
基于钻孔数据的可视化空间分析方法研究
2021-12-03 06:39陶德保
科技信息·学术版 2021年31期
关键词:可视化技术
陶德保
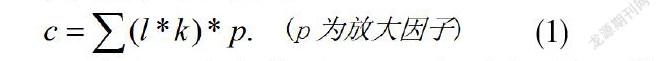

摘要:论文以钻孔数据的空间多维分析模型入手,主要研究了数据多维分析模型的发展和实现,提出适合钻孔数据管理的空间数据仓库进行数据分析的多维数据模型,并在此基础上提出了一种空间数据挖掘的模型结构,用三种空间数据挖掘算法分析了矿化段之间的相关性。空间数据的可视化以及基于可视化技术的空间分析、空间数据挖掘和知识发现已经发展成为空间信息处理的重要手段和关键技术。本文还介绍了基于OPENGL的几种可视化模型,实现了空间数据挖掘结果的交互式可视化。
关键词:钻孔数据;空间数据仓库;空间数据挖掘;可视化技术
1 引言
钻井领域数据复杂,既有定量测量的数据,又有定性的文字描述,它们量纲不一、形式多样。仅储层特性的数据就涉及到测井仪器、测井方法、测井原理、仪器所探测的深度、仪器分辨率等。如何把这些反映同一储层特性的数据结合起来,无冗余,而又不漏失地反映井、矿的特性,一直是钻井领域资料解释的重点。数据仓库是面向主题的、集成的、稳定的和随时间变化的数据集合。它是一项基于数据管理和运用的综合性技术和解决方案,是一种有效的数据存储和组织形式。经过数据仓库技术处理以后的数据是集成的、稳定的、干净的,从而有利于在后面集成并运用数据挖掘技术进行分析处理。但是目前,在大多数知识发现的过程中,数据仍然被视为是静态的,人机交互类似于传统的数据库操作。这样一来,只有在处理结果出来之后才能评判数据输入的好坏,挖掘算法选择的优劣。而将地理可视化与空间数据挖掘和知识发现相集成,可以使知识发现的各个阶段具有高度的交互性和灵活性。
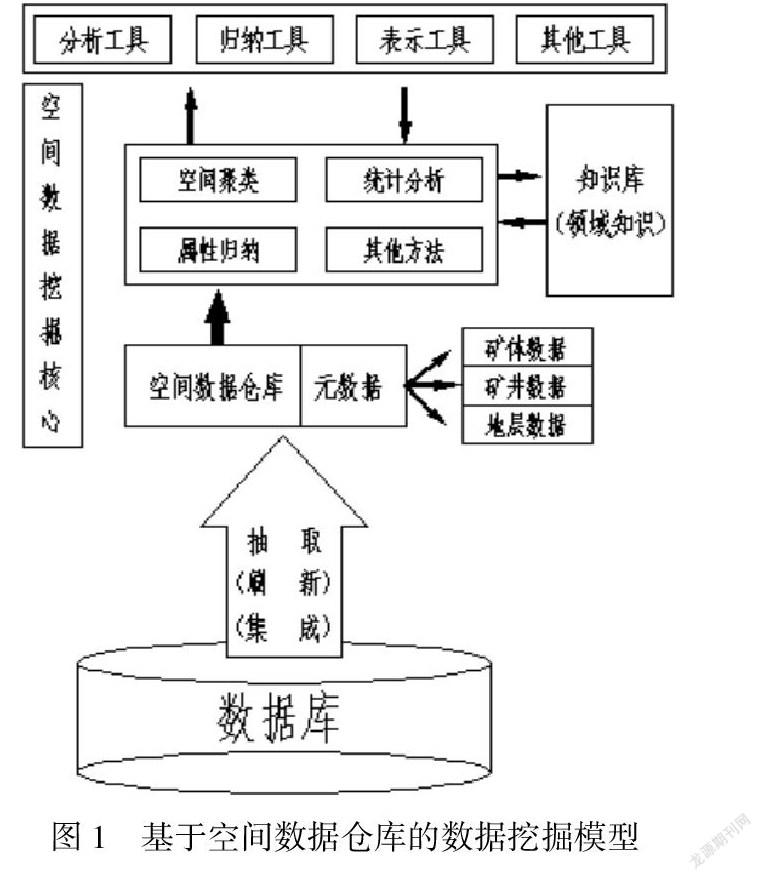
2基于空间数据仓库的数据挖掘模型设计
