
基于视觉检测的语音导航抗干扰系统
2021-12-02 01:22任碧芸刘宁董逸轩朱亦成刘微雪王晗
现代计算机 2021年28期
任碧芸,刘宁,董逸轩,朱亦成,刘微雪,王晗
(南通大学交通与土木工程学院,南通 226019)
0 引言
随着定位与导航技术的发展,车载导航设备被广泛应用[1]。常见导航设备的人机交互系统可分为触摸输入式和语音输入式。相较于触摸输入式导航设备,语音输入式导航由声音控制,操作更加方便。采用语音导航,司机可以解放双手,在车辆行驶过程中通过语音对其交互控制,从而避免操作时潜在的驾驶危险[2]。然而,常见语音导航设备无法准确判定出声音信号的来源;此外,车内外噪音也对其造成干扰[3]。利用视觉信息检测司机嘴部说话状态,进而控制语音导航的控制权限可以有效减少乘客语音和外部环境的干扰。现有方法通过相位空间分析嘴部区域整体像素值的变化特性来判断嘴部说话状态[8]。该方法可有效地减少光照对于像素值变化的影响。然而,该方法无法消除因为头部移动引起的像素值变化,导致说话状态的误判。同时,对闭嘴音的说话状态效果欠佳。
针对上述问题,本文设计开发一种基于视觉检测的自适应语音导航抗干扰系统。系统由司机正面设置的摄像头对脸部的主要特征点进行检测。通过判定面部方向自动调整嘴部状态判别函数的参数,对嘴部动作进行实时检测,进而获取语音信号开启和关闭的时间控制信号,增强司机对语音导航的控制权限,减少车内外的噪音干扰。经过实际车载环境检测,本系统准确性高、实时性能好,具有较好的应用前景。
1 基于视觉检测的语音导航抗干扰系统
1.1 系统组成
系统的组成分为硬件组成和软件组成两个部分。系统硬件设备组成包括:司机面部监控摄像头(罗技C270)、汽车驾驶系统、视频采集卡、数据传输线及英伟达Jetson深度学习开发板。软件系统按照不同的功能分为以下几个模块:传感器连接模块、人脸特征点提取模块、唇部状态识别模块、语音信息匹配模块、语音导航控制模块。首先,人脸特征点提取模块读取驾驶员面部监测摄像头中的图像信息,进而采用HOG pyramid算法进行人脸检测;再采用人脸对齐算法完成人脸特征点的提取,接着唇部状态识别模块对唇部进行定位并获得唇部特征点,基于特征点建立数学模型,从而完成唇部状态识别,判断驾驶员张闭嘴情况,确定驾驶员的语音时间窗。最后,语音信息匹配模块通过摄像头内置的麦克风获取语音信息,并将声音信息与唇部状态信息进行匹配,从而利用时间窗对司机声音信号进行判断、裁剪,为语音导航提供语音指令。如图1所示。
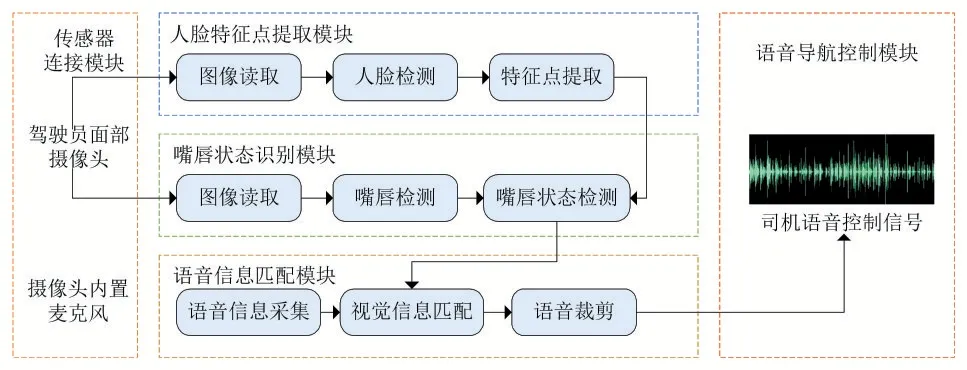
图1 语音导航抗噪声干扰系统软件部分流程
1.2 人脸检测与特征点匹配
本文采用基于Dlib人脸识别的68特征点检测方法,获取嘴部面部标志的索引[4]。通过opencv对视频流进行灰度化处理,检测出人嘴的位置信息。人脸特征点检测主要包括两个关键算法:基于HOG Pyramid[5]的人脸检测、基于回归树GBDT的人脸特征点匹配。前者用来检测人脸区域的界限;后者是用来检测固定区域内的特征点,并输出这些特征点的坐标[3]。
特征点检测主要使用一种基于回归树的人脸对齐算法(GBDT)[6],这种方法通过建立一个级联的残差回归树(GBDT)来使人脸形状从当前形状一步一步回归到真实形状。每一个GBDT的每一个叶子节点上都存储着一个残差回归量,当输入落到一个节点上时,就将残差加到改输入上,起到回归的目的,最终将所有残差叠加在一起,就完成了人脸对齐的目的,准确地定位出各个关键特征点。显示的效果如图2所示。

