
融合自编码降维的改进DNN水利工控网入侵检测算法*
2021-12-01 14:17刘庆华赵雪寒
计算机与数字工程 2021年11期
刘庆华 赵雪寒
(江苏科技大学电子信息学院 镇江 212001)
1 引言
随着科技互联网的发展,工业系统在许多领域取得了广泛的应用。许多工控系统在建立之初主要考虑系统的功能性,并未过多考虑系统的可靠性,工控系统的安全性面临着一定的风险[1~3]。
本文在对江苏省常熟水利枢纽望虞河站进行调研后针对水利泵站工控网易受攻击的分析主要有[4~6]网络结构的设计存在漏洞,且防护力度不够;主从站之间数据传输缺乏加密机制认证,从站设备正常运营受到影响;泵站工控网内通信协议的漏洞导致非法数据的入侵。针对以上问题,本文设计了一套融合自编码降维的改进深度神经网络的工控网非法数据入侵检测算法模型。该算法模型主要研究、分析协议自身及面临的安全性问题,结合自编码降维算法准确地检测出非法入侵的数据,为防护水利工控网通信安全奠定了基础。
2 水利泵站工控网检测算法
2.1 自编码数据降维
工控网内的数据流动量是很大的,就水利泵站通信网而言,从底层设备导入到本地数据库的每条数据都包含了27维特征,维度越高,数据在每个特征维度上的分布就越稀疏,这对于深度学习算法而言是灾难性的,故而在进行网络模型训练前需要进行数据降维,本文采用自编码器对数据进行处理,该方法可以有效地初始化权值,相比主成分分析法更有用。主成分分析法(PCA)就是为了从多维特征数据中找到能反映主元信息的数据属性,而自动编码器也正是如此,它实际上是一种无监督学习算法,一种尽可能复现输入信号的神经网络,因此必须在输入数据中提取出最重要的有代表性的特征因素。
自动编码网络首先将输入的27维特征通过编码网络得到编码,然后初始化编码网络的权值[ω1,ω2,…ωn],给定样本数据[x1,x2…xn],为了能更加有效地表示样本数据,加入了稀疏编码算法以更好地搜寻基础特征,即用一组基向量的线性组合来表示输入向量X:

通过稀疏编码算法训练学习一组基向量[φ1,φ2,…]后,利用基向量得到对给定样本数据的表达向量[α1,α2,…],经过不断训练和调整编码网络的权值和偏置值使重构误差最小,本文采用误差的偏导数后向传播的方式得到梯度,从而可以将权值调节到最佳值,权值更新的公式如下:

其中,wn指n层的权值更新量,En+1是下一层网络的误差,In是本层的输入,bn是n层偏置项更新量,Res是残差。在得到第一层的编码后,将第一层网络计算得到的编码结果作为第二层网络的输入信号,并且进行最小化误差重构计算,即可得到该层网络的参数及下一层网络的输入编码,以此类推直到结束从而达到降维的效果[12]。
2.2 模型参数优化
