
Deep Reinforcement Learning-Based Computation Offloading for 5G Vehicle-Aware Multi-Access Edge Computing Network
2021-12-03 02:13ZiyingWuDanfengYan
China Communications 2021年11期
Ziying Wu,Danfeng Yan
State Key Laboratory of Network and Switching Technology,Beijing University of Posts and Telecommunications,Beijing 100876,China
Abstract:Multi-access Edge Computing(MEC)is one of the key technologies of the future 5G network.By deploying edge computing centers at the edge of wireless access network,the computation tasks can be offloaded to edge servers rather than the remote cloud server to meet the requirements of 5G low-latency and high-reliability application scenarios.Meanwhile,with the development of IOV(Internet of Vehicles)technology,various delay-sensitive and compute-intensive in-vehicle applications continue to appear.Compared with traditional Internet business,these computation tasks have higher processing priority and lower delay requirements.In this paper,we design a 5G-based vehicle-aware Multi-access Edge Computing network(VAMECN)and propose a joint optimization problem of minimizing total system cost.In view of the problem,a deep reinforcement learningbased joint computation offloading and task migration optimization(JCOTM)algorithm is proposed,considering the influences of multiple factors such as concurrent multiple computation tasks,system computing resources distribution,and network communication bandwidth.And,the mixed integer nonlinear programming problem is described as a Markov Decision Process.Experiments show that our proposed algorithm can effectively reduce task processing delay and equipment energy consumption,optimize computing offloading and resource allocation schemes,and improve system resource utilization,compared with other computing offloading policies.
Keywords:multi-access edge computing;computation offloading;5G;vehicle-aware;deep reinforcement learning;deep q-network
I.INTRODUCTION
With the development and popularization of smart terminals,a large number of delay-sensitive and compute-intensive applications such as face recognition,natural language processing,live streaming and virtual/augmented reality(VR/AR)[1]have emerged,leading to explosive growth in mobile internet traffic[2,3].According to the report released by Cisco,in 2016,the global mobile internet traffic showed a growth by 74% year-on-year,and the global mobile internet traffic will exceed 30.6 exabytes per month by 2020[4].In this case,traditional centralized cloud computing services can no longer fully meet the needs of low latency,low energy consumption and high availability.Meanwhile,various near-end universal smart devices,such as radar,sensors and monitoring probes,etc.,have not been effectively used.Therefore,a new type of network computing mode,Multiaccess Edge Computing(MEC)is proposed,which is extended from the concept of Mobile Edge Computing.The basic idea is to deploy computing resources on the side close to people,things or the source of data and provide users with basic services such as network access,data storage,communication and task offloading,so as to achieve stable and rapid response to complex computation tasks[5–8].
With the development of intelligent vehicles,the demand for communication rate and reliable computing services for in-vehicle entertainment applications such as online games and vehicle security businesses such as autonomous driving(AD)[9]have brought the rapid development to vehicle MEC networks[10,11].Furthermore,the improvement of the 5G standard and the large-scale construction of 5G networks have enabled the continuous development of vehicle-to-everything(V2X)wireless communication technology,including vehicle-to-vehicle(V2V),vehicle-to-infrastructure(V2I),vehicle-to-pedestrian(V2P)and vehicle-to-network(V2N)[12].Key technologies of 5G such as Network Functions Virtualization(NFV)[13]and Network Slicing also provide greater communication advantages for the application of MEC in the Internet of Vehicles.
In general vehicle MEC network,the operators provide flexible real-time computing services by deploying Roadside Units(RSU)[14].MEC servers are densely distributed near the RSUs.Other network edge facilities,for instance,Base Station(BS)and Wireless Access Points(WAPs)can also be equipped with servers to provide edge computing service[4].The processing delay and energy consumption can be reduced by offloading tasks to the nearby MEC nodes through wireless transmission links.However,different from the traditional MEC network that supports low-speed mobile devices,the high-speed mobility of vehicles,time-varying topology of network and short interaction of information bring new challenges to computation offloading.During the movement of vehicles,the wireless channels are prone to fluctuations.Therefore,the real-time and reliability requirements of MEC servers are higher.What’s more,the interaction between the choice of access mode and resource allocation scheme makes computation offloading more complicated in the network environment where multiple access technologies coexist[15].
II.RELATED WORK
In this section,we review and summarize the related work about the optimization of MEC computation offloading policies.The research can be roughly divided into two categories,binary offloading decision and partial offloading decision.specifically,binary offloading decision means that tasks cannot be further divided,and can only be executed locally as a whole or offloaded to the MEC server for execution.The authors in[16]study the optimal binary computation offloading by a single user in an ultra-dense slice radio access network.In[17],authors combine the game theory and convex optimization algorithm to design a joint binary computation offloading scheme.In addition,Chen et al.use quadratic constrained quadratic programming transformation and separable semi-definite relaxation algorithm to solve the user offloading decision and resource allocation optimization problem,and proposed an effective approximation solution[18].Authors in[19]study the multiuser computation offloading problem for mobile-edge cloud computing in a multi-channel wireless interference environment.
Partial offloading decision means that mobile users can offload a portion of the task to the MEC server,which is more flexible than binary offloading decision.Related research on partial computation offloading focuses more on the balanced allocation strategy of resources.You et al.study the resource allocation problem of multi-user Mobile Edge Computation Offloading(MECO)systems based on Time Division Multiple Access(TDMA)and Orthogonal Frequency Division Multiple Access(OFDMA).They express the optimal resource allocation problem as a convex optimization problem to minimize weighted sum of mobile energy consumption under the computational delay constraint[20].Similarly,authors in[21]transform the delay minimization problem of a multi-user TDMA MECO system into a segmentation optimization problem and prove that the optimal data allocation strategy has a segmented structure.Based on this,an optimal joint communication and computing resource allocation algorithm is proposed.Considering the correlation between the dense deployment of MEC servers and users’computation tasks,Dai et al.propose a two-tier computation offloading framework.By jointly optimizing computing resources allocation,transmission power allocation and computation tasks offloading,the framework solves the problem of load balancing among multiple MEC servers and minimizes system energy consumption[22].
As machine learning has been a research hotspot in the computer field in recent years,Reinforcement Learning algorithms based on Markov Decision Processes have also been used to solve computation offloading problem.In[23],authors propose a DDLO algorithm based on deep reinforcement learning,which solve the computation offloading problem in a multi-server multi-user multi-task scenario.[24]proposes a Deep-Q Network based task offloading and resource allocation algorithm for the MEC to minimize the overall offloading cost in terms of energy cost,computation cost,and delay cost.Article[25]investigates the optimal policy for resource allocation in information-centric wireless networks(ICWNs)by maximizing the spectrum efficiency and system capacity of the overall network.Besides,Dong et al.construct an intelligent offloading system for vehicular edge computing by leveraging deep reinforcement learning.A two-sided matching scheme and a deep reinforcement learning approach are developed to schedule offloading requests and allocate network resources,respectively[26].A vehicle edge computing network architecture is explored in[27].Authors propose as vehicle-assisted offloading scheme for UEs while considering the delay of the computation task and use Q-learning algorithm to solve this problem.
In order to meet the demand for computation offloading in the future 5G network,we consider a 5G-based vehicle-aware Multi-access Edge Computing network(VAMECN)composed of vehicles,RSUs and cloud server,and propose a joint optimization problem of minimizing system delay and energy consumption.To solve the problem,a deep reinforcement learningbased joint computation offloading and task migration optimization(JCOTM)algorithm is proposed and its improvement is proved by simulation.The main contributions are summarized as follows:
· We model the communication and task computing process to derive the formula of system delay and energy consumption.And we apply Non-Orthogonal Multiple Access(NOMA)technology,the new access technology of 5G to improve spectrum efficiency and system access.
· As the mixed integer nonlinear programming problem is NP-hard,it is difficult to solve it directly.Therefore,we transform it into a Markov Decision Process and put forward a deep reinforcement learning-based joint computation offloading and task migration optimization(JCOTM)algorithm.
· Experiment performance illustrates the convergence and effectiveness of JCOTM algorithm.Compared with other computation offloading schemes,our proposed method can effectively reduce the processing delay and equipment energy consumption in different system environments.
