
基于嵌入表示的改进协同过滤旅游线路推荐
2021-12-04 06:12:18王洪建
中国民航大学学报 2021年5期
王洪建
(厦门航空有限公司,福建厦门 361006)
当前,各种旅游产品的推出使旅游信息数量变得异常庞大,用户很难从大量的旅游信息中快速定位其感兴趣的产品。而旅游公司为了争夺客源及增加收入,需要不断满足游客的需求,制定符合游客兴趣的旅游线路。旅游推荐系统[1-2]是解决旅游信息过载问题的重要手段,能主动推送符合游客兴趣的旅游线路,帮助其快速做出决策。
目前旅游线路推荐算法主要包括:基于内容的推荐、基于协同过滤的推荐、基于知识的推荐及基于社交媒体的推荐4 类。基于内容的旅游线路推荐根据游客选择的旅游产品向其推荐与该线路相似的线路。黄飞龙[3]根据游客的实时数据,为游客在有限时间内推荐可选的旅游线路。基于协同过滤的旅游线路推荐根据游客的线路偏好,为其推荐与其兴趣相似游客选择的线路。侯新华等[4]利用游客对旅游线路的线上评价,寻找相似游客,完成旅游景点的推荐。史一帆等[5]利用景点标签改进协同过滤线路推荐算法,提高旅游线路推荐的准确度。基于知识的旅游线路推荐则是将旅游领域知识引入线路推荐系统,提升线路推荐准确度。王显飞等[6]以交互方式获取游客的需求和兴趣,并以此为约束进行旅游线路推荐,提高了线路推荐的品质。基于社交媒体的旅游线路推荐则是将社交媒体中的游客关系引入线路推荐过程。文献[7-9]根据游客位置信息,建立游客位置-兴趣关联,推荐周边景点。但由于旅游数据一般是隐式反馈的,很难收集用户对旅游线路的喜好信息。这限制了以上传统旅游线路推荐算法的性能。
词向量(Doc2vector)模型最初应用于自然语言处理领域,将单词的丰富信息表示成低维向量,取得了非常好的效果,近几年其已被广泛应用于旅游推荐系统中[10-11]。由于旅游数据一般具有较详细的线路描述,因此每条线路可以利用词向量进行低维表示,利用游客参加线路对游客兴趣进行建模,提高传统旅游线路推荐算法对于隐式反馈数据的处理能力[12]。
针对上述研究的不足,提出了基于嵌入表示的改进协同过滤旅游线路推荐算法。首先,根据词向量模型将每条线路表示成低维嵌入表示,并根据游客的参与线路集合得到游客兴趣的嵌入表示;其次,根据线路间的相似性抽取游客共现线路集合并计算游客间的相似度;最后,利用改进的协同过滤模型完成线路推荐。
1 基于词向量的线路和游客兴趣嵌入表示
假设U={u1,u2,…,um},L={l1,l2,…,ln}分别为游客和旅游线路集合,Mm×n= {rul|u∈U,l∈L} 为交互矩阵,rul=1 表示游客u参加了l,否则为0。
1.1 线路的嵌入表示
