[11]基于分形编码和混沌LSB将秘密音频嵌入具有相同大小的封面音频中。张雪垣等[12-13]基于双层校验格码(syndrome-trellis codes,STC)提出一种音频分段隐写方法,通过对音频LSB载体流进行分段切割,利用最佳子校验矩阵嵌入秘密信息。
需要指出的是,上述已有工作大多只考虑如何使隐写失真达到最小化,牺牲了隐写容量,且忽略了鲁棒性。隐写是为了在不被发觉的情况下传输秘密信息,在很多网络音频应用中,发送者上传的隐写后的携密音频文件很可能会经过常规信号处理或有损转码、滤波、加噪等操作。而且,如果网络攻击者高度怀疑音频文件中包含秘密信息,但利用隐写分析器又检测失败,这时很可能采取“得不到就毁掉”极端措施,对音频文件进行改动、信号处理技术的加工或环境噪声攻击等。而已有工作,特别是基于压缩域的音频隐写,很难适应上述的信号处理和有损转码等情形,从而可能导致接收者无法从携密音频中正确提取出秘密信息,造成信息传递的失败。可见,音频隐写的鲁棒性也是实现秘密信息安全传递的一个重要指标,尤其是在商业机密等领域,理应受到足够的重视。
基于上述背景,本文基于扩频(spread spectrum,SS)[14]通信技术,通过分析隐写强度、隐写容量与不可感知性、鲁棒性之间的关系构建了一种音频隐写多目标优化模型,然后基于差分进化(differential evolution,DE)[15]进行求解,提出一种鲁棒音频隐写算法,最后通过实验验证了所提隐写算法的有效性。
2 基于扩频的音频隐写优化模型
2.1 基于扩频的音频隐写方案
已有研究表明,基于SS的信息写入方案通常具有较好的鲁棒性[14],但通常是直接对整个音频分段后进行信息写入,而没有考虑静音段和有声段对信息写入的影响不同,无法发挥音频载体隐写的最大性能。为了综合考虑鲁棒性和不可感知性,本文采用如图1所示的音频隐写方案,只在音频的有声段进行隐写。


2.2 隐写参数与不可感知性和鲁棒性之间的关系


图1 基于SS的音频隐写方案
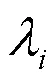

表1 常规信号处理攻击方式

表2 测试音频
鲁棒性与隐写参数的关系如图3所示,当隐写容量固定时,鲁棒性会随着隐写强度增加而逐渐增加;当隐写强度固定时,鲁棒性随着隐写容量增加基本保持平稳。但从总体看,MBER值波动平缓,验证了基于SS的音频隐写方案本身就具有很好的鲁棒性。

图2 不可感知性与隐写参数的关系
2.3 音频隐写优化模型的构建

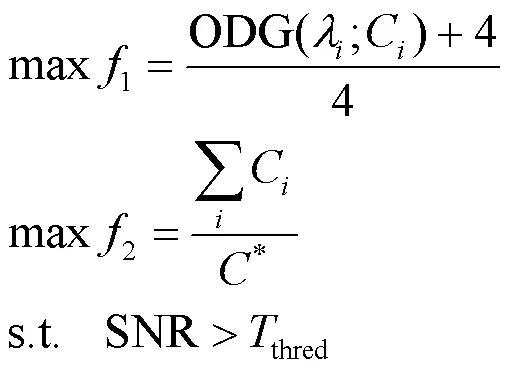

图3 MBER与隐写参数的关系

3 基于DE的鲁棒音频隐写算法

3.1 个体编码与初始化


图4 个体编码结构
3.2 适应度值计算
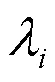
3.3 变异操作
变异操作采用DE/rand/1/bin方式[18]:

为了避免算法的早熟和进化后期较优解易被破坏,本文选择文献[19]的自适应变异算子:


3.4 交叉操作

3.5 边界处理
3.6 选择操作
3.7 算法描述
本文提出的基于DE的鲁棒音频隐写算法流程如图5所示,具体步骤如下。
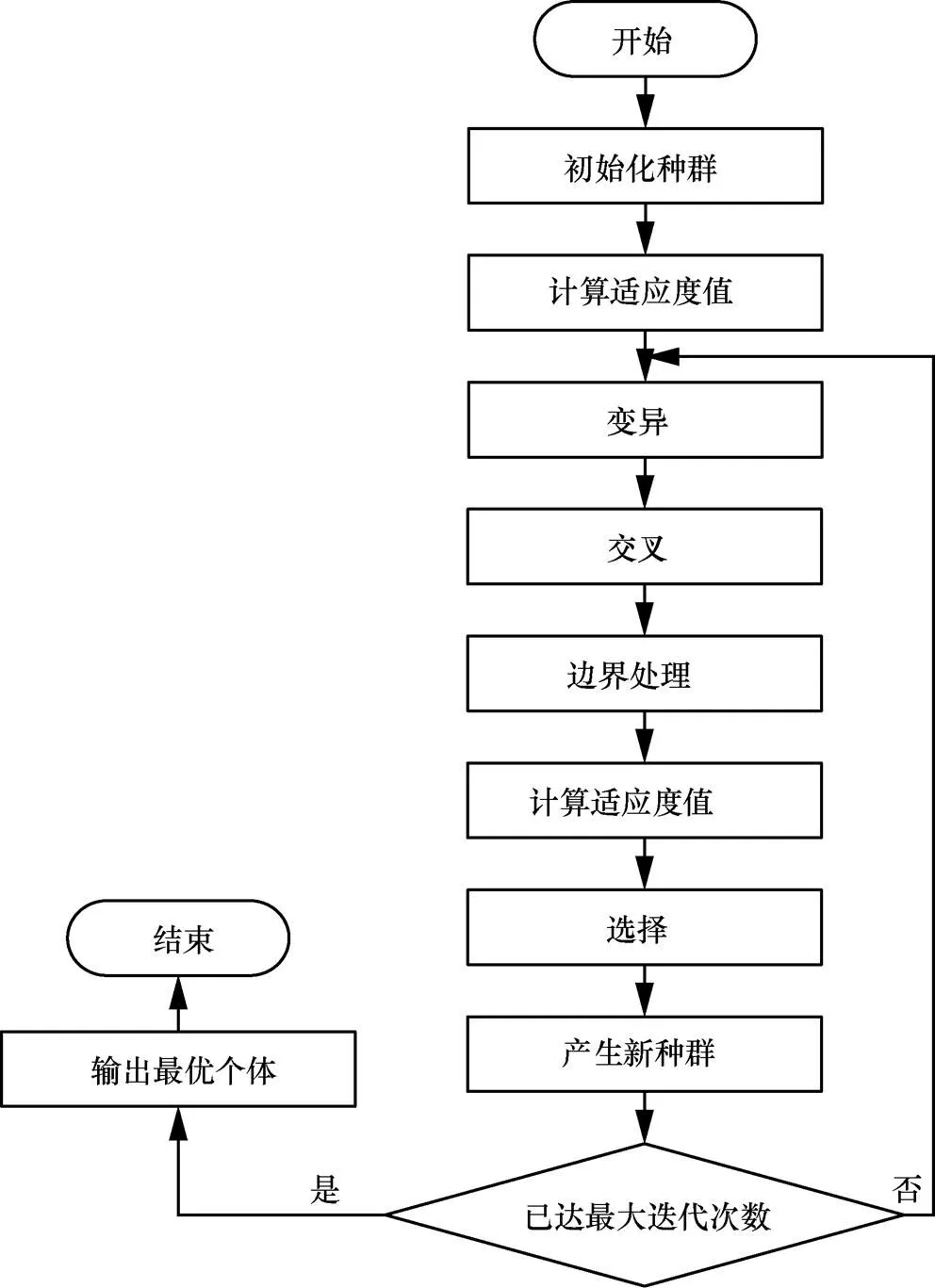
图5 基于DE的鲁棒音频隐写算法流程
步骤3 根据适应度值计算方法计算初始种群中每个个体的适应度值。
步骤4 对初始种群进行变异和交叉操作组成进化种群。按照边界处理方法对进化种群中的每个个体进行边界检查和处理。
步骤5 根据适应度值计算方法计算进化种群中每个个体的适应度值。
步骤6 对初始种群和进化种群进行选择操作,生成新的初始种群。
步骤7 如果已达最大迭代次数,则结束算法,输出种群中的最优个体;否则,转步骤4继续进化。
4 实验结果和分析
为了验证本文基于DE的鲁棒音频隐写算法(后称DE算法)的有效性,将DE算法与文献[12-13]提出的分段STC方法(简称STC)和文献[6,8]提出的DWT方法进行对比实验。测试音频数据集为50条采样率为48 kHz、分辨率为16 bit/s、长度为55 s的wav格式音频。为了直观地展示对比方法的效果,秘密信息采用64×64的二值图像,根据载体本身的特性,重复进行隐写。
所有对比方法的代码均基于MATLAB编写,并均在AMD Ryzen CPU 3.59 GHz、16 GB内存、Windows 10操作系统的个人计算机上进行测试。
4.1 鲁棒性测试
3种不同方法在测试数据集上的MBER结果如图6所示,STC方法的MBER值最大为0.43,最小为0.38,平均值在0.4左右,DWT方法的MBER值最大为0.33,最小为22,平均值在0.28左右,而本文DE算法的MBER值最低为0.02,最高为0.29,平均在0.14左右,明显低于STC方法和DWT方法。上述实验结果表明,在无攻击环境下,本文DE算法的误码率要更低。