The rest of this paper is organized as follows.In Section III,we describe the 5G-based vehicle-aware Multi-access Edge Computing network architecture and formulate the joint optimization problem.Section IV introduces Deep Q-Network and the detail procedure of JCOTM algorithm.Finally,we show the simulation parameters and results in Section V and conclude our research work in Section VI.
III.SYSTEM MODEL AND PROBLEM FORMULATION
3.1 5G-Based VAMECN System Model
As shown in Figure 1,we consider the 5G-based vehicle-aware MEC network architecture,consisting of N vehicles,M RSUs and a cloud server.Let V={1,2,...,N}and M={0,1,2,...,M,M+1}be the index set of vehicles and RSUs respectively.In particular,m=0 represents the local computing device and m=M+1 represents the cloud server.The number between 0 and M+1 denotes the edge server.Here,we assume that RSUs are evenly distributed along the road with the same coverage area R.Each RSU is equipped with one or more MEC servers so that it can be regarded as an edge computing node.In order to effectively simulate the moving trajectory of vehicles over time,the continuous road is described by discrete traffic areas.In Figure 1,a typical urban road network is divided into P discrete areas,whose index is represented by the set P={1,2,...,P}.Next,we will discuss the joint computation offloading and task migration optimization problem within a period of time T.We divide T into titime slots,which is denoted as T={1,2,...,ti}.
At the initial time slot t0,vehicles are randomly distributed in the network.When vehicles move,they may stay in the traffic area where it is currently located or drive to the adjacent traffic area.In order to describe the movement of vehicles,the transition proba-bility from location l to l′of vehicles can be expressed as Pr(l′|l).For example,Pr(l|l)=0.5 means that the vehicle will have a probability of 0.5 to stay at the same place.We assume that the probability of vehicles moving from l to l′(ll′)is the same.Thus,the position transfer probability can be calculated by
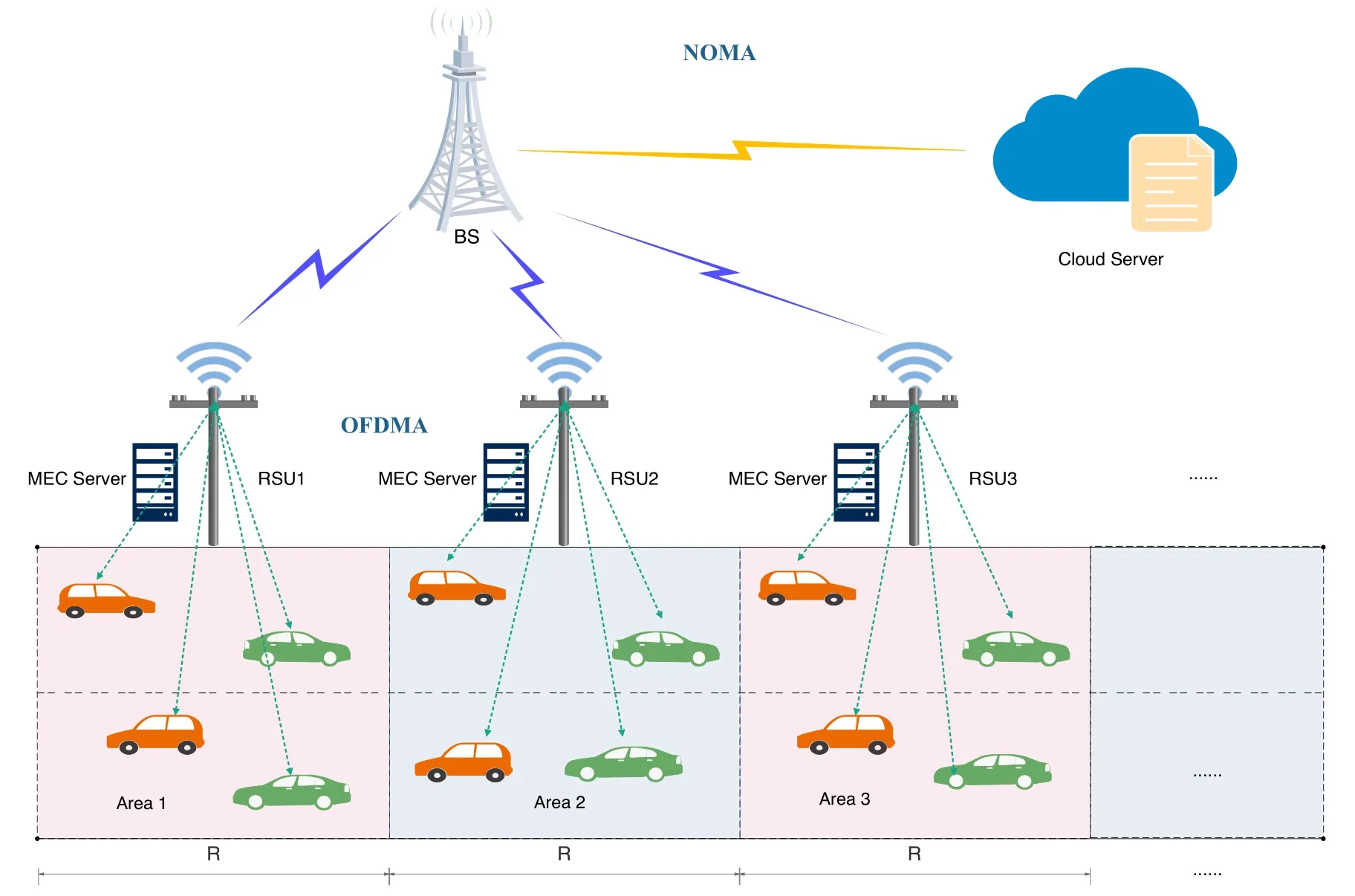
Figure 1.The architecture of our proposed vehicle-aware MEC network(VAMECN).
Assume that each user equipment(UE)has one compute-intensive task to be processed.Here,UE and vehicles have a one-to-one relationship.The n-th task can be described by a triple(αn,βn,γn),where n ∈ V,αnrepresents the data size of task,βnis the number of CPU cycles required to complete the task and γnis the maximum delay limit.We use the symbol xmn∈{0,1}to denote the binary offloading decision,for m∈M,n∈V.specifically,xmn=0 means that task n will be executed on the local UE,and xmn=1 means that task n will be offloaded to the m-th MEC server for execution.In particular,when m=M+1,task n will be offloaded to the cloud server.The offloading decision of the system at the t-th time slot is denoted as set X(t)={x01(t),...,x(M+1)1(t),x02(t),...,x(M+1)N(t)}.
Note that each UE can only connect to either one RSU or the BS during a time slot[26],so the following constraints should be satisfied
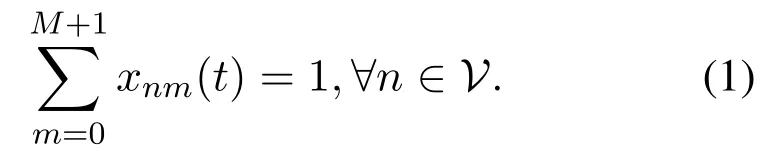
Next,we will discuss the communication model and computation model of the VAMECN system and derive the expression of delay and energy consumption.
3.2 Communication Model
Traditional communication relies on BS,so it brings transmission delay to upload data to the remote cloud server.Meanwhile,as the number of tasks increases,users compete for channel resources,which easily causes network fluctuations and high delays.Therefore,MEC can solve this bottleneck to a certain extent by deploying servers near users.
As one of the key technologies of 5G,the Non-Orthogonal Multiple Access(NOMA)uses nonorthogonal transmission at the transmitting end,actively introduces interference information,and correctly demodulates signal through Successive Interfer-ence Cancellation(SIC)at the receiving end[29–32].Compared with Orthogonal Frequency Division Multiple Access(OFDMA)[33],the receiver complexity is improved,but higher spectrum efficiency can be obtained.In the VAMECN system,as the BS is required to serve more users,NOMA is utilized for the communication links between UE and the BS,while OFDMA is utilized for the links between UE and RSUs.
