
基于深度学习的Spark 电影推荐系统设计
2021-12-02 08:19关凯轩禹素萍
科学技术创新 2021年32期
关凯轩 禹素萍
(东华大学信息科学与技术学院,上海 201620)
随着互联网的快速发展,各行各业的信息资讯正在呈爆炸式增长的态势。在信息过载[1]的时代,如何快速在海量信息中找到自己感兴趣的信息成为当务之急,推荐系统在这样的时代背景下应运而生。
推荐算法经历了从传统的协同过滤[2],因子分解机到深度学习算法大行其道的发展过程,尤其是2015 年之后,随着Wide&Deep[3],FNN[4]等一大批深度推荐模型的提出,深度学习模型成为了推荐系统的主流,推荐效果越来越好。同时,海量数据的处理需求也催生了大数据平台工具的进化,大数据存储,传输,计算等组件发展日趋成熟。
深度学习模型的表达能力强,与传统模型相比能够进行特征间的深度交叉,从而挖掘出特征间更多的潜藏信息,网络结构也可以随着业务不同而改变,十分灵活。而Spark,Flink 等大数据计算框架擅长从后端数据库,日志系统等数据中提取中模型训练所需的样本数据,为深度模型提供材料。
本文主要在现有推荐算法的基础之上,结合大数据处理工具对推荐系统进行设计。通过TensorFlow平台实现DIN[5]深度学习模型的端到端训练与部署;通过HDFS,Spark,Kafka 等大数据技术保证海量用户物品数据,模型数据存储的稳定,计算的实时高效。二者的结合保证了推荐系统的运行的稳定和推荐的良好效果。
1 系统设计
1.1 系统架构
系统采用模块化结构设计。各模块之间相互分离,耦合程度低,从而方便后续的维护与拓展。推荐系统整体架构设计如图1 所示。

图1 推荐系统整体架构设计
推荐系统由数据存储,特征处理,模型离线训练,模型线上服务与网站前后端设计等部分组成。各部分的功能如下:
1.1.1 数据存储层
主要负责用户特征,物品特征,用户Embedding,物品Embedding 等特征数据以及训练模型数据的存储。为了解决模型线上服务响应的实时性与海量用户物品特征存储的问题,采用分级存储方式。HDFS 容量近乎无限大[6],但访问速度慢,适合用来存储历次处理的全量数据与模型数据;MySQL 作为关系型数据库,用于存储用户注册登录信息,电影相关信息等,用作网站后端数据库使用;Redis 作为内存型数据库,访问速度快,用来载入线上服务所需特征;Elasticsearch 提供全文检索功能,作为搜索服务器提供电影全文检索功能。
1.1.2 数据与特征处理
数据处理部分主要负责推荐系统的用户行为日志处理、数据存储层数据的聚合更新、推荐模型训练样本数据与线上特征的生成等。Spark 离线计算能力强,并且有Spark MLlib 库,可以用来定时生成模型离线训练数据和线上特征更新,Flink 作为流处理引擎,可以实时处理用户行为日志,改变用户的特征,从而实现用户的个性化实时推荐效果。
1.1.3 离线模型训练
离线训练模块可以利用TensorFlow 平台实现深度学习模型,利用Spark MLlib 计算用户物品Embedding 以及实现协同过滤等传统模型。Embedding 和传统模型可以实现物品的快速召回,深度学习模型用来对召回的物品进行精排,生成最终的Top-N 推荐列表。
1.1.4 模型线上服务
线上服务要负责与网站后端,离线模型与数据存储部分交互。使用TensorFlow Serving[7]可以实现模型的端对端训练,端对端部署。将离线训练好的模型载入TensorFlow Server 并部署在Docker 容器中,后端服务器通过Http 请求获取候选物品的模型推断结果,通过模型返回的预测评分完成对候选物品的排序,从而完成推荐服务。