参数优化是一个全局的过程,通过优化可以较大程度调节学习率,促使网络参数更适应于当前样本数据。因为如果学习率很低,训练虽然会更加稳定,但是由于趋于损失函数loss最小值的步长很小,所以会花费大量时间来优化;如果学习率很高,则会导致训练结果收敛不了,优化会越过最小值从而使得损失值变大[13~14]。深度神经网络模型常用的优化算法是SGD(随机梯度下降算法),而SGD有很多衍生的算法,如Adagrad、RMSProp、Adadelta等。
常见的SGD优化算法是通过每次在训练集中随机选择一个样本的方式进行学习,过程是很快速的,所有的θt都使用相同的学习率,因此迭代到第t次时,参数向量Δθt的变化过程如下:
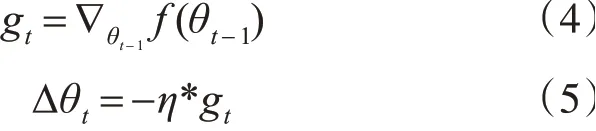
其中,η是学习率,gt是某次迭代时刻t目标函数对参数的梯度。该算法最大的缺点在于每次学习的方向不定,可能不会按照正确的方向进行,这就容易造成结果在最优解附近扰动[15]。而Adagrd算法可以很好地解决这个问题,在更新规则后,它能够针对不同的参数自适应不同的学习率,让其按照需要的正确的方向进行,参数向量Δθt的变化过程如下:
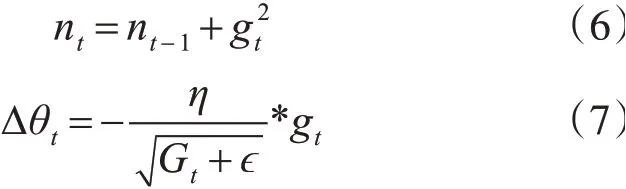
此处,Gt是一个对角矩阵,ε是平滑项,防止除零操作,对gt从1到t进行一个递推形成约束正则化矩阵,前期gt较小时,正则化矩阵较大,可以增大梯度值,后期gt较大时,正则化矩阵较小,可以约束梯度。但该算法仍有弊端,在计算梯度序列平方和时较为复杂,且分母上梯度平方累加逐渐增大,会导致训练提前结束。故而本文采用Adadelta算法,只使用Adagrad的分母中的累计项离当前时间点比较近的项,即将分母中的Gt换成了梯度平方的衰减平均值E[g2]t,避免了训练提前结束,公式如下[16]:
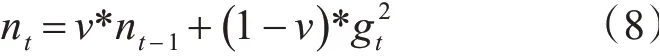
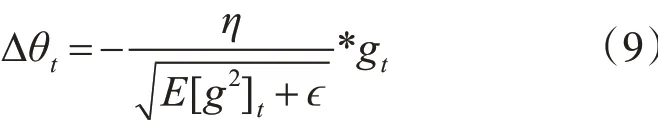
式中若是梯度更新值产生振动,则让梯度减小(乘以1-v),否则增加v,v的默认值为0.02,该算法可以有效地解决水利泵站工控网数据稀疏特征、数据量大的问题,收敛速度快,适用于本文提出的改进深度神经网络模型。
3 算法优化
3.1 基于DNN的入侵检测模型
由底层设备获取到的工控网内数据有很多并非工控协议,这就需要预先采用脚本剔除,比如Modbus协议中目的端口号是否是502,Profibus协议的开始定界符是否是16H,Hart协议的前导码是否由5位FF组成,这样预先进行剔除操作可以适当减少数据量。同样地,对协议地分类标准也是如此。同时为了让数据尽量处于相同的量纲,把数据限定在某一范围内,则需要进行归一化处理,公式如下:ρmax和ρmin分别对应数据中的最大值和最小值。