图2 人脸检测及其特征点匹配结果
1.3 多角度自适应嘴部动作判定
1.3.1 嘴部状态识别模块
通过仔细观察司机发音时嘴部特征点相对位置的变化,无论是张口音还是闭口音(O型嘴),特征点(51,53)之间的距离与特征点(51,59)之间的距离比值均会变小。因此,我们定义了判定是否发音的嘴部状态判定公式,如式(1)所示。
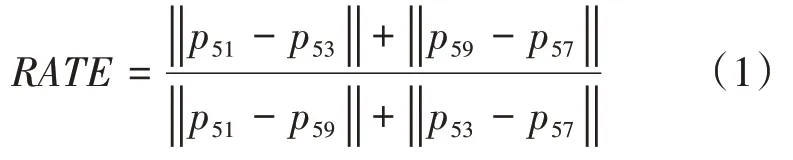
式中,RA TE代表着唇部上下边缘峰点横向距离与纵向距离的比值,pi代表着第i个特征点位置坐标|.|代表着两个特征点之间的距离。公式与特征点对照关系如图3所示。
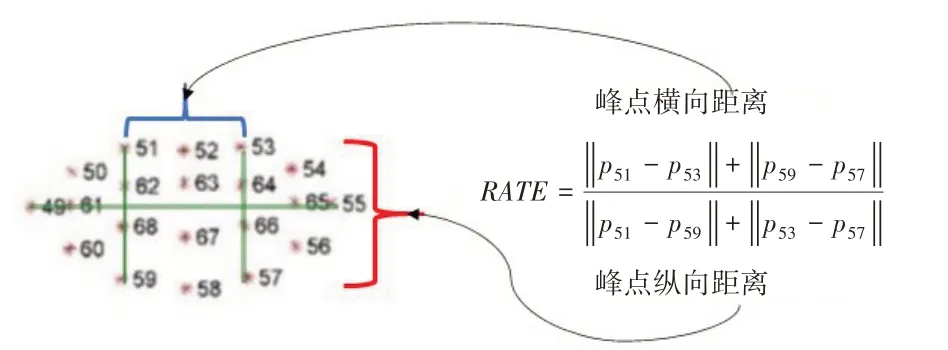
图3 本文提出的唇部发音状态判定数学模型与特征点对应关系
为了准确确定上述判定方法的阈值,本文采用基于贝叶斯最小错误的决策方法:首先,我们将训练阈值样本集合分成发音和非发音这两个类别;其次,利用正态分布分别拟合两个类,获取正态分布的参数;最后,利用基于最小错误的贝叶斯决策公式确定出最优的阈值。
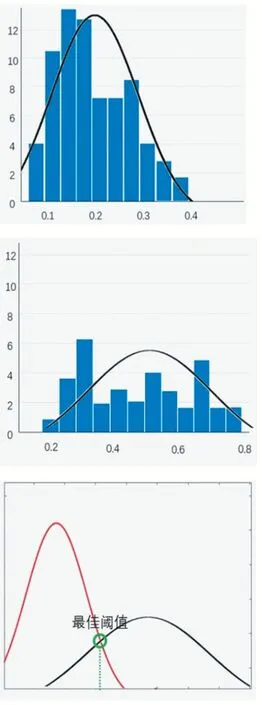
图4 样本正态分布拟合与最优阈值获取
图5给出了两组“O型嘴”闭嘴音发音时,不同数学模型的状态(说话/非说话)判定实验结果实例。经过比较可知,传统方法(MAR)发生误判如黄色框所示,把闭嘴音识别成非说话状态。相反,本文方法(RATE)对闭嘴音的判定较为准确、稳定。这说明上唇线峰点之间的距离对于“O型嘴”闭嘴音的状态更加敏感。

