
基于特征复用网络的医学图像分割
2021-12-02 01:22吴天宇
现代计算机 2021年28期
吴天宇
(唐山职业技术学院后勤及国有资产管理处,唐山 063000)
0 引言
随着数字成像技术的发展及图像分割技术[1-2]的持续改进,医学影像在临床诊断中的应用越来越广泛,已成为医生诊治的首要根据。通过计算机技术对医学图像中感兴趣区域(ROI)进行定位和分割,识别出ROI区域的像素点,获得ROI的特征参数,以便为后续的分析病情、评估治疗提供可靠的参考信息,辅助医生进行诊断治疗。医学图像分割是医学图像处理的关键步骤,对于下一步的诊断治疗至关重要[3]。
经过多年的研究,许多学者将大量的图像分割方法应用于医学图像分割并取得了较好的效果[4-6]。张滨凯等[7]提出了一种医学图像聚类分割算法,利用字典作为聚类分割的聚类中心,通过稀疏表示确定聚类归属,实现医学图像分割;房巾莉等[8]提出了一种水平集模型,该模型将整体信息与局部信息结合来分割医学图像,可以得到较完整的边界曲线。
近年来,深度学习算法在图像处理中展现出了强大的能力,对于医学图像的分割效果要优于传统的分割算法。Ronneberger等[9]提出U-net网络架构,已应用在对神经元、细胞瘤和HeLa细胞的医学图像分割任务中。Rathiba等[10]将几个网络结构结合,组成深度残差全卷积网络,可以自动分割皮肤图像上的黑色素瘤;杨兵等[11]为了解决特征信息易丢失的问题,提出了一种用于脑图像和眼底血管分割的深度特征聚合网络,有效的提高了分割精度;闫超等[12]总结了利用深度学习进行医学图像分割的发展过程,并对当前面临问题的解决提出了展望。
本文对U型网络进行了优化,结合DFAnet[13]提出的特征复用结构提出了一种特征复用结构的编解码器网络RU-net,并采用可分离卷积搭建Resnet34为编码器主干,利用旋转、放大、平移、仿射变换等多种图像增强方法扩充图像数据集;最后把原图进行不同角度的翻转变换后进行预测,对预测结果进行反变换并求平均,可有效提高预测结果的准确率。在LUNA竞赛数据集和EM竞赛数据集上与U-net网络对比可知,本文方法缩减了参数和计算量,同时分割精度得到极大的提升。
1 模型搭建
1.1 优化U-net网络
U-net是U型对称结构,原图经过左侧的五次卷积和池化进行编码,然后通过右侧的五次上采样和卷积进行解码,同时采用跳跃连接将左侧的包含更多细节信息的每个卷积层和右侧包含语义信息的上采样合并通道进行卷积从而可以使得最终所得到的特征图中既包含了高级的的语义信息,也包含很多的低级的细节信息,实现了不同尺度下特征的融合,提高模型的结果精确度,因为模型为完全对称结构,可以快速调整卷积核数量以应对多种多样的数据集。
