
融合子集特征级联预学习的封装方法研究
2021-12-09 01:27:18潘丽敏佟彤罗森林秦枭喃
北京理工大学学报 2021年11期
潘丽敏, 佟彤, 罗森林, 秦枭喃
(北京理工大学 信息系统及安全对抗实验中心,北京 100081)
特征选择是数据挖掘中广泛应用的数据处理技术,主要通过去除数据集中无关和冗余特征来减少数据维度[1]. 特征选择增强了数据的可理解性,有利于更好地进行数据可视化,提高学习准确性,减少学习算法的训练时间并且提高预测性能.
特征选择方法分为过滤法,封装法和嵌入法. 其中,过滤法是最经典的特征选择方法之一,其原理是在学习算法之前先进行特征过滤,根据一定的评价标准对特征进行排序[2]. 过滤法不依赖后续应用的分类器,因此具有高效的特征选择速度,一般不需要重复的模型训练及反馈过程,但忽略了特征与分类器之间的相互作用以及特征间的依赖性,所以可能无法选择出最佳的特征子集[3]. 为提高过滤法的特征搜索性能,KANIMOZHI等[4]提出了一种新的IF2S算法以及TIFMC算法来选择特征的最优子集. DITZLER等[5]提出了一个用于特征子集选择(SLSS)的顺序学习框架以减少不必要的复杂性. 相关方法主要关注于对提升过滤法中特征排序的效果,并尝试加入非模型类的反馈信息,指导特征搜索过程.
封装法则通过结合后续学习算法来评价、反馈并选择特征. 该方法相较于过滤法最显著的优点就是结合了特征受体模型的反馈信息,针对特定的后续模型选择“更适”特征,同时考虑了特征之间的依赖关系,给出了相较于过滤法准确度更高的结果[3]. 近些年该类方法的研究热度依旧不减,林棋等[6]设计了一种基于文化基因算法和最小二乘支持向量机的MA-LSSVM特征选择算法构建相对高效稳定的分类器. GONZLEZ等[7]提出了一种基于多目标进化算法的特征选择封装方法提高了泛化能力及稳定性. XUE等[8]提出了特征选择方法HGEFS来提高最终预测精度. MAFARJA等[9]提出了一种基于鲸鱼优化算法(WOA)的特征选择封装法,用WOA算法的两个二元变体来搜索用于分类目的特征子集. 相关方法主要关注于在高维环境下提高特征搜索性能,并选择高效且稳定的评价模型,提高特征选择效率.
嵌入法将特征选择过程和学习算法相融合,即在学习算法过程中进行特征选择,典型的学习算法如C4.5,CART等,利用决策树的生成进行特征选择. 嵌入法的时间复杂度一般在过滤法和封装法之间,但特征选择效果弱于封装法,且鲁棒性相对较差[10]. 嵌入法常和聚类算法一同使用,例如使用聚类中心点来代替相应簇中的一组特征,利用特征表达或构建识别数据集中样本间的全局或局部关联关系. 例如ZHU等[11]提出了一种新的无监督特征选择方法,通过最大化来自不同聚类的样本之间的距离来发现和利用数据的全局信息,并通过结合拉普拉斯正则化来保留数据的局部性. 相关方法主要关注于嵌入过程之前的特征工程,以及构建更为高效、具有特定目的的特征数量约束,在各应用领域内实现准确特征选择.
上述特征选择方法中,封装法可针对各类模型选择更合适的特征,在维持甚至提高判别效果的前提下有效约简特征集,但目前仍存在以下问题:
① 特征搜索算法输出的特征子集一般将直接作为评价模型的输入,缺乏有效且泛化的特征工程,导致通常情况下算法对特征的应用效果依赖于评价模型的特征学习能力;
② 封装法中存在高迭代次数的特征评价反馈过程,因此不适合引入涉及人工操作的特征扩展或是高性能代价的神经网络类方法.