图5 不同嘴部状态识别方法“闭嘴音”识别结果比较
1.3.2 多角度自适应阈值选择方法
为了增强司机在转头侧面下也能判定出嘴部是否发音的状态,本文设计了一种基于面部方向检测的自适应阈值条件方法,如图6所示。

图6 基于面部方向检测的自适应阈值选择方法
利用两个嘴角的特征分别到最近脸颊特征点的距离之比r(下图蓝色线段所示)作为正面和侧面的判定依据,如图7所示。

图7 基于特征点距离比例的司机正面、侧面方向判定方法
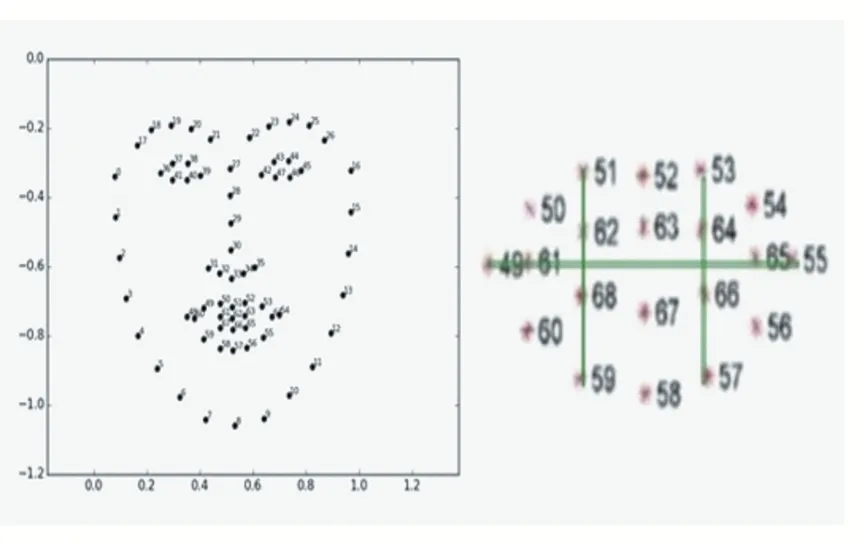
根据上述依据,建立方向判定函数f(r)及其自适应阈值选择数学模型RAT E(r)如下:

式中,r代表着两个嘴角特征点(43,55)到相应脸颊特征点(4,32)的距离比值,a1,a2分别代表着正面时r的最小值和最大值。pi代表着第i个特征点。左右侧脸下,嘴部状态判定比较实验结果如图8表示,传统MAR在右侧没有说话时发生误判如黄色框标注所示,而本文方法较为准确、稳定。

图8 嘴部状态判定比较实验结果
1.4 视觉信息匹配与语音裁剪
视觉信息匹配与语音裁剪模块的流程图如图9(a)所示。首先,对实时检测出来的唇部状态进行平滑滤波,去掉误判带来的时间不连续。其次,确定嘴部发音的时间起止时间,将其确定为时间窗口长度。最后,利用“时间窗”对声波进行裁剪,输出司机说话过程中的声音信号作为语音导航的输入命令语音。
为了保证视觉和语音信号的采样充分,设计了基于全局标志位的跨线程控制模式:视觉检测线程中,如果检测到开始说话,令全局标志位值为1,开启声音采集控制信号;一旦检测到开始停止说话,领全局标志位值为0。关闭声音采集控制信号。在语音指令录制线程中,始终扫描检测全局位值的情况,根据标志位实时准确的录制语音指令和采集声音信号,原理如图9(b)所示。
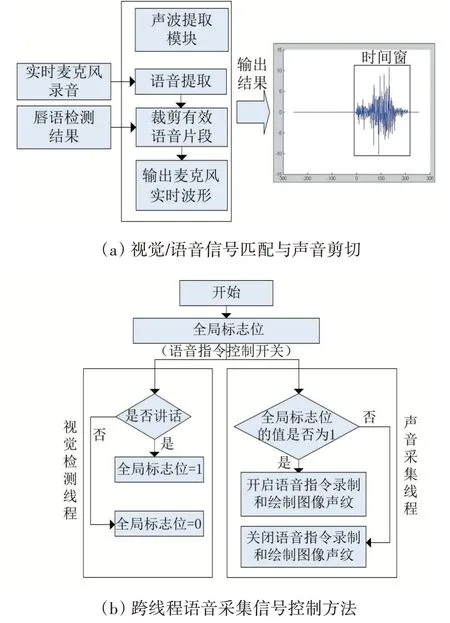
图9 视觉匹配与声音裁剪过程及其跨线程控制方法
2 实验结果及其分析
2.1 实验环境与数据介绍
图10给出了本文系统的硬件设备及其配置图:在司机头部正前方设置面部表情监控摄像头,实际车载环境中利用罗技摄像头,利用英伟达开发板在模拟驾驶系统中做嵌入式计算支持。

