
逐时降雨的类条件概率密度分区比较与拟合函数初探
2021-12-04 10:44沈铁元刘静向怡衡祁海霞殷志远王俊超
暴雨灾害 2021年6期
沈铁元,刘静,向怡衡,祁海霞,殷志远,王俊超
(1.中国气象局武汉暴雨研究所,暴雨监测预警湖北省重点实验室,武汉 430205;2.湖北省气象服务中心,武汉 430205)
引 言
降雨的概率密度(Probability density,简记为PD)函数能反映降雨的气候与区域特征以及实况降水中较少观测到的强降水发生的可能性与分布,为此20世纪一些学者基于日降雨观测开展了研究。张耀存和丁裕国(1991)建立了降雨量概率分布的通用模式;丁裕国(1994)等利用日降雨观测资料验证了气候降水量频数分布的最佳模式,并理论证明了降雨量频数(时间域、空间域)的最可几分布为Γ分布,由此构建了较完备的降雨概率密度理论体系,拟合函数普适性强,拟合参数物理意义明晰,并由此带来计算与分析上的便利,但是这种采用极大似然估计法的优势并不在于拟合精度。丁裕国等(2009)介绍了气候概率分布理论及其应用研究增加的新内涵与进展;魏锋等(2005)基于概率加权、Ding等(2008)采用广义帕雷托分布(GPD)和广义极值分布(GEV)对极端降水时空分布进行模拟。类似研究工作的进展推进了其应用领域的拓展,使其在分析与预报极端强降雨与洪水、计算设计暴雨雨型与暴雨强度公式、分析自动雨量站观测数据质量等方面成为了一种重要工具。另外,Dijkvan等(2004)应用其来建立径流与土壤侵蚀模型;向小龙等(2020)将其应用于建立滑坡失稳概率模型;周建中等(2020)建立的水文预报方法及系统中使用了强降雨和弱降雨下的后验概率密度函数;Zou等(2014)利用其来检验区域气候模式中积云参数化方案的优化效果;Ogarekpe等(2020)利用其来检验了16个全球环流模式的月降雨模拟结果;陈爱军等(2018)将其应用于评估卫星降水估计精度;沈艳等(2013)将其应用于评估降水量融合产品质量检验。近年来一些研究使用概率密度匹配法来改进定量降雨估算结果,如宇婧婧等(2013)改进的卫星估算降水方法、Seppo等(2016)建立的雷达估算降雨模型、潘旸等(2018)介绍的高分辨率三源融合降水产品业务系统。
PD应用的拓展又对其研究工作提出了更高的需求,当前降雨观测时空分辨率得到了大幅提高,以日降雨资料得出的研究结果需要以新的海量资料来发展完善。随着我国自动气象站逐步增加,利用逐时降雨有了大量研究,其中涉及概率密度或(和)概率分布的相对较少,姚莉等(2009)基于我国485站14 a逐时降雨分析了六个雨强级别的年均发生频率、日变化和极端降水等,指出百年一遇的逐时降雨量达100~150 mm,高值区主要在东南沿海一带。其中研究对象虽是降雨发生频率(频次),但分别针对六个雨强级别来分析,已具备逐时降雨概率密度的雏形。田付友等(2014)用518个站点18年暖季的小时降水资料,用Γ函数估算概率密度分布,给出了超过阈值的降水累积概率分布,认为极端小时降水的阈值自西北向东南增大,华南沿海和海南岛西北部为短时强降水最容易出现的区域。赵琳娜等(2017)用中国东南818个国家站33 a夏季小时降水资料以及台风路径观测数据分离出台风降水后拟合Gamma概率密度函数分布参数,得到台风小时降水总的降水概率分布特征以及不同台风影响距离和台风强度影响下超过给定阈值的降水累积概率分布与极端降水阈值。王彬雁等(2018)用皮尔逊Ⅲ型概率分布模型对四川省测站降水进行拟合,根据降水累积概率空间分布的拟合函数,计算了最大小时降水量的概率分布及其重现期极值。这些研究承袭了极大似然估计法使用Gamma函数(或其变形)来拟合,均未给出拟合优度(或确定系数)、均方差之类的拟合统计量。
对于逐时降雨的概率密度(或分布),极端强降雨的发生是小概率事件,样本数量非常有限,降雨概率密度的研究势必受到观测资料年限的限制,相关研究较难深入开展,致使目前降雨概率密度尚难以得到精细化的结果,其函数拟合精度仍需提高、降雨等级需要细化,特别是对强降雨段(或小概率降雨段、长重现期降雨段)有待提高。当前降雨观测条件的改善,同时先进的数学拟合技术也大为改观,为提高拟合精度提供了有力支撑,势必推动降雨概率密度研究向精细化方向发展,并为相关应用奠定更科学的数理基础。精细化研究包括七个发展方向:细化分类;提高拟合精度;增强拟合函数与方法普适性;细分降雨等级;延展至更强降雨;结合地理地形筛选降雨结构特征参数及其时空分布的影响因子分析;研究联合概率密度分布,联合的对象诸如雷达回波、云反射因子、各高度层温压湿风等气象要素与降雨。其中“细化分类”这一方向便牵出了降雨的类条件概率密度(CCPD),参考边肇祺(2000)关于类条件概率密度的概念,定义降雨的类条件概率密度为在某降雨定条件或类别状态下的概率密度,是概率密度下的次级“小”概念,其定义域是降雨概率密度定义域的子域,其在定义域内的积分为1。定条件是指有雨、连续性降雨这样的条件(另外还可设定为强降雨、夏雨、夜雨、台风降雨、暖季降雨等);类别状态指降雨历时、无降雨历时这样的类别。降雨的类条件概率密度在其函数定义域内与降雨概率密度存在倍率关系。引入这一概念是为了对特定条件或类别开展分析研究,从而能够更深入细致地去探讨降雨结构特征及地域差异。以往也曾有过相关研究,但均使用概率分布(或概率密度)来表述,致使大小概念混用,该概念的引入能梳理相关概念并分类归纳,建议逐步规范以避免大小概念混用。
本文在我国洪涝灾害主要发生区内以空间开窗口方式选择六个分区,细分四十二个降雨等级,统计逐时降雨量、逐时连续降雨过程雨量、逐时连续降雨历时等三类类条件概率密度进行分区比较,选择一种与以往研究不同的拟合方法和拟合函数开展拟合研究,从而得到高精度的降雨类条件概率密度算法,以期为定量降雨估算中概率密度匹配法等提供新的、更细致可靠的数据来源。
1 资料与方法
1.1 研究区域
为了更好地了解我国长江梅雨锋地带上的降雨特征,沿30°N选取四个经纬度长方形区域为研究对象,同时在其南北各选取了一个区域来与之进行比较分析。图1给出了六个分区及所处地理位置示意图。图中分区编号I、II、III、IV、V、VI按降雨频率降序排列,前五个分区年均降水量大于1 000 mm,VI区最小、不足800 mm。I、II、III、IV区同在30°N线上。I区位于四川雅安附近,由于其周边地形坡降大,为避免代表性的减弱而选取了1°×0.6°相对较小的范围;V区范围2.6°×2.3°,包含海南全岛;II区位于杭州湾以西,III区位于鄂西南山区,IV区位于江汉平原南部,VI区位于华北平原、黄河流域内,这四个分区经纬度范围均为2°×1°。

图1 研究选定的六个分区(红色方框内是分区编号)方框内及所处地理位置示意图Fig.1 The research selected six sub-regions(red boxes with division number in the boxes)and schematic diagram of their geographical location.
