
基于DCMM的集团级全域数据管理与共享平台研究与应用
2021-12-06 12:07段瑞永
电力大数据 2021年8期
段瑞永
(湖南大唐先一科技有限公司 北京100033)
对于当前很多企业大量数据分散在不同信息系统中且缺乏标准化,“数据烟囱”林立的现状[1-2],本文总结提炼了中国大唐集团有限公司(以下简称公司)基于《数据管理能力成熟度评估模型》(GB/T 36073-2018,简称DCMM)国家标准,系统梳理和全面分析数据现状、制定数据标准,统一“数据方言”,打通数据孤岛,实现集团级全域数据汇聚、双向实时交换等提升企业数据管理能力的主要做法;提出了建设数据汇聚共享交换平台的总体架构、技术架构,分析研究了在对不同数据源进行联合查询时采用统一SQL路由引擎屏蔽多种引擎SQL方言、实现统一SQL语法和统一入口技术,为提高接入数据质量、采用的基于边界阈值的数据校验技术,以及以促进用户扩大数据共享范围的数据分析技术等关键技术。
1 深度融合DCMM国家标准
1.1 DCMM数据管理能力成熟度评估模型介绍
DCMM是针对一个组织数据管理、应用能力的评估框架,通过数据能力成熟度模型,组织可以清楚地知道自身所处的发展阶段以及未来的发展方向。DCMM定义了数据战略、数据治理、数据架构、数据应用、数据安全、数据质量、数据标准和数据生存周期8个核心能力域及数据战略规划、数据战略实施、数据战略评估等28个能力项,并以组织、制度、流程和技术作为8个核心域的评价维度。DCMM评价维度及能力域如图1所示,DCMM所包含的8个能力域及28个能力项如表1所示。

表1 DCMM的8个能力域及28个能力项Tab.1 8 capability domains and 28 capability items for DCMM
DCMM将数据管理能力成熟度划分为5个等级,自低向高依次为初始级、受管理级、稳健级、量化管理级和优化级,不同等级代表企业数据管理和应用的成熟度水平不同。DCMM5个等级划分及主要特征如图2所示。

图2 DCMM等级划分及主要特征Fig.2 Classification and key features of DCMM
1.2 基于DCMM的做法
通过对业务部门、相关系统承建商等的调研访谈,调研问卷、资料研读等手段,归纳总结公司在数据管理,尤其是在数据汇聚共享交换方面存在的问题。根据DCMM数据管理能力域的具体要求,对公司规划、工程、生产、经营、海外、资本运营等业务领域和党建、决策、风险管控、法律、综合办公等管理事项进行详细梳理分析,并以此为基础,制定印发了数据共享管理规定、大数据指标手册(发电主要指标)、数据资产管理办法、数据安全管理办法等制度、标准。
主要的做法如下:
(1)明确基础数据来源,对于组织机构与人员、投资项目代码与名称、投产前后机组基础信息、生产运营等基础数据明确了唯一系统来源,其他系统逐步引用。
(2)建立数据管理责任制,理顺数据责任部门、使用部门、归口管理部门职责界面。数据责任部门指数据开发、提供、维护部门,对数据质量负主体责任;数据使用部门是根据授权使用数据的部门,对数据使用的合法合规及使用所造成的影响负责;数据归口管理部门为信息化部门,负责数据统一管理工作。
(3)建立数据质量缺陷报警机制,数据汇聚共享交换平台将用户发现或系统分析所得到的数据质量缺陷推送至各业务系统,由数据责任部门组织整改,建立数据质量管理常态化机制,提高数据的完整性、准确性、及时性。