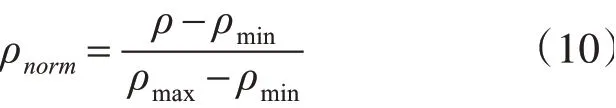
在对数据进行预处理、分类、特征选择降维后,将得到的训练数据集经过网络进行训练,对可以得到每一层网络层的训练输出结果,而要训练具有多个隐含层的深度网络的全局优化值,便要采用逐层训练的机制,每次针对网络某一隐层进行训练,得到该层的最有参数和特征,作为一下层输入;然后再对下一层进行单独训练得到相关数据,以此类推,逐层训练出整个网络的全局最优解,最后可得到深度神经网络入侵检测模型。为了验证模型的准确度,采用测试数据集进行验证,最终通过Soft⁃max分类器输出预测结果,通过加入权重衰减改动损失函数来解决Softmax回归的参数冗余带来的数值问题[17~18]。网络共五层,由输入层、三隐藏层和输出层构成,在每层之间采用Dropout来防止过拟合发生,Dropout率始终保持在20%~50%之间,输入层的节点由每种协议的维度决定,三隐藏层的节点一般通过经验确定,可以采用遍历的方法比较选取最合适的节点数,但由于该方法会耗费大量时间和人力,所以本文通过公式法确定,公式如下:

式中m指隐含层节点数,n指输入层节点数,α是1~10之间的常数,采用公式法大大减少了遍历的次数和时间。同时隐藏层需要采用激活函数RE⁃LU,可以很好地解决神经网络训练过程中的梯度弥散问题,基于DNN的入侵检测模型如图1所示。
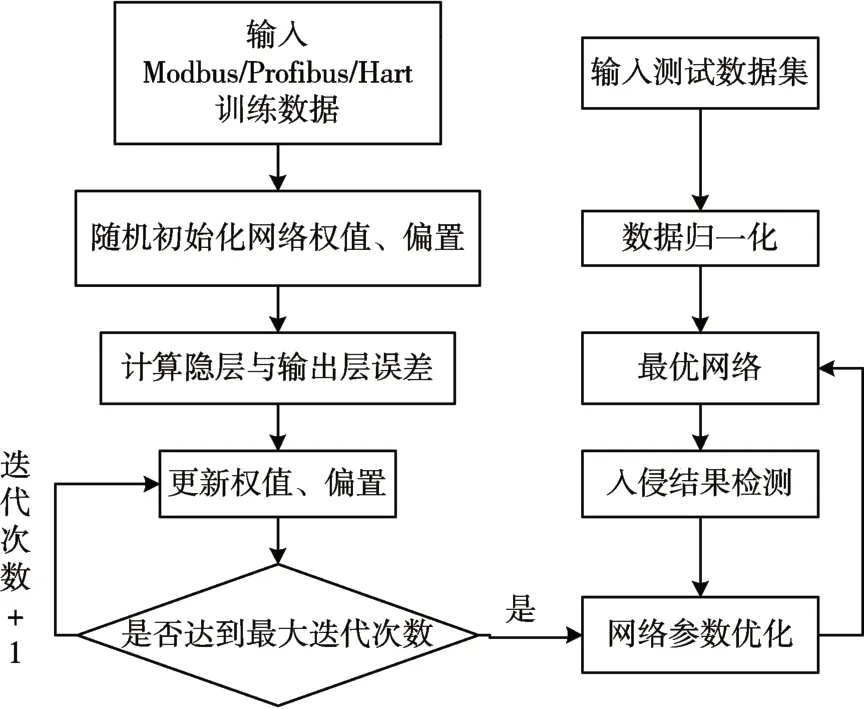
图1 基于DNN的入侵检测模型
3.2 基于受限玻尔兹曼机的改进DNN入侵检测模型
本文以受限玻尔兹曼机网络(RBM)作为构建深度神经网络算法的基础,对原来模型的特征提取进行改进,将RBM层作为深度网络的单层结构实现深层特征提取,以便得到更高级的特征向量,以此作为分类识别的依据。RBM由可视层与隐藏层组成,RBM在可视层和隐藏层之间有一个联合组态的能量,可表示为
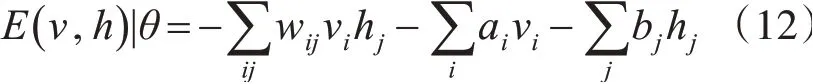
其中:θ={w,a,b}为RBM模型参数,RBM的学习过程就是通过训练获得参数θ的过程。wij表示可视单元i与隐藏单元j之间的连接权重,ai为可视单元i的偏置,bj为隐藏单元j的偏置,基于该能量函数,可得到(v,h)的联合概率分布:
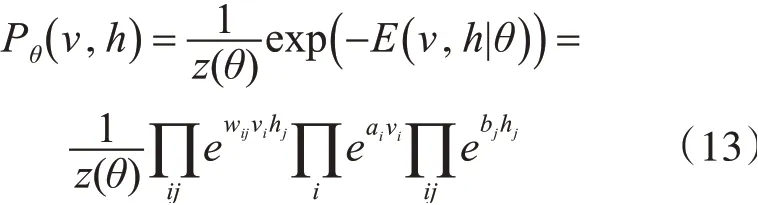
将多个RBM网络层进行叠加,组成新的网络,使得该网络具有较高的灵活性和可扩展性,模型如图2所示。
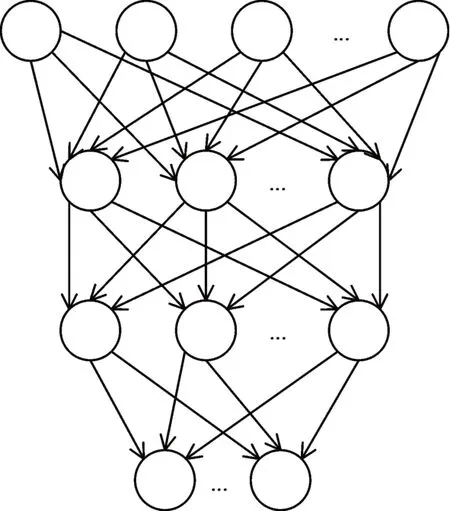
图2 RBM网络组成有向无环模型
