
基于ADASYN-AdaBoost-CNN的信用风险评估模型
2021-12-02 01:21徐文倩
现代计算机 2021年28期
徐文倩
(安徽工业大学管理科学与工程学院,马鞍山 243032)
0 引言
随着现代金融系统的发展,借贷平台在现代金融系统中具有重要地位,尤其在个人借贷方面得到了广泛的应用。社会整体消费观念的转变及消费水平的发展,极大地刺激着人们的消费欲望。个人借贷的出现,不仅满足了人们的需求,并保证了社会经济的长期稳定增长。然而,由于借贷平台缺乏有效的风险控制,信用风险不可避免。良好的借贷关系有利于达成借贷平台与贷款者的共赢,但随着个人贷款交易数量的迅速增长,一些无节制透支、超时还款以及借款无法追回等违约现象不仅影响了借贷平台的正常运营以及投资人的利益,还对个人信用产生了极大的影响。为了有效的避免或降低借贷风险,保证借贷关系的持续健康发展,对个人信用风险进行有效评估具有重要意义。
信用风险评估是根据贷款者相关信息对贷款者进行评估的一种方法,通过将贷款者分为好的和差的两种信用类型,然后决定是否提供贷款[1]。信用评分法在传统金融机构中已被广泛使用,根据目前的研究,信用评分方法主要基于统计方法和机器学习方法[1-3]。
由于大部分信贷数据集属于不平衡数据集,数据集中具备良好信贷关系的贷款者数量远远大于存在违约现象的贷款者数量。因此,信用风险评估问题中的不平衡现象对评估模型的有效性提出了重大挑战,对不平衡数据分类的研究也将有助于信用风险评估问题的研究。不平衡数据分类主要分为数据层面方法和算法层面方法。数据层面方法使用重采样技术预先平衡目标训练数据集进而使用分类方法进行分类,主要有过采样方法和欠采样方法。过采样方法通过合成少数类样本,增加少数类数量来平衡数据集。SMOTE(synthetic minority,SMOTE)方法[4]作为经典的过采样方法,通过在每个少数类样本与其K个近邻样本之间的连线上产生合成新样本来增加少数类样本数量,从而使数据集趋于平衡。欠采样方法通过减少多数类样本来平衡数据集。研究表明,在信用风险评估问题中,采用重采样方法平衡数据集能够有效提高对信用风险不平衡数据集的分类性能。Song等[5]使用基于多准则决策的方法评估了用于信用风险预测的几个不平衡分类器,证明了基于SMOTEBoost的模型对于不平衡数据分类比其他方法更有效。Shen等[6]提出一种合成少数过采样技术和分类器优化技术的集成模型,使用SMOTE技术平衡目标训练数据集,构造基于Ada-Boost和BP神经网络算法的集成模型对不平衡信用数据进行分类。数据层面的方法主要使用代价敏感学习和集成学习方法来提高分类性能。针对信用风险不平衡数据集,代价敏感方法为具有良好借贷关系的贷款者和存在违约现象的贷款者指定不同的误分类代价,对存在违约现象的贷款者提高误分类代价,从而提高对存在违约现象的少数贷款者的识别率,降低信用风险。马鹏举等[7]构造基于代价敏感学习方法的决策树,提高了对贷款者违约情况的评估能力。Xia等[8]提出了一种代价敏感的集成树贷款评估模型,结合代价敏感学习和XGBoost方法增强对潜在违约贷款者的辨别能力,证明了模型对不平衡问题的有效性。集成方法在信用风险评估中的应用已经取得了显著进步,陈舒期等[9]通过改进选择性支持向量机集成算法,提供了一种有效的个人信用评估方法。李淑锦等[10]将Boosting和Bagging两种集成方法的优势结合,提出了基于LightGBM和Bagging的评估模型,进一步提高了对信用风险评估问题的分类能力。Ye[11]利用机器学习算法建立了logistics回归模型、决策树模型、支持向量机模型以及基于三种算法的集成模型评估和预测个人信用风险,通过比较不同模型的预测效果,表明集成学习模型分类效果更好。
