
多策略混合的关键情感词识别方法
2021-12-03 06:39马婉贞陈淑婷李雅洁明涛
科技信息·学术版 2021年31期
关键词:机器学习
马婉贞 陈淑婷 李雅洁 明涛
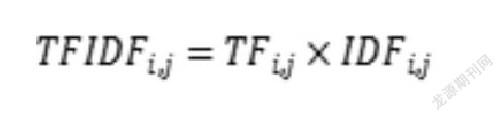
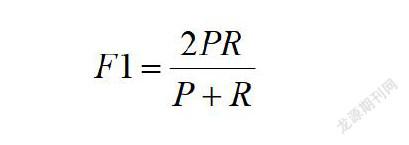
摘要:随着数字化转型的新趋势到来,为解决企业审计或办公人员面对海量数字化文档工作效率低、重复工作等问题,本文在传统机器学习SVM的基础上,加入文本预处理、TF-IDF算法、LDA算法,构建了一套多策略混合的文本关键情感词识别模型。通过模型测试及与单一SVM分类器模型的对比实验,结果显示本文构建的混合模型F1值达到了89.08%,比单一SVM分类器模型提升了22.58%,证明该模型对关键情感词的识别有一定程度的提升,应用于办公或项目管控场景,可以有效提升企业审计办公智能化水平。
关键词:机器学习;情绪识别;TF-IDF;SVM;LDA
引言
随着互联网技术及各个政府机构或企事业单位数字化建设的快速发展,各类文本信息数据呈爆发性增长,为进一步提高办公文件审校效率,及时下发日常相关文件文书;进一步优化项目资料规范化管理检查流程,提升项目文档审计效率,降低工作成本,防范项目审计风险,本文对TF-IDF(词频-逆文档频率)算法、LDA(隐狄利克雷)算法及SVM(支持向量机)算法进行融合,以句子为最小分析单元,以办公文件敏感词及项目建设负面清单关键字为情感词典,计算整句情感词得分,输出整个文本内容情感倾向性,深入开展智慧办公和智能化管控场景应用,提升工作效率。
1.相关工作
现如今,对自然语言的文本数据分析已成为当下研究的热点。单从文本分类而言,其指的是在人为规定好的分类标准下,根据文本自身含义对文本数据进行分类的过程。而文本情绪分析则是对文本内容中的关键情感信息进行挖掘,并进一步分析处理,进行文本情绪识别的过程。通过对文本中的情感成分进行提取,分析出文本中的隐含情感,对文本的情绪、观点和态度作出归纳判断。
随着机器学习模型在自然语言处理领域的不断发展,对其模型的优化也随之引起了各类研究学者的关注。机器学习模型广泛被分成监督学习、无监督学习和半监督学习,其中应用最为广泛的则是监督学习模型,比如Pang等人对比了朴素贝叶斯、最大熵和SVM算法在多个特征集中的应用,得出了SVM相较于其它学习模型表现出了较高的优势。针对半监督学习方面,文献证明了图形半监督学习算法具有较优性能。针对无监督学习方面,文献提出了一种基于非随机初始化的无监督学习模型,并在特征中采用文本统计分析算法进行扩展,获得了较好效果。现如今随着对单一模型的研究日渐成熟,效果已然到达瓶颈期,开始有研究学者将目光转移到混合学习模型领域,比如文献构建出一种基于 SVM 和 CRF(条件随机场算法)的情感分析系统,输出结果表现出了良好的反馈效果,证明多策略混合模型有着相对于单个模型的优越性。