但是U-net网络每个编码层通道数多,各个特征图之间联系不密切,解码的过程中也是采用简单拼接的方式融合,导致了参数冗余、分割效率低、分割不准确的问题。文献[12]提出了一种阶段性特征复用结构如图1所示。
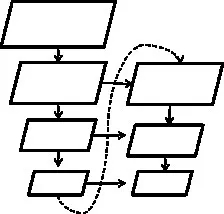
图1 阶段性特征复用结构
在编码器阶段将深层的特征图插值放大再进行下采样,与此同时与前一个下采样主干进行特征融合,采用此方法可以使得网络在编码的过程中不断的融合不同阶段的特征信息,因此可以适当缩减通道数,以节约计算量,深层特征图插值放大再次进行下采样加深了网络的深度,提取到的语义信息更加丰富。为了发挥U型网络在二分类方面的优势本文编码器部分借鉴了阶段性特征复用结构,解码器依然采用逐渐2倍上采样的方式恢复特征图,在恢复的过程中不断的融合左侧编码器部分的特征图,此时融合的特征图为多个阶段编码器子网络融合并采用卷积层提取信息后的结果,将特征复用结构改进U型网络,加深了网络各个阶段的联系,特征表达能力更强,RUnet结构如图2所示,图中特征图大小均为输出大小,“C”为合并通道并1×1卷积为下一个卷积层输入特征图通道数。
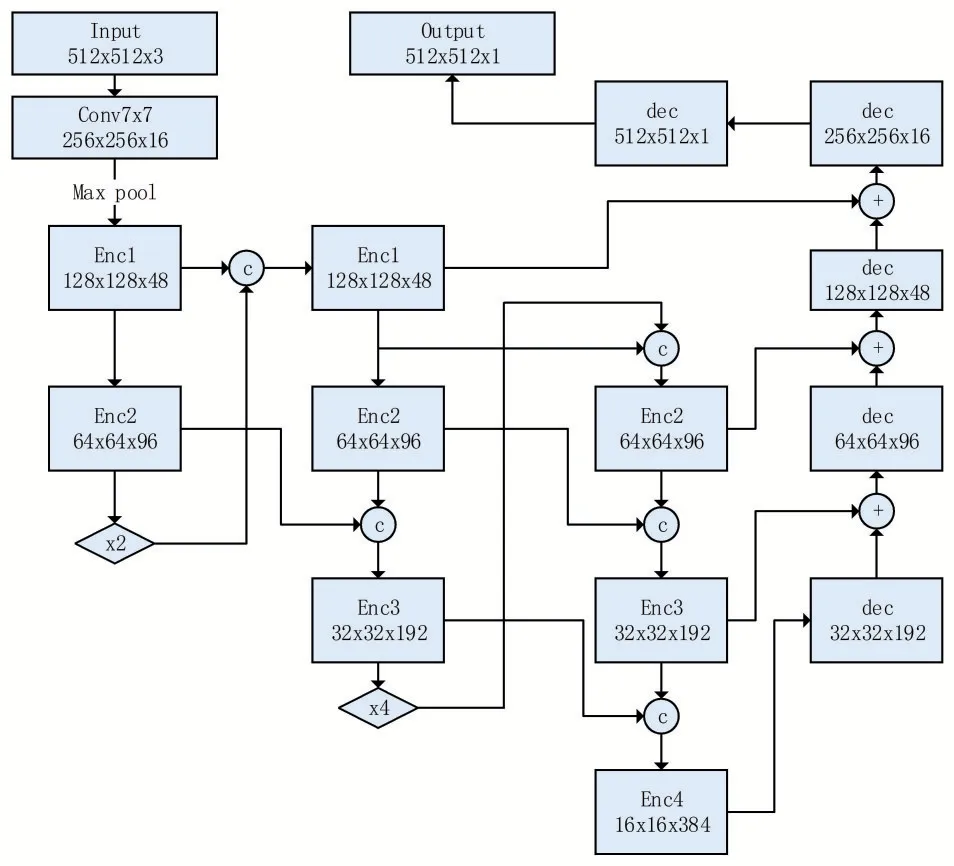
图2 特征复用Ru-net
1.2 深度可分离卷积模块
利用普通卷积对特征的提取可以对特征图建立局部相关性进而共享参数,从而可以比全连接网络利用的参数更少[14],Xception[15]网络中提出了一种深度可分离卷积,将空间相关性与通道相关性解耦,可以做到比普通卷积更少的参数完成对特征的两种相关性的学习,如图3所示为普通卷积核和深度可分离卷积示意图。
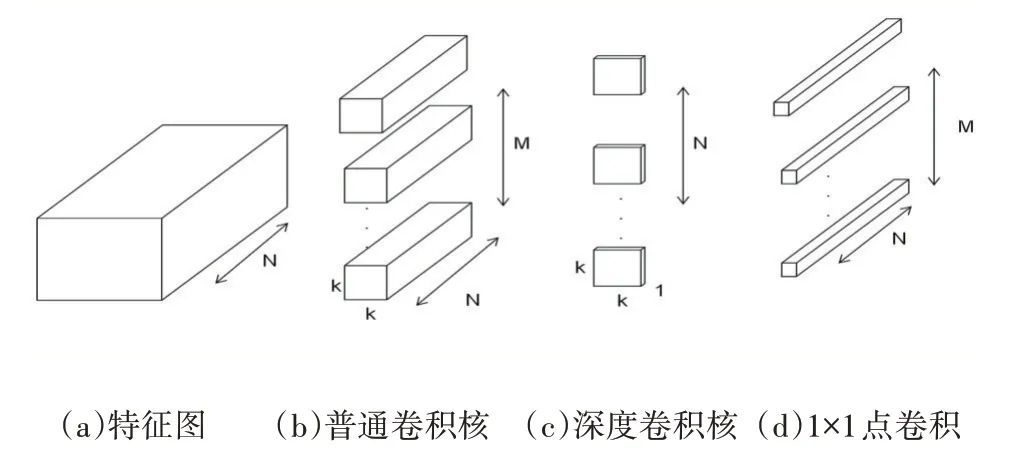
图3 深度可分离卷积
其中N表示输入通道数,M表示输出通道数,k表示卷积核大小,深度可分离卷积先采用N个k×k×1卷积核分别对每个通道特征图进行采样,产生N个特征图,再采用M个1×1×N卷积核对各个通道建立相关性[16]。这样普通卷积核需要N×k×k×M个参数,深度可分离卷积需要N×k×k+M×N,与普通卷积核的参数对比为(k2+M)/(M×k2),输出通道M越大,参数缩减越多。
2 研究方法
2.1 实验设置
