
基于动态规划的服务功能链映射算法
2021-12-02 01:21袁绍露张向利
现代计算机 2021年28期
袁绍露,张向利
(桂林电子科技大学广西无线宽带通信与信号处理重点实验室,桂林 541004)
0 引言
随着数据流量爆发式增长,智能工厂、车联网等新型技术日益成熟需要多样的网络服务,以及5G网络需利用网络切片技术为用户提供定制化网络服务[1],传统的TCP/IP架构网络面临巨大挑战。传统网络采用的是分布式网络架构,通过简单地增加网络设备和线路修补式的解决网络拥堵问题,不仅会增加网络流量传输动态调控的难度,而且不能对整体网络性能有较大的提高[2]。因此,各大运营商利用网络功能虚拟化(NFV)技术构建全新的网络体系结构解决上述问题。
VNF核心思想是将传统网络中专用网络设备上网络功能的软件实现与昂贵的专用硬件资源进行解耦,在通用服务器上共享硬件设施并以软件方式实现不同的网络功能。VNF可以灵活快速地在最优位置上部署所需的网络功能[3],根据用户服务需求将所需的VNF构建成一个有序的服务功能链(SFC),然后将SFC映射到切片网络中为用户实现定制化网络服务,实现差异化服务。将如何在基础设施中为网络服务分配所需要资源称为VNF资源分配(VNF-RA)问题[4]。NFV-RA问题第二阶段称为VNF转发图嵌入,也称之为服务功能链的映射。如何对服务功能链的映射是对不同服务请求进行差异化服务的前提。关于服务功能链映射问题的研究。文献[5]将用户服务请求构建成SFC后,对SFC映射问题转成类似于VNE问题,其两者的差别在于约束条件和优化目标不同。文献[6]是在虚拟机上尚未部署网络功能情况下对SFC进行映射,将问题分成网络功能部署和SFC调度两个子问题,以网络切片中服务功能链的最小服务时延为优化目标,并通过粒子群算法对目标进行优化。文献[7]提出基于马尔科夫模型的SAMA启发式算法,通过计算虚拟机优先接收优先级高的SFC进行映射,降低搜索空间,从而提高映射效率。
SFC映射被证明是NP难问题[8],当前研究方法采用较多的是启发式算法。当SFC数目较多时,利用启发式算法对多目标求解具有快速求解的优势,但实际网络环境中存在需要映射SFC数目较少情况,如果继续利用基于启发式的算法,存在优化时间较长的问题。因此,本文提出一种SFC映射算法(DI-MCMF),即将该问题分成VNF映射和虚拟链路映射物理链路两个子问题,首先分别找出VNF匹配的虚拟机,然后通过动态规划有向无环低时延算法获得VNF映射方案;再采用最小费用最大流算法获得虚拟链路映射方案。
1 问题描述
一个核心切片网络可以根据不同用户需求为其提供差异化网络服务,这些网路服务可以用服务功能链(SFC)进行表示。服务功能链上VNF的服务是由切片网络中服务器上的虚拟机所部署的网络功能来提供。由于虚拟机的资源是有限的,因此在实际网络环境中不同服务功能链上相同的虚拟网络功能需要共享某个虚拟机上的网络功能,如图1所示。
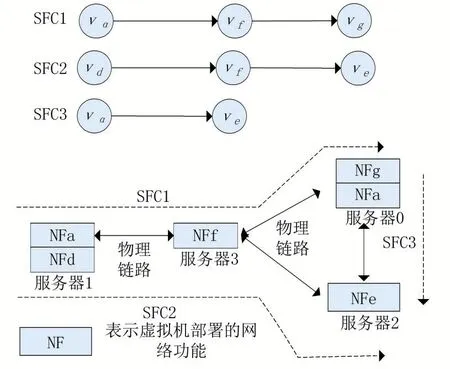
图1 SFC与网络切片