针对上述问题,本文提出一种基于级联森林结构的子集特征预学习封装法. 通过在搜索算法与评价模型之间添加多层级联森林,在低消耗条件下有效重构待评价特征子集为高级特征集,降低评价模型模式识别难度,同时提高对特征子集综合性能的评价效果. 多组实验结果表明,在多种搜索算法和评级模型的组合中,本文方法均可更准确的选择更合适的特征子集,在保证判别性能的条件下,获得更小的特征子集,进一步提高了模型可解释性.
1 算法原理
融合子集特征级联预学习的封装方法原理图如图1所示,首先对模型进行特征搜索,生成预选特征子集,然后输入到级联森林中进行特征重构,生成预选高级特征子集,之后基于预选高级特征子集训练评价模型,以此评估预选特征子集综合性能;重复上述特征搜索及评价过程,直至达到停止条件,输出更适特征子集.
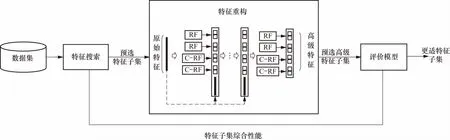
图1 融合子集特征级联预学习封装法模型原理图Fig.1 Principle diagram of combing wrapper method and subset feature with cascade pre-learning
1.1 特征搜索
特征搜索的目的是为了生成预选特征子集,并接受评价模型对当前预选特征子集的性能反馈,持续搜索潜在的更优预选特征子集. 其搜索策略根据特征子集形成过程不同大致可分为3类:全局最优、启发式搜索和随机搜索[12]. 全局最优搜索策略是对解空间进行充分搜索,从而找到全局最优解的过程,其中典型的有穷举法和分支定界法[13],分支定界法能保证在事先确定优化特征子集中特征数量的情况下,找到相对可分性判据来说最优子集,但算法时间复杂度较高,推广性差;启发式搜索根据某种次序不断向当前特征子集中添加或剔除特征,从而获得优化特征子集[14],例如序列前向选择、后向选择、浮动搜索等,此类策略通常计算复杂度相对较小,但容易陷入局部最优;随机搜索则是从随机产生的某个候选特征子集开始,按照一定的启发式信息和规则逐步逼近全局最优解的过程,随机算法属于一种近似算法,能找出近似最优解,具体算法例如粒子群算法,遗传算法,模拟退火算法等,但不确定性较高,总循环次数较大才可能得到较好结果,参数选择对最终结果好坏影响很大. 综上,在具备充足计算资源的条件下,全局搜索可遍历评价全部预选子集从而确定最佳子集;而在计算资源有限条件下,则应使用启发式搜索及随机搜索. 本模型针对各实际任务,分别采用贪婪搜索、粒子群优化以及随机搜索作为搜索策略的代表以完成特征搜索.
1.2 特征重构
级联森林是一种具有级联结构的决策树集合模型,通过堆叠多层随机森林或完全随机森林,以实现更好的特征表示和学习,其中完全随机森林即是在训练过程中完全随机选择一个原始特征作为决策树的每个节点. 此模型可以自适应级联数量及复杂度,因此在任意规模的数据上都能够表现出色且发挥集成学习的优势[15]. 级联森林将输出一种低维连续、稠密的实值特征向量,该特征集可更好地映射不同类别样本的差异性,保持封装法低耦合性的同时降低后续评价模型模式识别难度,提高任意评价模型对特征子集综合性能的评价效果. 其模型结构可见图1中的特征重构部分,其具体过程如下.
首先,经特征搜索模块选择后的仅包含预选特征子集的训练子集将作为级联森林的输入,而该数据集的特征集合在级联森林中将被称为原始特征. 第一级联层将基于原始特征默认训练4个森林模型,其中包含2个随机森林(决策树采用信息增益比或基尼指数确定分裂节点所用特征)及2个完全随机森林(决策树随机确定分裂节点所用特征),以此增加层内模型多样性. 级联层将拼接各森林的输出标签向量(维度为标签类别数量)和原始特征向量得到当前层的输出特征向量,例如针对三分类问题,每个森林模型都将产生一个三维向量,输出特征向量则会在原始特征向量的基础上增加12维重构特征构成输出特征.