图10 基于视觉检测的语音导航抗干扰系统硬件设备及其配置图
为了验证所提方法的效果,利用Python语言进行“基于视觉的语音导航抗干扰系统”软件系统的开发,并且制作了人机交互界面如图11所示。系统自动识别驾驶员的嘴部状态来判断驾驶员是否在说话,并将判断结果在监控窗体内显示出来,主界面由人脸检测画面、驾驶员声音波形及环境声音波形图构成。

图11 基于视觉检测的语音导航抗干扰系统实时运行结果
2.2 评价方法与性能比较
表1给出了本系统中,关于嘴部状态识别性能的评价指标及其结果。为了测试本系统的性能,我们组织多位同学,采集了近5000张样本图像,将采集的样本进行最佳阈值训练,并根据训练的结果对传统识别方法MAR和本文方法RATE进行实时测试。测试结果如表1所示:RATE识别正确率达到90.27%,提高8%;错误率达到7.73%,降低7%。性能得到明显提高,经过滤波后能够比较准确地确定出声音信号的时间窗。
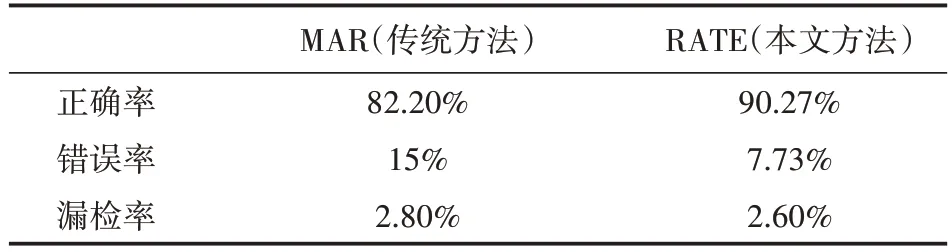
表1 嘴部状态识别结果性能评价结果
3 结语
针对语音导航设备在噪音环境下无法识别出声音的来源问题,本文设计开发了一种基于视觉检测的语音导航抗干扰系统。该系统通过车内的摄像头来对驾驶员的嘴部状态进行检测,判断出驾驶员是否在说话。利用视觉检测结果确定司机说话的时间窗,进而对声音信号进行有效的裁剪、滤波;确定司机对语音导航系统的控制权限,减少车内外噪音对其产生的干扰。实验表明,本系统有着较高的实时识别率,准确性高、实时性能好,对于头部水平移动、两侧方向转动、光照变化均有较好的鲁棒性,并且系统成本较低、安装方便快捷具有较好的市场应用前景。
猜你喜欢
意林·作文素材(2021年9期)2021-07-06
奥秘(2021年5期)2021-06-15
小资CHIC!ELEGANCE(2020年2期)2020-03-10
保健与生活(2020年3期)2020-03-02
小资CHIC!ELEGANCE(2019年30期)2019-09-12
阅读(快乐英语高年级)(2019年5期)2019-09-10
阅读(快乐英语高年级)(2019年2期)2019-09-10
小说界(2018年5期)2018-11-26
小雪花·初中高分作文(2017年9期)2018-05-21
女友·家园(2016年11期)2016-11-10