图6 不同方法在测试数据集上的MBER结果
为进一步对比3种方法的抗攻击能力,随机选取了test17和test47两条音频,将二值图像完全写入音频,对隐写后的音频进行表1所示的8种常规攻击。表3和表4给出了这两条音频在每种攻击之后提取秘密信息与原始密信之间的BER。可以看出,本文DE算法在MP3压缩、重量化、幅值修改、重采样和中值滤波后的误码率几乎接近于0;在经加高斯白噪声和低通滤波后的误码率在0.1左右。STC方法只有在裁剪攻击下误码率约为0.04,在其他7种情况下均很难恢复出秘密信息。DWT方法在幅值修改、重采样、加高斯白噪声和裁剪后的误码率在0.15左右,在其他4种情况下也很难恢复出秘密信息。可能的原因是,本文测试音频相对较长,对20 ms经过DWT变换之后,高频系数的前半部分能量或后半部分能量可能会为0,即使在无攻击情况下也会出现提取错误。上述实验结果表明,在常规信号处理攻击环境下,本文DE算法的误码率更低,可以提取出全部或者大部分秘密信息。

表3 test17在8种攻击下的BER

表4 test47在8种攻击下的BER
综上,本文DE算法所给隐写方案的鲁棒性更强,即使在被信号处理攻击后也能保持较低的误码率。
4.2 不可感知性测试
为进一步量化分析不同方法的不可感知性,3种方法在测试数据集上的SNR和ODG值如图7所示,STC的不可感知性最好,DWT的不可感知性最差,本文DE算法不可感知性居中。这是因为,在优化目标上,STC只追求失真度最小,而DWT同时考虑SNR和BER,本文DE算法兼顾隐写容量和ODG。具体来说,本文DE算法在50条测试音频的SNR值均大于20 dB;除了test17,其余测试音频的ODG值均大于−2,人耳已经很难感知载体音频的细微变化。上述实验结果表明,本文DE算法给出的隐写方案保持了很好的不可感知性。此外,test17的VAD结果如图8所示,在第37 s和40 s之间,分割出的3个有声段长度过小,且包含了静音段,导致此段的ODG的值较低。基于这一发现,未来可以考虑不在时长过短的有声段中嵌入秘密信息,以确保更好的不可感知性。
4.3 抗隐写分析性能测试
采用文献[20]的卷积神经网络通用隐写分析器检测DE、STC和DWT 3种隐写方法的抗隐写分析能力。首先,从开源平台“喜马拉雅”下载采样率为48 kHz、分辨率为16 bit/s的wav格式音频,利用CoolEdit将其切分为每条时长55 s、共1 300条语音文件;然后,分别利用DE、STC和DWT对其进行隐写,得到各自的1 300条载密音频;并分别用1 300条含密语音与1 300条原始音频训练隐写分析器;最后,利用训练好的隐写分析器检测前面实验采用的50条测试音频和对应的50条含密音频。
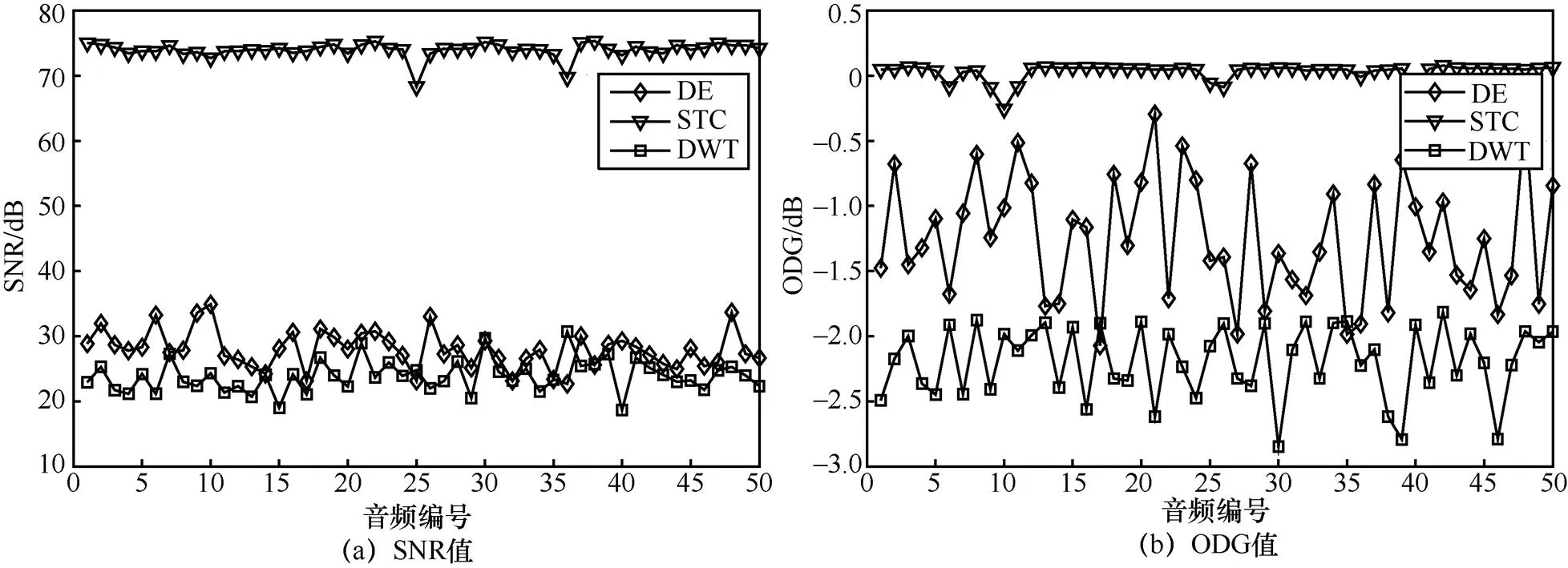
图7 不同方法的不可感知性测试结果

图8 音频test 17的VAD结果
当隐写分析器同时检测出原始音频和对应的隐写音频时,认为检测正确。3种方法的隐写分析检测结果见表5,本文DE算法可以检测出10组,正确率为20%;STC方法检测出11组,正确率为22%;DWT方法检测出9组,正确率为18%。上述实验结果表明,本文DE算法在抗隐写分析性能上与STC和DWT方法不相上下。

