
基于集成方法的不平衡数据分类研究*
2021-12-01 14:17赵礼峰
计算机与数字工程 2021年11期
陈 力 赵礼峰
(南京邮电大学理学院 南京 210023)
1 引言
在数据分类问题中,不平衡数据分类是一种较为困难的问题,由于数据中存在少数类与多数类,不平衡数据的分类结果往往偏向于多数类,导致表面上的准确率虚高,实际上占重要位置的少数类样本被错分。这个问题在生活中亦普遍存在,例如,防盗门在人脸识别时会出现的四种判别情况:将房主(多数类)正确判别为房主,将房主误判为入侵者(少数类),将入侵者正确判别为入侵者,将入侵者误判为房主。显然,最后一种情况最为严重,一旦误判会造成财产甚至是生命安全的损伤,少数类的分类重要性可见一斑[1]。对不平衡数据分类的研究主要集中在数据层面和算法层面。数据层面包含下采样和过采样,算法层面包含代价敏感学习、集成学习和单分类器学习。本文着重算法层面中集成学习上的研究。集成学习是一种通过训练多个弱分类器后将其集成为一个强的组合分类器再进行分类的方法,训练期间通过不断迭代改变弱分类器和样本的权重,组合形成的强分类器综合了众多弱分类器的优势。在集成算法中,AdaBoost是较为著名的一种算法,有许多针对不平衡数据的算法都是基于其改进而来的[2]。例如Joshi等提出的针对AdaBoost处理不平衡数据的缺陷的RareBoost算法[3],宋海燕将下采样和过采样与AdaBoost结合提出的SPBoost和KBOSBoost等[4]。这些方法有的在迭代过程中融入了代价敏感的思想,有的在算法执行之前就加入了数据层面的处理,但均未能直接适应不同数据集的不同错分代价,往往需要多次迭代才能优化分类效果,这给运算量方面带来了一定的负担。故本文首先对不同分类情况进行分析,定义新的分类评价指标,在指标中引入关注度调整参数,使指标与不同特征的数据集高度相关,进而改变AdaBoost算法中每一轮迭代的弱分类器权重以及弱分类器中的样本权重,使组合分类器自适应不同特征不平衡数据集的分类。
2 相关工作
2.1 AdaBoost算法
