
基于多智能体强化学习的分布式停电检修管控系统设计
2021-12-07 07:45齐蓬勃
电子设计工程 2021年23期
齐蓬勃,李 凡,高 雯
(国网固原供电公司,宁夏固原 756000)
电力系统需要兼顾发电、输电、变电、配电与用电等实施平衡的问题,这要求电力部门对电网内部的所有设备状态非常了解。我国的电网规模庞大,设备衰老与缺陷问题严重。而传统的电网停电检修管控系统较为粗旷,存在停电时间长、计划完成率低的问题。
当前电网故障智能诊断的研究方向主要是设计新的故障诊断模型,提高工程应用中的适应性和容错性,以及通过完善信息来源提高模型的诊断精准性。但电网故障诊断技术在工程应用中,仍存在一些问题:
1)诊断算法的适应性能力弱。由于现有处理技术中的信息采集方法不够完善,造成了信息具有较强的单一性。所以当操作方式发生改变或面对多种因素造成的复杂故障时,故障诊断算法的正确性就会急剧下降。
2)故障信息的获取与分析不完善。传统技术方案在检测到电源故障时,会将信息自动上传到控制中心而不进行任何处理,这可能导致控制中心服务器超负荷、数据包丢失或框架变形。
3)模型的容错性难以满足需求。例如,当一个或多个保护继电器(PR)和断路器(CB)不能正常工作时,故障判断模型未能正确判断出故障元素的数量和类型,模型需要妥善处理错误数据维持整体综合性能。
因此文中设计了一种基于多智能体强化学习的电网故障诊断模型,电网可以通过互联网将众多位于不同地理位置的计算机组成一台超级计算机,从而解决难以诊断的电力系统故障。
1 基于多智能体的系统构建
停电检修管理系统本质上是不稳定的,用数学可表达为环境生成函数f随时间的变化[1]。为了简化问题,文中基于近期观察的行为对环境生成函数f的结果进行建模。在每个时间步长t,有XH=(X1,…,Xt)。考虑到历史数据观测,尝试预测未知的Xt+1[2]。
优化求解漂移问题,有以下两种方案:
1)被动的解决方案,基于近期观察的样本持续更新模型[3]。
2)有效的解决方案,一旦模式改变,检测机制发现模型的预期行为发生了意外变化,就会触发新模型的生成[4]。
第二种方案能自适应地调整数据模型,对于实际模型有更优的预测能力。因此基于第二种方案建立多智能体强化学习的停电检修管控系统[5],如图1所示。

图1 MARL算法架构
MARL 体系结构包含3 个关键模块:
1)预测模块[6],该模块考虑了最近的有效历史值和其他可能影响环境的关键变量,以对未来行为进行估计[7]。
2)模式改变检测与匹配模块[8],用于检测预测模块未能提供对环境未来状态的合理估计的时间。这将触发一个新模型,该模型将以数据库中的最新观测结果为基础[9]。
3)基于强化学习的多智能体系统,其采用先前的数据作为输入以改善其在动态环境中的性能[10]。
从预测模块和模式改变检测与匹配模块中可以估算出环境未来的预期行为[11]。多智能体系统用于评估未来的行为,并依靠当前约束以最佳方式实现其目标。
在智能电网环境中,该模型可以为检修机构对未来需求提供良好的估算[12]。在该场景下,多智能体系统是检修机构,可以评估未来需求并尝试达到合理的供电需求,以达到合理的期望。同时多智能体系统追求将检修成本降至最低,根据实际经验可知,检修成本与实时定价机制中的电力需求成正比[13]。MARL 优化决策过程如图2 所示[14]。

图2 MARL优化决策过程
通过遵循强化学习方案将Q-Learning 与WLearning相结合,分别开发每个智能体,具体步骤如下:
①需要设计每个智能体的单一目标问题,要确保达到所需的收益,需要在优化结算时对智能体进行奖励。这可能会导致模型出现贪婪行为,解决方案如下:调整智能体在每个时间周期的行为直到可接受为止[15]。
②避免在高需求时期对不重要的智能体进行检修,将问题转变为一个多目标问题。系统优化的第二个目标是惩罚智能体的不当行为,若智能体决定在需求量高时被维修,则对智能体模型输入惩罚[16],这可以通过采用预测组件提供的有关环境的未来状态信息来实现。
本质上,预测组件通过额外的目标为智能体提供了一种赏罚机制。但这只是一个估计,不能保证任何确定性。若估计优,则智能体优化决策的结果较好;若估算结果不正确,则智能体优化决策的性能欠佳。通过实验可发现,良好的估计值比未估计值的优化结果好。
2 检修系统模块化软件设计
诸如Petri 网络和专家系统等检修系统均具有相同的前提,既获取了电网的拓扑结构,又可通过警报确定故障范围。因此该文使用相似的拓扑结构来设计模块化的检修系统软件架构,软件拓扑流程如图3所示。

图3 软件拓扑流程图
在第一部分中,RDF 策略编辑器将CIM-RDF 数据文件制成RDF 文件;软件在第二部分中使用CIMRDF 数据集成SVG 图形;软件在第三部分通过LINQ to XML 查询对电网的接线图进行格式化的元素,最终将该数据以矩阵形式进行储存。
此次选择的电网表格集成方式为网格计算法,网格计算法可视为最终还原模型与资源模型之间的中间件。具体实现方式如图4 所示。