词向量将一个给定词语表示为一个向量,每个不同的单词映射到不同的向量,具有相近意思的词语,其表示也是相似的。常用的模型为跳字模型(Skipgram)和连续词袋模型(CBOW,continuous bag of words)。但这两种模型忽略了单词之间的排列顺序对句子或文本信息造成的影响,而Doc2vector 模型解决了这个问题,其可处理可变长度文本,在使用向量表示段落或文本时,考虑到了词序对于语义的影响。在旅游数据集中,与线路集合L={l1,l2,…,ln}对应的线路描述文档集合可表示为D={d1,d2,…,dn},对于任意线路li∈L可利用Doc2vector 将其对应的线路介绍文档di∈D映射成低维向量vli∈Rd。这样每条线路就被表示成了一个d维向量,如果两条线路的主题比较相近,其向量也比较相似,向量距离较小;反之,向量距离则较大。
1.2 游客兴趣的嵌入表示
在旅游推荐系统中,由于缺乏游客对旅游线路的反馈信息,因此认为游客参加的线路就是其喜欢的旅游产品。游客兴趣的嵌入表示由其参与过的线路特征描述。假设游客ui参加过的线路集合为则游客ui对线路的兴趣可表示为

2 游客间相似性计算
在协同过滤推荐过程中,相似性计算是非常重要的关键步骤。假设两个游客共同参加过很多相同/相似的线路,则认为两个游客兴趣是相似的。但因为旅游数据的极度稀疏性特点,在实际过程中不同游客参加过相同线路的次数非常少,因此如何抽取游客的共现线路集合是度量游客间是否具有相同偏好的关键。两条线路间的距离衡量了线路间的特征相似性,距离越小,说明两条线路具有相似特征,距离越大,说明线路特征差别越大。不同线路间的距离计算公式如下

由于旅游数据稀疏性高,游客共现线路更少。如果两游客参与的线路相似性较高,则认为其是共现线路。为了衡量线路间的相似性,设定一个阈值T,当两条线路向量表示的距离小于T时,则认为两条线路是相似线路。因此可以得到游客ui与uj共现线路集合可表示为
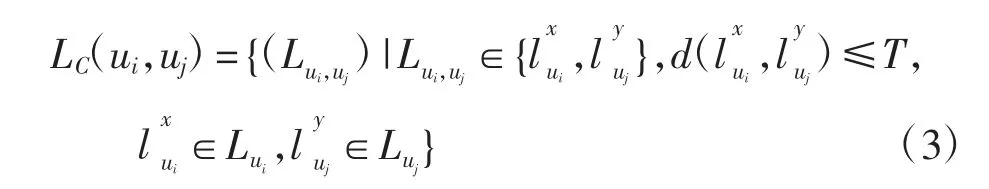
任意两名游客间的相似性由其共同参与的线路来表示。共同参与的线路越多,线路越相似,其偏好越相似。游客更喜欢给其推荐共现线路集合中未参加的线路,任意两个游客ui与uj的相似性利用改进余弦公式进行计算如下
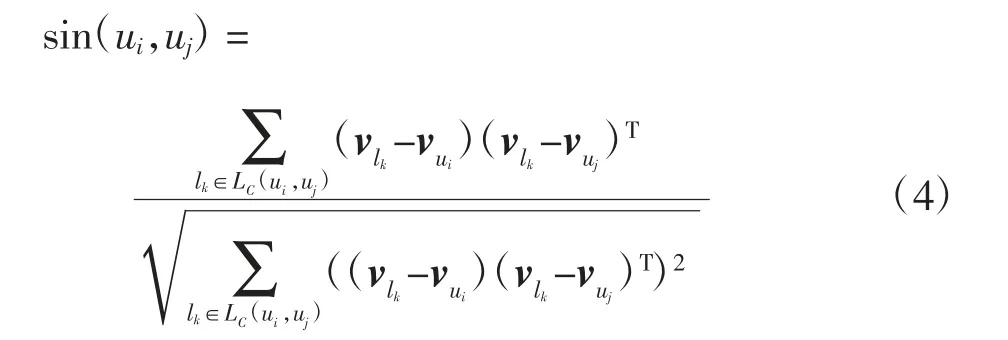
其表示了游客ui和uj对于共现线路的向量累计偏差,也就是游客ui与uj对线路兴趣的偏好。累计偏差越大,ui和uj间的相似性越差;偏差越小,说明ui和uj的偏好越相似,其喜欢相同/相似线路的可能性越大。
因此实际推荐过程中,利用游客间的相似性得到相似游客,目标游客ui的相似游客参与的线路构成候选推荐线路集合如下
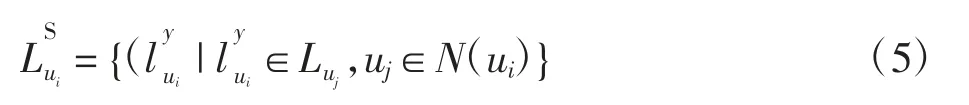
式中N(ui)为ui的相似游客集合。将某个相似游客去过,但目标游客没有去过的线路向其推荐。
3 旅游线路推荐