表5 隐写分析检测结果
5 结束语
音频隐写是信息隐藏领域中的一个研究热点,主要致力于将秘密信息写入音频信号,同时在鲁棒性、不可感知性、隐写容量和抗隐写分析性能之间达到一个理想的均衡。为此,本文基于扩频技术研究音频隐写,通过分析隐写参数与不可感知性和鲁棒性的关系,构建了一种音频隐写多目标优化模型,并基于DE算法进行求解,设计了相应的编码和初始化方法,变异、交叉、选择和边界处理方法。实验结果表明,本文所提隐写算法在保持不可感知性和抗隐写分析能力的基础上,具有更好的鲁棒性,可以有效抵御一些常规信号处理的攻击。
但是,本文只是对基于搜索的音频隐写的一个初步探索,未来仍有许多问题需要进一步的深入研究。首先,需要在目标函数中考虑抗检测性,以期进一步提升隐写方案的抗隐写分析能力;其次,需要基于VAD分辨出时长过短的有声段,以避免在这些有声段进行隐写造成的过度失真;此外,还将考虑基于多目标DE算法求解音频隐写模型,以期在隐写容量、鲁棒性、不可感知性和抗检测性之间达到一个理想的均衡。
[1] 李凤华, 李晖, 贾焰, 等. 隐私计算研究范畴及发展趋势[J]. 通信学报, 2016, 37(4): 1-11.
LI F H, LI H, JIA Y, et al. Privacy computing: concept, connotation and its research trend[J]. Journal on Communications, 2016, 37(4): 1-11
[2] 孙树亮. 基于非下采样Contourlet变换和Hill编码的图像隐写[J]. 电信科学, 2016, 32(6): 124-128.
SUN S L. Image steganography based on nonsubsampled Contourlet transform and Hill cipher[J]. Telecommunications Science, 2016, 32(6): 124-128.
[3] DUTTA H, DAS R K, NANDI S, et al. An overview of digital audio steganography[J]. IETE Technical Review, 2020, 37(6): 632-650.
[4] 邹明光, 李芝棠. 基于振幅值修改的wav音频隐写算法[J]. 通信学报, 2014(z1): 36-40.
ZOU M G, LI Z T. Wav-audio steganography algorithm based on amplitude modifying [J]. Journal on Communications, 2014(z1): 36-40.
[5] LIU H L, LIU J J, HU R G, et al. Adaptive audio steganography scheme based on wavelet packet energy[C]//2017 IEEE 3rd international conference on big data security on cloud (bigdatasecurity), IEEE international conference on high performance and smart computing (hpsc), and IEEE international conference on intelligent data and security (ids). Piscataway: IEEE Press, 2017: 26-31.
[6] AHANI S, GHAEMMAGHAMI S, WANG Z J. A sparse representation-based wavelet domain speech steganography method[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2015, 23(1): 80-91.
[7] MELIGY A M, NASEF M M, EID F T. An efficient method to audio steganography based on modification of least significant bit technique using random keys[J]. International Journal of Computer Network and Information Security, 2015, 7(7): 24-29.
[8] 吴秋玲, 吴蒙. 基于小波变换的语音信息隐藏新方法[J]. 电子与信息学报, 2016, 38(4): 834-840.
WU Q L, WU M. Novel audio information hiding algorithm based on wavelet transform[J]. Journal of Electronics & Information Technology, 2016, 38(4): 834-840.
[9] KANHE A, AGHILA G. A DCT-SVD-based speech steganography in voiced frames[J]. Circuits, Systems, and Signal Processing, 2018, 37(11): 5049-5068.
[10] BHARTI S S, GUPTA M, AGARWAL S. A novel approach for audio steganography by processing of amplitudes and signs of secret audio separately[J]. Multimedia Tools and Applications, 2019, 78(16): 23179-23201.
[11] ALI A H, GEORGE L E, ZAIDAN A, et al. High capacity, transparent and secure audio steganography model based on fractal coding and chaotic map in temporal domain[J]. Multimedia Tools and Applications, 2018, 77(23): 31487-31516.
[12] 张雪垣, 王让定, 严迪群, 等. 基于分段STC的音频隐写算法[J]. 电信科学, 2019, 35(7): 115-123.
ZHANG X Y, WANG R D, YAN D Q, et al. An audio steganography algorithm based on segment-STC[J]. Telecommunications Science, 2019, 35(7): 115-123.
[13] ZHANG X Y, WANG R D, YAN D Q, et al. Selecting optimal submatrix for syndrome-trellis codes (STCs)-based steganography with segmentation[J]. IEEE Access, 2020, 8: 61754-61766.