1.2 资料说明
本文使用了六个分区内近1700个自动降雨观测站(含国家站和区域站)近年的逐时降雨观测资料(以下简称HR),其中V区使用了海南岛内21个国家站的降雨资料,为保障统计样本数量,故选取的范围比其它五个分区大;其余五个分区使用了国家站和区域站资料。表1给出了六个分区降雨资料的基本情况及逐时降雨频率,从中可见,各分区降雨统计资料平均年限并不相同,其原因是为了更充分地利用现有数据资料。选取2020年10月29日00时(北京时,下同)为所有资料的截止时间,而资料的起始年份根据站点资料入库时间来定,起始时间与截止时间的月、日、时相同,使资料时间长度保持为整年,且尽可能保障使用的资料年限最长,在资料年限短于4 a时观测站资料全被弃用,故表1中参与统计的测站数要小于区域内测站数。从表中还可见,所有资料的缺测率均低于40‰,保障了资料的完整性及统计结果的可信度。
表1中还给出了逐时降雨频率。为了避免与天气预报中公众已普遍接受的“降雨概率”概念上冲突或混淆,本文选用“降雨频率”这一概念,而对于概率密度中“概率”一词仍按惯例沿用不随之调整。从表1可见,排名前四位均在30°N线上。雅安由于受到特定地形影响而最大,海南岛即使处于低纬且受海洋性气候影响也包含一些山地,而其降雨频率居然比30°N线上各分区小。六个分区逐时降雨频率差别大,I区近乎VI区的4倍,即使同在30°N线上,I区是IV区的1.74倍。
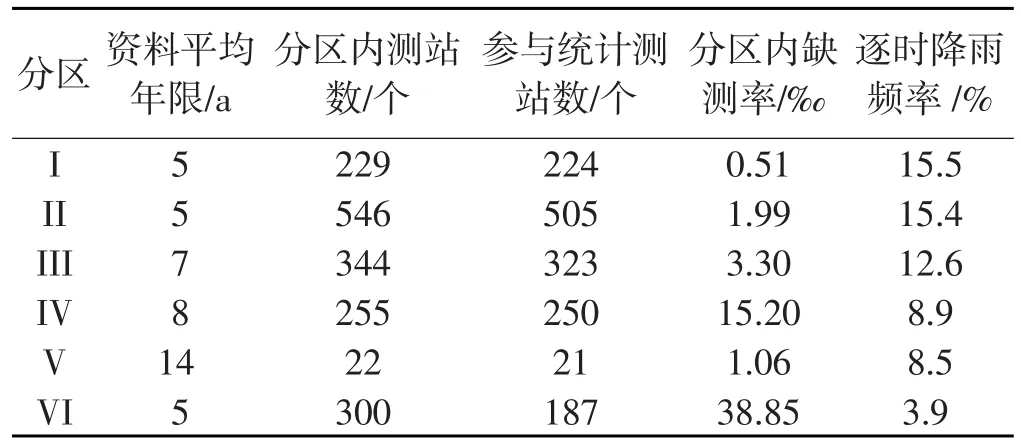
表1 研究选定的六个分区降雨资料基本情况及逐时降雨频率Table 1 Basic information of rainfall data in research selected six sub-regions and frequency of hourly rainfall.
1.3 分析方法
虽然自动雨量站观测年限有限,但如果以空间换取时间,改变原来单站进行统计的方法,在相对较小的分区内多站并合来开展统计,能使样本数量得到大幅提升,才有可能实现细分降雨等级,提高在强降雨区段概率密度拟合精度,契合PD研究精细化的发展方向。这种以空间换取时间的方式必须满足在分区内地理、气候特征相同,临近站降雨特征相近。
针对上述六个分区,统计逐时降雨、逐时连续降雨的频率;同时细分降雨等级,对各降雨等级分别统计三类(逐时降雨量、逐时连续降雨过程雨量、逐时连续降雨历时)类条件概率密度。通过六个分区之间的比较,可以分析降雨与降雨结构的地域性差异,有利于明晰类条件概率密度与概率密度的共性与差异性。以下简要介绍降雨等级的划分以及统计特征量、计算特征量。
1.3.1 降雨等级的划分
依据降雨数据的样本量根据经验自行细分了四十二个降雨等级进行统计,原则是尽量使相邻等级间统计值变化有序、经验函数上下起伏跳跃小、尽量避免统计频次为0的区间。表2分别给出了这四十二个降雨等级的区间中值、区间长度、区间上限,前二十四等级以降雨观测的分辨率0.1 mm为间隔来划分,区间长度也为0.1 mm,后十八个降雨等级由于发生频次越来越小,随降雨强度变强区间长度逐步加大,其中对于短时强降雨(Rain≥20 mm)仅分了七个等级。

表2 四十二个降雨等级的划分表2 Classification of 42 rainfall grades.