(4)建立数据共享开发机制,数据使用部门可将新增共享数据需求报送至数据汇聚共享交换平台,数据责任部门确认后,由业务系统、数据汇聚共享交换平台技术人员进行数据配置或开发,上线后由数据使用部门确认是否满足需求。
2 建设数据汇聚共享交换平台
2.1 平台总体架构
平台的整体架构由数据采集层、数据存储层、数据分析层和平台展示4部分组成[3-8]。如图3所示。

图3 数据汇聚共享交换平台总体架构Fig.3 Overall architecture of data aggregation shared switching platform
(1)数据采集层。实现对各类数据的采集,同时对各类数据进行预处理。采集业务系统的各类监测数据,例如配置数据、性能数据、告警数据、日志数据,实现个性化数据采集设置,并且将收集到的监控数据储存在数据库中。
(2)数据存储层。提供数据集中处理中心,包括告警数据处理,性能数据处理,配置数据处理,日志数据处理,实现对不同格式的数据存储。
(3)数据分析层。实现对当前数据的实时关联分析和历史数据的统计分析,并建立相关分析模型。
(4)平台展示层。对实时指标数据通过各种图形进行可视化展示,同时与外部第三方应用进行信息集成与共享。
2.2 平台技术架构
系统采用大数据核心技术进行组建。外部数据通过采集代理,按照平台序列化规范,接入并存储到kafka中。Kafka中的数据通过数据加载引擎,存储到指定的数据存储中。系统支持关系型数据库、分布式检索引擎和分布式文件系统。同时,kafka中的数据可以对接Spark Streaming实时计算引擎,进行实时处理和分析。
系统具备统一资源管理,支持多种计算框架。对于存储后的数据,系统提供MapReduce和Spark两种计算框架,进行数据处理和分析。系统通过分布式检索引擎,对外提供结构化和半结构化数据检索;通过Presto、Hive、SparkSQL对外提供结构化和半结构化数据统计、关联等OLAP操作;通过Spark计算框架,提供机器学习等复杂数据分析算法[9-11]。平台的技术架构如图4所示。
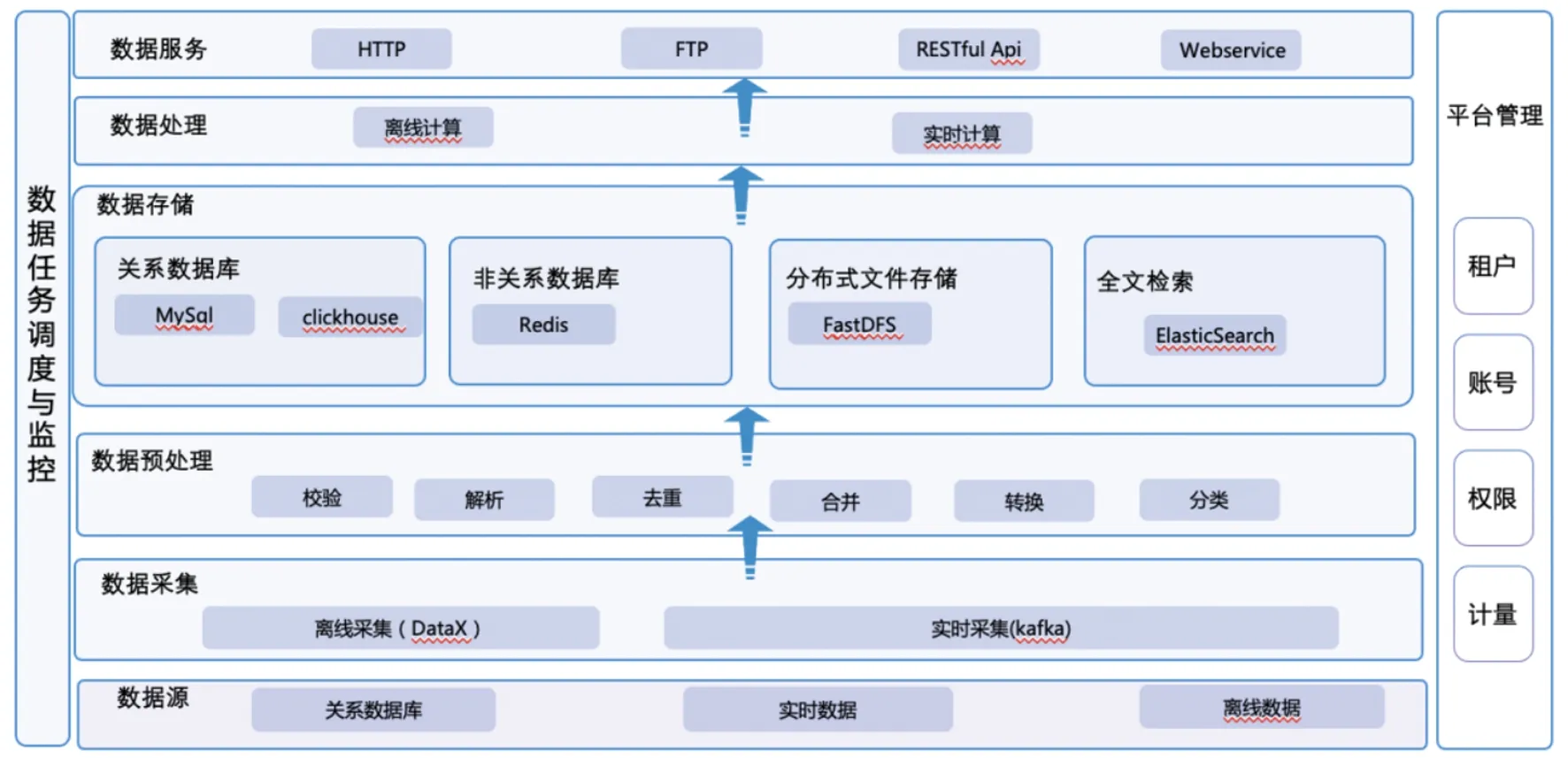
图4 数据汇聚共享交换平台技术架构Fig.4 Technology architecture of data aggregation sharing exchange platform
2.3 关键技术研究
2.3.1 统一SQL路由多引擎技术
当前,存储与管理数据的数据管理系统种类繁多,包括关系型数据库、NoSQL 数据库、文档数据库、key-value数据库、对象存储系统等,这些数据管理系统基于ANSI SQL逐渐发展成具有自身特点的SQL方言,并且差异愈加明显,因此,在对不同数据源进行联合查询时,就需要使用不同的客户端去连接不同的数据源,整个分析过程复杂、编程入口多、系统集成困难,对于涉及海量数据的数据分析将会异常困难。数据汇聚共享交换平台通过采用SQL多引擎路由技术实现了统一SQL语法和统一入口,屏蔽了多种引擎SQL方言切换,根据各引擎集群空闲负载情况、SQL复杂度及开销成本等路由到合适的引擎执行,为元数据管理,动态字段级血缘关系的数据地图提供了基础支撑[12-14]。SQL路由方案设计如图5所示。

图5 智能引擎:SQL路由方案设计架构Fig.5 Smart engine: design architecture of SQL routing scheme
统一SQL路由多引擎方案可通过改写Presto的词法文件、访问器模式、函数适配等完成。