空间数据仓库(Spatial Data Warehouse-SDW)是GIS技术与数据仓库(Data Warehouse-DW) 技术相结合的产物,它是在DW基础上,引入空间维数据,根据主题从不同的GIS 应用系统中截取不同规模时空尺度上的信息,从而为地学研究以及有关环境资源政策的制定提供最好的信息服务。图1是本文提出的一个基于空间数据仓库的空间数据挖掘的模型结构。用户发出知识发现的命令,知识发现模块从空间数据仓库中获取感兴趣的数据 (与任务相关的数据)。知识发现模块根据要求和领域知识库,从那些与任务相关的数据中发现知识,发现的知识提供给用户应用。一般这一过程要交互地反复进行才能得到最终满意的结果。
3空间元数据的数据结构及生成算法
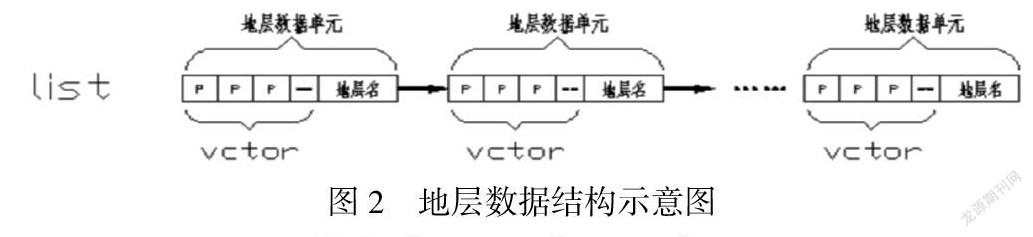
为实现基于钻孔数据的空间多维分析,本系统主要从四个维度来分析原始数据库中的信息,分别为地层维、矿化段维、矿化量维和钻井维。可以利用标准模板库(STL)中的链表和向量模板来设计出其数据结构。地层数据结构的结构图如下(P代表Point3D):
图中采用了一个链表来存储所有的底层数据,链表中包含了多个地层数据单元,每个单元由一个vctor和地层名组成,而vctor中存储了该地层的所有数据点。本系统中还用了很多数据结构,例如在做数据分析时,基本的分析单元是矿化段,用于矿体插值的矿化点数据结构等,其设计思想同地层数据结构是相同的,即先设计出基本数据单元,再结合STL中的LIST和VCTOR来组织数据。需要注意的是系统在整个设计过程中,要充分考虑程序的可扩展性,对系统采用模块划分,各模块功能明确;同时在设计数据机构时,可以采用了范性编程的思想,利于系统的进一步完善和扩充。
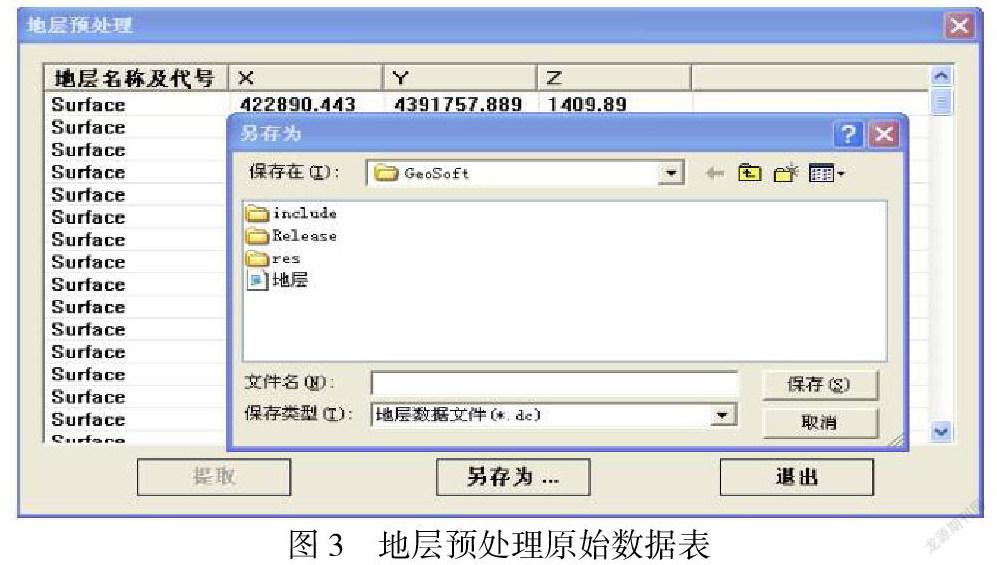