1.1.5 网页前后端设计
采用SSM 后端框架以及JQuery,AJAX 等前端技术实现了推荐系统网站的常见功能。
1.2 系统功能
推荐系统只实现了电影推荐的核心功能,因此设计尽可能简洁。功能设计如图2 所示。

图2 系统功能设计
1.2.1 用户主题
用户主题实现用户的历史行为展示,如评分记录,搜索记录等,与此同时用户的行为数据会被后端系统实时记录到日志文件中,并通过Flume,Kafka 传输,交给Flink 流处理平台处理后作为用户实时推荐的特征数据。
为你推荐列表也展示在用户主题中,通过召回,排序策略为用户生成可能感兴趣的Top-N 电影。
1.2.2 电影主题
电影主题下主要包括电影的描述信息,电影平均评分等统计信息以及由推荐算法计算得到的Top-N 相似电影列表。
1.2.3 网站首页
首页包含了按类别分类电影信息的展示和电影搜索框。电影搜索功能由全文检索引擎Elasticsearch 实现,同时用户搜索记录通过后端埋点记录后可以作为用户的行为特征。
2 推荐策略
出于工程上的考虑,推荐系统中经常把推荐模型分为召回和排序两个阶段。召回阶段负责把大规模的候选集快速缩减到几百量级的规模,为了召回速度快,常采用简单模型;排序阶段负责得到精准的排序结果,因此要尽可能的利用所有特征,并使用复杂模型充分挖掘特征。
为了保证物品的召回速度与召回率的平衡,本文采用基于Embedding 的召回方法,并使用局部敏感哈希[8](Locality Sensitive Hashing,LSH)进行快速Embedding 最近邻计算;为了实现对多特征的精准排序,排序层使用引入注意力机制的DIN 模型。
2.1 召回层算法
Embedding 起源于自然语言处理领域谷歌提出的Word2vec[9]模型,基本思想是基于一组词序列训练得到Embedding,用Embedding 间的内积距离表示词之间的接近程度。Item2vec 是Word2vec 在推荐系统界的推广,把词序列换成了用户的观看序列,购买序列等,从而可以通过用户已观看序列推断用户感兴趣的物品序列。
假设Item2vec 中一个长度为K 的用户历史记录为w1,w2,…,wk,则Item2vec 的优化目标为:
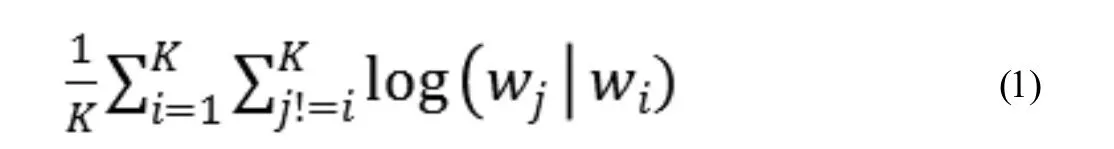
Item2vec 利用wi向量来预测wj向量,可以转换为图3 的神经网络结构,利用梯度下降训练参数。输入向量矩阵WV×N的每一个行向量对应的就是我们要找的Embedding。

图3 Item2vec 的模型结构
Spark MLlib 库提供了Item2vec 模型,利用Spark 处理rating表(如表1 所示),按时间戳进行排序后,就可以得到用户的近似评分序列,从而训练出电影的Embedding,用户的Embedding 可以由该用户观看过的电影Embedding 加权平均后得到。训练完成后将Embedding 存入到Redis 内存数据库中,方便召回时实时获取。
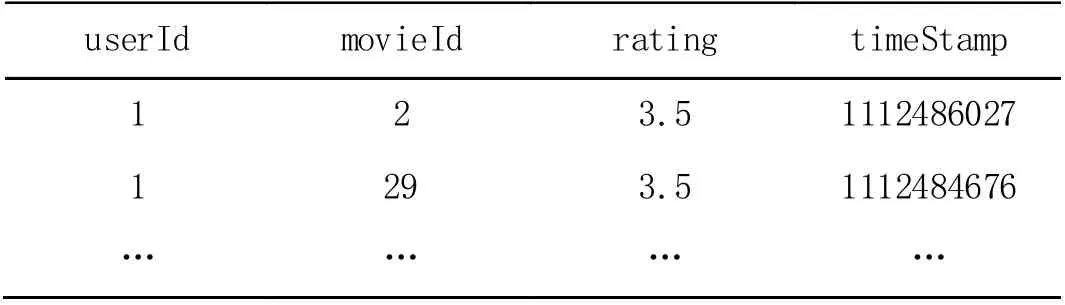
表1 MovieLens rating 表
在召回时,需要逐一计算物品Embedding 之间的相似度,在面对大规模数据集时十分耗时,为了提高召回效率,可以采用局部敏感哈希的方法。