1.3.2 各分区各等级下降雨发生频次统计
针对六个分区统计各区内观测次数、缺测次数、降雨频次、逐时连续降雨场频次。逐时连续降雨(HCR)是与孤立逐时降雨相对的,孤立逐时降雨指前后时次均无降雨的单独小时降雨,HCR指在逐时降雨观测中连续多个小时中降雨量均不为0的降雨过程。再针对各分区(公式中用M代替,分别取I、II、III、IV、V、VI)分别统计降雨量落在各降雨等级(N)下的次数;然后对各分区分别统计HCR过程雨量落在各降雨等级N下的次数,统计中先按各站点计数,后对分区内所有站点累计;最后对各分区分别统计逐时连续降雨历时(HoCR)在2~42 h内各整数时数上的场次数,历时在42 h以上降雨频率太小而没参与统计。
1.3.3 降雨频率、类概率密度、类条件概率密度经验函数的计算
根据上面统计的频次便可以计算频率、概率密度、类条件概率密度。频率分两类,PD、CCPD分别分三类,通过计算分别得出PD、CCPD在各分区M等级N(或连续历时)下的概率质量,便可得到三类PD、CCPD的经验函数。下面需要进行简单计算的物理量仅列示了概念,公式略。
(1)逐时降雨频率、逐时连续降雨频率
通过上面统计频次就可以得到各分区降雨频率、逐时连续降雨频率。用PHR(M)表示各分区逐时降雨频率,用PCR(M)表示各分区逐时连续降雨频率。连续降雨频率可以按场次数、时数两种方法来统计,由于两者可以依据平均历时相互转化,故在第二、三类CCPD计算分析中选择按场次来统计,而非时数。
分区内各降雨等级下的降雨频次与总的降雨频次比值再除以降雨等级的区间长度得到HR类的CCPD,是在各降雨等级中值附近CCPD的近似值,于是便有了第一类CCPD的经验函数,在CCPD定义域类该CCPD与PHR(M)的乘积是HR类PD。第二类CCPD与之类似,第三类CCPD由于自变量是降雨历时,间隔为1 h,所以根据各历时下的降雨场次数除以总的逐时连续降雨频次而得到。
(2)类条件概率密度(CCPD)
第一类:逐时雨量类的类条件概率密度HRCCPD(以下简称CCPD1),定义域是[0.1,∞);
第二类:逐时连续降雨过程雨量类的类条件概率密度HCRCCPD(以下简称CCPD2),定义域是[0.2,∞);
第三类:逐时连续降雨历时类的类条件概率密度HoCRCCPD(以下简称CCPD3),定义域是[2,∞)。
下文中CCPD1、CCPD2单位为mm-1,CCPD3单位为h-1。
(3)类概率密度
与上面三类CCPD对应的PD,分别记为HRPD、HCRPD、HoCRPD,类似简记为PD1、PD2、PD3。
PD1是CCPD1的PHR倍率关系,当然两者间定义域是有差别的,前者是[0,∞),后者是[0.1,∞)。第一类概率密度PD1自变量是雨量,以前的研究中均以“降雨概率密度”称之,为了便于区分,建议分类,让相关大小概念规范化。
PD2是指HCR过程雨量落在某一单位降雨区间的发生频率,CCPD2是仅针对有HCR发生(定义域缩小为[0.2,∞))才进行统计的过程雨量落在某一单位降雨区间的发生频率,因此,PD2是CCPD2的PCR倍率关系。
PD3指HCR历时在某个小时数下的发生频率,CCPD3是仅针对HCR进行统计的降雨历时在某个小时数下的发生频率,其分布图中横坐标与CCPD2不同,由逐时连续降雨量变成了连续历时(即持续时数),PD3是CCPD3的PCR倍率关系。
2 分区之间对比分析
2.1 第一类类条件概率密度CCPD1
图2给出了六个分区中的第一类概率密度PD1与第一类类条件概率密度CCPD1。为了便于识别强降雨段曲线结构与趋势及分辨各曲线间微小差别,图中采用了双y轴坐标“一线两画”方式,对每个分区在同一张图上同时给出y及ln(y)随x坐标变化的两条曲线;x坐标是降雨等级中值Rain的对数ln(Rain),x=0、1、2、3、4、5时分别对应Rain≈1、2.7、7.5、20、55、150 mm。在x>0时,CCPD1六条曲线黏合在一起,需要从右边曲线簇才能区分辨认,在x<1时,ln(CCPD1)六条曲线黏合在一起,需要从左边曲线簇才能区分辨认。图中为了方便辨识区分,以曲线的方式给出,而没有采用在四十二个降雨等级上给出离散数据点的绘图方式。从图2可见,CCPD1、PD1曲线均是单调凸(斜率递增)减函数,弱降雨段递减快,强降雨段递减较慢;在双对数图上曲线均是单调凹减函数,弱降雨段递减慢,强降雨段递减较快。六根PD1曲线排列稀疏,而六根CCPD1曲线排列变得密集,并存在相互穿插黏合的现象。ln(PD1)、ln(CCPD1)曲线也是如此。原因在于PD1与降雨频率成正比,而CCPD1是用来表示在有雨条件下不同量级降雨发生可能性的分布情况,即强、弱降雨出现多少的配置关系,与降雨频率无关。六个分区降雨频率的差别大(参见表1),降雨的地域间差异性会通过降雨频率传递给PD1,导致图2a中PD1曲线间差距大,V、VI两区差别最大时能超8倍;CCPD1统计计算中抛开了无降雨的时间,不受降雨频率影响,部分削弱了地理地形影响降雨结构的主要功效,更利于表征降雨的固有结构特征,故在图2b中六根曲线较PD1差距小。由此可以说明:虽然对同一地域PD1、CCPD1均有反映降雨结构的能力,但在地域差异性分析时两者相比较,PD1受地理地形影响大,受降雨频率多少所左右,其能力将被削弱,更侧重于用来表征指定降雨出现的可能性;CCPD1受地理地形影响相对小,反映强、弱降雨出现的配比情况更直截了当,更侧重于用来反映降雨结构性特征,以及降雨结构性地域差异比较,尤其在表征强降雨出现难易程度的地域差异性上比PD1效果会更明显。
在图2b中V分区的ln(CCPD1)曲线与其他区表现出明显的差异性,即横坐标1.1~4.7区间内(Rain在3~100 mm区间)PD1、CCPD1明显大于其他各区,表明了V分区与其它区降雨结构性差异。海南岛由于属热带季风气候,四面环海,水汽充沛、热动力过程强烈等诸多降雨有利条件,是导致其CCPD1分布独特的原因。V分区的这种持有降雨结构在图2a中表现并不很突出,是由于受到海南岛降雨频率不高因素的干扰。

图2 研究选定的六个分区中的第一类概率密度PD1(a)和第一类类条件概率密度CCPD1(b)(a:左边曲线簇对应左边y轴PD1,右边曲线簇对应右边y轴ln(PD1);b:左边曲线簇对应左边y轴CCPD1,右边曲线簇对应右边y轴ln(CCPD1))Fig.2 The first class(a)PD1 and(b)first CCPD1 in research selected six sub-regions(a:The left curve cluster corresponds to the left y-axis PD1,and the right curve cluster corresponds to the right y-axis ln(PD1).b:Left curve cluster corresponds to left y-axis CCPD1,right curve cluster corresponds to right y-axis ln(CCPD1)).