In general,the channel state is a time-varying finite continuous value,where the state at the next moment is only related to the previous.In this paper,we discretize the state into L levels and further model them as a finite-state Markov Chains.Channel gain is an important parameter used to calculate the data transmission rate.We use the variable Γmn(t)to represent the channel gain of the wireless link between vehicle n and RSU m at time t,and its calculation formula is shown in equation(2)
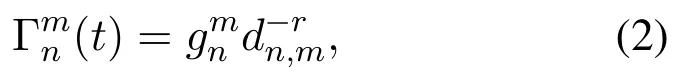
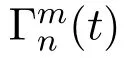
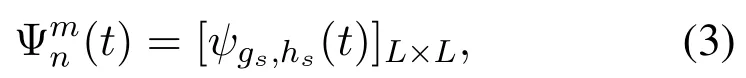
Thus,according to Shannon formula,the data transmission rate between vehicle n and RSU m at time slot t is calculate as follows
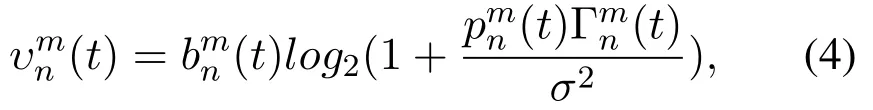
Next,we discuss the communication between vehicles and BS.Take the uplink as an example,when users are connected to the BS simultaneously,each UE will be allocated different transmission powers and signals will be superimposed to send.The superimposed signal is computed by
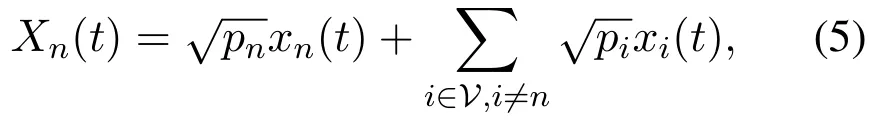
where xnand xirespectively represent the transmission signal of target user n and other users.The received signal is
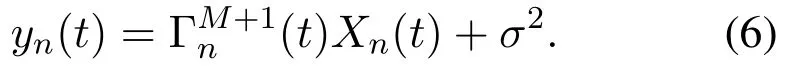
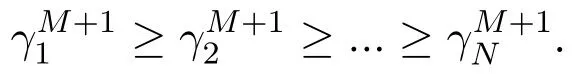
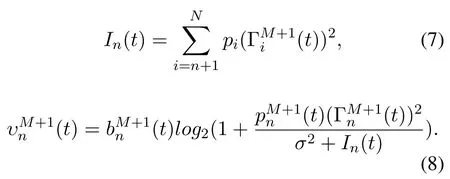
Thus,the data transmission rate of vehicle n can be uniformly expressed by equation(9)
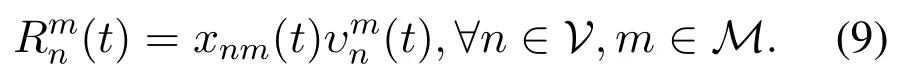
The communication delay and energy consumption of task n is show as follows
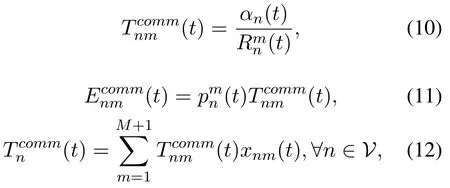
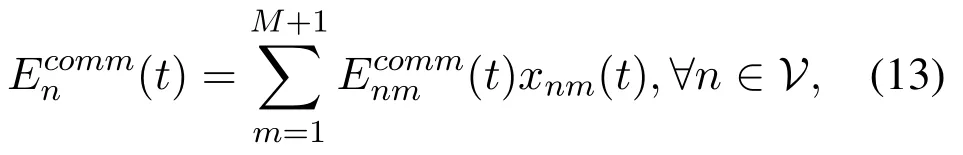
where αn(t)is the remaining data size of task n at time slot t.Here,the value of m starts at 1 rather than 0,for the reason that m=0 means the task will be processed locally,so there is no transmission delay and energy consumption.
3.3 Computation Model
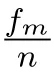
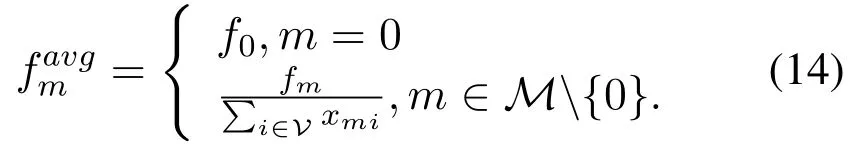
Hence,the processing delay for vehicle n can be expressed as
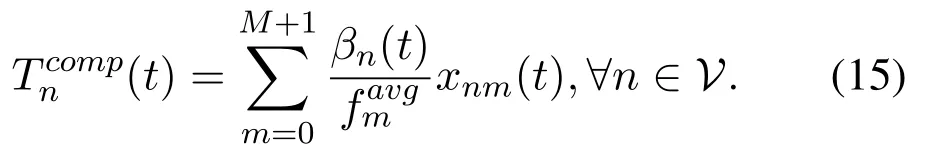
where βn(t)represents the rest number of the required CPU cycles of vehicle n at time slot t.It is obviously that the computation delay decreases as the computation power of servers increases.Meanwhile,the server load is also an important factor to consider for the reason that it affects the CPU time allocated to each user.
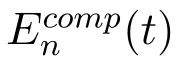
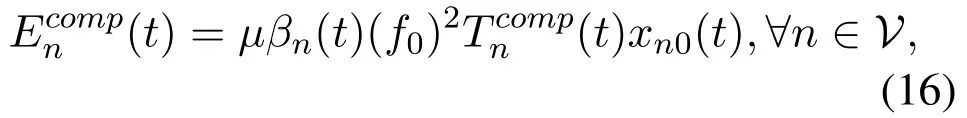
where μ=10-11is the effective switched capacitance[34].
3.4 Problem Formulation
We have modeled the communication and the computation process through the above discussion.Based on our previous analysis,we formulate the task completion latency and UE’s energy consumption as follows
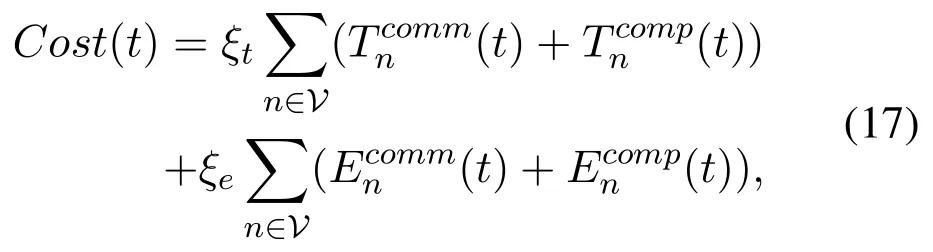
where ξt,ξe∈ [0,1]are two scalar weights representing latency and energy consumption,respectively.Note that the system latency is the maximum among the sum of communication and computation delay of all tasks.
Therefore,the joint computation offloading and task migration optimization problem(JCOTM)can be expressed as follows
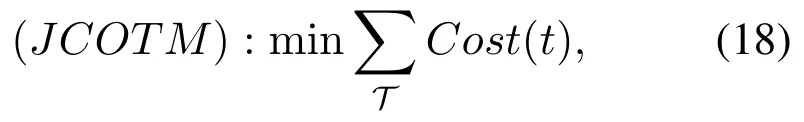
subject to:
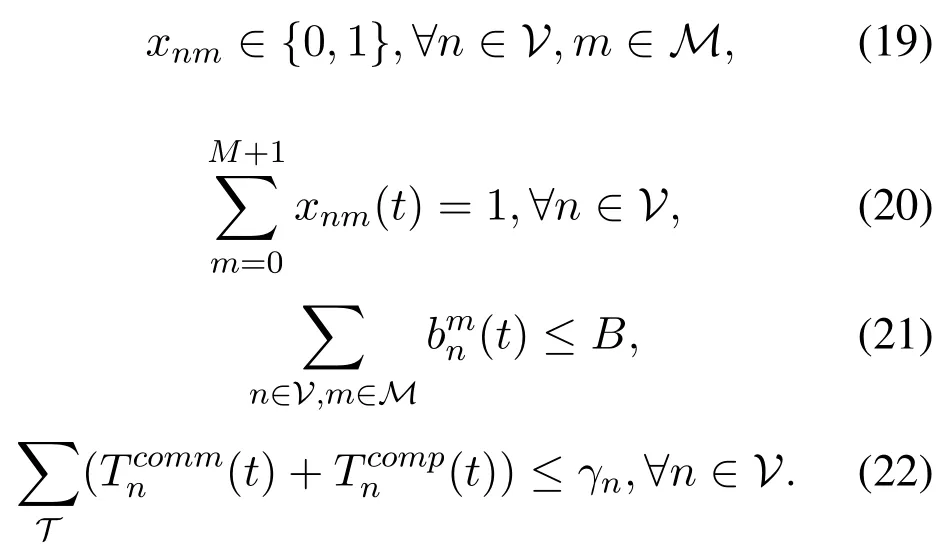
The notations and the definitions used in this paper are listed in Table 1.