局部敏感哈希(LSH)基于这样的思想:原始数据空间中的两个相邻数据点通过相同的哈希函数映射后,在新的数据空间中相邻的概率仍然很大,而不相邻的数据点相邻的概率很小。因此,对Embedding 进行哈希映射后,相邻的Embedding 大概率会被划分到同一个“桶”中,在召回时只需要在一个桶内,或相邻几个桶内的元素中进行搜索即可,大大降低了候选集相似度计算的数量。
Spark MLlib 同样提供了LSH 分桶模型,利用局部敏感哈希可以极大提高召回速度,实现快速召回。
2.2 排序层算法
DIN 模型[5]是阿里妈妈用在展示广告中的CTR 算法,在传统深度推荐模型的基础上引入了注意力机制,利用用户的历史行为与目标推荐物品之间的相关性计算注意力得分,从而提供更有针对性的推荐结果。
利用Spark 处理MovieLens 数据集,按照“物品特征”“用户特征”“场景特征”分类,可以提取出以下特征,见表2。

表2 可用的所有特征
为了使评分数据更好的符合DIN 的CTR 预估模型,我们将用户评分进行二分类处理,评分大于等于3.5 的标记为1,评分低于3.5 的标记为0。
DIN 模型将注意力机制用在了用户评分电影序列上,注意力模块中将用户评过分的电影与候选电影Embedding 以及通过element wise 差值向量合并起来作为输入,然后喂给全连接层,最后得出注意力权重。网络模型如图4 所示。
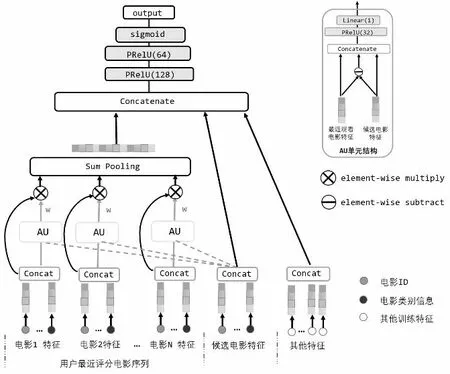
图4 DIN 模型结构
2.3模型线上部署
结合前面的召回层、排序层算法以及大数据处理工具,我们可以得到推荐模型的详细架构设计,如图5 所示。
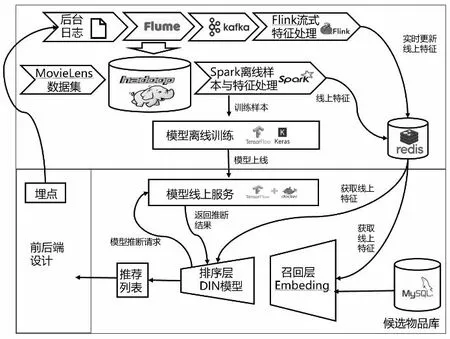
图5 推荐策略整体架构
利用前后端埋点,用户行为日志经过Flume 采集后一方面落盘到HDFS,另一方面由Kafka 传输到Flink 进行实时处理,前面提到用户Embeddig 是由该用户观看过的电影Embedding 加权平均得到的,Flink 在得到用户最新的评分电影后,就可以实时更新用户的Embeddig,从而改变用户的推荐结果。
Spark 从HDFS 上获取全量数据后进行离线处理,一方面得到训练样本数据供模型离线训练,另一方面将特征存储到Redis中,方便线上服务时获取。
在模型线上服务时,利用Embeddig 实现候选集的快速召回,排序时后端服务器利用拼接好的用户特征,通过请求TensorFlow Serving API 得到推断的结果,然后根据结果排序,生成最终的推荐列表。
3 实验与分析
3.1 评价标准
衡量推荐系统推荐效果的方法有离线评估和在线测试两种。离线评估常用来对算法模型本身进行评估,无需将模型部署到线上环境,是最常用最基本的评估方法;线上测试是在实际生产环境中将被测对象分组,分别部署新旧两套模型来比较模型的效果差异,通过计算视频观看时长,访问数等商业指标来衡量新模型的效果。
本实验中离线评估指标有准确率(Accuracy),P-R AUC 和ROC AUC[10]。准确率是指分类正确的样本占总样本个数的比例,其公式用混淆矩阵可以表示为:
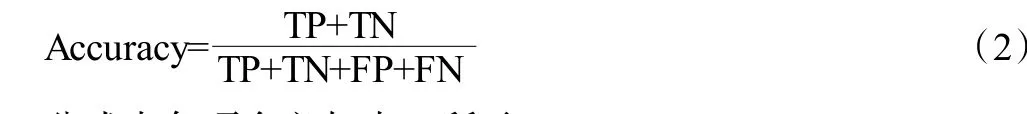
公式中各项含义如表3 所示。
P-R 是指精确率(Precision)和召回率(Recall)变化的曲线。P-R 曲线的横轴是召回率,纵轴是精确率。
精确率指的是分类正确的正样本个数占分类器判定为正样本个数的比例,公式如下:

ROC(the Receiver Operating Characteristic)曲线全称为“受试者工作特征曲线”。它的横坐标是FP,纵坐标是TP。
3.2 数据集
离线评估使用数据集为Movielens-1m 数据集,其中包括了由6000 名用户对4000 部电影的100 万条评分数据,每个用户至少评分20 部电影。用户和电影从1 号开始连续编号,数据随机排序。
3.3 实验平台
采用8 核16 线程联想电脑进行训练,内存16G,CPU 为AMD-4800H ,Python 版本为3.7,TensorFlow 版本为2.3.0,不使用GPU 加速。
3.4 模型参数设置
在构建训练集与数据集时,为了避免引入未来信息,训练集包含的用户评分时间不应该晚于测试集数据。利用Spark 划分训练集和测试集时,采用时间切割的方式,将用户评分按照时间戳排序,前80%作为训练集,后20%作为测试集。
使用TensorFlow Keras 构建神经网络,使用Adam 优化器,训练10 个epochs,每次batch 大小设置为64。
3.5 实验结果与分析
将本文所用的DIN 模型与NeuralCF[11],MLP 模型,Wide&Deep[3],DeepFM[12]等模型进行对比实验,使用Acc,PR AUC 和ROC AUC 测试[1]模型效果,实验结果如表4 所示。

表4 模型对比结果
由表4 可知,Netural CF 是传统协同过滤模型的神经网络化实现,表现效果最差;而DeepFM由于要进行特征间的深度交叉,在小数据集上表现不好,存在比较严重的过拟合问题。
DIN,MLP,Wide&Deep 模型的效果较好,其中DIN 模型的综合表现最好,这是因为DIN 相比MLP 引入了注意力权重,而MLP 只是将所有特征连接后直接送入全连接层。
3.6 线上测试
除了离线测试模型本身的效果之外,生产环境中还可以用线上AB 测试来评估整个推荐系统的效果。
在实际上线项目中,针对不同的用户,将其userId 计算哈希后对测试分组进行取余操作,将用户分布到不同的组中,从而采用不同的推荐模型对用户进行推荐。通过对比不同模型下网站访问量,播放时长,视频播放完成情况等测试上线模型的真实效果。
4 结论
本文利用Spark 等大数据工具搭建了一套完整的电影推荐系统,基于Embedding 和DIN 深度学习模型实现了电影的离线推荐与实时推荐功能,在离线环境下取得了较好的推荐效果。其中对开源技术框架的选型、推荐系统的每个功能模块做了详细介绍,清晰的展示了各模块之间的协作过程;并介绍了推荐系统推荐效果的评价指标和方法。对于如何设计一个工业化的完整的推荐系统来说具有很好的借鉴意义。
但也存在着诸多不足,本文中用到的推荐算法只是对以往算法在电影推荐领域的一个整合和应用,下一步考虑针对电影数据集对现有算法进行改进。
猜你喜欢
电脑知识与技术(2022年15期)2022-07-02
汽车实用技术(2022年10期)2022-06-09
昆明医科大学学报(2022年3期)2022-04-19
昆明医科大学学报(2022年2期)2022-03-29
名家名作(2021年4期)2021-05-12
中国药学药品知识仓库(2021年18期)2021-02-28
电脑爱好者(2020年23期)2020-12-30
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
电脑爱好者(2015年5期)2015-09-10