然后,将前一级联层升维后的训练子集作为下一层的输入,重复执行上述步骤. 级联森林结构通过事先定义好的多层级联构架不断迭代,最后输出经过多层变换得到的升维数据集及相应的高级特征. 值得说明的是,根据实际任务的特征维度及模式复杂性,可对级联层的森林数量进行调整,从而改变重构特征数量,使得该模型具有良好的任务适应性,可应对各类规模的实际任务.
具体地,以d表示原始特征向量,mi表示第i层的输入向量,Foresti,n(mi)表示第i层、第n个森林的输出向量,则级联森林的第一层的输入m1=d,第i层输出mi+1可表示为
(1)
其中Con(·)表示向量连接操作.mi+1将作为Foresti,n(mi)的输入,以此构成级联结构.而输出层的重构特征将不再包含原始特征d,即
(2)
构建级联森林时,可根据实际数据的特征维度、样本量及复杂度对其层、级结构进行调整. 针对层结构,可扩展单级结构中森林的数量、调整随机森林与完全随机森林的比例、使用其他模型作为分类单元,以此平衡特征重构模型的灵活性及性能. 而针对级结构,模型将从单层开始自动扩展,每添加新一层后,将在验证集上估计整个级联性能,如果没有显着性能增益,将终止训练过程. 最终输出特征维度由类别数及单层中分类单元数决定,而这些高级特征将用于后续评价模型的训练.
1.3 评价模型
后续分类算法(如支持向量机)被嵌入到特征选择过程中作为评价模型,目的是评价当前待选子集在特定模型中的综合表现性能,以搜索更合适的特征子集. 具体地,为选择出最适合支持向量机模型的分类特征,支持向量机将作为评价模型,以此来实现高针对性特征评价及选择. 评价过程与搜索过程交替进行,每次评价,将通过模型评价指标,如准确率、F1值等,估计预选特征子集性能. 该过程将重复至满足终止条件(如在随机搜索中采用预设的搜索次数作为终止条件),输出当前评价最高的特征子集及评价指标水平.
2 实验及分析
2.1 实验目的
特征选择算法目前广泛应用于医学信息处理领域,以帮助构建可解释性强、判别逻辑清晰的医疗辅助系统,实现可用化的风险评估、疾病判定与趋势预测. 因此,实验选择多个医疗数据验证本文提出的子集特征级联预学习封装法的实际效果.
考虑到封装法中特征搜索算法及评价模型的多样性,实验包括了3种搜索算法及2种常用分类器的组合,并分别应用常规封装法及子集特征级联预学习封装法构建共计12个判别模型,并进行对比分析,以说明本文方法可在保证分类效果的基础上选择出包含更少特征的更适特征子集,提高特征选择的效果.
2.2 实验数据
本实验采用两个真实医学信息数据集WDBC和ESR作为实验数据. WDBC是威斯康星诊断乳腺癌数据集,由Wolberg,Street和Olvi建立,包含30个描述性属性和一个二元分类变量的569个乳腺FNA病例,实验任务为乳腺癌辅助诊断(是否患有乳腺癌). Epileptic Seizure Recognition(ESR)是癫痫发作识别数据集,包含了采集自500人的周期记录性大脑活动数据,由178个特征进行描述,总计11 500个样本,以及针对每个样本的癫痫发作标识,分类任务为癫痫发作检测(是否处于癫痫发作期).
2.3 评价指标
本实验采用准确率和F1值来评价各模型的判别效果. 准确率考虑正类和负类分类正确的概率,体现了正负两个类别的总体分类效果,计算方式为
式中:TP为预测正确的正样本个数;TN为预测正确的负样本个数,FP为预测错误的负样本个数;FN为预测错误的正样本个数.