与统计方法和机器学习方法相比,深度学习模型尚未广泛应用于信用风险评估。杨德杰等[12]针对银行客户数据的数据特征之间的相关性,引入截断的Karhuncn-Loève对堆栈降噪自编码神经网络模型改进,提高了信用风险评估准确率。Dastile等[13]采用系统的文献调查方法,分析了信用风险评估中的常用统计方法和机器学习技术,并表明了深度学习算法对信用风险评估的适用性。
通过上述研究发现,基于神经网络和集成方法的混合与集成模型已成为信用风险评估问题研究的新趋势,这些模型为借贷平台提供了更复杂、更准确的工具。因此,本文提出一种ADASYN-AdaBoost-CNN集成学习模型用于不平衡信用风险评估。通过ADASYN(adaptive synthetic sampling,ADASYN)过采样方法平衡目标训练数据集,利用卷积神经网络(convolutional neural network,CNN)分类预测性能的优越性,将卷积神经网络作为基分类器,使用AdaBoost集成方法避免卷积神经网络的过拟合,构造强分类器,从而提高对信用风险不平衡数据集的评估准确性和鲁棒性。
1 信用风险评估模型:ADASYNAdaBoost-CNN
1.1 ADASYN算法
ADASYN算法的主要思想是根据少数类样本密度分布自适应生成不同数量的新少数类样本[14]。与SMOTE算法为每个少数类样本生成相同数量的新样本相比,ADASYN方法不仅可以减少原始不平衡数据分布带来的学习偏差,还可以自适应地将决策边界转移到难以学习的样本上。
ADASYN算法步骤如下:
输入:训练集{(x1,y1),(x2,y2),…,(x i,y i),…,(x n,y n)},其中x i是n维特征空间X中的一个实例,y∈Y={1,-1}是类别标签。n s:少数类样本数量,n l:多数类样本数量。
输出:加入合成样本后数据集。
(1)计算数据集的不平衡率:d=n s/n l,其中,d∈(0,1]。
(2)如果d<dth(dth为最大不平衡率预设阈值):
1)计算需要为少数类样本生成的合成数据示例的数量:G=(n s-n l)×β。其中β∈[0,1],用于指定合成数据生成后所需的平衡水平。β=1表示完全平衡的数据集。
2)对于每个少数类样本,基于n维空间中的欧式距离找到K个最近邻,Δi为k个邻居中属于多数类的样本数,并定义比例r i为:r i=Δi/K,i=1,…,n,r i∈[0,1]。
4)计算每个少数类样本合成样本的数量:g i=̂×G。
5)对每个少数类样本,按照以下步骤合成样本:Forz=1 tog i:
①在待合成的少数类样本x i的K个最近邻中选择1个少数类样本x zi。
②根据s i=x i+(x zi-x i)×λ合成新少数类样本,其中λ是一个随机数,λ∈[0,1]。
1.2 AdaBoost-CNN算法