AdaBoost算法(adaptive boosting)是一种集成算法,其核心思想是针对同一个训练集训练不同的基分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的组合分类器(强分类器)[5]。AdaBoost算法一方面增大错分样本的权重,减小正确分类样本的权重使得每次迭代后下一轮的弱分类器更关注错分样本,另一方面给予准确率高的弱分类器以更大的权重,准确率低的弱分类器以较小的权重使得性能更好的分类器占据主导地位[6~8],最终集成强分类器。
2.2 GBDT算法
在集成学习中,最常用的方法之一是梯度提升决策树(Gradient Boosting Decision Tree,GBDT)算法。作为集成学习Boosting的成员,但是和传统AdaBoost有很大不同,该方法是利用前一轮迭代弱学习器的误差率来更新训练集的权重,以此迭代下去直至满足收敛条件。GBDT采用前向分布算法,但是弱学习器限定只能使用CART回归树模型,它是在Adaboost算法的基础上改进优化后的一种算法[9]。
GBDT能够灵活处理各种类型的数据,包括连续值和离散值,而且在相对少的调参时间下能够得到较高的预测准确率。
2.3 衡量分类效果的指标
首先,在二分类问题中会发生四种分类情况[10],具体如下:
TP--将正类预测为正类数;
FN--将正类预测为负类数;
FP--将负类预测为正类数;
TN--将负类预测为负类数。
通常二分类常被表述为一种分类矩阵,即混淆矩阵,形式如表1。

表1 混淆矩阵
准确率是衡量一般性分类问题分类效果好坏的主要指标,但在处理不平衡数据分类问题时,由于错分代价的不同,准确率的高低往往无法真实反映分类器的好坏,因此本文额外使用了两种在研究不平衡数据分类时常用到的分类评价指标,三类指标分别如下。
1)准确率(Accuracy)
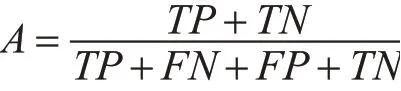
准确率A是指在所有样本中,判别器正确预测的样本数占所有样本数的比例,其值越大表明分类器分类效果越好。
2)F1值(F-measure)
F1值是精确率和召回率的调和均值,即:
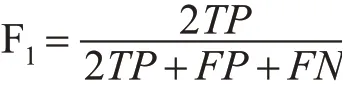
当精确率和召回率都高时,F1值也高,分类效果好。
3)G-mean
G-mean在不平衡数据分类的评价中使用较广[11],它同时考虑了召回率和特异率,当两者都高时其值较高,其综合评估了算法性能,计算公式如下:
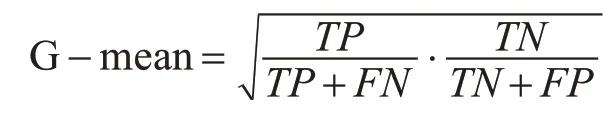
3 PFBoost算法