本文采用的数据集是EM挑战赛的公开数据集和(lung nodule analysis,LUNA)挑战赛数据集,EM数据集分割任务是在电子显微镜记录中分割神经元结构,训练集包含30张512×512像素的灰度图像,该数据集开始于ISBI 2012,至今一直为医学图像分割的经典数据集[17],但是该数据集训练集并不包含标签,因此本次测试使用训练集Dice系数;LUNA挑战赛数据集包含264张图片,本文将该数据集按比例8∶2分为了训练集和测试集。
2.2 数据增强方法
在扩充的数据集时不能损坏原图的语义信息,本文采用的方法是对多种数据增强方法的组合,其中包含的方法有:随机旋转90°~270°、随机对图像进行对比度和亮度调整、随机放大图片并随机选取区域裁剪至原图尺寸、随机旋转0°~90°、在水平方向和垂直方向随机平移一定距离、仿射变换,具体组合方法如图4所示。
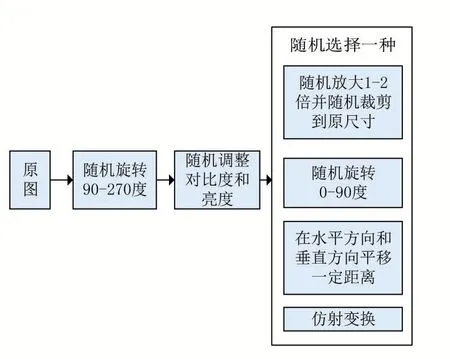
图4 数据增强方法组合
采用以上数据增强方法可以使得原数据集扩大许多倍,足够使模型提取到更多的语义信息。如图5和图6分别为原数据集中一张图像采用本文数据增强方法后的部分图像和其对应的标签。
图5 数据增强后的图片

图6 数据增强后对应标签
2.3 评价指标和损失函数
本文采用的评价指标为在医学图像分割任务中一个常用的指标Dice系数[18],Dice系数是两个样例之间重叠的指标,这个值的值域为0至1,其中Dice系数为1时代表完全的重合,Dice系数的计算方法如下:
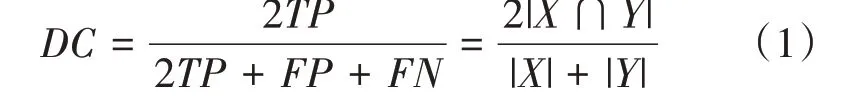
其中X,Y分别表示预测结果和真实的标签,T P是真正例,F N是假正例。
采用的损失函数是基于Dice系数的函数,D C可被定义为Dice损失函数(DL):

其中p∈{0,1}n,0≤̂≤1。p与̂分别为真实标签和预测分类,<·,·>表示点积。
2.4 图像预测方法
在深度卷积模型中由于卷积核每次都从左往右进行移动,因此原图的位置不同,预测结果也会有一些差别。为了提高预测结果的准确率,防止单次实验结果误差过大,或者在某一类图片上不鲁棒,本文分别对原图进行垂直翻转、水平翻转、逆时针旋转90度、逆时针旋转180度操作,并将变换后的四张图输入神经网络进行预测;然后对四张预测图进行对应的反向变换操作;最后将预测图求平均值获得最终的结果图。
3 实验对比分析
3.1 编码器网络选择
为了寻找合适的编码器网络,本文选择了Resnet-18,进行对比实验,如表1为测试结果,可以看到随着网络深度的增加分割精度明显增加,深层的网络可以提取到更多的语义信息,对模型的推理能力有很大的提升,为此选择了Resnet34作为编码器网络。