在图1中,SFC1中的虚拟网络功能vf和SFC2中的虚拟网络功能vf共享服务器3上部署网络功能为NFf的虚拟机。在采用VNF技术的网络环境下,通过在服务器的虚拟机上部署网络功能作为虚拟网络功能设备来提供该功能的网络服务。为了进一步提高资源的利用率,不仅让某个虚拟网络功能设备可以被不同的服务功能链中同类型的VNF共享使用,而且可以在服务器上配置多个虚拟机以提供更多的网络服务。如图1中服务器1上两个虚拟机分别部署了网络功能NFa和网络功能NFd。但是由于单个虚拟网络功能设备资源的限制,所以单个虚拟网路功能设备服务用户的数目也是有限的,就会造成不同服务功能链上相同的VNF被调度到不同服务器的虚拟网络设备上。如图1中,SFC1与SFC3具有相同的虚拟网络功能va,但被分别调度到服务器1和服务器0上进行信息的处理。单个服务功能链中各虚拟网络功能会调度到不同服务器上具备该类型的虚拟机来处理,并且各个虚拟网络功能之间的虚拟链路可以由多条物理链进行数据流的传输。
本文研究的是服务功能链映射问题,是指在切片网络中为虚拟机分配了资源并且虚拟机上已经部署了相应的网路功能的情况下,将服务功能链上虚拟网络功能调度到各自匹配的虚拟机上处理数据流,还需要解决服务功能链上虚拟链路分配哪些物理链路进行信息的传递。如图2所示。

图2 服务功能链调度
在图2中,切片网络中各服务器上的虚拟机已经部署相应的网络功能。在对SFC1功能链进行映射时会存在多种映射方案。方案Ⅰ的部署方式为先从服务器2上的NFa到服务器1上的NFf再到服务器4上的NFg。方案Ⅱ的部署方式为从服务器3上的Nfa到服务器1上的NFf再到服务器5上的NFg。方案Ⅰ和方案Ⅱ的部署方式有相同的服务器1,也有不同的服务器2、服务器3等。由于已经有服务功能链在物理网络上运行,就会造成部署相同网络功能的不同服务器剩余的计算力不相同,例如服务器2和服务器3上有相同的NFa,但是它们的剩余计算力不相同,就会造成虚拟网络功能a处理时延不相同,并且不同服务器之间的传输时延也会不同,所以方案Ⅰ和方案Ⅱ的部署方式就会造成服务功能链的服务时延不相同。当有新的服务功能链需要映射物理网络时,如何选择低服务时延的映射路径非常重要。因此,本文提出了DI-MCMF算法来解决上述问题。
2 数学模型
数学模型使用的符号及其物理意义如表1所示。

表1 数学模型中的符号及其物理意义
2.1 网络模型及SFC模型
在本文中使用一个加权无向图G=(N,E)对物理传输网络进行表示。将物理服务器与物理交换节点视为一个节点,每个服务器上可部署V S个虚拟机,每个虚拟机部署一个网络功能。根据用户的服务需求构建成相应的SFC,服务功能链上不同的虚拟网络功能处理单个数据流时延不同,相同的虚拟网络功能处理单个数据流时延相同。
2.2 约束条件
2.2.1 服务器上部署虚拟网络功能约束条件
在本文中一个服务器可以虚拟化出多个网络功能,每个服务器上有多个虚拟机,每个虚拟机上部署一个虚拟网络功能。使用表示网络功能F d是否部署到第n个服务器的第m个虚拟机上,则:

2.2.2 SFC中VNF离线匹配的约束条件
通过映射算法将集合C中SFC上的虚拟网络功能映射虚拟机上,当虚拟机上部署的网络功能与的功能相同,或者上还没有部署网络功能。使用表示第k个服务功能链的第h虚拟网络功能映射到第n个服务器上的第m个虚拟机,并且SFC上的网络功能只能映射到一个虚拟机上,则:

网络功能对业务处理能力是有限的,一个虚拟机上的网络功能对映射到该虚拟机的SFC数据流之和不能超过网络功能业务能力,则:

2.2.3 SFC中虚拟链路映射的约束条件
SFC上两个虚拟网络功能的虚拟链路的带宽为,一个虚拟链路可映射到物理网络的多条物理链路e i,j,用来表示是否占用物理链路e i,j的带宽,用表示在物理链路e i,j上占用带宽的大小。物理链路e i,j剩余的可利用的带宽用b i,j表示,则:

2.3 核心网络切片的服务时延
服务功能链的服务时延由两部分构成,分别为服务功能链各虚拟网络功能在所映射虚拟机上处理时延和服务功能链在物理网络上传输时延τC K。处理时延由网络功能所需的计算量与该功能所映射物理网络上服务器的计算速度来表示,每条服务功能链上所有虚拟网络功能处理时延用进行表示,则:
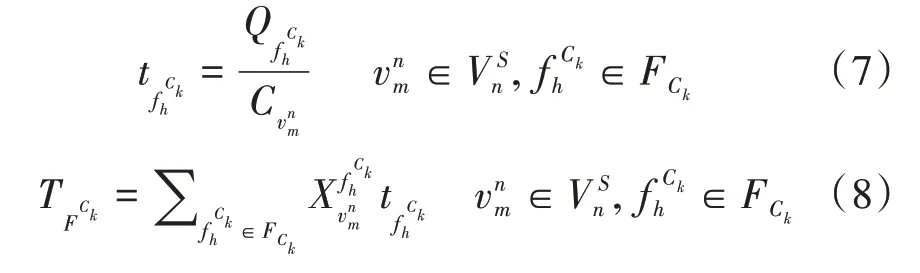
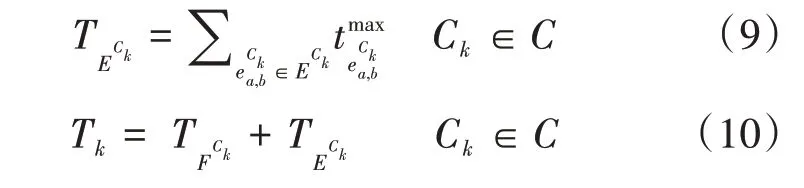
使用Ttotal表示服务功能链集合C服务时延之和,则有:
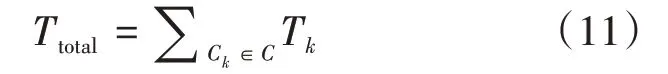
3 服务功能链映射算法
本文提出的服务功能链映射DI-MCMF算法分成SFC上虚拟网络功能映射虚拟机和虚拟链路映射物理链路两个部分。
3.1 虚拟链路映射算法
当一个SFC上的两个VNF映射到物理网络上后,需要将这两个VNF之间的虚拟链路映射到物理网络上。由于物理网络上链路有多条虚拟链路映射,就有可能造成该物理链路不能满足虚拟链路的带宽需求。如果将虚拟链路只映射到一条物理链路上,当该物理链路发生故障的时候,就会直接影响到用户的网络服务。因此,需要将分配到多条物理路径上。不同物理链路的需要费用不一样,为满足SFC上虚拟链路带宽要求和降低使用成本,采用最小费用最大流算法的思路[9]。由于本文物理链路的参数设定义为带宽和时延,因此需要将问题转化为最小时延最大带宽问题。在对虚拟链路进行映射的时候,先找出最小时延时路径,即在物理网络上寻找两个VNF映射节点间以时延为权值的最短路径,然后沿着最小时延路增加带宽,直到满足SFC虚拟链路的带宽需求,虚拟链路映射算法步骤如下:
(1)在物理网络拓扑上分别增加一个虚拟发送节点S和一个虚拟接收节点R。生成邻接矩阵M。虚拟发送节点S到所映射的服务器h∈S N为单向流出链路,该单向链路的带宽为第C k个服务功能链的带宽需求,并且将该单向链路的时延设置为0。虚拟接收节点R到所映射的服务器l∈S N为单向流入链路,该单向链路的带宽同样为,链路的时延也为0。物理网络链路都只设定带宽和时延这两个约束条件,服务功能链的虚拟链路映射问题就转变成虚拟发送节点S到虚拟接收节点R之间的最小时延最大带宽问题,如图3所示。

图3 (带宽、时延)拓扑图
(2)新建路径集合P,并赋初始值为空;新建S节点到R节点带宽f,并赋初始值为0。
(3)用Dijkstra求解节点S到节点R之间的最小时延有向路径a,在路径上的可用带宽为b。
7.学习成功后点击“确定”进行第二把的匹配(哈佛H6钥匙匹配时至少需要匹配2把才能着车),如图8所示。
步骤3-1:增加带宽f+=b,在M中把路径a上所有链路的可用带宽减去b,同时反向链路可用带宽值上加b。若M中某条链路的带宽为0,则在M中取消该条链路。
步骤3-2:将路径a和该路径的带宽分别赋给路径集合P和带宽f。
重复执行步骤3直到f≥。若f≥,则能够映射到物理网络中,P值作为映射方案,的传输时延为t。否则映射失败。
3.2 SFC上VNF的映射
服务功能链中VNF映射到最优位置上的虚拟机问题类似于动态规划有向无环最短路径问题,如图4所示。
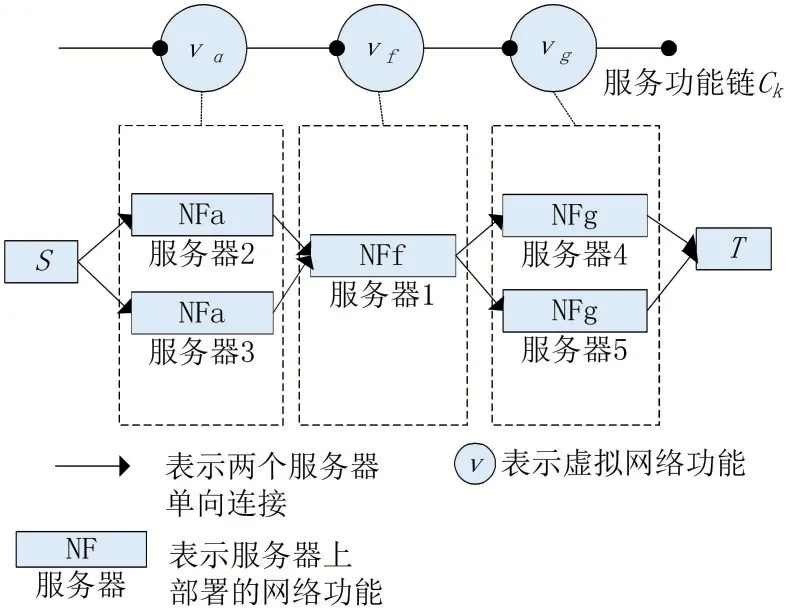