(1)改写Presto词法文件
Presto语法是在标准SQL基础上实现的,通过对Presto词法文件源码语法进行改写使其满足HQL语法,作为统一SQL引擎的HQL词法文件。改写内容包括改写删除语法、添加clusterBy语法规则、添加Hive语法中TABLESAMPLE关键字取样的相关语法规则、添加lateral:LATERAL VIEW语法规则等方面内容。此处以添加clusterBy语法规则以满足完整的HQL语法的部分源码为示例,其SQL语句如下:
querySpecification
:SELECT setQuantifier selectItem (',' selectItem)*
(FROM relation (',' relation)*)
(WHERE where=booleanExpression)
(GROUP BY groupBy)
(HAVING having=booleanExpression)
(ORDER BY sortItem (',' sortItem)*)
(clusterBy)
(LIMIT limit=INTEGER_VALUE );
clusterBy语法规则:
clusterBy
:((CLUSTER BY expression (',' expression)*)| ((DISTRIBUTE BY expression (',' expression)*) (SORT BY sortItem (',' sortItem)*)) );
(2)实现访问器模式
先根据不同引擎语法实现不同的监听器逻辑或访问器逻辑多种语法翻译功能,从而实现统一SQL多引擎执行的支持。以Hive引擎为例,继承Hive Sql Base Base Visitor
(3)函数适配
通过预写映射模版,调换参数顺序,转换参数的数据类型,填充默认的参数,转换返回的数据类型来满足统一SQL引擎实现时解决的函数适配的问题。函数适配配置主要SQL语句如下:
//presto函数适配配置
multiFunc.put("date_add",Arrays.asList("date_add('day',p4,cast(p2 as date))"));
multiFunc.put("date_sub",Arrays.asList("date_add('day',-p4,cast(p2 as date))"));
multiFunc.put("add_months",Arrays.asList("date_add('month',p4,cast(p2 as date))"));
2.3.2 大数据控制集群技术
控制集群在设计上包含三大主要模块,分别是请求处理器(Worker)、调度器(Scheduler)和作业执行管理器(Executor),它们分别实现不同的逻辑[15]。
Worker处理所有的RESTful请求,它可以本地处理一些作业,如对用户空间、表、资源、作业等的管理;而对于需要执行分布式计算的作业,Worker会进一步把它提交给Scheduler处理。
Scheduler负责Instance的调度,它会维护一个Instance列表,并把Instance分解成各个Task,生成这些Task的工作流——DAG图(Directed Acyclic Graph,有向无环图),把可以运行的Task放到TaskPool中。此外,Scheduler还可以查询计算集群的资源状况。