图2a中蓝色线代表分区I(雅安),在横坐标大于3时(Rain>20 mm)PD1明显大于30°N线上的其他三区;图2b中其CCPD1相比30°N其他区呈现两端大、中间小的分布特征:起点高(指弱降雨等级下CCPD1高)但递减快,在横坐标0.3~2.5区间(1.3 mm

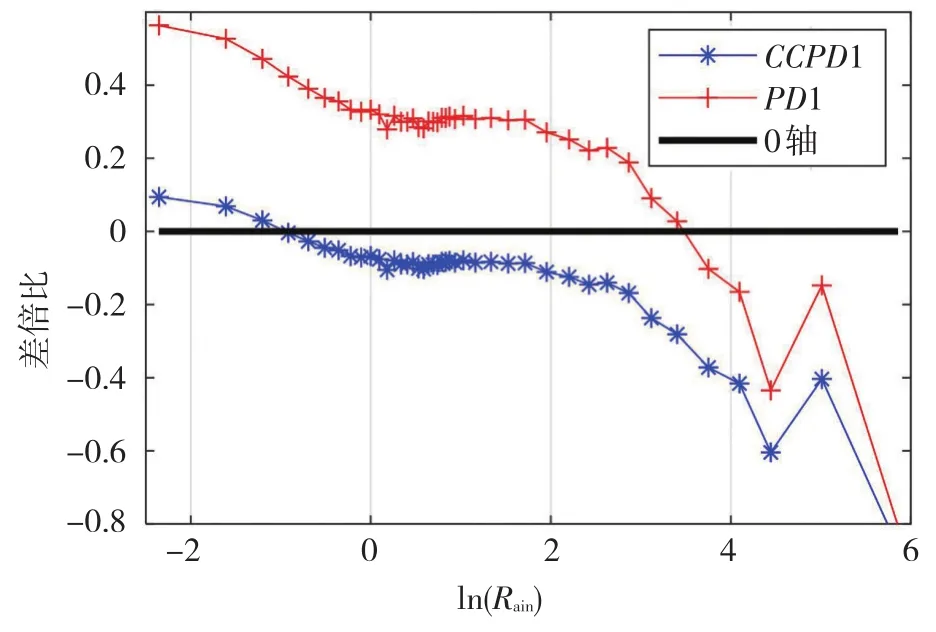
图3 PD1、CCPD1 III与IV分区的差倍比Fig.3 Difference ratio of PD1 and CCPD1 comparing III with IV sub-regions.
2.2 第二类类条件概率密度CCPD2
表3给出了六个分区HCR的有关频率统计值,从中可见,I、II分区接近且最大,VI分区位置偏北最小;III、IV分区处于中间位置但差距仍较大,III分区HCR频率是IV分区的1.45倍;HCR海南岛最小为4.29 h,其他五个区接近,II分区最大,为6 h。如果以场次记,孤立降雨与逐时连续降雨近乎各占一半,而按降雨时数记,孤立降雨占总降雨时数不足2成,逐时连续降雨占比超8成,I分区(雅安)逐时连续降雨占比最大,为87%;海南岛孤立性降雨占比最大,逐时连续降雨占比最小,逐时连续降雨历时最短。

表3 逐时连续降雨有关频率统计值Table 3 Frequency statistical values of HCR.
图4a、b分别给出了六个分区的PD2、CCPD2,也采用了双y轴一线两画方式。从中可见,PD2、CCPD2曲线是单调凸减函数,在双对数图上曲线是单调凹减函数;I分区CCPD2相对其它区走势类似其CCPD1,存在两端大、中间小的分布特征;III、IV两区HCR频率差别较大(按时数记分别是0.107和0.076),两区HCR频率比值与HR频率的比值(1.43)相当,山区比平原大1.45倍;PD2山区总体大于平原,且随降雨等级加大差距缩小至趋同,并没出现类似PD1平原反超山区的现象;V分区海南岛CCPD2起点最低,但10 mm以上降雨CCPD2比其它区大,其PD2在强降雨段较大,但由于受到HCR频率干扰而没有CCPD2表现突出;VI分区由于地理位置偏北,PD1、PD2比其它区小,与其他五个分区差别大,但CCPD1、CCPD2与30°N线上四个分区差别小。
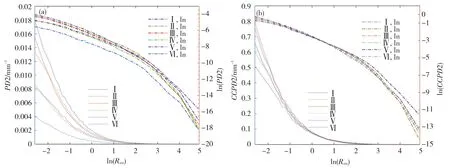
图4 研究选定的六个分区的第二类概率密度PD2(a)和第二类类条件概率密度CCPD2(b)(a:左边曲线簇对应左y轴PD2,右边曲线簇对应右y轴ln(PD2);b:左边曲线簇对应左y轴CCPD2,右边曲线簇对应右y轴ln(CCPD2))Fig.4 The 2nd class(a)PD2 and(b)CCPD2 of research selected six sub-regions(a:The left curve cluster corresponds to the left y-axis PD2,and the right curve cluster corresponds to the right y-axis ln(PD2).b:Left curve cluster corresponds to left y-axis CCPD2,right curve cluster corresponds to right y-axis ln(CCPD2)).
2.3 第三类类条件概率密度CCPD3
图5给出I、V分区的第三类条件概率密度。除V分区外的其他五个分区曲线较接近、曲线高度叠合,所以图中把I分区选作代表。各分区CCPD3也是单调凸减函数;海南岛CCPD3偏态性强,即起点高、递减率大,HCR历时为2 h的CCPD3比其它区高出1/3强,历时为4 h及其后CCPD3便低于其他区了,历时为13 h的相对差别最大(低1.6倍)。海南岛CCPD3偏态性强的降雨历时分布结构,是造成表3中海南岛孤立降雨时数占比大、连续降雨历时短这种降雨特征的原因。

图5 I、V分区的第三类条件概率密度CCPD3(浅蓝色横线代表0轴)Fig.5 The 3rd class conditional probability density of I and V subregions(The light blue horizontal line is the 0 axis).
通过上面三类CCPD、PD的分区比较可知:三类CCPD、PD曲线均是单调凸减函数,在双对数图上曲线均是单调凹减函数;逐时降雨频率各分区间差别大,导致PD差别也大,而三类CCPD分区间差别小,在曲线图上难以分辨;对同一地域PD、CCPD均有反映降雨结构的能力,对不同地域,PD受降雨频率影响致其能力被削弱,更侧重于用来表征指定降雨出现的可能性,而CCPD1反映强、弱降雨出现的配比情况更直截了当,更侧重于用来反映降雨结构性特征,以及降雨结构性地域差异性比较,尤其在表征强降雨出现难易程度的地域差异性上比PD1效果会更明显。