TF-IDF算法是一种针对关键词的统计分析方法,具有简单、可靠性高等特征,用于评估一个词对一个文件集或者一个语料库的重要程度,这类算法能有效减弱常用词对关键词的影响,提高关键词与文本间的关联性。LDA是一种监督学习的降维技术,就是将数据在低维度上进行投影,投影后獲得类内方差最小,类间方差最大的输出。LDA既可以用来降维,又可以用来分类,并且它在降维过程中可以使用关键词分类的先验知识,这也符合本文多策略混合模型构建技术路线要求。因此通过以上研究及大量调研分析工作,本文确定了主要机器学习模型SVM,再使用TF-IDF及LDA(线性判别分析)进行特征空间优化完善。
2.基于多策略混合的文本关键情感词识别方法
2.1算法流程
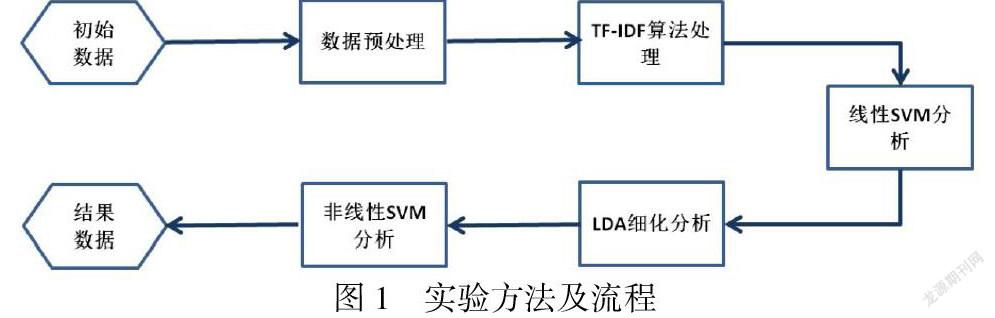
为解决以上众多困境,本文实验方法及流程如图1所示,首先通过文本去噪、基于同义词词林和互信息量的方法对已有的办公文书敏感词和项目负面清单关键词情绪词典进行进一步扩展;使用TF-IDF算法对文本数据中的关键词计算权重值,并以此权重建立文本提取特征矩阵;采用线性SVM分类器对文本内容进行关键情感词分类,对每个句子有无关键词进行判断;其次,使用LDA算法对关键词判断进行细化分析,得到文本特征矩阵;最后使用非线性SVM对特征变量优化映射,得到最终句子的关键词倾向结果。
2.2数据预处理
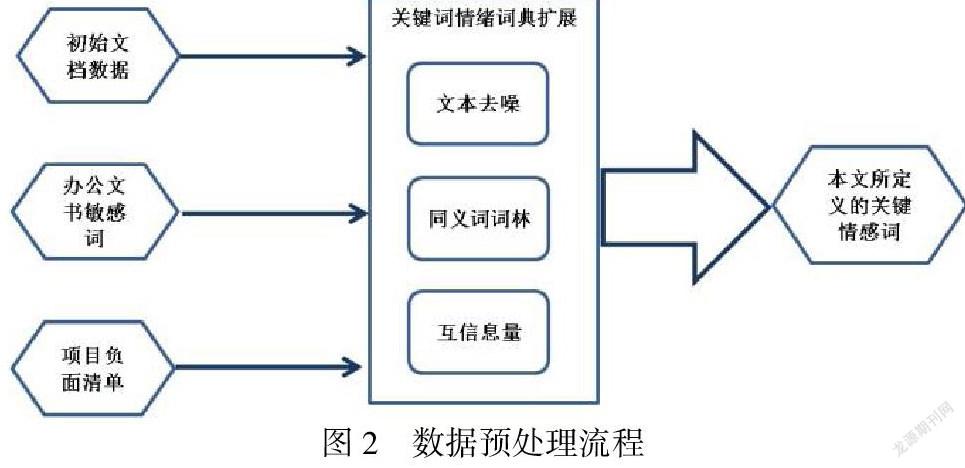
本文分析的情感词并非属于广泛理解的情感词典,而是针对具体办公或者项目管控情景下的关键词,因此开展文本情绪分析前,需进行数据预处理,流程如图2:
1)输入a.初始文档数据:包含通报、通知、批示等办公文书以及项目全过程资料;
b.办公文件敏感词:定密模型文件、公文敏感词库;
c.项目负面清单:项目负面清单库;
2)文本去噪:对以上输入数据去除语气副词、助词等无用信息,提取基础关键词;
3)同义词词林:对基础关键词通过同义词词典找到关键词的同义词,从而扩展基础关键词词典;
4)互信息量:对全文本文档数据及关键词词典,借助网络共享程序包(https://www.omegaxyz.com/2018/08/03/mifs/),进行文本数据与关键词的互信息量计算,进一步扩展基础关键词词典;
5)输出本文所定于的关键情感词词典。
2.3 TF-IDF算法处理
TF-IDF算法是一种根据单词在语料库中出现频次判断其重要程度的统计方法,主要思想是先对词频(term frequency,TF) 进行统计,认为词语出现次数越多,则文档可能与该词语有越多的正向关联性,再通过逆文档频率(inverse document frequency,IDF) 减少常见词的权重[8],计算公式为:
其中TFIDF表示词频TF和逆文档频率IDF的乘积,TFIDF值越大,对当前文本的重要性越大。本文利用TF-IDF算法,给关键情感词赋予权重,进行特征提取,将关键情感词转化为词频向量,建立文本提取矩阵。
2.4线性SVM分析