在多维数据结构设计的基础上,我们要对数据库中的原始信息进行精确的分析,采用ADO连接数据库,从原始数据库中提取出需要的数据,跟设计的数据结构相对应起来,这样就得到了系统的元数据。以地层数据为例,首先要分析数据库中所有与地层相关的表,然后用SQL语句在多张表中查询所需要的字段信息,将查到的信息进行筛选、提取,然后存入我们所设计的数据结构中,这样就为进一步的数据分析提供了数据准备。其他元数据的获取方法同地层数据类似,限于篇幅,在此不做详细说明。
4可视化空间数据挖掘
通过离散钻孔数据的空间挖掘我们希望能够找出矿体的空间分布规律,从而为进一步的三维矿体模拟提供一定的先验知识,使其模拟结果更为精确。这部分属于整个数据挖掘模型中的知识库中的内容,由于钻孔数据的复杂性与不确定性,首先要对矿体的平面分布做一个大致的估计,在这个基础上再做空间数据分析,这样得到的结果会更为精确。
4.1矿化量统计分析
矿化量表示的是每个钻井所对应的矿化情况,即将空间分布的矿化段数据投影到一个平面上,用一个平面来表示矿井对应的点的矿化情况。根据每个钻井下的矿化段的长度L和每段的矿化度K,得出了每个钻井的矿化量:
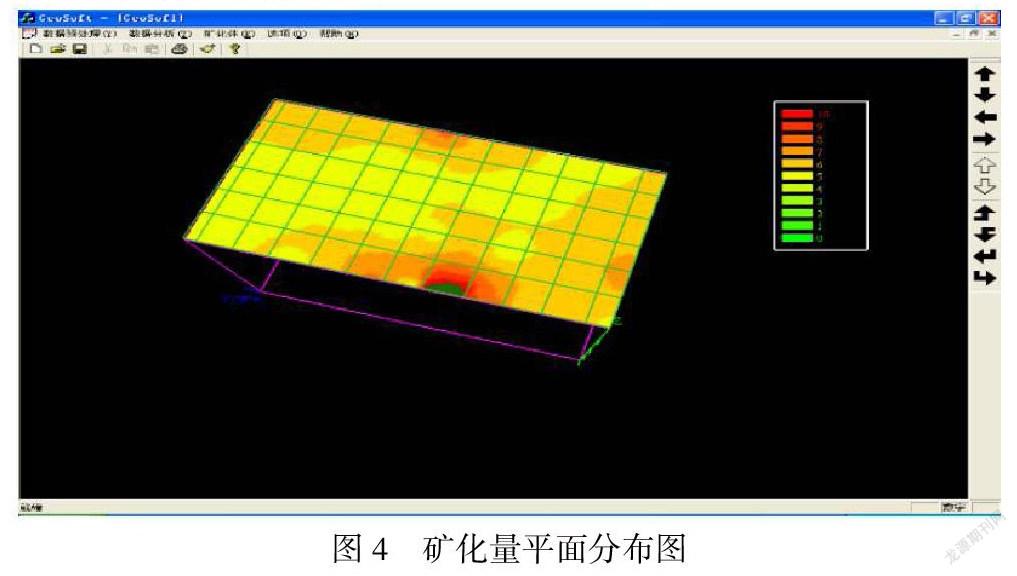
定义这个参数后,可以得到表示每口钻井矿化情况的一个量化的值,用此参数进行平面距离倒数加权插值(IDW),将插值结果可视化,则从平面的角度表示出矿体的矿化分布情况。图4是对研究区域在的矿化量做IDW插值后使用OPENGL生成的平面效果图,颜色越深的部分表示其含矿的量也越大。通过以上的分析,我们就找到了矿化量在地表的大致分布规律,在这个基础上我们对矿化段在三维空间的分布规律进行空间聚类分析。
4.2空间聚类分析
本文中采用的是K-means空间聚类算法。傳统的K均值聚类算法存在两个固有的缺点:(1)对于随机的初始值选取可能会导致不同的聚类结果,甚至存在着无解的情况;(2)该算法是基于目标函数的算法,通常采用梯度法求解极值,由于梯度法的搜索方向是沿着能量减小的方向进行,使得算法很容易陷入局部极值,而且对于孤立点是敏感的。