The optimization problem JCOTM is a non-convex mixed-integer linearize programming problem,constrained by multiple variables.Due to the correlation between variables,it is difficult for us to solve it.Therefore,we model the original problem as a Markov Decision Process(MDP)and propose a promoted algorithm based on Deep Reinforcement Learning(DRL).

Table 1.Notations used in this paper.
IV.DEEP REINFORCEMENT LEARNING
As a branch of the artificial intelligence field,Reinforcement Learning(RL)is the third machine learning method after Supervised Learning(SL)and Unsupervised Learning(UL).In Reinforcement Learning,an agent learns to take actions that would yield the most reward by interacting with the environment[13].In Supervised Learning and Unsupervised Learning,the data is static and does not need to interact with the environment,such as image recognition,as long as enough difference samples are given, the deep network can learn the difference between samples through iteration training.However,the learning process of RL is dynamic and interactive,and the required data is also generated through continuous interaction with the environment.Therefore,compared with Supervised Learning and Unsupervised Learning,Reinforcement Learning involves more objects,such as action,environment,state transition probability and reward function.Thus,Reinforcement Learning can better solve problems in situations approaching real-world complexity[35].
Generally,reinforcement learning algorithms can be divided intoModel-FreeandModel-Basedreinforcement learning.Here,‘Model’refers to the model of the environment.The main difference between the two algorithms is whether the agent knows the environment model.The advantage of Model-Based is that the agent can plan the action path in advance based on the known environment elements.However,due to the error between the learned model and the real environment,the expected result is difficult to be achieved.Therefore,Model-Free is often easier to implement and adjust.Model-Free algorithms can be divided into three categories,that isValue-Based,Policy-BasedandActor-Critic.specifically,the value-based algorithms obtain policy by learning the value function or the action-value function,while the policy-based algorithms model and learn the policy directly.The Actor-Critic algorithms combine the advantages of the other two methods.Actor selects action according to policy,while Critic outputs the value of action.Therefore,policy and value function influence each other so that the convergence process is speeded up.
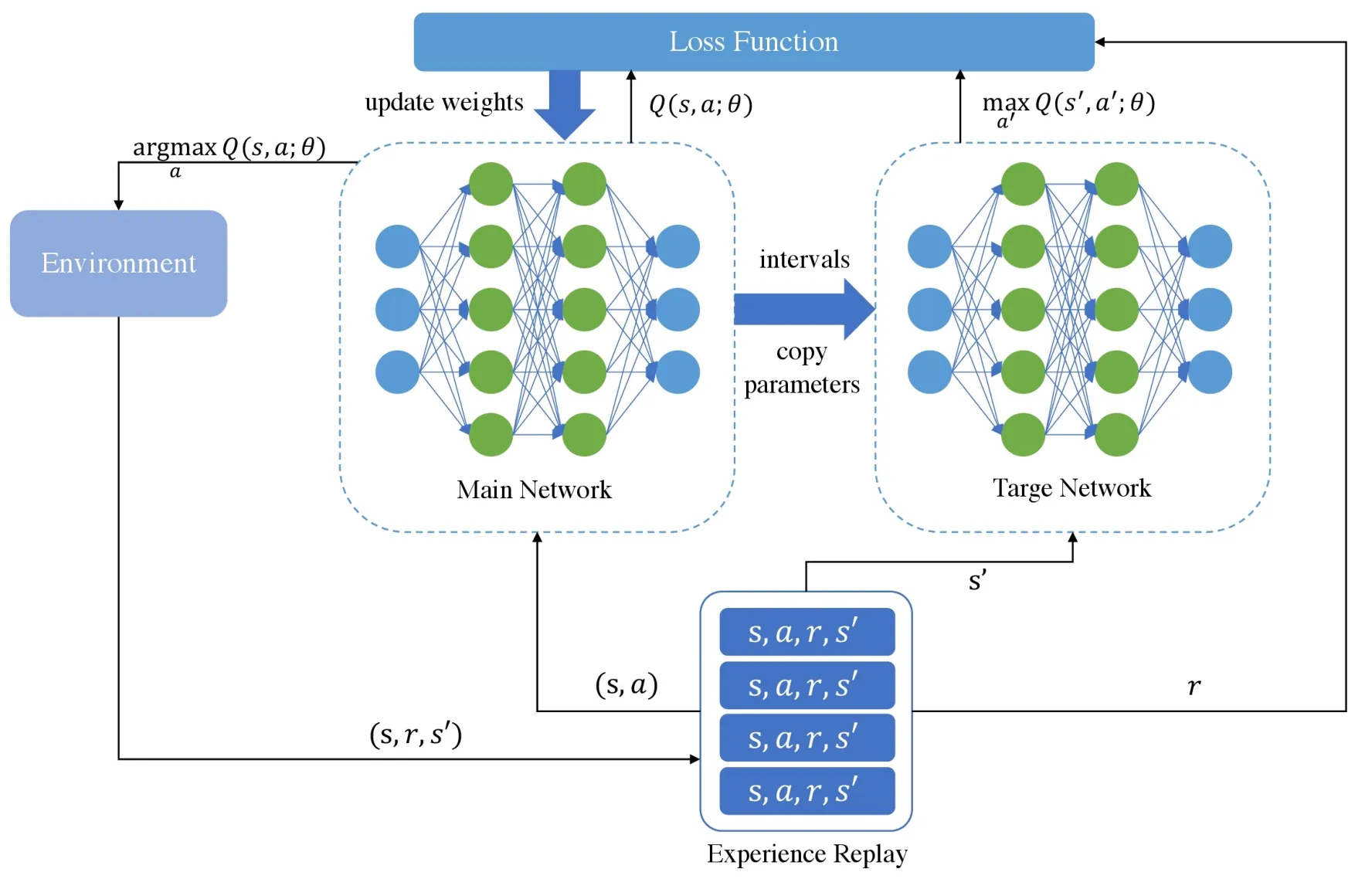
Figure 2.The structure of DQN.
Q-learning is a classic value-based reinforcement learning algorithm.Agent learns Q-values of stateaction pairs and selects the action with the highest Q-value.Q-value is denoted as Q*(s,a)=maxπE[rt+γrt+1+ γ2rt+2+...|st=s,at=a,π],which is the expected reward obtained by taking action a(a∈A)under state s(s∈S)at some point[35].Q-learning uses Q-table to store the Q-values of all state-action pairs and optimizes the policy by updating the entire Q-table in every iteration.The update function of Q-value is given by
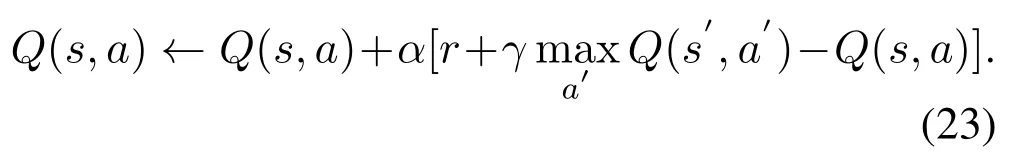
In Equation(23),s is the current state,a is the action taken at s,s′is the next state after taking action a,and a′is the next action that could be taken at state s′.Parameter α and γ denote learning rate and discount factor,respectively.r is the reward caused by choosing action a.It can be seen that Q-learning uses the maximum Q-value of next state to update the current Q-value.Here,r+ γ maxa′Q(s′,a′)represents the target Q-value,while Q(s,a)is the estimated Q-value.Obviously,the Q-table will become in finite and take larger storage space when the state space and action space are too large.To solve the problem,a promising algorithm,DQN(Deep Q-Network)is proposed,which combines the deep neural network and the Q-learning algorithm.