假设目标游客为游客ui,游客uj为其相似游客集合N(u)i中的游客;为游客uj参加过的,但游客ui没有参加过的线路,则游客ui喜欢线路的概率表示为

由此可得到ui对所有相似游客uj参加过,而游客ui未参加过的线路感兴趣的概率,之后按照概率的大小降序排列,得到Top@k推荐列表,即按游客兴趣度排列的前k条推荐线路。
4 实验结果及分析
4.1 数据集
实验数据集来源于某旅游公司,共包括4 737 个游客,1 436 条旅游线路,交互记录为25 717 条。每个游客的信息包括游客姓名、性别、身份证号、参加的旅游团号、线路出发时间、价格、景点的详细介绍。对于每条线路都包含一个详细的线路描述,包括行程、线路中包含的每个景区特点等。其为隐式反馈数据集,游客参加了某线路则认为该游客喜欢这条线路。对数据集以6∶2∶2 的比例拆分成训练集、测试集和验证集。
4.2 评估指标
实验中采用召回率(recall)、归一化折损累计增益(NDCG,normalized discounted cumulative gain)和平均精准度(MAP,mean average precision)作为评估标准。Recall 描述推荐系统推荐给用户的旅游线路占用户真正感兴趣的线路的比例。NDCG 和MAP 则表示推荐项目在推荐列表中排序位置情况。
4.3 参数训练
4.3.1 游客和线路向量维度的影响
向量维度k的大小,直接影响着旅游线路推荐算法的性能。k值太大,会增加计算量,太小不能表示游客和线路特征。图1 给出了随着向量维度的变化,推荐算法NDCG 的变化趋势。从图1 可知,随着向量维度的增大,推荐性能快速提升之后变缓,性能变换的折点在200 附近,因此向量维度取能使算法性能达到最高的200。
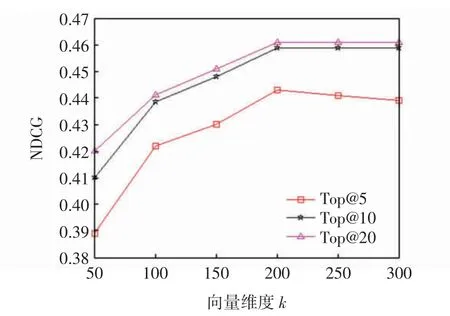
图1 向量维度对算法NDCG 的影响Fig.1 Effect of vector dimension on NDCG
4.3.2 阈值T的敏感性分析
线路向量距离阈值T决定着游客的向量表示,影响了游客间相似性计算。如果阈值T太小,不能将相似线路融入相似性计算;阈值太大,则会将不相近的线路选择进来。图2 给出了推荐算法NDCG 的性能随阈值T的变化趋势。从图2 可知,随着阈值T的增大,算法性能先增大,后减小,性能变换的折点在T为1.1 附近,因此阈值T取1.1。
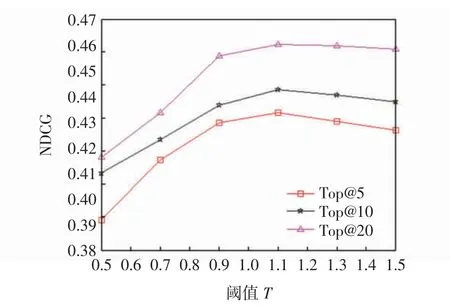
图2 阈值对算法NDCG 的影响Fig.2 Effect of threshold on NDCG
4.3.3 相似游客数n的影响