图4 VNF所匹配的虚拟机
当新服务功能链需要添加到物理网络中时,首先按照服务功能链上虚拟网络功能的依赖顺序寻找各自匹配服务器的集合其中,S i∈S表示服务功能链上第i个虚拟网络功能所匹配服务器的集合。如图4上待映射服务功能链C k上虚拟网络功能a匹配的服务器集合为服务器2和服务器3。添加源节点S,节点S单向连接服务功能链C k上第一个虚拟网络功能匹配的服务器节点。添加终节点T,服务功能链C k上最后一个虚拟网络功能单向连接节点T。
由于虚拟网络功能之间是单向传递的关系,所以服务功能链上各虚拟网路功能所匹配的服务器集合之间就能构建一个以服务器为节点的有向图G S=(N S,E S),N S表示以服务器节点和源终节点的集合,E S表示服务器之间链路的集合。集合Si里的服务器节点之间没有链路连接。集合Si上的服务器均与集合Si+1上的服务器都存在单向连接关系。源节点S到S0的各服务器节点的边权值为0。服务器节点与服务器节点的边权值表示在满足服务功能链上v i与v i+1带宽需求前提下的传输时延加上v i在服务器处理时延,处理时延利用公式(7)计算。到终节点T边权值为服务功能链C k上最后一个虚拟网络功能在服务器上的处理时延。
服务功能链C K映射优化目标是服务时延,因此将问题转变成动态规划有向无循环低时延问题。首先对图GG进行分段,每一层的各个节点互不连通,后驱节点均在同一层。将节点S列为第一层,终节点T为最后一层,中间各层为服务功能链上虚拟网络功能所匹配的服务器集合S i(i表示SFC的虚拟网络能的序号)。用Tde_min()表示源点S到节点的最优服务时延,则有如下状态转移方程:
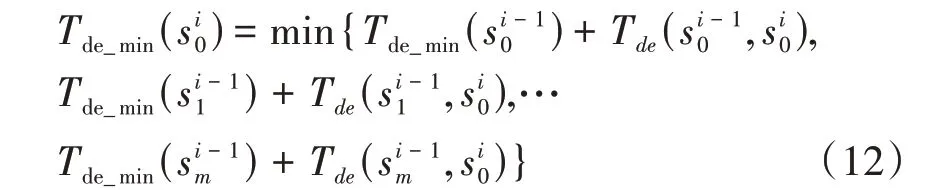
算法3:DI-MCMF算法
输入:待映射服务功能链C k,已有SFC的物理网络G。
输出:C k映射方案。
1.nfv_num←SFC虚拟网络功能个数;
vm_num←切片网络中虚拟机个数。
2.for i←0 to nfv_num do
3. for j←0 to vm_num do
4. 将服务功能链C k上VNF匹配虚拟机编号记录到Store_num中
5. //Store_num表示二维数组,将C k上VNF匹配的虚拟机进行编号
6. end for
7.end for
8.size←store_ser_num.size()-2
9.for i←size 0 to 0 do
10.nextPos//一维数组,记录距离目的节点T最小服务时延的邻接的node
11.nextPos[T]=NO-NEXT;
//NO-NEXT表示没有下一个节点
12.dist[T]=0;//dist表示一维数组,记录该pos到目的节点T的服务时延
13. for j←0 to store_ser_num[i].size()do
14. nowpos←store_ser_num[i][i];
15. dist[nowpos]=INT_MAX;
16. for m←0 to Store_num[i+1].size()
17. last SegNodePos←Store_num[i+1][m];
18. 计算dist[nowpos]最小时延,记录next Pos[nowpos]最小时延节点//该过程需利用虚拟链路映射算法计算传输时延
19. end for
20. end for
21.end for