AdaBoost[15]是一种精度提升算法,其核心思想是通过不断调整样本权重和创建若干基分类器,直至新创建的基分类器的精度不再变化,进而将创建的基分类器组合成一个强分类器以达到较好的预测效果。训练过程中,AdaBoost算法自适应地调整数据集中每个样本的权重。首先,为训练集中的每个样本随机分配一个相同的权重,表示对所有样本的重要性相同。然后在迭代过程中,增加错误分类的样本的权重,减少正确分类的样本的权重,目的是在后续的迭代过程中更加重视误分类样本的学习,使分类错误率随着训练增加而稳定下降。
卷积神经网络(CNN)是一种包含卷积计算并且具有深度结构的前馈神经网络,能够在大量数据样本中自动学习原始数据特征表达。因此,基于卷积神经网络的分类性能,将其作为基分类器,构造AdaBoost-CNN集成学习模型,以处理不平衡数据分类[16]。本文构建的卷积神经网络主要由输入层、卷积层、池化层、全连接层和输出层组成,其中,除了输出层使用Sigmoid函数作为激活函数外,其余都使用ReLU作为激活函数,同时在池化层和全连接层后添加了Dropout技术以缓解过拟合。
AdaBoost-CNN算法步骤如下:
输入:训练集{(x1,y1),(x2,y2),…,(x i,y i),…,(x n,y n)},其中其中x i是n维特征空间X中的一个实例,y∈Y={1,-1}是类别标签。
Form=1 toM:
(1)如果m==1,根据初始化样本权重分布D m-1={D1()i=1n}在训练集上训练第一个基分类器C m-1(x)。
否则,将前一个基分类器的学习参数转移到第m个基分类器:C m(x)。根据样本权重分布D m在训练集上训练第m个基分类器C m(x)。
(2)获取第m个基分类器的输出,即每个类别的概率估计:(x),其中k={0,1}。
(3)基于(x)更新数据样本权重D m。
(4)重新标准化数据样本权重D m。
(5)保存第m个基分类器:C m(x)。
2 评价指标
不平衡数据分类结果可以用混淆矩阵表示,本文将存在违约现象的少数类定义为正类,具备良好信贷关系的多数类定义为负类。混淆矩阵如表1所示:

表1 混淆矩阵
根据混淆矩阵,相关评价指标如下:
精确率(Pr eci sion)表示被预测为正类的样本中实际为正类的比例:
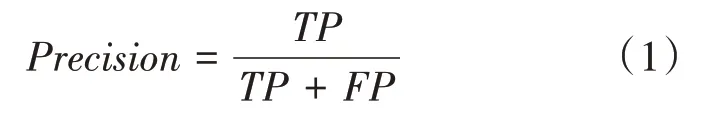
召回率(Recall)表示正类样本被正确分类的概率:

F1值(F1-measure)表示精确率和召回率的加权调和平均,当F1值高时意味着精确率和召回率都高:
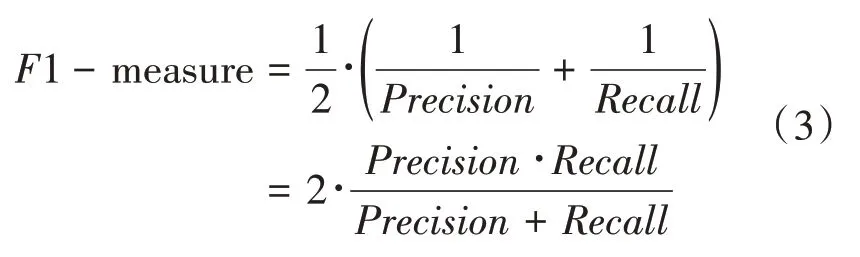
G-均值(G-mean)表示正类分类准确率和负类准确率的均衡值:
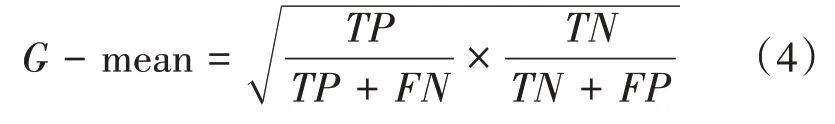
F1-measure和G-mean表现了分类准确率的高低,ROC曲线下的的面积AU C的大小,体现了模型平均性能的优劣,A U C值越大,模型性能越好。
3 实验结果与分析
3.1 数据预处理
本文实验数据集使用从Kaggle获取的Lending club数据集的一个子集,其中数据集总量90096条,多数类样本76745条,少数类样本13351条,不平衡率为0.17。
使用ADASYN算法对数据集进行过采样后,数据集总量为151026条,多数类样本76745条,少数类样本74281条,数据集趋于平衡。