[14] SU Z P, ZHANG G F, YUE F, et al. SNR-constrained heuristics for optimizing the scaling parameter of robust audio watermarking[J]. IEEE Transactions on Multimedia, 2018, 20(10): 2631-2644.
[15] STORN R, PRICE K. Differential evolution - A simple and efficient heuristic for global optimization over continuous spaces[J]. Journal of Global Optimization, 1997, 11(4): 341-359.
[16] CHANG J H, KIM N S, MITRA S K. Voice activity detection based on multiple statistical models[J]. IEEE Transactions on Signal Processing, 2006, 54(6): 1965-1976.
[17] LEI B Y, SOON I Y, TAN E L. Robust SVD-based audio watermarking scheme with differential evolution optimization[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2013, 21(11): 2368-2378.
[18] DAS S, SUGANTHAN P N. Differential evolution: a survey of the state-of-the-art[J]. IEEE Transactions on Evolutionary Computation, 2011, 15(1): 4-31.
[19] YANG Z Y, TANG K, YAO X. Self-adaptive differential evolution with neighborhood search[C]//2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence). Piscataway: IEEE Press, 2008: 1110-1116.
[20] JIANG S Z, YE D P, HUANG J Q, et al. SmartSteganogaphy: Light-weight generative audio steganography model for smart embedding application[J]. Journal of Network and Computer Applications, 2020, 165: 102689.
A robust audio steganography algorithm based on differential evolution
SU Zhaopin1,2,3, SHEN Chaoyong1, ZHANG Guofu1,2,3, YUE Feng1,2,, HU Donghui1,2,3
1. School of Computer Science and Information Engineering, Hefei University of Technology, Hefei 230601, China 2. Anhui Province Key Laboratory of Industry Safety and Emergency Technology (Hefei University of Technology),Hefei 230601, China 3. Intelligent Interconnected Systems Laboratory of Anhui Province (Hefei University of Technology), Hefei 230009, China
Audio steganography is to hide secret information into the audio carrier and has become a research hotspot in the field of information hiding. Most of the existing studies focus on minimizing distortion at the expense of steganography capacity, and it is often difficult for them to extract secret information correctly after some common signal processing attacks. Therefore, based on the spread spectrum technology, firstly, the relationship between steganography parameters (i.e., segmented scaling parameters and steganography capacity) and imperceptibility as well as robustness was analyzed. Next, a multi-objective optimization model of audio steganography was presented, in which segmented scaling parameters and steganography capacity were decision variables, imperceptibility and steganography capacity were optimization objectives, and the signal-to-noise ratio was a constraint. Then, a robust audio steganography algorithm based on differential evolution was proposed, including the corresponding encoding, fitness function, crossover and mutation operators. Finally, comparative experimental results show that the proposed steganography algorithm can achieve better robustness against common signal processing attacks on the premise of ensuring imperceptibility and anti-detection.
audio steganography, steganography parameters, differential evolution, robustness
TP309.2
A
10.11959/j.issn.1000−0801.2021246