在协同过滤推荐中,相似游客数是影响算法性能的关键参数。相似游客数太大,可选线路会太多,计算量变大;相似游客数太小可选线路又可能太少,不能得到好的推荐性能。图3 给出随着相似游客数n的变化,算法的性能变化。从图3 可知,随着相似游客数的增加,性能先增大,后减小,性能变换的折点在60 附近,因此相似游客数取能使算法性能达到最高的60。
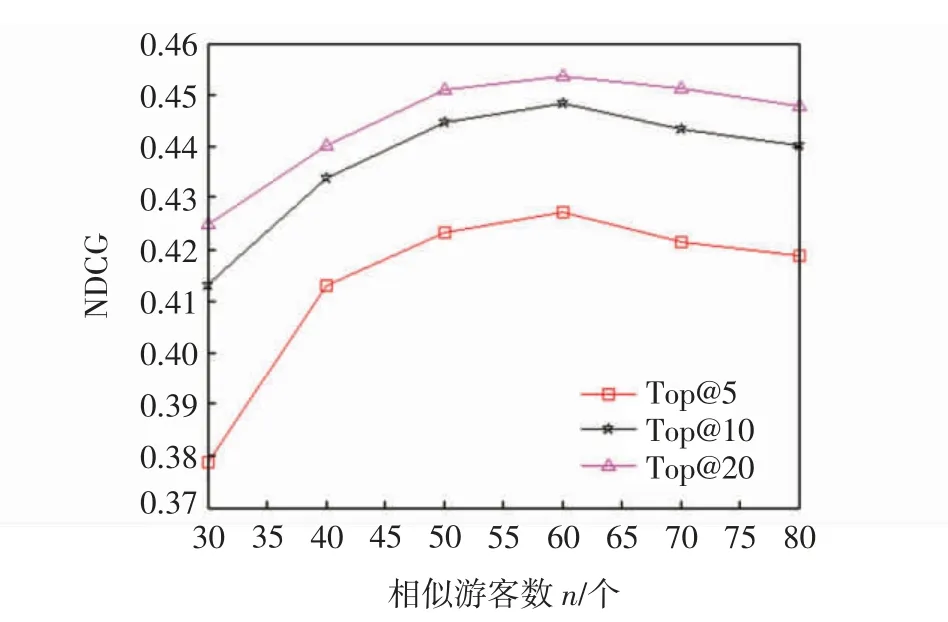
图3 相似游客数对算法NDCG 的影响Fig.3 Effect of the number of neighbors on NDCG
4.4 实验结果与对比分析
将提出的基于嵌入表示的协同过滤线路推荐算法(ECF,embedding collaborative filtering)与基本协同过滤推荐算法(BCF,basic collaborative filtering)进行对比。ECF 与BCF 的性能对比如表1所示。
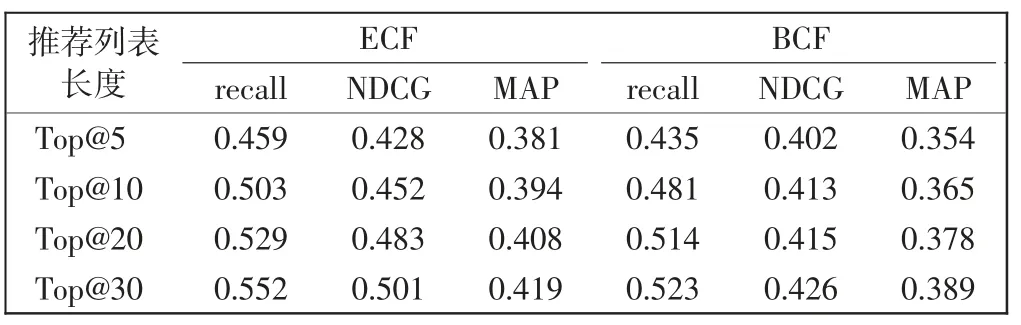
表1 ECF 与BCF 性能对比Tab.1 Comparison of ECF and BCF
从表1 可知,随着推荐列表长度的增加,3 种性能指标都有所提升。将k从5 分别增加到10、20 和30,在ECF 情况下,NDCG 分别提升5.60%、12.90%和17.00%,MAP 分别提升3.40%、7.10%和9.97%;在BCF 的情况下NDCG 分别提升2.70%、3.30%和5.97%,MAP 分别提升3.10%、6.80%和9.89%。可见NDCG 和MAP 两者提升都较小,说明游客感兴趣的线路并没有在推荐列表的最前面。但ECF 性能提升结果要好于BCF,说明利用词向量模型得到游客和线路的向量表示对于这种稀疏的、隐式反馈的数据集能够提升推荐结果。
5 结语
基于嵌入表示的改进协同过滤的线路推荐算法首先利用词向量模型(Doc2vector)将每条线路用一个低维向量表示,这样解决了对于这种隐式反馈数据特征表示的问题。其次利用游客参加过的线路得到游客的兴趣向量表示,解决了某些游客参与线路过少导致游客偏好建模困难的问题。通过计算线路间的相似性得到抽取的共现线路集合,解决旅游数据高度稀疏,共现线路少的问题。最后利用相似游客参与的线路得到候选线路及参与概率,完成线路推荐列表。通过在实际数据集上的实验表明,该算法提升了线路的推荐性能,缓解了旅游数据稀疏的问题。
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
河北画报(2020年8期)2020-10-27 02:54:20
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
河北遥感(2017年2期)2017-08-07 14:49:00
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