22.nextPos为C k上VNF映射的虚拟机,虚拟链路利用虚拟链路映射算法映射,输出映射方案
4 仿真实验
为了验证算法的性能,本文的仿真实验平台是Visual Studio 2017,硬件配置为Intel Core i7-8550 CPU、16GB RAM的计算机。实验采用的经典EURO网络扑图[10]。总计为28个节点,其中部分带有灰色填充的节点表示带有物理计算服务器的节点,总数为6个,且每台物理服务器上拥有3个虚拟机,剩余的为普通的路由节点。物理网络中相连的节点之间均为全双工链路,链路带宽为1 Gbps。每条服务功能链随机生成U(5,8)个虚拟网络功能,虚拟链路的带宽由均匀分布U(3,7)Mbps生成。
为了验证本章提出的DI-MCMF算法有效性,是在切片网络中已有服务功能链映射到物理网络中,通过对新的服务功能链映射后,切片网络中服务功能链的平均服务时延和映射新的服务功能链算法运行时间进行评估,并与PSO-MCMF和GA-MCMF算法进行对比。新映射服务功能链后切片网路中SFC平均服务时延如图5所示。
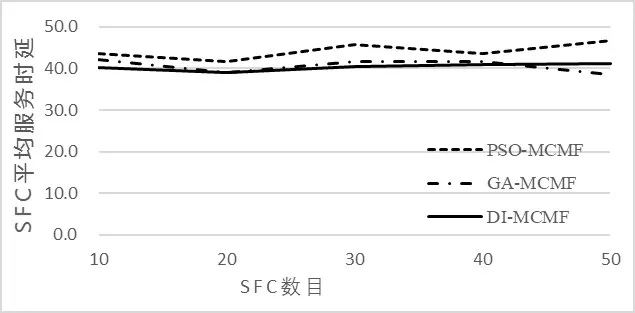
图5 映射不同SFC数目后平均服务时延
算法DI-MCMF是当物理网络上虚拟机已部署网络功能后,添加新服务功能链。当需要添加新服务功能链到物理网络上时不会影响到原本已经成功映射的服务功能链。通过PSO-MCMF和GA-MCMF算法在物理网络对新映射服务功能链时,需要将原先的服务功能链和新增的服务功能链组合成一个服务功能链集合后,再利用各自算法进行映射。PSO-MCMF和GA-MCMF算法都会影响原本服务功能链的正常服务。图5显示的是三种算法在新增服务功能链后,物理网络上服务功能链的平均服务时延。从图5可以看出,通过DI-MCMF算法与PSO-MCMF算法映射的服务功能链的平均服务时延基本处于重叠,低于PSOMCMF算法的平均服务时延。所以通过DI-MCMF算法能够为新增的服务功能链匹配到较好的映射方案。
添加不同数目的SFC三种算法运行的时间,如图6所示。随着SFC数目的增加,DI-MCMF算法运行时间均低于PSO-MCMF和GA-MCMF算法运行时间,DI-MCMF算法对SFC映射效率更高。
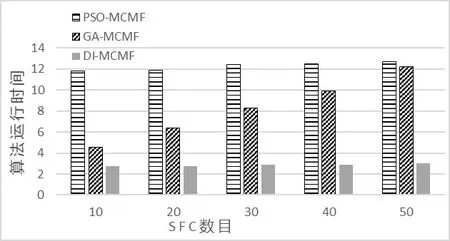
图6 映射SFC不同算法运行时间
5 结语
本文研究了核心网络切片中服务功能链映射问题,对问题进行了数学建模,提出了利用动态规划寻找最短服务时延算法对服务功能链的虚拟网络功能映射最优的虚拟机,利用最小费用最大流算法获得虚拟链路映射方案,从而对服务功能链进行映射。通过实验对比分析,该方法映射效率得到提高,同时不会影响到切片网络中其他SFC的正常运行。
猜你喜欢
火力与指挥控制(2022年8期)2022-09-16
计算机系统应用(2022年8期)2022-08-25
电脑知识与技术(2021年22期)2021-09-14
电脑知识与技术(2021年22期)2021-09-14
现代信息科技(2021年21期)2021-05-07
花火B(2019年3期)2019-04-27
中国计算机报(2018年12期)2018-10-08
科技创新导报(2016年27期)2017-03-14
网络与信息(2009年4期)2009-04-26
中国计算机报(2009年21期)2009-04-22