苏兆品(1983− ),女,博士,合肥工业大学副教授,主要研究方向为语音安全、进化算法。
沈朝勇(1996− ),男,合肥工业大学硕士生,主要研究方向为音频隐写、进化算法。
张国富(1979− ),男,博士,合肥工业大学教授,主要研究方向为语音安全、软件工程。
岳峰(1981− ),男,博士,合肥工业大学副研究员,主要研究方向为软件工程、信息安全。
胡东辉(1973− ),男,博士,合肥工业大学教授,主要研究方向为信息安全、机器学习。
s: The Anhui Provincial Key Research and Development Program (No.202004d07020011, N0.202104d07020001), MOE (Ministry of Education in China) Project of Humanities and Social Sciences (No.19YJC870021), Guangdong Provincial Key Laboratory of Brain-inspired Intelligent Computation (No.GBL202117), Fundamental Research Funds for the Central Universities (No.PA2020GDKC0015, No.A2021GDSK0073, No.PA2021GDSK0074)
2021−05−24;
2021−10−14
安徽省重点研究与开发计划(No.202004d07020011,No.202104d07020001);教育部人文社会科学研究青年基金项目(No.19YJC870021);广东省类脑智能计算重点实验室开放课题(No.GBL202117);中央高校基本科研业务费专项资金项目(No.PA2020GDKC0015,No.PA2021GDSK0073,No.PA2021GDSK0074)
猜你喜欢
雷达与对抗(2022年1期)2022-03-31
合肥工业大学学报(社会科学版)(2020年2期)2020-05-14
农业机械学报(2020年2期)2020-03-09
合肥工业大学学报(自然科学版)(2020年1期)2020-02-24
中华建设(2019年7期)2019-08-27
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
合肥工业大学学报(自然科学版)(2015年7期)2015-03-17
单片机与嵌入式系统应用(2014年7期)2014-03-24
铁路通信信号工程技术(2014年3期)2014-02-28