Executor根据自身资源情况,如果资源满足,则会主动轮询Scheduler的TaskPool请求获取下一个Task,TaskPool会根据Task的优先级和计算集群的资源情况,把相应Task提交给Executor,Executor获取到Task后,生成计算层的分布式作业描述文件,提交给计算层,监控这些任务的运行状态,并定时把状态汇报给Scheduler。
简单地说,当用户提交一个作业请求时,接入层先进行用户认证,然后发送给控制层的Worker,Worker判断是否为同步请求,如果为同步请求,则本地执行并返回。如果是异步请求,Worker会先做些检查,生成InstanceID,把请求进一步发送给Scheduler,并返回给客户端。Scheduler把作业分解成各个Task,Executor主动轮询Scheduler,获取相应Task,提交给计算层执行,并定时将自己持有的Task的状态汇报给Scheduler。大数据计算任务调度过程如图6所示。

图6 大数据计算任务调度Fig.6 Big data computing task scheduling
2.3.3 跨集群数据复制技术
跨集群数据复制技术克服了数据的准实时跨集群复制、动态配置作业对跨集群数据的依赖,根据任务的优先级等合理管理和分配资源,为未来数据业务长期发展打下坚实的基础。跨集群数据复制主要具有以下优点。
(1)突破了单集群的数据存储上限。由于目前主流分布式系统Master/Slave的结构,单集群受限于Master的内存和处理能力上限,而现在数据可以存储在多个集群上,不再受单集群的限制。
(2)可以实现多机房数据容灾,将来可以动态的跨机房备份重要数据。
(3)实现跨数据中心动态负载均衡,将热点集群上的数据和作业动态迁移到空闲集群,缓解热点集群的压力,提高空闲集群的使用率。
(4)对于响应速度要求比较高的请求,可以在多个集群同时调度这个作业,将响应最快的请求返回给用户。
2.3.4 基于边界阈值的数据校验技术
数据汇聚共享交换平台将众多相关业务系统数据统一汇聚进行共享管理,以便提供全方位、全生命周期的数据共享。只是在当前,由于复杂的数据来源和系统间采用的统计口径不一,以及数据汇聚过程中可能存在的数据转换与处理问题,所以需要对接入数据进行适当的校验,以保证数据的可靠性和准确性。结合电力数据专业特性,并考虑海量数据的校验效率,提出通过阈值校验实现多种数据的有效汇聚[16-20]。
电力数据的特性使得相关数据通常具有合理有效的边界范围,比如电站的发电出力具有非负性,且一般小于装机容量,部分特殊情形会超出装机,但幅度不会太大;再如机组的发电流量应该小于等于其最大过流能力;针对这类数据,可以预先定义合理的边界范围阈值进行校验,并对超限数据进行异常预警和相应的处理。具体的校验公式如下。

(1)

2.3.5 以促进用户扩大数据共享范围的数据分析
技术
数据汇聚共享交换平台建设初期,根据需求,梳理汇总了近万个数据指标,并由多个业务应用系统汇聚至数据共享交换平台,出于各种理由,在平台上线应用时,仅开放共享不到5000个指标,一些相对重要的生产经营指标也没有实现完全共享交换,个别部门“本位主义”思想严重影响了数据的深度应用,致使数据汇聚后再次成为另一种形式的数据烟囱。为了解决这个问题,公司从管理上出台了相关管理规定,从技术上基于贝叶斯平均法计算热门搜索指标Top10(每周)并以词云图的形式展现给所有用户,并以数据质量周报的形式呈公司领导、各部门阅。管理手段的约束以及技术手段的倒逼,让这些部门认识并感受到数据管理、数据质量、数据应用的重要性,并逐步同意共享了原先不同意共享的数据指标,扩大了数据共享指标的范围。贝叶斯平均法如公式(2)所示。