4.1 DQN Algorithm
DQN is proposed by Google DeepMind Technologies in 2013,which can be regarded as a milestone of Deep Reinforcement Learning.The structure of DQN is shown in Figure 2.Compared with the traditional Q-learning,there are two core improvements in DQN.Firstly,it transforms the update process of Q-table into a function fitting problem,which generates Q-values by fitting a function instead of Q-table.In DQN,Q-values are predicted by deep neural network.There are mainly two neural networks.The one is target network whose parameters is relatively fixed and the other one is main network that updates the parameters for each iteration.The target network copies the parameters from main network at the same intervals.Therefore,only the main network is truly trained through back propagation.Secondly,a special structure is used to store every step of the agent,which is called experience replay and represented by(s,a,r,s′).During each training iteration of the network,a batch of experience will be extracted randomly from experience replay for learning.Because Q-learning is an off-policy algorithm,it can learn from the current experience and the past experience.So,in the learning process,the random addition of previous experience will make the neural network more efficient and the correlation between training samples will be broken.DQN updates at iteration i using the following loss function
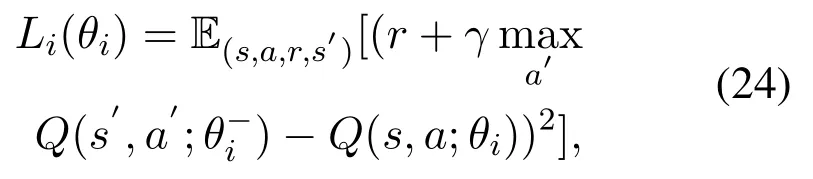
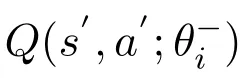
4.2 JCOTM Algorithm
In this subsection, we formulate the optimization problem JCOTM as a DRL process. Here, we set a centermanagement system as the agent, responsible for interacting with the environment and making decisions.Thus, the agent will collect the status information fromservers and vehicles and broadcast the computation offloading decisions to all UE.
In order to apply DQN to solve our proposed problem,we are supposed to define the three key factors of DQN in our algorithm that isState,ActionandReward function.Sate is used to describe the environment model,while action is the possible specific behavior of each step.Reward function is used to calculate the reward generated by each action,which could be positive or negative.
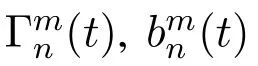
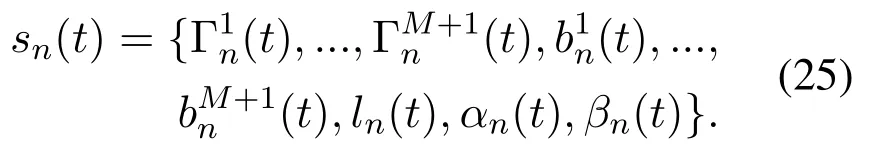
· Action:The binary offloading decisions is denoted as vector an(t)∈ RM+2that denotes whether task n is offloaded to server m.For each time slot t,agent is supposed to choose one action and environment moves from the current state to the next state.an(t)is defined as follows
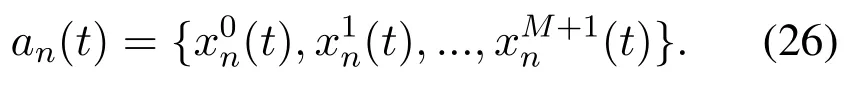
· Reward function:Reward is an indicator value that the environment feeds back to the agent to judge whether the selected action is good.In this paper,the optimization goal is to minimize the system cost made up of the latency and energy consumption.Thus,we set system cost as the reward function
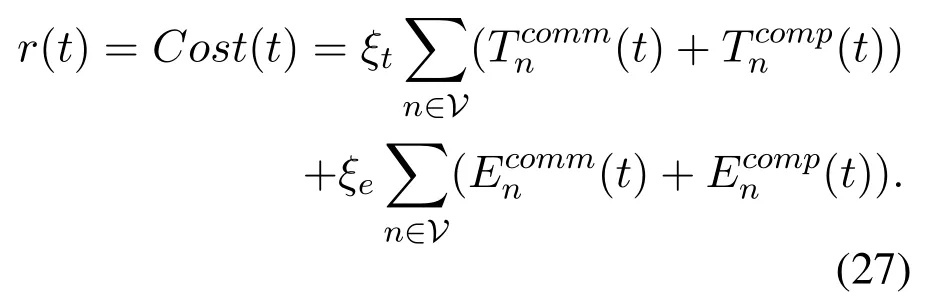
The structure of the deep reinforcement learningbased JCOTM algorithm is shown in Figure 3.We use k deep neural networks(DNN)with the same structure to predict binary offloading decisions.The input of the neural network is the current state of environment,and the output is the action.Here we add a decode layer after the output layer to convert the decimal values into binary.In our proposed offloading model,the dimension of binary action vector is N(M+2).
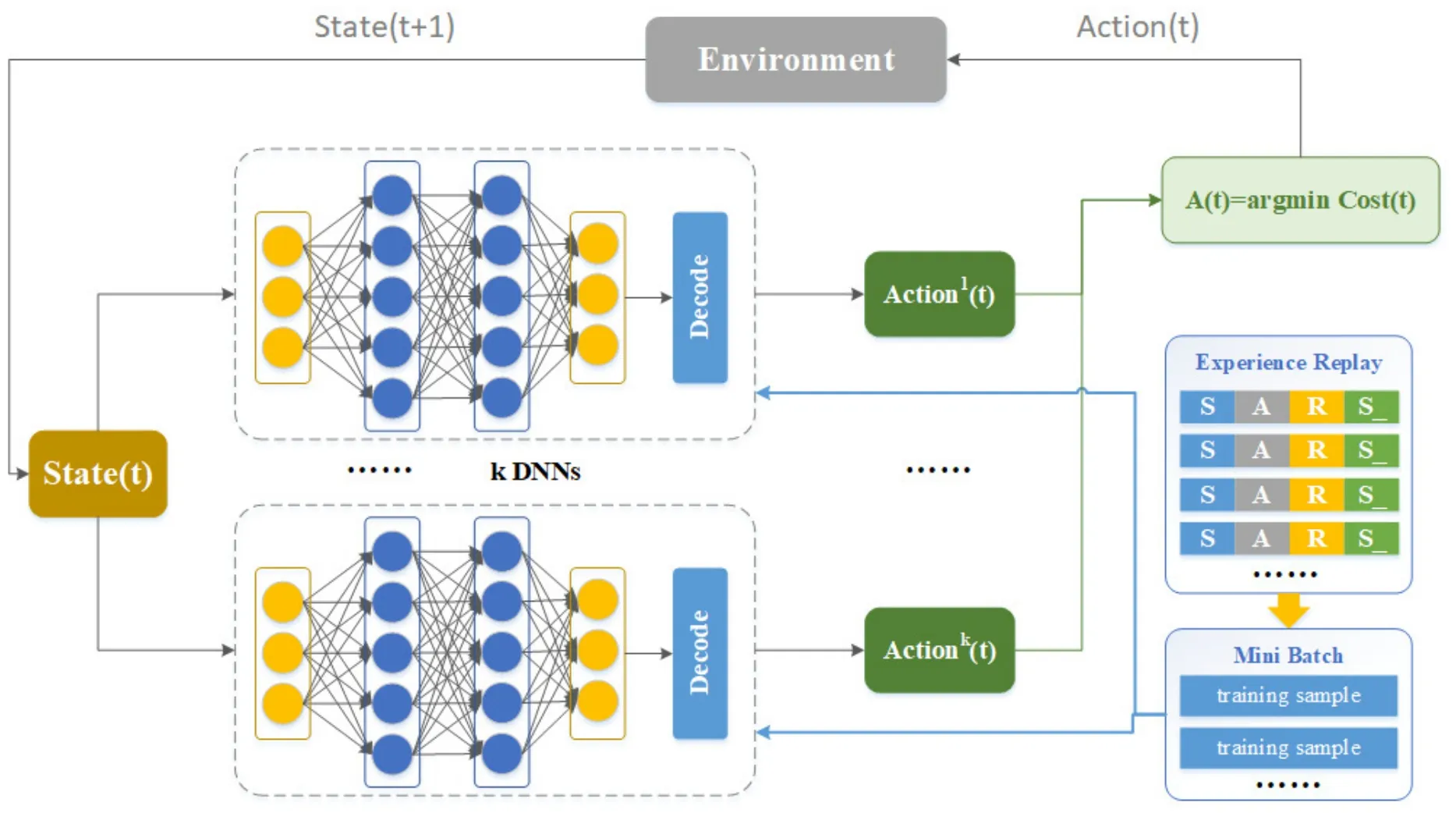
Figure 3.The architecture of our proposed JCOTM algorithm.