SVM是一种用于分类的算法,分为线性可分和非线性可分,通俗理解所谓线性和非线性就是指能够用一条直线直接划分数据。
本文根据特征矩阵高维、稀疏特征,先采用线性SVM分类器对文本内容进行关键情感词分类,对每个句子有无关键词进行判断。
经过LDA细化分析后,再采用非线性SVM分类器将低维变量映射到高维特征空间,在高维特征空间计算内积,建立非线性分类器,实现文本关键情感词的识别。
2.5 LDA细化分析
LDA算法的原理就是将带上标签的数据/点,通过投影到维度更低的空间中,促使投影后的点将会按类别区分,形成一簇一簇情形,最终相同类别的数据/点,将会在投影后的空间中更接近。
本文利用LDA算法对经过线性SVM分类器处理后的带有标签的数据进行投影,将有无关键词的句子区分更开;将有关键词的句子按隐含关键情感词进行进一步聚类,得到句子与隐含关键情感词的对应概率矩阵,以此作为文本特征矩阵。
3.实验
3.1实验环境搭建
本文依托于企业智能化办公项目,数据集均来自企业内部文件及模型:
a)初始文档数据:包含企业2017-2021年发布的通报、通知、批示等办公文书以及项目全过程资料,共计5899条;
b)办公文件敏感词:企业自有的定密模型文件、公文敏感词库;
c)项目负面清单:企业自有的项目负面清单库。
实验环境:i7-8700CPU/64,内存/256G,固态/2T硬盘,RTX2080ti-11G显卡的高性能工作站,运行操作系统为:Ubuntu18.04。
3.2实验评估指标
模型效果优劣广泛采用精确率P、召回率R以及 F1 值 3 个标准作为实验评估指标,值越高,则模型效果越好。
在本文中,精确率P又称查准率,就是指预测为关键情感的文件条目中实际关键情感的文件条目占比。
召回率R又称查全率,就是指实际关键情感的文件条目中被预测为关键情感的文件条目占比。
F1值,就是指精确率和召回率的加权调和平均值,是综合性的评价指标。本文采用综合评价指标F1值衡量模型的关键情感识别效果。公式为:
3.3实验结果
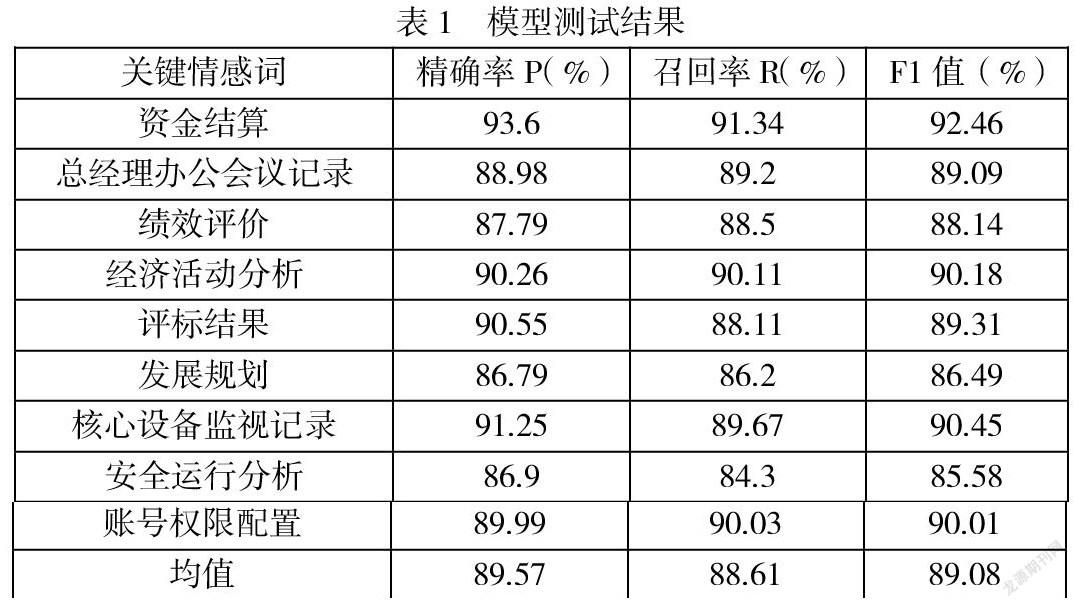
使用数据预处理后的关键情感词典及基础数据作为训练数据,通过本文构建的多策略混合的文本关键情感识别模型进行训练,再使用测试集合对模型进行多个方面的测试,模型关键情感倾向评估结果如表1(由于本文涉及企业内部事项,这里选取部分关键情感词进行结果展示):
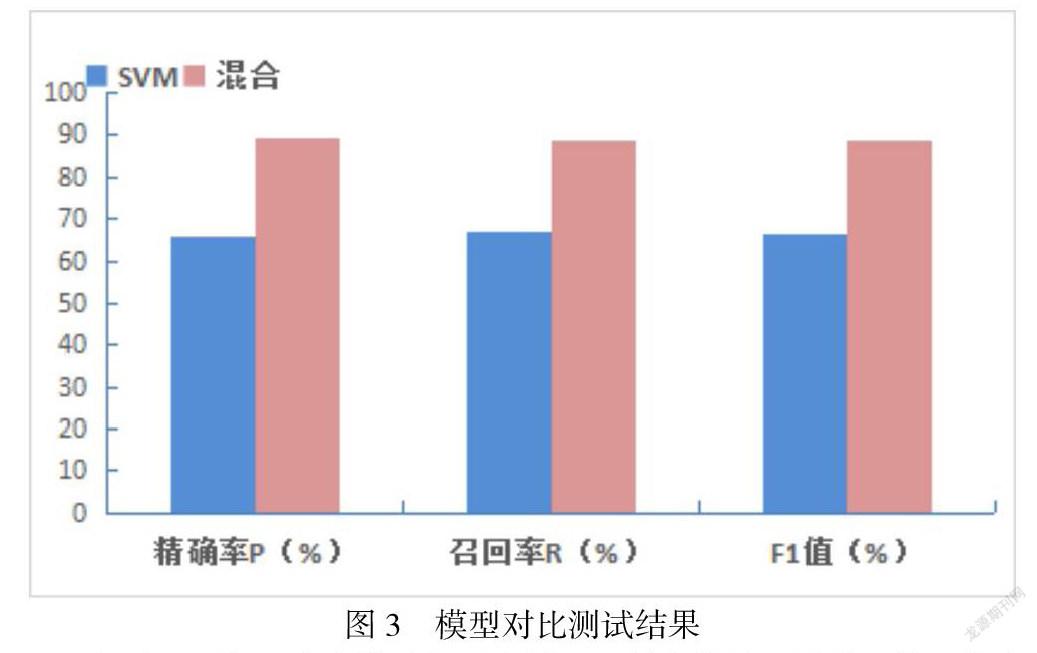
由表1可知,此次模型测试测出的精确率、召回率以及F1值得均值分别达到了89.57%、88.61%以及89.08%。为进一步评估构建的混合模型优越性,本文采取了对比分析法,利用单个传统机器学习SVM分类器,同样输入数据预处理后的关键情感词典及基础数据作为训练数据进行训练,使用相同测试指标进行测试,测试结果如图3:
由图3可知,本文构建的混合模型比单个传统机器学习模型精确率提升了23.58%、召回率提升了21.58%、F1值提升了22.58%,综合性能大大提高。