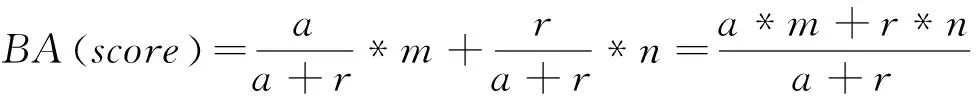
(2)
公式(2)中BA(score)表示指标的点击搜索热度,值越大,表明热度越高。a表示指标点击量,m表示指标点击用户数,r表示指标平均点击量,n表示历史点击平均用户数。
通过点击率、正样本频次等算法对大量的用户行为进行偏好类统计,进行用户精准画像设计。点击率算法如公式(3)所示。
(3)
公式(3)中,m和C是平滑系数。通过用户精准画像设计,使用户体验度大幅提升,更加促进了各部门数据汇聚共享交换的积极性,进一步扩大了数据共享的范围[21-24]。
3 平台实施应用
3.1 平台实施
数据汇聚共享交换平台实施过程当中,除了平台前后端的分离部署配置,达到数据字段级别的权限配置等实施工作以外。平台的实施工作着重在与多个业务系统的数据集成上展开[25]。
从采集的数据量、数据频率要求、安全稳定性等多种因素考虑,确定了从OA系统接入数据采用webservice方式,从财务、物资、项目、燃料等业务系统接入数据采用JDBC方式;向数字化作战室、生产调度中心等系统输出数据采用webAPI方式;与国资委数据交互按照要求采用双向SM2方式加密上传下达db文件至央企前置机。平台对所有接口任务开发了可视化的界面并内含异常告警配置,实时掌握数据动态[26-28]。
3.2 平台应用
平台在数据存储与管理方面采用了Click House+MySQL模式。ClickHouse是基于列存储的数据库,比传统行式存储数据库速度更快,性能更好,长于实时数据分析,用于海量业务数据的存储分析。MySQL是传统的基于行存储的数据库,系统运维操作相对简单,人机交互体验更加友好,用于流程、权限配置等系统本身数据的存储管理。Click House+MySQL模式兼顾了系统性能及系统运维两个方面,提高了普通用户和系统运维人员的使用体验。
目前,数据汇聚共享交换平台已在公司总部及下属100余家企业上线应用,应用效果良好。截至目前平台已汇聚近4000万条数据,满足了公司总部各部门及下属企业的数据共享需求,并与数字化作战室、生产调度中心等十几个应用系统实现实时双向交互。大额资金、三重一大、第三方服务机构数据通过平台与国资委统一数据采集平台进行对接。9000多件专利、4000多项成果论文、400多项国行标供系统企业查看学习。
4 总结
当前,数据是企业的核心资产已是共识,积极推动数据的汇聚共享交换、加强基于大数据的分析应用已是各大企业正在实施或计划实施的重要工作。本文所提出的集团级全域数据管理的相关做法、数据汇聚共享交换平台关键技术的研究与应用,对于大型企业集团数据管理、数据汇聚共享交换、数据中台的建设,具有较大的借鉴参考价值。
猜你喜欢
江苏安全生产(2022年8期)2022-11-01
汽车实用技术(2022年10期)2022-06-09
汽车实用技术(2022年5期)2022-04-02
智能制造(2021年4期)2021-11-04
纺织科学研究(2021年6期)2021-07-15
房地产导刊(2020年12期)2021-01-14
人民交通(2020年4期)2020-04-16
军事运筹与系统工程(2019年4期)2019-09-11
信息化建设(2019年2期)2019-03-27
智富时代(2018年10期)2018-01-30