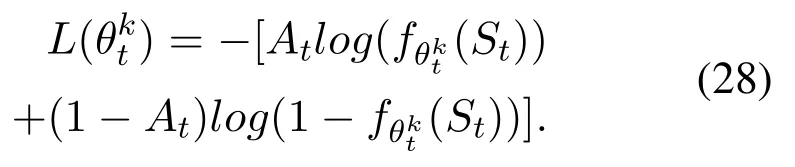
The pseudo code of JCOTM algorithm is shown in Algorithm 1.
V.SIMULATION ANALYSIS
In this section,we design different simulation experiments to evaluate the performance of our proposed JCOTM algorithm.The simulation environment is mainly based on Python 3.7 and TensorFlow.Firstly,we verify the convergence of JCOTM algorithm by adjusting the key parameters in model.Then,we compare the average system offloading cost of JCOTM with other task offloading policies to evaluate the advancement of the deep reinforcement learning-based computation offloading algorithm.

We set the number of RSUs M=4 and the number of vehicles N=15 to build a resource-constrained vehicle-aware MEC network.The road is divided into P=4 traffic areas and each area is equipped with one RSU,whose coverage diameter R=1km.We consider the CPU frequencies of each UE,each edge server and the cloud server are 0.6×109,1×1010and 1×1012,respectively.The total bandwidth B is 10MHz and the Gaussian white noise power σ2is-88dB.We assume that the data size of task n αnis distributed between 10M and 30M and the required CPU cycles of one byte is ρ=960 Cycles/Byte[23].Some key parameters are listed in Table 2.Next,we will conduct simulation experiments and analyze the simulation results.
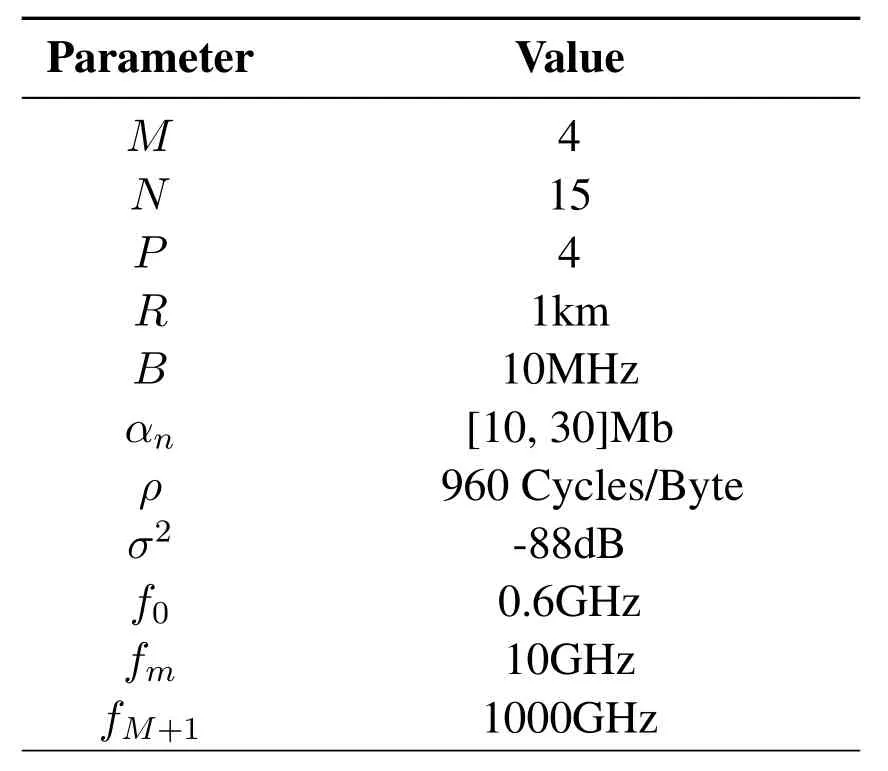
Table 2.Simulation parameters.
5.1 Convergence of JCOTM
In order to verify the convergence of JCOTM,we usereward ratioas the evaluation indicator,which is the ratio between the cost of the optimal offloading policy by enumerating and the cost of the policy generated from JCOTM.Therefore,the closer the reward ratio is to 1,the better the algorithm performance.The formula is defined as
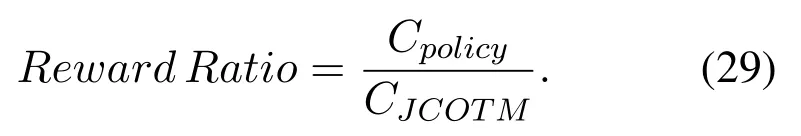
Figure 4 shows the effects of learning rate on convergence and reward ratio.We set the values of the learning rate to 0.1,0.01,0.001 and 0.0001,respectively.It can be seen from the figure that the four curves tend to converge as the number of iterations increases.When learning rate is 0.0001,the reward ratio reaches the lowest value 0.85.When learning rate is 0.1 and 0.001,JCOTM algorithm can converge to the maximum reward ratio after about 750 iterations.Therefore,we can set the learning rate to 0.1 or 0.001.
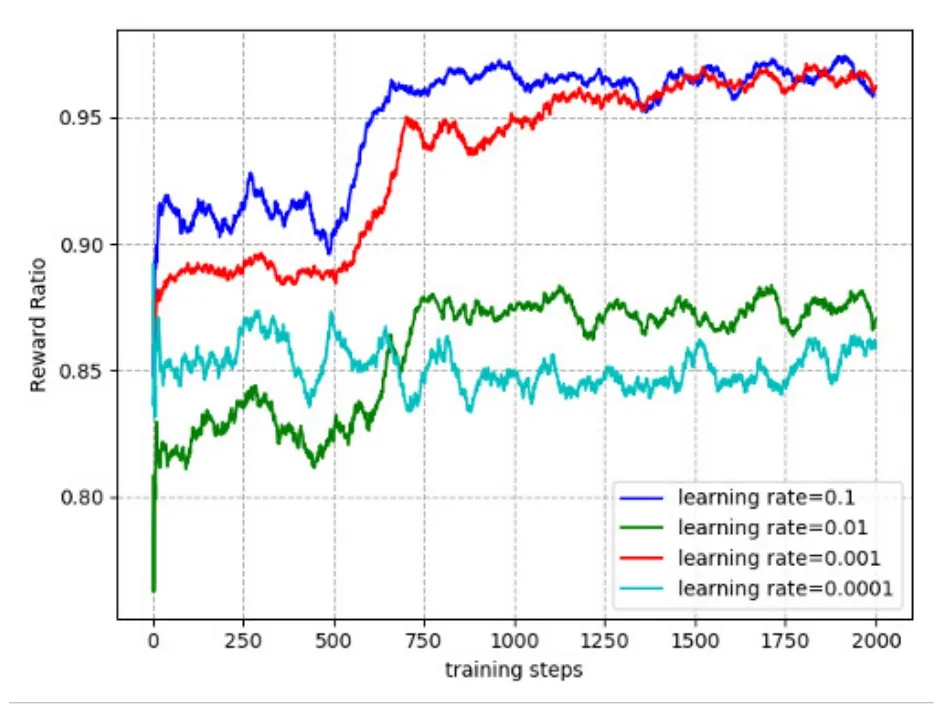
Figure 4.The convergence performance of JCOTM under different learning rates.