雅安降雨频率是30°N线上四个分区中最大的,其CCPD1、CCPD2相对其它分区呈现两端大、中间小的格局,特别是极端短时强降雨CCPD1比其他区高。位置临近的III、IV分区,由于山地与平原的地理差别,导致降雨频率两区差距大,山区地形致降雨频率增加,且主要是弱降雨的增加,强降雨反倒有所减少,对于非特殊地形结构下的山地,由于地面摩阻力的增大,对强降水的发生总体上却是不利因素。海南岛属热带海洋性季风气候,与其他分区不同有着独特的降雨结构特征,表现在:降雨频率偏低、孤立性降雨占比多、连续降雨历时短、CCPD3递减快偏态性强,这些是降雨的不利因素,但是由于强降雨区段CCPD1、CCPD2比其他分区大的有利因素,而致年均降雨偏多。地理位置偏北的VI区,降雨频率小,PD1、PD2明显比其它区小,但三类CCPD均与30°N线上分区相近。
3 拟合经验公式与拟合方法
现有研究多以Gamma函数来进行降雨概率密度拟合,所以最初在Matlab软件平台下用Curve Fitting Tool进行Gamma函数拟合试验,由于对降雨区间进行了细分,曲线尾部(最后的几个降雨等级)的拟合相对误差超3个数量级几乎是常态,即使拟合的决定系数(R-Square)高达0.9999,相对误差依然会很大;改用Weibull、(对数)正态、Gumbel、Pareto、Beta、Cauchy、泊松、皮尔逊III型等多种分布函数也存在类似问题。为此放弃该拟合方法,改用基因遗传算法来搜索这些函数的最优拟合参数,拟合时如果想兼顾到强降雨区段的相对误差时,弱降雨的拟合效果就变差,总是难以首尾兼顾。最后,放弃这些常用的概率密度函数,改用三参数幂函数的指数函数(1)式作为经验公式来拟合能收到很好的拟合效果,该函数形式简单,并且适用所有分区、三类CCPD,唯一的缺憾是不能严格保证定义域内函数的积分为1。其中自变量x对应取为HR、HCR、HoCR,y是这三类CCPD的拟合值,n、a、b是拟合参数;为了公式的简洁,式中关于分区标号M、类别的下标予以略去。

采用多目标遗传基因算法来搜索三个拟合参数的最优解,目标函数综合了加性误差模型与乘性误差模型,采用权重系数WP来均衡两类误差,设定公式为
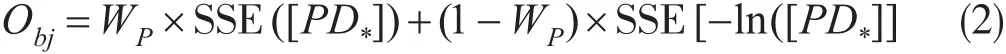
(2)式中下标*是通配符,PD*在此小节代表CCPD1,y*是其拟合值;1-WP是PD*乘性误差对目标函数Obj贡献的权重系数,SSE为带权重系数的协方差算子。WP是PD*加性误差对目标函数贡献的权重系数,设定为


3.1 CCPD1的拟合
拟合时各降雨等级下权重系数选取:对所有分区统一设定一套权重系数。对头部第1降雨等级权重系数取0.85;对尾部第40、41、42三个降雨等级,由于统计时区间长度长,样本量又有限,其概率密度结果数值上存疑,参考价值不大,把其权重系数分别取0.85、0.60、0.15,以降低其对拟合结果的不利影响;其余38个降雨等级取1。然后对该序列进行平滑运算,再做均值为1的中心化处理,得到最终权重系数序列。图6给出了CCPD1拟合目标函数中权重系数Weight(N)随降雨等级的分布,从中可见,中间主体区域略大于1,头部1个降雨等级下取值小于1,尾部4个与头部1个降雨等级下取值小于1。这种立足于38个中间等级按经验取值的益处在于,能让拟合函数去充分适应经验函数的主体,同时又兼顾到头、尾部数据所包含的部分信息量。
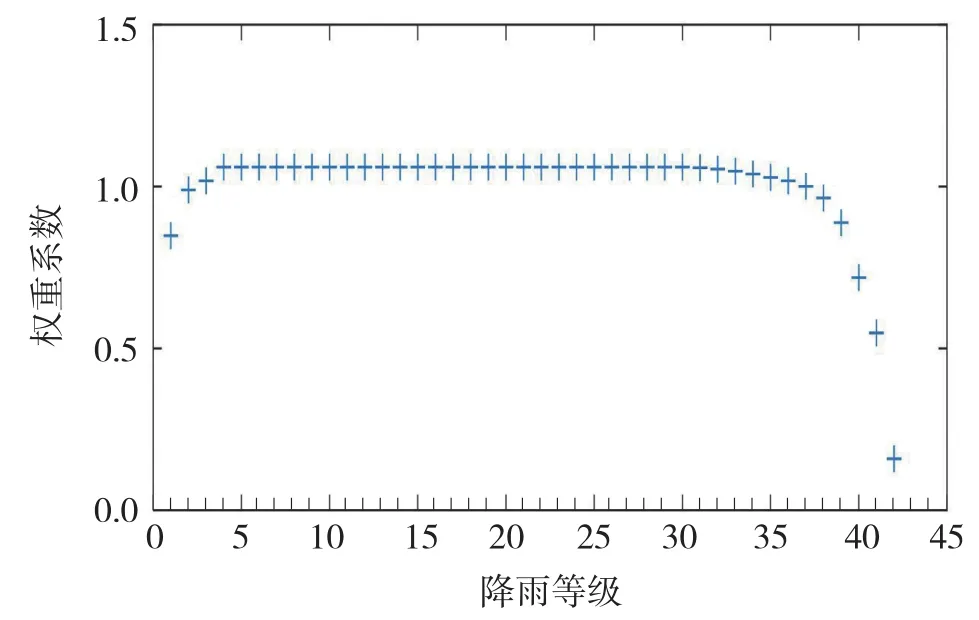
图6 CCPD1拟合目标函数中各降雨等级下的权重系数Fig.6 The weight coefficient of 42 rainfall grades in the fitting objective function.
表4给出了六个分区CCPD1拟合参数与拟合统计量,拟合参数供读者核算与参考,从拟合统计值中看出:CCPD1及ln(CCPD1)的标准化后的拟合均方差均是很小的量,V区最大为0.013 5及0.050 4;CCPD1决定系数均大于0.99,ln(CCPD1)决定系数除V区的0.920 8外均大于0.977;ln(CCPD1)的皮尔逊相关系数除V区的0.972 6外均大于0.99。
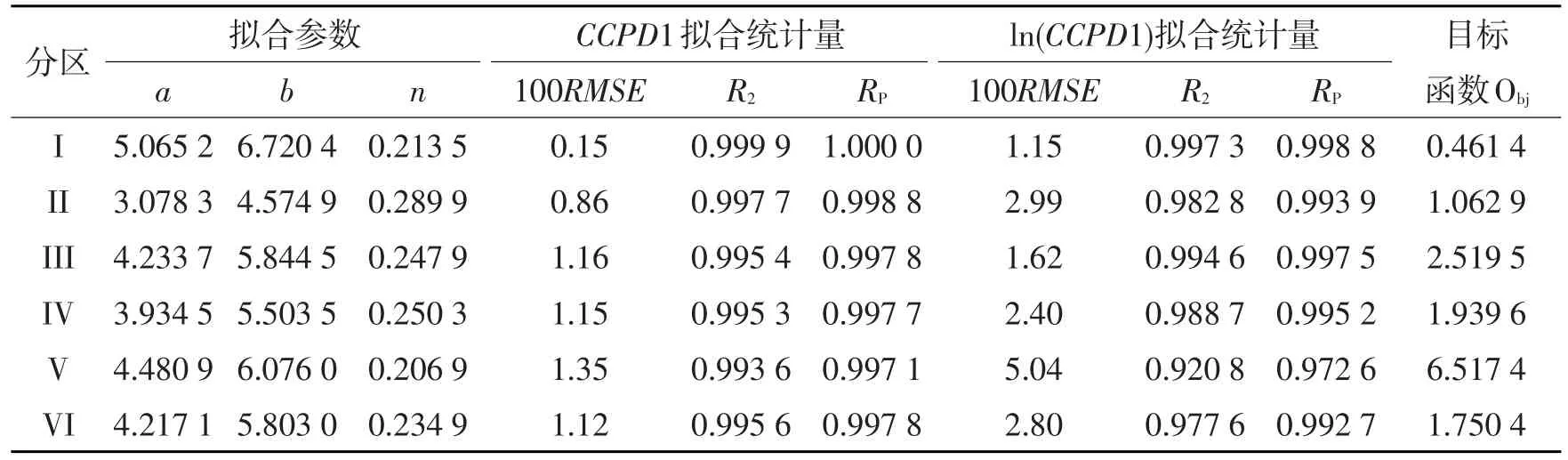
表4 各分区CCPD1拟合参数与拟合统计量Table 4 Fitting parameters and statistical values of CCPD1 in six sub-regions.