F1值是精确率和召回率的调和均值,相当于精确度和召回率的综合评价指标,计算方式为
式中:P为精确率;R为召回率,该评价指标将同时用于各封装法中,以及评价模型对预选特征子集性能的评价过程.
2.4 实验过程
特征搜索算法包括3种搜索算法,即贪婪搜索(greedy selection,GS)、粒子群优化(particle swarm optimization,PSO)以及随机搜索(random selection,RS);评价模型则选择了2种性能优异的分类算法,包括集成模型XGBoost及支持向量机(support vector machine,SVM).
实验过程使用10折交叉及网格法完成调参及验证. 通过交叉验证和网格法调节参数可以得到使测试数据准确性及泛化能力达到最佳状态的参数,一般常用10折交叉验证,10次结果的均值作为算法的结果,一定程度上可以减小过拟合及获得更多有效信息. 贪婪及随机搜索均采用特征逐个减少的策略搜索测试,粒子群算法局部学习因子0.4,全局因子0.8,惯性权重1.2,粒子数50,最大迭代30. 针对判别模型,在全特征数据集上调参并固定超参数,以稳定对比封装法及特征预学习效果,XGBoost中的学习率为0.3,树个数为1 000,最大深度6,叶子节点最小权重1,使用二项logistic损失;SVM使用RBF核,C=1,γ=1;级联森林最大层数3,每层4个单元,分别使用Random Forest Classifier,XGBClassifier,ExtraTree Classifier,Logistic Regression作为单元分类器,各分类器均使用默认参数.
2.5 实验结果及分析
表1展示了两个数据集上的多个对比实验结果,FR(feature refine)表示子集特征级联预学习模块. 其中,特征选择效果应由最终选取的特征数量及判别模型效果综合评判,故应同时关注特征数、准确率及F1.
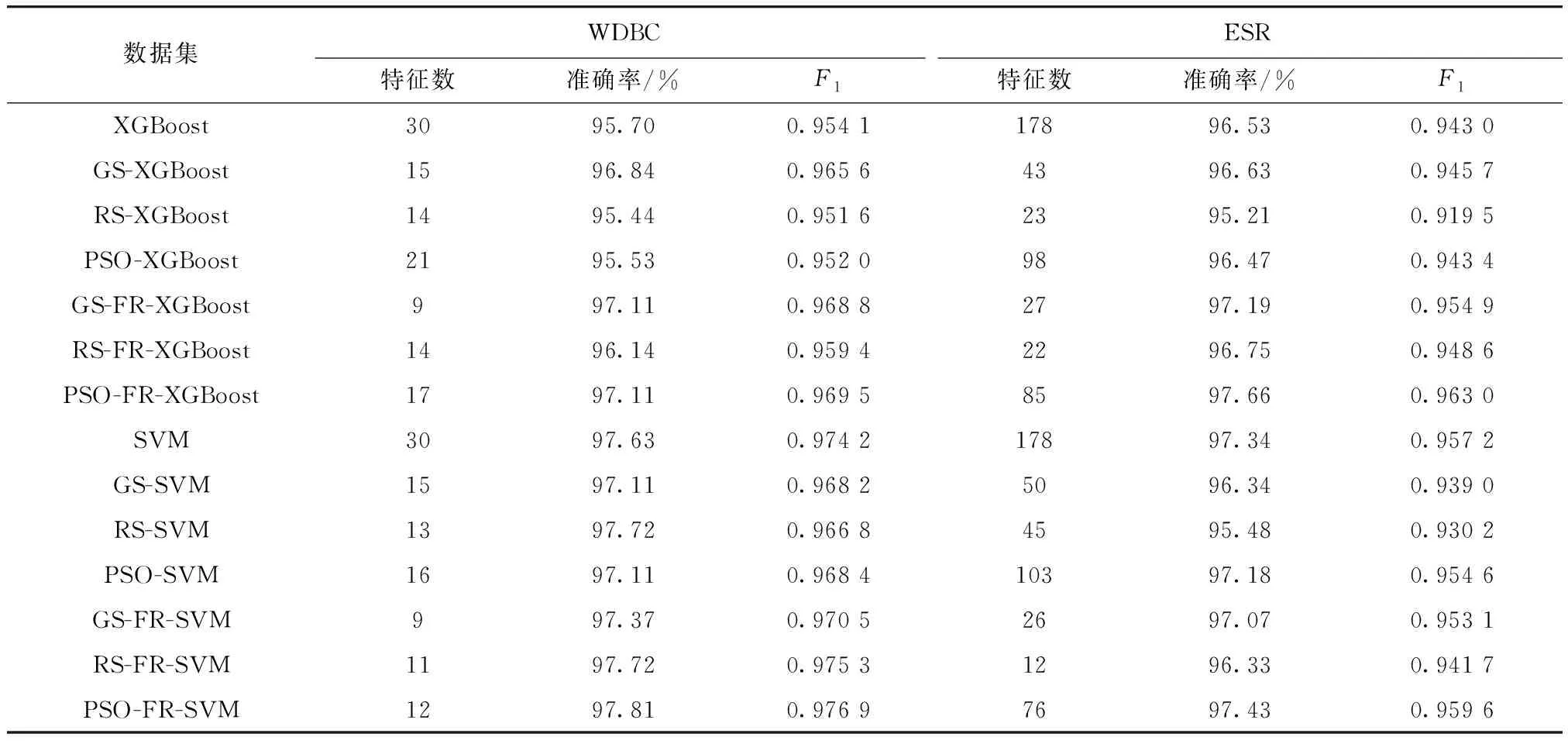
表1 对比实验结果