Figure 5 shows the convergence performance of JCOTM algorithm under different batch sizes.The batch size is set to 32,64,128,and 512,respectively.As shown in Fig.5,the curve converges after about 750 iterations.When batch size is 64 and 128,the two curves finally converge to the value 0.95.When batch size is 32,the value of reward ratio is the highest,which is around 0.96.Considering that too many batch samples will increase the execution time,we set the batch size to 32.
Figure 6 shows the impact of different training intervals on the convergence performance of JCOTM.Training interval is the number of steps for the target network to copy the hyper-parameters from the main network.The curves with different values of training intervals tend to converge after about 750 iterations.Obviously,the reward ratio is the highest when training interval is 30.Therefore,we set the training interval to 30.
Figure 7 shows the convergence performance of JCOTM algorithm under different values of k.The highest reward ratio exceeds 0.96 when the value of k is 5 and 4.In general,the more DNNs,the more possible to obtain the optimal offloading strategy,because the DNNs will output more actions to be selected.Considering that more DNNs require more computing resources,we set the value of k to 4.
5.2 Performance of Different Offloading Policies
In this subsection,we evaluate the performance of different computing offloading policies.Besides the JCOTM algorithm we proposed,the other offloading policies are introduced as follows.
1.Local Computing:Local computing means that all tasks are processed by local UE rather than offloaded to servers.The system cost is the weighted sum of local computing delay and devices’energy consumption.
2.Edge Computing:In contrast to local computing,edge computing refers that all tasks are offloaded to edge servers for processing.The system cost includes computation delay,transmission delay and energy consumption of UE caused by data transmission.In this section,Edge Computing means that all tasks are offloaded to one MEC server for execution.
3.Cloud Computing:Cloud computing means that all tasks are offloaded to the cloud server,similar to the traditional cloud computing services provided by operators.The transmission delay and energy consumption are relatively larger,for the reason that the cloud server is far away from users.
4.Random Computing:Random computing is a kind of policy where the offloading decisions are generated randomly.Therefore,each task may be executed locally or at the edge or on the cloud.
5.DGTA:We regard the comput offloading problem in VAMECN as a dynamic non-cooperative game model and use DGTA to obtain the Nash Equilibrium solution of the game model[37]DGTA is a distributed computation offloading algorithm based on Game Theory where each user can choose an optimal offloading strategy during each iteration to minimize the offloading cost.
In Figure 8,we compare the average system offloading cost of the six offloading policies under different number of vehicles.It can be seen that the system cost gradually rises with the increasing number of vehicles for all policies.Obviously,more vehicles mean more tasks are processed so that the time and energy cost will increase.From Figure 8,we can see that JCOTM has the lowest offloading cost in contrast to the other offloading policies and DGTA achieves the suboptimal offloading performance.Besides,cloud computing performs better than random computing,while random computing performs better than edge computing and local computing.In addition,when the number of vehicles is less than 16,the offloading cost of local computing strategy is greater than that of edge computing,while the performance is opposite when the number of vehicles is more than 16.The reason is that when a large number of tasks are offloaded to the same MEC server,the computing resources that each user can be allocated will decrease,resulting in the increase of computing cost.
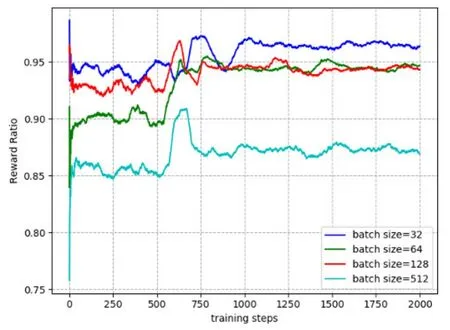
Figure 5.The convergence performance of JCOTM under different batch sizes.
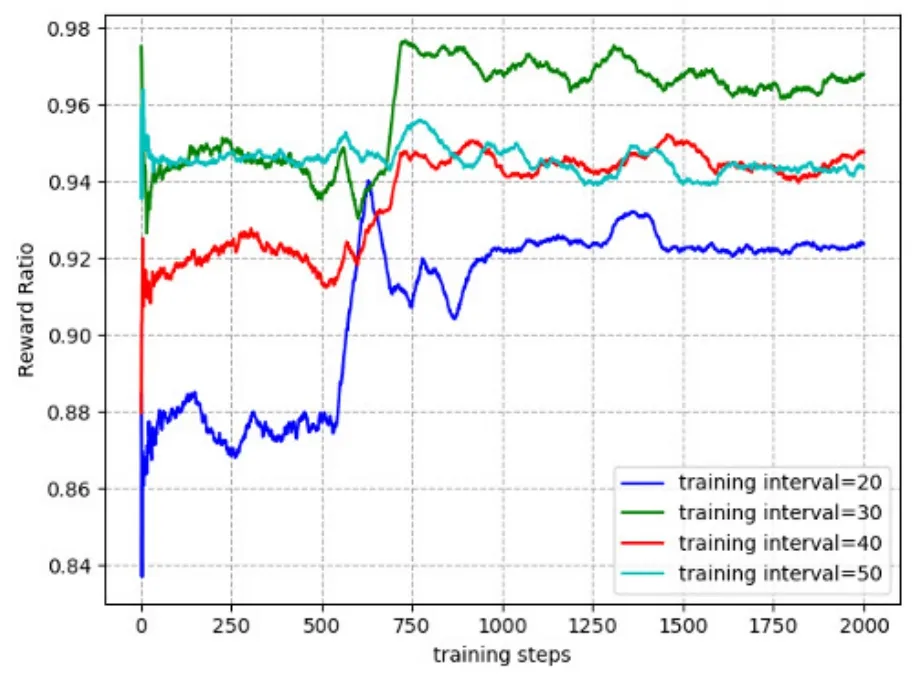
Figure 6.The convergence performance of JCOTM under different training intervals.
Figure 9 shows the comparison of the average system offloading cost under different data sizes of tasks.Here,we separately calculated the offloading cost with the data size range of 10MB to 80MB.As the data size of tasks increases,the average cost of computing offloading gradually increases.Obviously,JCOTM outperforms the other offloading policies,because it optimizes the system resource allocation while other policies only use a certain type of computing resources or do not achieve the optimal system resource allocation.The offloading cost of local computing strategy is the highest,followed by edge computing.In contrast,the average system offloading cost of cloud computing,random computing and DGTA are lower.
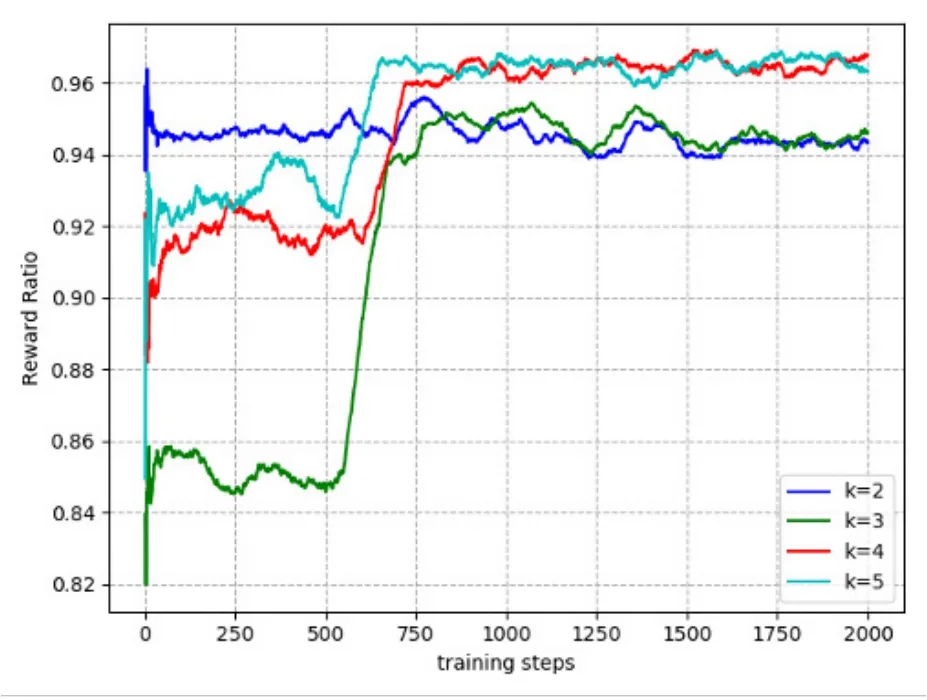
Figure 7.The convergence performance of JCOTM under different values of k.