图7以III、V分区为例给出了第一类条件概率密度及其拟合函数,蓝色线主要反映弱降雨量级拟合函数(实线)与经验函数(*离散点)匹配情况,红色线反映整体及强降雨区段两者匹配情况。其它四个分区图略,拟合函数与经验函数均吻合度好,包括CCPD1及ln(CCPD1)曲线,并且曲线头尾均得到了兼顾,具有很高的拟合精度。由表4可知,III、V分区是拟合目标函数最大的两个区,从图7中仍可看出有较好的拟合效果。
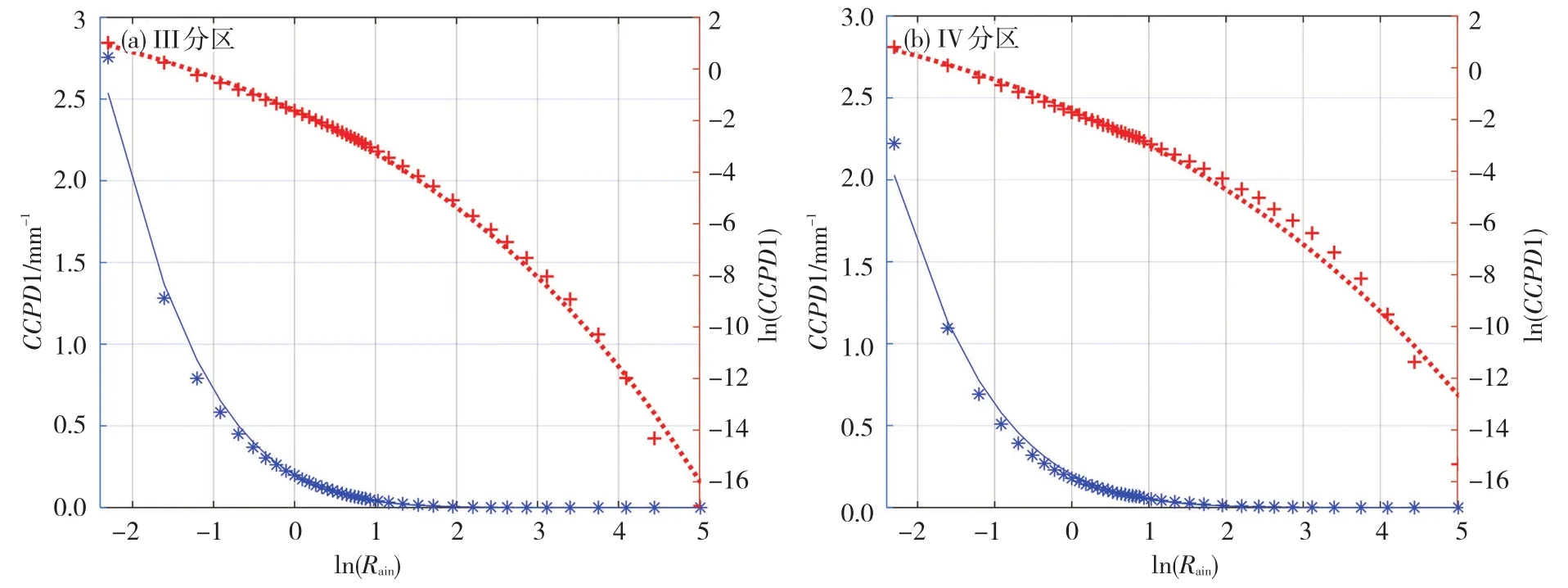
图7 III(a)、V(b)分区的第一类条件概率密度CCPD1及其拟合函数(蓝色对应左边y轴,*离散点代表CCPD1,蓝实线代表其拟合函数;红色对应右边y轴,+离散点代表ln(CCPD1),红点化线代表其拟合函数)Fig.7 The first class conditional probability density of(a)III,(b)V sub-regions and its fitting function(Blue corresponds to the left y-axis,the*discrete point is CCPD1,and the blue solid line represents its fitting function.Red corresponds to the right y-axis,the+discrete point is ln(CCPD1),and the red dotted line represents its fitting function).
综合表4及图7来看,用(1)式和上述拟合方法对各分区CCPD1整体拟合情况好,拟合目标函数考虑到了CCPD的协方差及Ln(CCPD)的协方差两项因素,即综合考虑了拟合误差与拟合相对误差,用多因子基因遗传算法来寻优,能使曲线头尾得到兼顾,提高了强降雨段CCPD的拟合精度。
根据概率密度函数可以计算概率分布,有了高精度的CCPD拟合函数,就可以估算某重现期降雨量、年均降雨量、各降雨级别下雨量贡献率与发生频率等,此略。
3.2 CCPD2的拟合
由于函数定义域与CCPD1有了变化,降雨起点是0.2 mm,第1降雨等级0.1 mm不存在了,各降雨等级下权重系数类似图6,但有所改变:第2、41、42降雨等级下权重系数分别取0.85、0.85、0.70,其余取1后平滑,再做均值为1的中心化处理。
表5给出了六个分区CCPD2拟合参数与寻优目标函数值,CCPD2目标函数比表4中CCPD1目标函数整体要小。由于拟合统计量与表4中比较RMSE更小,R2、RP更接近1,比如六个分区ln(CCPD2)拟合确定系数均值为0.9937,比ln(CCPD1)拟合确定系数均值0.9770高,故表5中拟合统计量略。V、VI两分区是目标函数最大的两个区。
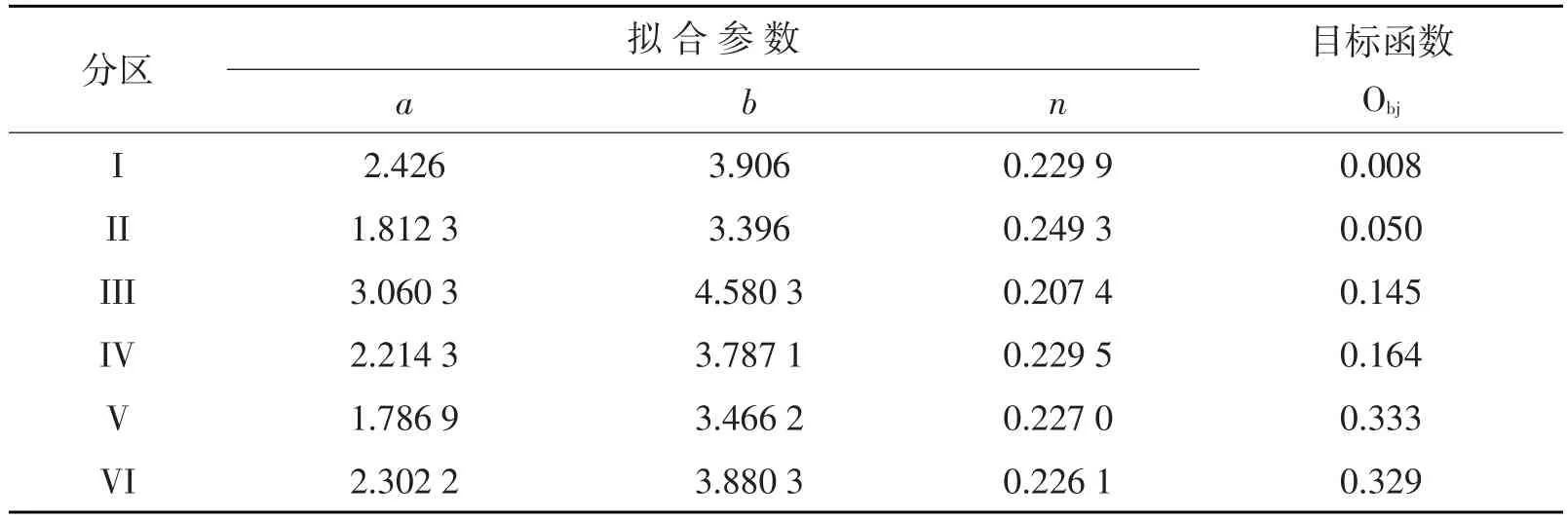
表5 研究选定的六个分区CCPD2拟合参数与寻优目标函数值Table5 FittingparametersandobjectivefunctionofCCPD2inresearchselectedsixsub-regions.