3.1 PFBoost算法详解
PFBoost算法是本文基于Ada Boost算法提出的一种聚焦于不平衡数据集中正类(少数类)样本分类的集成算法。首先观察表1的2×2混淆矩阵,其中包含了二分类的四种分类情况:将正类预测为正类,将负类预测为负类,将正类预测为负类,将负类预测为正类。前两种属于分类正确的情况,比较可知,不平衡数据对正类样本的正确分类关注程度高于负类样本的,故在构造新的评价指标时给予第一种情况更大关注;后两种属于分类错误情况,在处理实际问题时,将更为重要的正类样本预测为负类样本比将负类样本错分类为正类样本的损失来得更大[12],故给予第三种情况更大关注。至此,四种分类情况的重要性已厘清,接着,本文在研究F1值的计算公式时发现,F1值将正类错分情况与负类错分情况的损失等同视之,而在不平衡数据分类的具体问题中[13],这两者的重要性并不相同,基于此本文开始构造新指标如下:
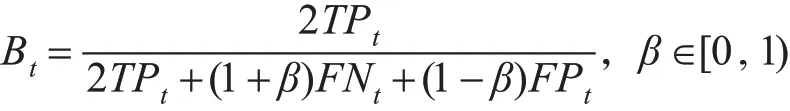
上式中,Bt是第t轮迭代下的新评价指标,TPt,FNt,FPt分别是第t轮迭代下的正类分类正确样本个数、负类样本错分样本个数、负类样本正确分类样本个数,β是关注度调整参数,作用是为了使最终的集成算法自适应不同特征的不平衡数据集。
接着将新指标引入分类器权重的构造中,进而对AdaBoost中的样本权重[14]作改进,迭代集成弱分类器,形成本文的PFBoost算法。
3.2 PFBoost算法流程
PFBoost算法流程如下。

4 实验与分析
4.1 仿真对比实验
本文收集了KEEL数据库和UCI数据库中共计八组不平衡数据集,为证明PFBoost算法对不同特征数据分类的自适应性,收集到的数据涵盖了各种不同的维度特征和不平衡程度特征,展示如表2。为方便聚类,先将数据集中存在的分类变量做哑变量处理[15]、单位不统一的变量做标准化处理[16]。
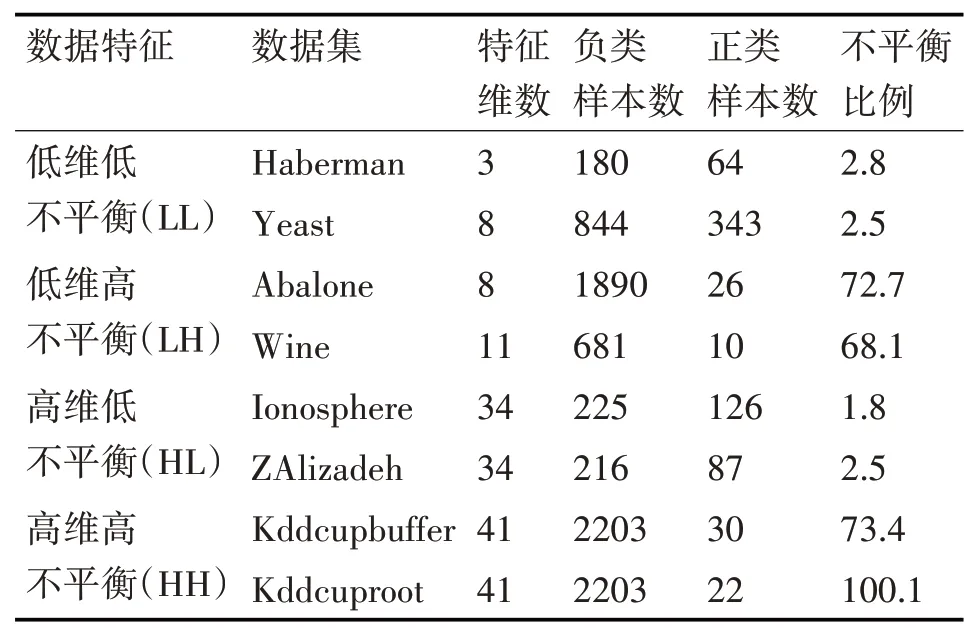
表2 数据集描述
本文对这八个数据集分别运用了AdaBoost算法、GBDT算法和PFBoost算法,并与未经过集成处理的单一决策树作分类效果对比,分类效果采用Accuracy、F1值和G-mean值衡量。
4.2 实验结果与分析