综上,结果显示,本文方法在各数据集与评价模型组合实验中,均能在基本保持、甚至提高判别模型准确率和F1值的情况下,进一步减少特征子集维度,提高了特征选择效果. 其中,使用贪婪搜索与子集特征级联预学习的封装法在多数(75%)情况下可获得最佳实验效果;同时,随机搜索与子集特征级联预学习的封装法也可获得较好的特征选择效果,且相比于贪婪搜索计算代价更小. 而添加了子集特征级联预学习后,特征数平均比一般封装法可再减少28%,有效说明了本文方法在上述实验中具有更好的特征选择效果.
3 结 论
本文提出的基于级联森林结构的子集特征预学习封装法,克服了由于评价模型通常将搜索算法筛选出的特征子集直接作为输入,导致算法对特征的利用和评估效果受限于评价模型的特征重构和学习能力,限制了对更适特征子集发现能力的问题. 具体而言,本文方法在一般封装法的特征搜索及评价模型间加入子集特征级联预学习,模块化地构建富含高信息密度的高级特征,以此降低评价模型模式识别难度,同时提高对特征子集综合性能的评价效果,且适用于基于各类搜索及评价算法的特征选择过程. 经实验证明,融合子集特征级联预学习的封装法可在维持甚至提高模型性能的基础上,显著降低特征数量.
猜你喜欢
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19 08:38:42
电子制作(2017年23期)2017-02-02 07:17:06
电子制作(2016年15期)2017-01-15 13:39:09
系统工程与电子技术(2016年2期)2016-04-16 05:16:51
西北工业大学学报(2015年4期)2016-01-19 03:31:47
电测与仪表(2015年15期)2015-04-12 00:43:48
河北科技大学学报(2015年5期)2015-03-11 16:16:37
中央民族大学学报(自然科学版)(2014年1期)2014-06-11 01:28:38
电测与仪表(2014年1期)2014-04-04 12:00:34
电测与仪表(2014年1期)2014-04-04 12:00:28