对采样后的数据集进行分类预测,基于先前研究,采用对比算法为AdaBoost[15]算法,SMOTEBoost[5]算法,AdaBoost-CNN算法[16],其中Ada-Boost算法,SMOTEBoost算法使用决策树作为基分类器,深度为8,实验中使用10折交叉验证方法,将数据集划分为10份,其中9份作为训练集,1份作为测试集,重复进行10次实验,取平均值作为结果。对于ADASYN-AdaBoost-CNN模型与AdaBoost-CNN算法,在训练过程中将数据集的80%作为训练集,20%作为测试集。本文ADASYN-AdaBoost-CNN模型实验过程如图1所示。
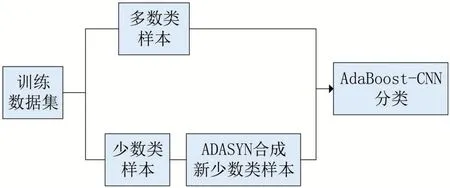
图1 ADASYN-AdaBoost-CNN模型实验过程
3.2 结果比较与分析
仿真实验后,本文提出的模型ADASYN-AdaBoost-CNN和其它对比算法在数据集下得到的评价指标值如表2所示。其中加粗值为当前评价指标下最高值。为了更直观的表示实验结果,图2展示不同算法得到的实验结果对比图,图中横坐标表示评价指标,纵坐标表示结果取值。
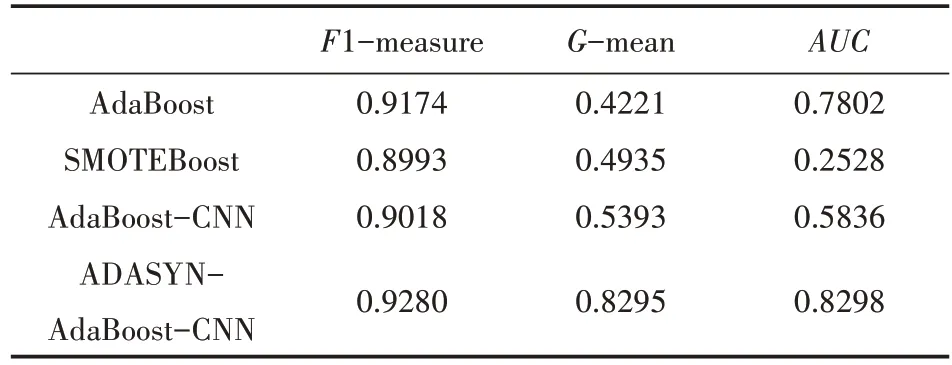
表2 不同算法在数据集上的F值、G-mean、A U C值
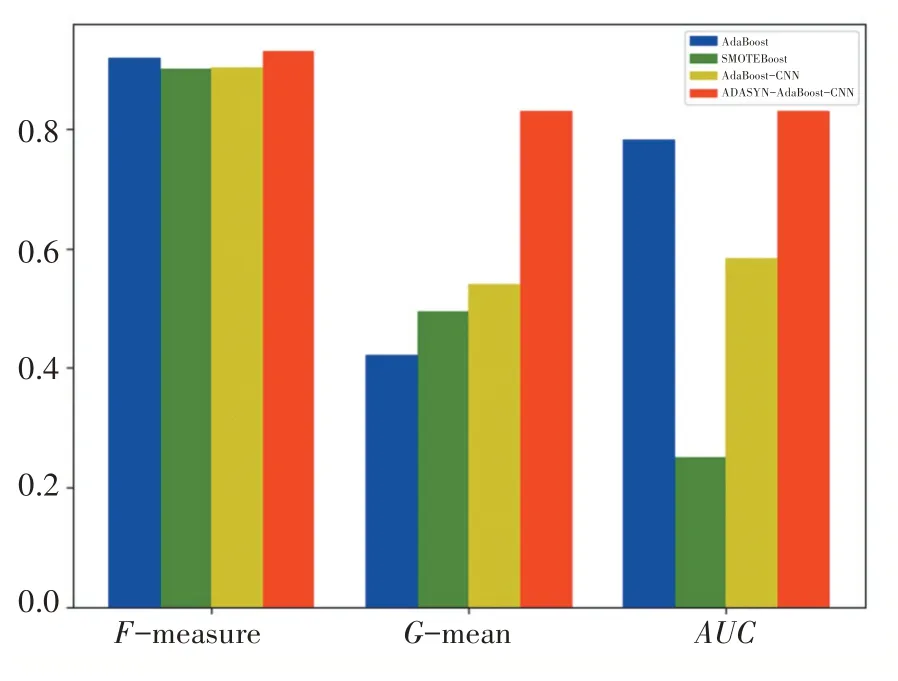
图2 实验结果对比图
从上述结果可以看出,本文提出的ADASYN-AdaBoost-CNN模型整体表现最优。在F1-measure评价指标上,4个不同算法结果较为稳定,说明模型的精确率和召回率保持在稳定的状态。其中,相对于SMOTEBoost算法本文模型的F1-measure提高3%。在G-mean评价指标上,ADASYN-AdaBoost-CNN模型的G-mean达到82.95%,与AdaBoost算法相比提高40%,与SMOTEBoost算法和AdaBoost-CNN算法相比提高30%,说明本文模型对于训练数据集的正类分类准确率和负类分类准确率较高。在AUC评价指标上,相比SMOTEBoost算法,ADASYN-AdaBoost-CNN模型的AUC值提高57%,与其他两个算法相比也有明显提升,说明本文模型的泛化性能较好,能够针对信用风险不平衡数据集进行有效评估。
4 结语
针对信用风险评估中数据集不平衡现象,本文应用ADASYN自适应过采样算法进行数据预处理,减小数据集不平衡程度,并进一步结合Ada-Boost集成算法的鲁棒性以及卷积神经网络的分类准确性,构造ADASYN-AdaBoost-CNN信用风险评估模型。实验结果表明,与AdaBoost,SMOTEBoost,AdaBoost-CNN算法相比,本文模型实现了对信用风险不平衡数据集的有效评估,有助于借贷平台降低风险,进而维护借贷系统中良好的运作环境。
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
电子产品世界(2022年4期)2022-04-21
煤气与热力(2022年2期)2022-03-09
科学与财富(2019年9期)2019-06-11
智富时代(2018年2期)2018-05-02
智富时代(2018年2期)2018-05-02
软件(2017年6期)2017-09-23