从三种分类标准折线图中可以发现,三种集成算法和未处理的决策树算法对低维不平衡数据集的分类效果均不如高维数据集的。从Accuracy(准确率)角度来看,大多数数据集经过集成算法分类后准确率都有所下降,而PFBoost在重点关注少数类样本分类的前提下仍能使准确率降幅相对最小,甚至在其中5个数据集上的准确率不低于初始未处理算法,计算其在8个数据集上的平均准确率为90.5%,比未经过集成的决策树算法高出2.6%。而观察F1值和G-mean值可发现,PFBoost算法除了在ZAlizadeh一个数据集上的F1值为0.77,比Ada⁃Boost算法的0.783低了0.013,在其余数据集上的表现均为最好,这充分证明PFBoost算法可以在大幅提升其他不平衡数据衡量指标的情况下尽可能少地牺牲分类准确率,对不平衡数据集分类效果优秀。
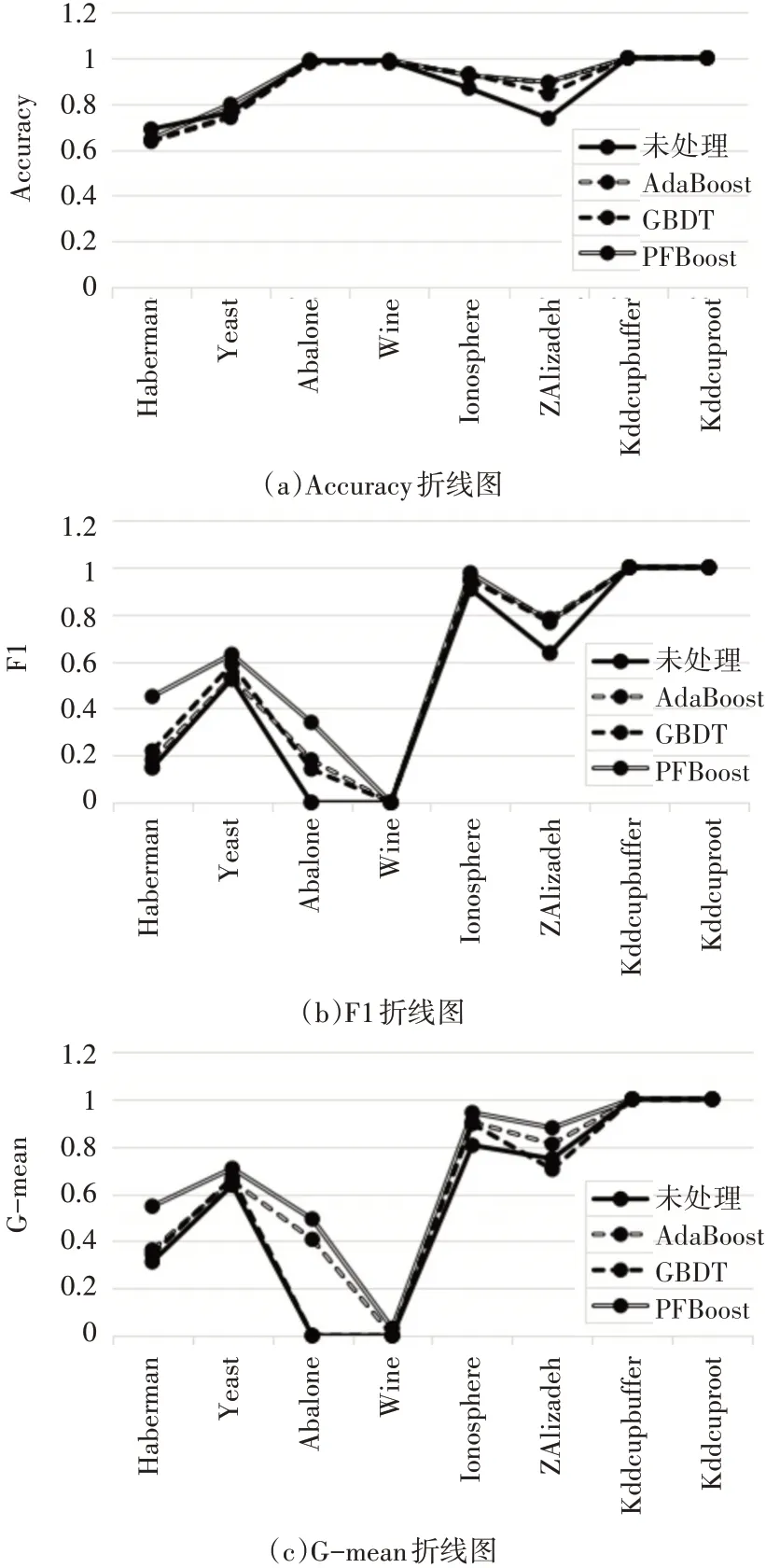
图1 集成方法效果对比折线图
5 结语
本文根据不同特征不平衡数据分类情况重要性的不同,构造了新的适用于不平衡数据分类器的评价指标,并基于此提出了聚焦于正类样本分类正确率的集成算法PFBoost。本算法首先对传统的分类评价指标F1值作出调整,在公式中引入关注度调整参数β,构造出新的评价指标B,再利用此指标改进AdaBoost算法中的分类器权重和样本权重,使PFBoost算法自适应于不同特征的不平衡数据的分类[17]。最后选择决策树算法作为基分类器算法进行仿真实验证实了PFBoost的有效性。
虽然PFBoost算法能够很好地处理不平衡数据的分类问题,其依旧存在缺陷。如随着迭代次数的上升、数据量以及数据维度的上升,算法带来的计算量也会大幅上升[18]。并且本文只使用了一种基分类器算法,可能会有泛化能力不足的问题,在接下来的工作中还可以在本算法中尝试一些其他优秀的分类方法。
猜你喜欢
心理学报(2022年5期)2022-05-16
电子产品世界(2022年4期)2022-04-21
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
计算机系统应用(2021年2期)2021-02-23
健康体检与管理(2021年10期)2021-01-03
当代陕西(2020年17期)2020-10-28
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