将多层RBM叠加后,高层RBM网络输入数据采用底层RBM网络输出数据,且数据是训练得到的概率分布数值。需要注意的是,仅含有由多层RBM网络叠加而成的网络结构只能够实现对输入数据的特征提取工作,要实现最终的入侵检测任务,我们需要在网络的最终层输出之上设置一个Softmax分类器对网络输出数据做出合法非法的分类,把网络的最后输出层数据作为Softmax回归分类器的输入值,从而形成完整的分类神经网络[19~20]。整个网络仍有五层,但对隐藏层节点数的计算方法有所改进,增加了输出节点数:

其中m为网络输入节点数,n为网络输出节点数,k为10左右的常数。这样通过网络的实际结构加上实验的基础更加准确地确定隐藏层节点数,以减少资源虚耗,入侵检测模型如图3所示。
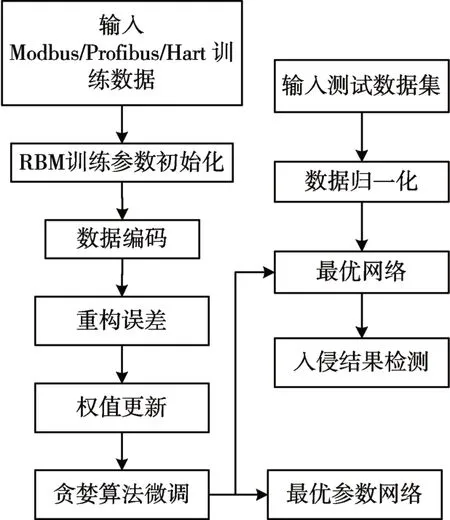
图3 基于受限玻尔兹曼机的改进深度神经网络的入侵检测模型
4 实验与分析
4.1 实验数据准备
本文的实验数据从水利泵站工控网采集,将采集得到的数据处理后存至本地保存,其中,数据处理的操作主要包括训练集、测试集制作。采集数据除了工控网内正常数据外,为了能够检测出非法数据,还对工控网内DNS欺骗数据、拒绝服务攻击数据、IP源地址欺诈等多类异常数据。
4.2 实验评价标准
入侵系统评价指标主要包括三个:1)检测率,该指标为工控系统受攻击后,系统能够正确检测到概率;2)误识率,该指标为工控系统将正确行为判断为攻击行为的概率;3)漏报率,该指标为工控系统未检测到外界攻击系统的概率。以上三个指标的计算公式如下:
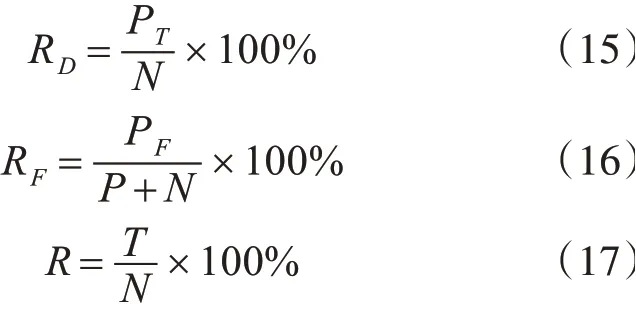
其中PT是工控系统入侵检测模型正确预测攻击行为的数量,N是总攻击数,PF是入侵检测模型错误预测攻击行为数,P是总正常样本量,T是模型不能正确预测的样本数量。
4.3 算法对比
为了验证本文算法的效果,下面将从两个方面进行验证比较。
首先是网络模型参数优化算法,SGD、Adagrad算法都可优化模型,但其对收敛速度的影响相比本文采用的Adadelta算法有不足。三种算法学习曲线如图4所示。
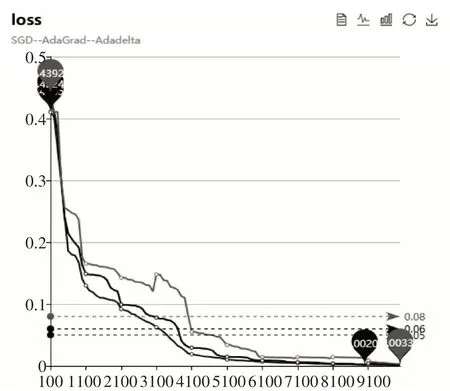
图4 三种算法学习曲线图
由上图可看出随着迭代次数的增加Adadelta算法很快便寻找到正确的方向并前进,收敛速度也相当快,而Adagrad算法收敛速度较Adadelta慢些,SGD算法不仅收敛速度慢,且中间出现“走弯路”现象,在震荡后才沿正确方向收敛。并且本文的优化算法能将loss值收敛到0.0012,显然比另两种算法收敛的更小,因此采用Adadelta算法较Adagrad和SGD算法的收敛性更好。