从拟合效果来看,同CCPD1拟合时相比有提高,拟合函数与经验函数均吻合度更高。图8以一线两画方式给出了V、VI两分区的CCPD2及其拟合函数,这是六个区中拟合效果最差的两个区,但与图7相比效果更好。

图8 V(a)、VI(b)两分区的第二类条件概率密度CCPD2及其拟合函数(说明同图7)Fig.8 The 2nd conditional probability density of(a)V,(b)VI sub-regions and its fitting function(The description is the same as Fig.7).
3.3 CCPD3的拟合
拟合函数沿用(1)式,拟合方法与前面两者有所不同,采用了一种简便方法:指数n由人为经验选取1/n得到,然后对ln(CCPD3)与xn进行一次多项式拟合得出参数a、b,这种简便方法虽然会降低拟合精度,但仍能得到好的拟合效果。表6给出了六个分区ln(CCPD3)拟合参数与拟合统计量,从表中拟合统计量看出,该简便方法由于采用了(1)式对六个分区均能给出很好的拟合。
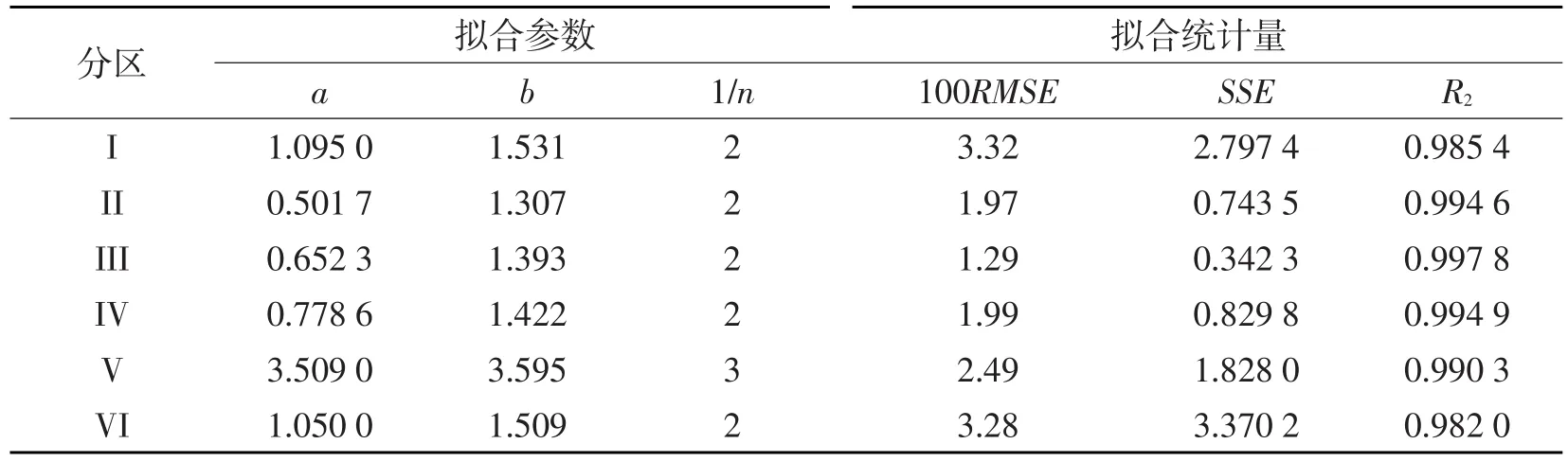
表6 研究选定的六个分区ln(CCPD3)拟合参数与拟合统计量Table 6 Fitting parameters and statistical values of ln(CCPD3)in research selected six sub-regions.
图9以VI分区为例给出了CCPD3随HCR历时的变化情况及其拟合函数曲线,也是一线两画,拟合效果也很好,即使VI分区的拟合协方差最大、确定系数最小。
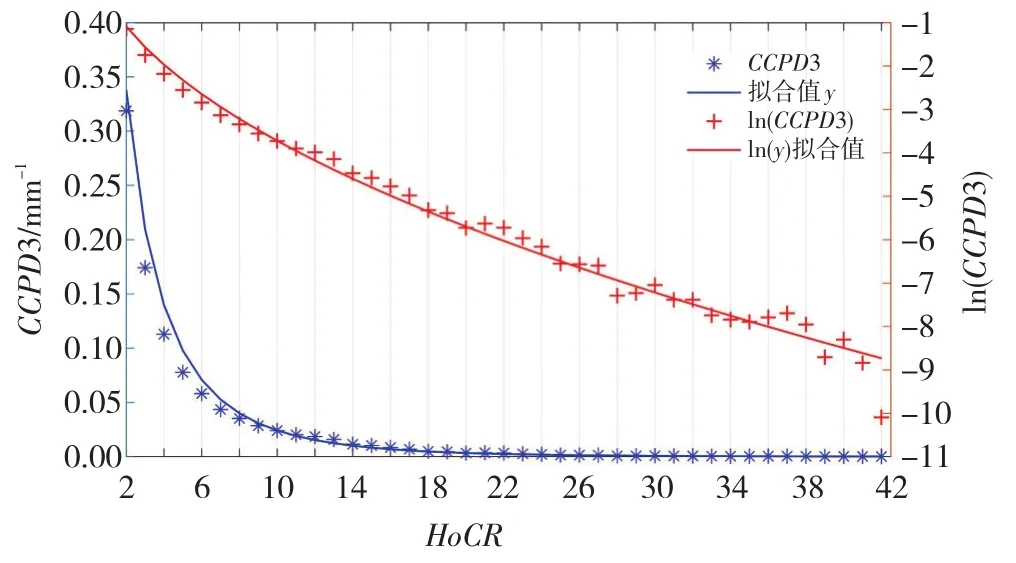
图9 VI分区第三类条件概率密度CCPD3及其拟合函数(说明同图7)Fig.9 The 3rd class conditional probability density of VI subregion and its fitting function(The description is the same as Fig.7).