表1 编码器对比实验
3.2 模型对比实验
如表2所示为U-net、Ce-net和RU-net的分割效果图,可以看出RU-net相比于其余网络参数量和运算量极大的减少,在两个数据集上测试分割精度均高于U-net,略低于CE-net,但是也具有可比的分割性能。
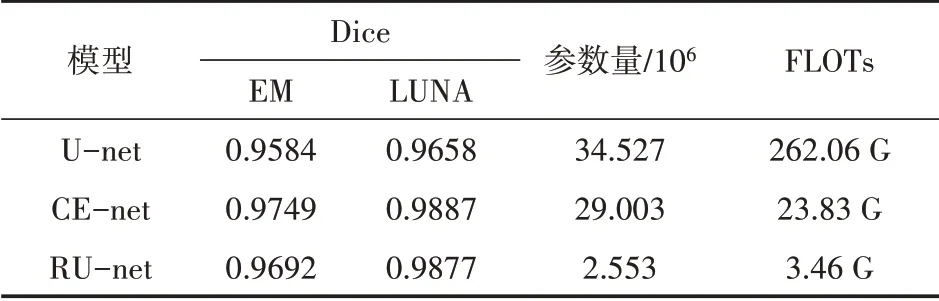
表2 模型对比实验
3.3 模型分割效果对比
如图7所示为在EM数据集上的表现结果,可以看到相比于U-net,RU-net可以将一些难分的细胞边界分割出,分割图中细胞内错分的点较少,U-net网络中第一个卷积层参与了跳跃连接与解码器融合,虽然会补充到细节信息,但是导致了计算量的增加,同时最后一个解码器层连接的卷积层很少,导致了融合后两个特征图建立的联系不强,而RU-net只将4倍下采样后的特征图参与跳跃连接,多次上采样后学习到的关联性更强,同时计算量极大减少。

图7 部分细胞边界分割对比实验
如图8所示为RU-net和CE-net在LUNA数据集下的分割效果,可以看到CE-net预测图像中存在一些分离的像素点,而RU-net很少出现此类情况,CE-net在运行过程中只是在解码器部分融合同尺度的编码特征图,并且是简单相加的方式融合,在上采样过程中造成了信息的损失,而RU-net则是融合多个阶段的特征图进行运算,空间信息和细节信息更加的丰富,在一些图片上RU-net分割表现强于CE-net。
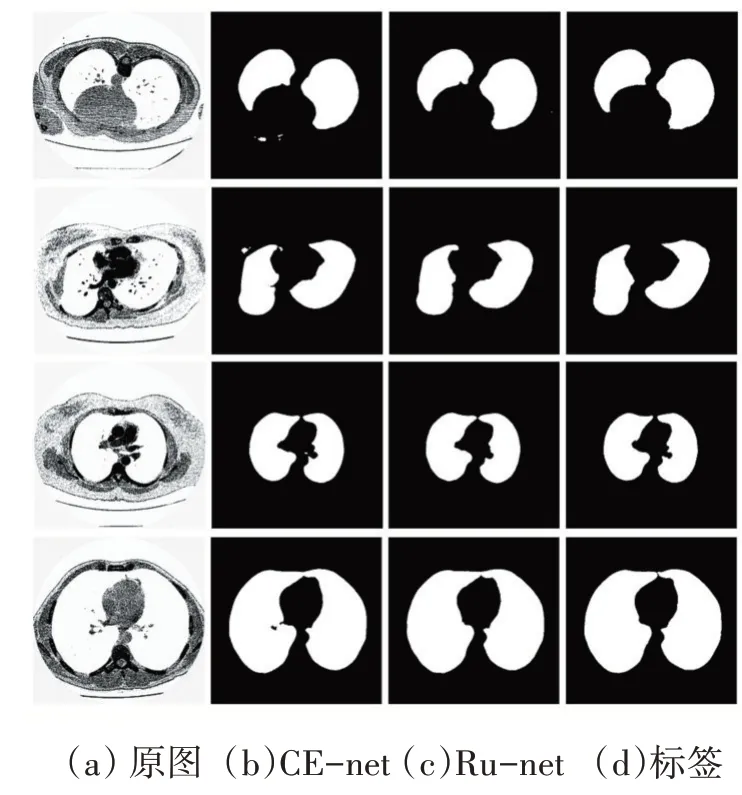
图8 部分肺部分割对比实验
4 结语
本文采用可分离卷积的Resnet34作为主干搭建阶段性特征复用结构,并以此为编码器优化U型网络,由于特征复用结构在每个特征提取阶段均融合了不同尺度的信息,因此在缩减通道数的情况下依然有良好的表现,与其他几种U型网络比较,参数量极大的减少,经过实验验证,其分割精度也有保证,同时由于网络更加的深,提取的语义信息更加丰富。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
家庭医学(2021年12期)2021-08-23
安徽医学(2021年1期)2021-03-22
安徽医学(2021年1期)2021-03-22
祝您健康(2020年4期)2020-05-20
上海师范大学学报·自然科学版(2019年5期)2019-12-13
中国新通信(2017年9期)2017-05-27
科技与创新(2017年5期)2017-03-28