其次是与传统DNN模型以及采用PCA降维算法较。传统DNN模型不能够适应水利泵站工控网数据量大、纬度高的数据特点,所以需要对传统DNN模型进行改进;PCA降维算法主要是线性降维,对水利泵站工控网的非线性数据处理效果并不理想,三种方法的模型训练准确率及在检测率、误报率和漏报率指标方面的表现如表1所示。
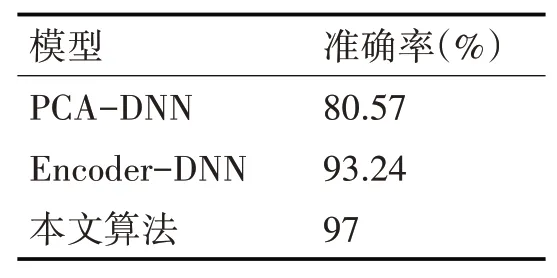
表1 不同算法模型训练准确率对比
由表1可以看出,在训练数据集上进行PCADNN、Encoder-DNN、融合自编码降维的改进DNN模型训练。通过模型在测试集上的测试可知,PCA-DNN模型准确度最低,表明该模型对特征无相关性的数据训练效果不好。本文提出的融合自编码降维的改进深度神经网络模型将数据经过自编码降维处理后,模型训练效果较好;除了数据处理,该模型还针对训练机制等多方面做了改进,模型准确度可达97%,相比其他模型具有更好的攻击行为预测能力。
由表2可以看出,PCA-DNN入侵检测系统的检测率较低、误报率及漏报率高,模型训练效果不好,其主要原因是因为降维效果不好。自编码降维算法检测率相比PCA-DNN来说有了一定的提高,但与本文提出的改进网络相比,检测率还有待提升,且漏报率也相对较大,但其误识率较本文算法略低。综合以上分析可以得到如下结论:本文提出的算法模型综合效果最优,对系统攻击的检测具有较高的准确性,系统具有较强的稳定性。
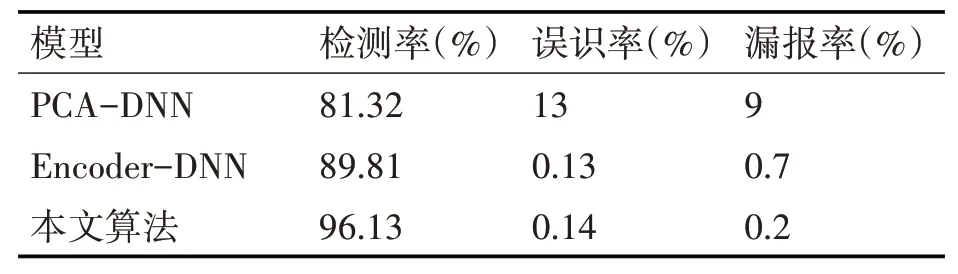
表2 不同算法的入侵检测模型性能指标对比
5 结语
水利泵站工控安全问题在不断引起重视,本文以水利泵站为背景,针对泵站工控网内的高维数据量提出一种结合自编码降维的改进深度神经网络入侵检测模型,在对原始数据自编码降维后,基于受限玻尔兹曼机对网络模型进行改进,再经过网络进行分类预测,同时为了提高算法检测的准确率,采用Adadelta算法对模型进行参数优化。实验结果表明,本文的算法模型优于其他算法,有较高的预测准确率,在检测率、误报率和漏报率三项指标上都比另外两种算法表现优异,具有较好的特征表征学习和分类预测能力,是一种可行且有效的入侵检测模型。
猜你喜欢
河北农业(2022年9期)2022-11-27
农业科技与信息(2022年12期)2022-11-22
车主之友(2022年4期)2022-08-27
汽车实用技术(2022年4期)2022-03-07
小学生学习指导(中年级)(2021年12期)2021-12-30
建材发展导向(2021年15期)2021-11-05
汉字汉语研究(2020年2期)2020-08-13
装备环境工程(2020年3期)2020-04-03
海峡姐妹(2019年12期)2020-01-14
电子制作(2019年22期)2020-01-14