3.4 三类CCPD的递减率指数分析
递减率指数是由三个拟合参数组合而来,与exp(a)、b、n均成正比,反映CCPD曲线整体递减率情况。海南岛CCPD3递减率指数为40.04,高出其他区17倍以上,故表7中排除了海南,给出了余下的五个分区三类CCPD递减率指数与统计量,从表中可见:CCPD1递减率指数雅安最大。虽然图2b中难以区分不同分区的CCPD1曲线,但递减率指数各分区之间差别大,最大与最小之间有一个量级上的差别,五个分区CCPD1的离差系数为0.476,利于从数据上整体反映各分区之间的差别。CCPD2递减率指数鄂西南山地最大,雅安次之;CCPD3递减率指数均值1.684,雅安最大,II区最小;比较三类CCPD递减率指数五个区的平均值,CCPD1比CCPD2大一个数量级,CCPD2比CCPD3又大一个数量级,三类CCPD递减率指数五个区的离差与均方差也存在类似的量级差别;比较三类CCPD递减率指数的离差系数,CCPD1分区间的差异性最大,CCPD3分区间的差异性最小。该离差系数可以代表降雨特征的地域差别大小,CCPD1中包含中小尺度降雨成分更重,地域差别大,离差系数便大;CCPD2由于过滤掉孤立逐时降雨而次之,CCPD3在降雨历时大于3后的曲线走势反映大范围天气系统性降雨的成分更浓,地域差别小,离差系数最小。三类CCPD包含中小尺度、大尺度降雨成分多寡的这种差别也是导致三类CCPD平均值、离差与均方差在类间量级上的差别。
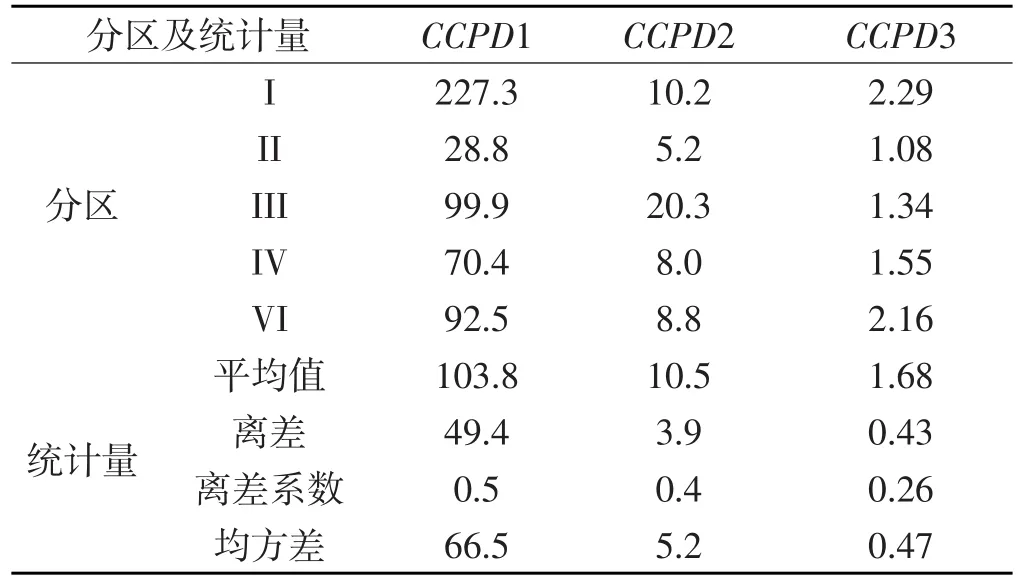
表7 各分区CCPD递减率指数b·n·ea与统计值Table 7 Decline rate index of CCPD in subregions.
4 结论
(1)三类PD、CCPD曲线均是单调凸减函数、在双对数图上曲线均是单调凹减函数,逐时降雨频率各分区间差别大,导致PD差别也大,而三类CCPD分区间差别小,在曲线图上难以分辩;三类CCPD递减率指数分区之间差距明显,能反映CCPD地域差异性。
(2)用三参数幂函数的指数函数作为经验公式来拟合,目标函数考虑了CCPD的偏方差及CCPD对数的偏方差两项因素,便综合考虑了拟合误差与拟合相对误差,用多因子基因遗传算法来寻优,能使曲线首尾得到了兼顾,提高了强降雨段类概率密度的拟合精度。该函数及拟合方法适用全部所选分区、三类CCPD。
(3)对同一地域PD、CCPD均有反映降雨结构的能力,对不同地域PD受降雨频率影响致其能力被削弱,更侧重于用来表征指定降雨出现的可能性,而CCPD1反映强、弱降雨出现的配比情况更直截,更侧重于用来反映降雨结构性特征,在表征强降雨出现的难易程度上比PD1效果会更好。
(4)雅安降雨频率是30°N线上四个分区中最大的,其CCPD1、CCPD2相对其它分区呈现两端大、中间小的格局,特别是极端短时强降雨CCPD1比其他区高。
(5)海南岛属热带海洋性季风气候,与其他分区不同有着独特的降雨结构特征,表现在强降雨区段CCPD1、CCPD2比其他区大,纵然其包含降雨频率偏低、孤立性降雨占比多、逐时连续降雨历时短、CCPD3递减快偏态性强等降雨量不利因素,仍致年均降雨量偏大。
(6)位置临近的III、IV分区,由于山地与平原的地理差别,导致降雨频率两区差距大,山区地形致降雨频率增加,且主要是弱降雨的增加,强降雨反倒有所减少。对于非特殊地形结构下的山地,由于地面摩阻力的增大,对强降水的发生总体上却是不利因素,与雅安附近特殊的地形影响迥异。
猜你喜欢
今日农业(2022年14期)2022-09-15
环球时报(2022-03-29)2022-03-29
数学学习与研究(2020年15期)2020-11-28
知识经济·中国直销(2018年7期)2018-07-27
数学年刊A辑(中文版)(2015年1期)2015-10-30
河北建筑工程学院学报(2015年2期)2015-04-29
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
振动工程学报(2015年2期)2015-03-01
浙江水利科技(2010年4期)2010-02-13