图4 模型实现方式
此次选取网格计算技术的主流方法即基于OGSA 的Globus Toolkit 工具包,此次的网格系统利用Globus Toolkit 的优势来构建特定的中间件基础架构。在网格计算的基础上,使用多种故障诊断方法判断故障要素。此次建立的软件服务结构与常用的故障诊断方法如图5 所示。
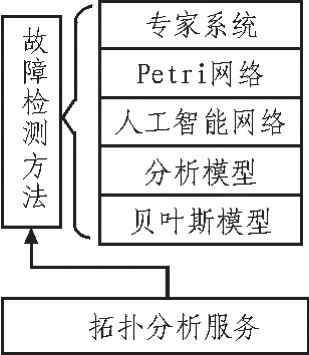
图5 软件服务结构与常用的故障诊断方法关系图
网络内部的每个变电站均提供准确的资源信息,因此所有的拓扑结构均较为准确。若变电站的部分结构发生更改,则整个拓扑将按时进行转换,诊断系统可以在最短时间内接收到相关信息。
在该文中,并行计算是软件服务的核心。不同的应用软件通过引擎驱动程序压缩到程序市场中,使用引擎驱动程序索引所有应用程序软件以实现寻找合适的解决方案。该软件通常包括MPICH2、LAPACK 等。
基于如下原因,选用消息传递接口(MPI)标准的MPICH2 驱动引擎:
1)MPICH2 提供多种MPI 实现,以有效支持不同的计算和通信平台,包括商业软件群、快速传输网络和定制高端计算系统。
2)MPICH2 引擎使用扩展度高的模块化设计,在MPI 中进行前沿研究。文中使用的LAPACK 软件包是用于数字线性代数的软件库,其提供了求解线性方程组和进行线性最小二乘法运算的计算工具。奇异值分解的计算也支持相关矩阵分解的计算,可以在经过调整的BLAS 架构中高精度、高速率运行。
由于现代计算机可以并行执行多个线程,因此对于众多计算机系统上的整体程序性能,此方法尤为有效。计算池库可以高效地分配异步任务,并可自定义动态的管理池,从而轻松将其集成到软件中。
该软件模型中,计算机集群是实现硬件集成的主要方法,其主要区别是紧密耦合各个节点。在设计系统中,考虑到可能存在网络中特定计算机需要在特定节点之间高频通信,因此针对特定计算机设计一个专用的同质节点共享网络。诸如MPI(消息传递接口)或PVM(并行虚拟机)之类的中间件,允许将计算群集程序移植到各种群集中。
3 实验验证
使用训练集大小为300 的电力数据库,对该停电检修管控软件进行验证。该模型实际上代表着一个规则库,该规则库由64 个规则组成(3 个输入变量分为4 个模糊子集)。假定所有模糊集(高斯激活函数)具有相同的扩展功能。从有功功率变压器和负载电流数据中提取的模糊模型最初由64 条规则组成,其中包含64 个线性参数(权重)和12 个非线性参数(模糊集的中心)。在省略这些规则后,模型的大小减小到27 条规则。
通过实验可以发现,若未假定电力变压器出现故障,则多次实验可发现系统模型的w1测试平均值等于38.713。而一个小的故障(与标称参数值的偏差)足以生成w1测试的输出,系统检测输出超过故障阈值的数倍,如图6 所示。

图6 故障x2 测试
就故障检测而言,数值结果表明,故障隔离的灵敏度方法在区分电力变压器参数集中所有39 个参数的故障参数方面较为有效。从图7 中可以看出,上述故障检测的成功率达到了99%以上。

图7 故障检测成功率实验
通过使用最大-最小故障隔离方法进行故障部件分离测试,以检测电力变压器模型的线性参数w1和非线性参数的变化。相关的结果在图8 中进行了描述,可以看出使用最大-最小故障隔离方法寻找变压器模型中的故障参数成功率也较高。

图8 最大-最小故障隔离法实验
该次在故障诊断方法的开发和测试中已考虑了测量噪声。在无故障的情况下,电力变压器的输出及其无故障模型的输出应仅与电力系统的传感器测量有关。输出差(残差)的序列遵循以0 为中心的高斯分布,而其加权平方遵循χ2分布。在电力系统参数变化的情况下,对残差信号的平均值和针对修改后的残差信号将向非零值偏移。这种偏移是由于变压器的结构(参数)变化,而不是存在测量噪声。
值得注意的是,该次系统使用的故障诊断方法(局部统计方法)适用于检测早期故障,即小的参数变化和电力变压器组件与其标称值的最小偏差。这是因为该次检测方法基于似然比的泰勒级数展开,该似然比是从被监视系统中获得的测量序列来计算的。在大多数实际系统中,变化是逐步漂移而不是直线漂移。这意味着其会缓慢前进,直至达到不可逆转的损坏程度。因此该系统能够检测到较小的参数变化(初期故障),可以在故障仍可管理或可逆的阶段作出控制动作,挽救系统。
4 结束语
文中使用多智能体强化学习技术,建立了一套分布式的停电检修管控系统。通过使用标准的电力系统模型,建立了智能的故障分离方法,可以在早期发现有关电力变压器故障的迹象,并在出现关键情况之前采取维修措施。所提出的故障检测方法可应用于电网的更关键部件的状态监视,且可帮助维持电力传输与分配系统的可靠运行。
猜你喜欢
一重技术(2021年5期)2022-01-18
数学大王·趣味逻辑(2021年11期)2021-12-03
当代工人(2019年24期)2019-01-17
电子制作(2016年19期)2016-08-24
河南电力(2016年5期)2016-02-06
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
河南电力(2015年5期)2015-06-08
河南电力(2015年5期)2015-06-08
中国石油石化(2015年12期)2015-04-20
振动、测试与诊断(2014年5期)2014-03-01