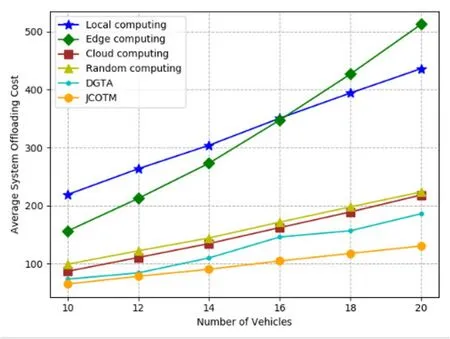
Figure 8.Comparison of average system offloading cost under different number of vehicles.
Figure 10 illustrates the impact of different number of MEC servers on the average system offloading cost.Obviously,local computing and cloud computing are unaffected so that the curves are straight lines parallel to the x axis.As shown in Figure 10,with the increase of the number of MEC servers,the offloading cost curve of edge computing is also similar to a horizontal straight line.This is not difficult to understand,because all tasks are offloaded to one MEC server to compute under edge computing policy so that the increase in the number of MEC servers has little impact on the offloading cost.For random computing and DGTA policies,more MEC servers can reduce mode computing delay,so the curves decrease as the number of MEC servers increases.We can see from the figure that the average system offloading cost of JCOTM is almost independent of the number of MEC servers.One possible explanation is that the resourceconstrained environment we have simulated can just meet the computing requirements of all users so that the cost curve does not show a significant decrease trend.
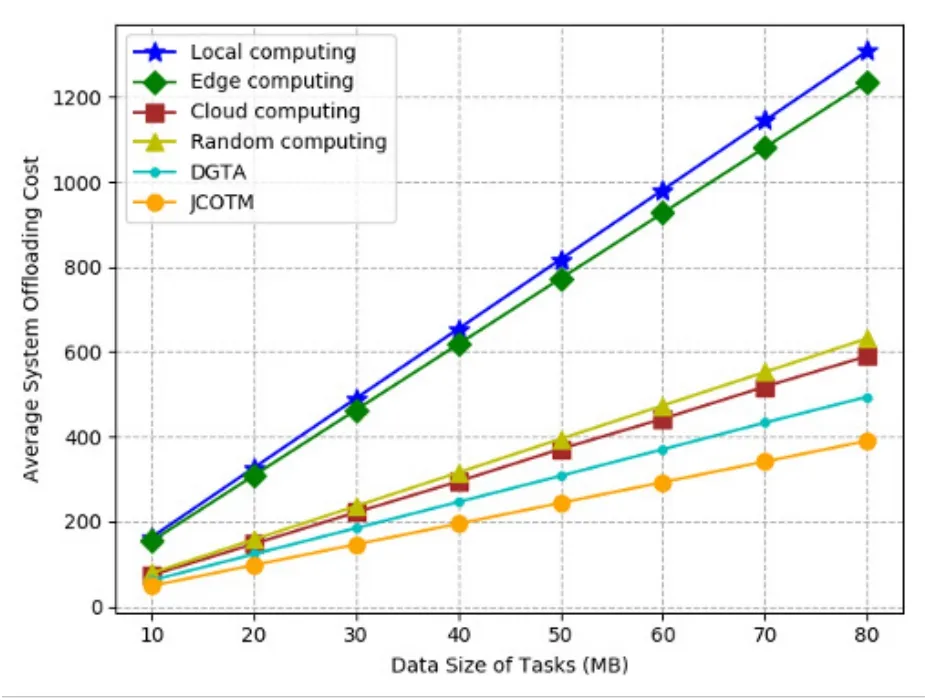
Figure 9.Comparison of average system offloading cost under different data size of tasks.
Figure 11 shows the comparison of the average system offloading cost under different computing capacity of MEC servers.Similarly,local computing and cloud computing are not affected by the computing capacity of MEC servers.We can conclude from the figure that the stronger the computing capacity of MEC servers,the lower the offloading cost.And,with the increase of the computing capability of MEC servers,the rate of descent of the offloading cost also gradually becomes smaller.The average system offloading cost of JCOTM is lower than the other policies.What’s more,when the computing capacity of MEC servers grows to more than 30GHz,edge computing achieves the lower offloading cost than cloud computing,and when it grows to more than 40GHz,edge computing performs better than random computing.It can be concluded that the computing capacity of MEC servers has a relatively large impact on the average system offloading cost.
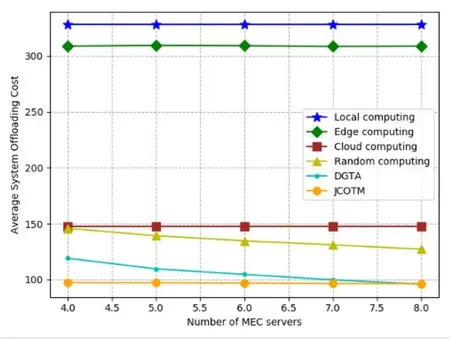
Figure 10.Comparison of average system offloading cost under different number of MEC servers.
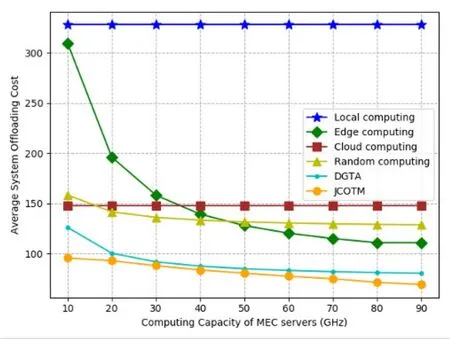
Figure 11.Comparison of average system offloading cost under different computing capacity of MEC servers.
VI.CONCLUSION
Aiming at the joint multi-user computation offloading and task migration optimization problem under vehicle-aware Multi-access Edge Computing network,this paper comprehensively considers multiple factors such as concurrent multiple computation tasks,system computing resources distribution and communication bandwidth,proposing a deep reinforcement learningbased JCOTM algorithm to minimize system delay and energy consumption.In the process of problem modeling,we fully consider the Non-Orthogonal Multiple Access technology in the future 5G network to improve the communication rate and quality and reduce the communication delay.The algorithm abstracts the system resources and the offloading policy into the environment state and the binary action vector,respectively.And deep neural network is applied to predicting offloading decision.Agent perceives the environment state by multiple iterative training until the optimal offloading decision is obtained.In order to evaluate the convergence and performance of the algorithm,we design the simulation experiments.The simulation results show that JCOTM converges under different values of algorithm parameters and performs better than other offloading policies under different experiment conditions.Therefore,the algorithm proposed by us can effectively reduce the total delay and energy consumption of VAMECN system.
ACKNOWLEDGEMENT
This work was supported in part by the National Key R & D Program of China under Grant 2018YFC0831502.

- China Communications的其它文章
- On Treatment Patterns for Modeling Medical Treatment Processes in Clinical Practice Guidelines
- IoT-Fog Architectures in Smart City Applications:A Survey
- Pilot Allocation Optimization Using Enhanced Salp Swarm Algorithm for Sparse Channel Estimation
- Put Others Before Itself:A Multi-Leader One-Follower Anti-Jamming Stackelberg Game Against Tracking Jammer
- DCGAN Based Spectrum Sensing Data Enhancement for Behavior Recognition in Self-Organized Communication Network
- Organization-Driven Business Process Configurable Modeling for Spatial Variability