综上所述,本文构建的多策略混合文本关键情感詞识别模型整体性能优于单一传统机器学习模型,且具有良好的识别效果,应用于办公或项目管控场景,可以有效提高工作效率,提升企业审计智能化水平。
4.结束语
为有效迎接企业数字化转型新趋势,解决企业审计或办公人员面对海量数字化文档工作效率低、重复工作等问题,本文在传统机器学习SVM的基础上,加入文本预处理、TF-IDF算法、LDA算法,构建出一套多策略混合的文本关键情感词识别模型。通过模型测试及与单一SVM分类器模型的对比实验,结果显示本文构建的混合模型在性能上有了显著的提高。
参考文献:
[1]张膂.基于LPAL模型的超文本分析[J].微型电脑应用,2016,32(03):77-80.
[2]袁彬. 基于语义特征的文本分类算法研究[D].北京邮电大学,2016.
[3]焦桐. 面向微博文本的情绪内容分类系统设计与实现[D].北京邮电大学,2018.
[4]Pang B .Thumbs up? sentiment classification using machine learning techniques[J]. Proc. EMNLP,2002,2002.
[5]Sindhwani P V . Document-Word Co-regularization for Semi-supervised Sentiment Analysis[J]. IEEE Computer Society,2008.
[6]AAS ,AFL ,B M P . Sentiment analysisAn automatic contextual analysis and ensemble clustering approach and comparison[J]. Data & Knowledge Engineering,2018,115:194-213.
[7]Ting-Ting L I ,Dong-Hong J I ,Computer S O ,et al. Sentiment analysis of micro-blog based on SVM and CRF using various combinations of features[J]. Application Research of Computers,2015.
[8]张蕾,姜宇,孙莉.一种改进型TF-IDF文本聚类方法[J].吉林大学学报(理学版),2021,59(05):1199-1204.
[9]颜端武,梅喜瑞,杨雄飞,朱鹏.基于主题模型和词向量融合的微博文本主题聚类研究[J].现代情报,2021,41(10):67-74.
国家电网公司电力数据“口袋书”关键技术及产品设计研发科技项目基金支持。
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
科教导刊·电子版(2016年10期)2016-06-02