为了克服传统的K-均值聚类算法收敛时易陷入局部极值问题和对初始选值敏感性的缺点,同时又能保持K-均值算法快速收敛的特点,我们在选择初始值时结合矿化量的统计分析结果,用矿化量平面上的极值点来确定K-MEANS算法的初始聚类中心,其算法步骤如下:
1)根据矿化量统计分析结果,找出矿化量平面上的极值*S。
2)合并相近的极值点*S,得到初始的聚类中心S。
3)获取聚类数目k ,置迭代误差阈值e= 0.00001(可根据需要设置)。
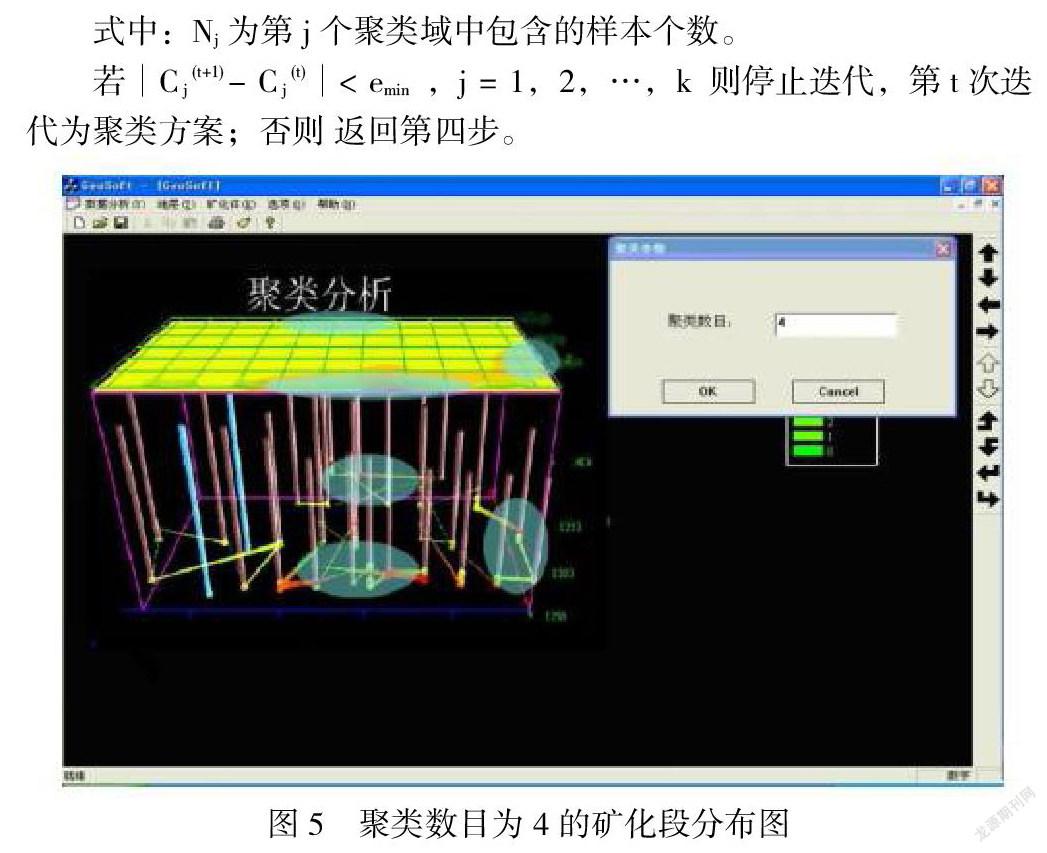
聚类数目由用户指定,用户可以通过图5中的对话框随时改变聚类的数目,直到得到满意的聚类效果。不过聚类数目有最大限制,其最大值不能超过Sj的长度。通过空间分析,我们可以发现空间聚类的效果同矿化量的平面分布有着较好的对应关系,可以将矿区大致分为三块区域,还得到了钻井及矿化段间的相关性信息,有利于我们从宏观上把握矿区的矿体分布。
5结论
本文提出的基于钻孔数据的空间数据挖掘方法,首先提出了矿化量的概念,将矿化段的分布情况做一个平面分析,通过距离倒数插值对矿体的分布做大致的估计,在这个基础上对K-MEANS聚类算法做改进,用矿化量的极值点来初始化K-MEANS中的初始聚类中心,使得分析结果更具科学性;然后将分析结果进行可视化,从而大大地提高了人机交互的水平。但此方法仍存在一些不足,如各种地质资料、专家知识和工程经验不能及时融入到实际数据分析中,系统中所用到的可视化模型不能表现更为复杂的地质构造。由于地质现象的高度复杂性和不确定性,上述问题将随着研究和实际应用的深入而逐步得到解决。
参考文献:
[1]雍世和,洪有密. 测井资料综合解释与数字处理[M ]. 北京石油工业出版社,1982.
[2]刘毅勇,何雄,李金山等.空间数据挖掘:变数据为知识.计算机世界报,2005.8.15.
[3]李德仁,王树良,李德毅等.论空间数据挖掘和知识发现的理论与方法[J].武汉大学学报(信息科学版).2002.27(3):221-223
[4]Mapinfo Corporation.Mapinfo and Data Warehouse:A Mapinfo White Paper.1996.
[5]杜明义,郭达志.空间数据仓库技术与模型研究[J].计算机工程与应用1999( 12) 32- 34.
[6]郭仁忠.空间分析.高等教育出版社,北京,2001.10.
[7]Ujjwal M,Sanghamitra B.Genetic Algorithm Based Clustering Technique[J].Patten Recognition,2000,33(9):1455.
[8]Huang Z.Extensions to the k-Means Algorithm for clustering Large Data Sets with Categorical Values [J].DataMining and Knowledge.
[9]王家耀,張雪萍,周海燕.一个用于空间聚类分析的遗传K-均值算法.计算机工程,2006.2.
[10]Dave Shreiner,Mason Woo,Jackie Neider,Tom Davis. OpenGL编程指南(第四版).人民邮电出版社,北京,2005.4.
猜你喜欢
科学与财富(2016年30期)2017-03-31
科学与财富(2016年24期)2017-03-29
西部资源(2017年1期)2017-03-27
中国科技纵横(2017年1期)2017-03-10
考试周刊(2017年1期)2017-01-20
安徽农学通报(2016年20期)2016-12-26
企业文化·中旬刊(2016年10期)2016-11-21
企业技术开发·中旬刊(2016年10期)2016-11-12
求知导刊(2016年24期)2016-10-14
科技传播(2016年3期)2016-03-25
