
基于历史轨迹的个性化路线推荐算法的研究*
2021-12-01 14:15赵加坤阚伊柠赵燕子刘小英
计算机与数字工程 2021年11期
赵加坤 阚伊柠 赵燕子 刘小英
(西安交通大学软件学院 西安 710049)
1 引言
随着信息时代的到来,路径导航[1]在我们日常生活中有着重要地位,私家车的出行活动离不开导航系统,与此同时人们对导航功能的需求也逐渐提高。过去的导航软件只是根据我们所提供的起始和终止位置为我们推荐最优的行驶路线,虽然方便实用,但往往所推荐的路线并不适用于所有人,这些导航软件并没有考虑到不同的司机有不同的驾驶习惯。如果导航可以自动获取用户的偏好,再根据偏好过滤出最符合用户需求的推荐路线,那么就将极大程度提高导航软件的导航质量。
因此,本文抓住了这一需求,在前人研究的基础上丰富了轨迹数据的多样性,修改了模型。在司机个人偏好上,不仅考虑了大众所考虑的时间、距离和油耗的问题,还关注到一些经验丰富的司机经常会考虑的转向开销和信号灯等待的问题,进一步对司机的个人行驶偏好建模,提出了一种根据司机不同的驾驶偏好来推荐个性化行驶路线的算法模型,同时文中还使用了大数据技术对车辆的历史轨迹进行存储,可以保证轨迹数据的实时更新,提高轨迹的检索速度,保证了推荐的效率。此方案大幅度提升了推荐路径的合理性和准确性,将在来自全国的私家车数据集上进行验证,这些复杂的数据具有多样性,也进一步验证了文中方法的可用性。
2 相关工作
导航基本可以分为两类:1)基于数字地图的导航;2)基于轨迹数据的导航。
基于数字地图的导航是传统的导航方式,其原理相当于数据结构图的最短路径或者最优路径,其中最简单的是Dijkstra[2]算法和A*[3]算法,主要应用动态规划的原理去计算最短路径,但是当路网比较大、路线图分支比较多时,这种算法会大大浪费时间。在此基础上,覃柯棚等[4]提出一种寻找最短路径更加高效率的改进算法,通过最小堆对算法进行优化,进一步提升了算法的效能。这种方法更加注重效率,但是却没有考虑用户的驾驶习惯。本文提出的方法更加看重轨迹推荐的质量,把用户的偏好考虑在内,最终推荐出与用户偏好最相符的行驶路线,适用于任何复杂路况下的个性化推荐。
基于轨迹数据的导航大多把注意力放在轨迹挖掘[5]上,Letchner J等[6]在文章中首次提出了根据轨迹特点来进行路径选择,打开了个性化推荐的大门,但是数据挖掘技术使用比较单一,未能得到足够的轨迹代表性特征。Funke等[7]提出了用线性不等式的方式对个人的偏好向量进行求解,但是这种方式需要假设用户的历史轨迹是开销最小的,这种假设会与实际情况有一些和误差。Yang等[8]认为在不同的场景下用户的偏好不同,通过SVM分类器的方式得出一个超平面的场景进行个性化推荐,但是这种方式并不能穷举场景,导致推荐的路线有些单一。Dai等[9]使用出租车的历史轨迹为基础进行路径的推荐,得到了很不错的效果,但是出租车的轨迹数据比较单一,对于用户偏好的考虑不周全,本文进一步对轨迹进行挖掘,提取出更多的偏好特征,对偏好分布进行更加精准的建模,从而推荐出更适合用户出行的路线。
另外,本文数据集来自全国各地的私家车历史轨迹数据,提高了历史轨迹的多样性,在数据上更具有信服力。同时文中引用大数据存储技术[10],在轨迹数据索引上极大提高效率,集群的I/O性能[11]是影响整体性能的一个关键性因素,文中对性能进行优化,对I/O性能进行实验验证其高效性。
3 算法模型
3.1 基本概念及整体框架
定义1(轨迹序列)一段行驶轨迹是由无数个轨迹点有序组成的一组序列Trj={t1,t2,…,tn},其t中包含了轨迹点的地理坐标信息。
定义2(轨迹分割)为了更好地对轨迹进行聚类,我们需要根据实际情况把一段长轨迹分割为几个不等长的有序轨迹序列Trj1={t1,t2,…,ti},Trj2=
一般轨迹分割[5]分为四种:按时间间隔分割、按转向分割、按轨迹形状关键点分割以及按照停留点进行分割。根据本文的数据特征,采用最后一种按照停留点进行分割,如图1所示,轨迹就可以分为
定义3(轨迹去噪)由于某一个或者某些个轨迹点的异常会为轨迹挖掘工作带来不必要的麻烦,因此会采取一定的措施去避免这些麻烦。我们采用的方式是均值滤波和异常点舍弃两种方案结合来对轨迹进行去噪处理。
如图2所示,均值滤波可以参考前后点的状态对异常点进行评估。异常点[5]探测方法在本文中主要考虑速度这个过滤条件,首先通过距离和时间间隔去计算该点的实时速度,这里设定阈值为120km/h,超过阈值的点被视为异常点,给予舍弃。
定义4(轨迹高斯混合模型)在轨迹高斯混合模型中,每一个高斯过程函数可以表示轨迹的一个特征,即轨迹的特征是由多个模型线性组合而成的,假设生成来自M个相互独立的高斯过程线性组合的混合模型G={GP1,GP2,…,GPM}。
本文提出的个性化导航[12]方法主要分为三个部分:1)轨迹索引;2)个性化路径获取;3)个性化路径确定。推荐整体框架图如图3所示。
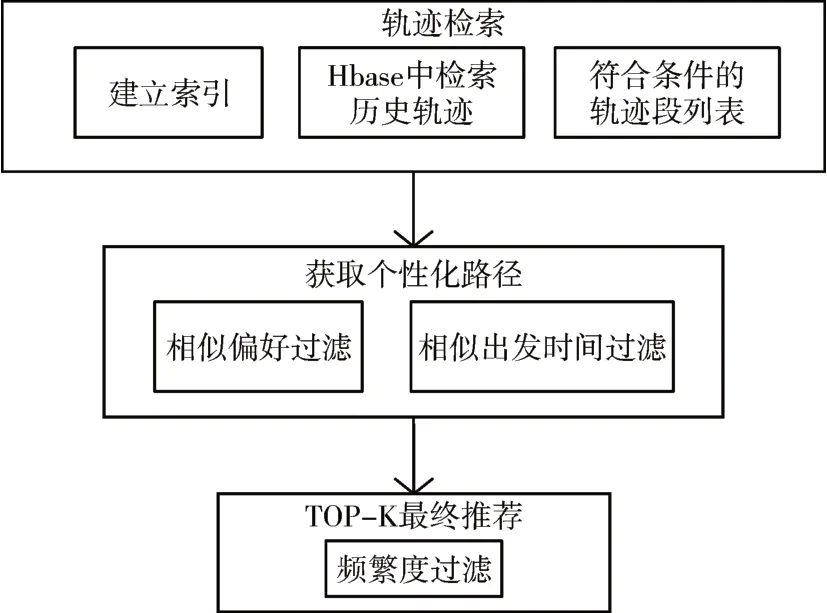
图3 推荐框架图
3.2 轨迹检索模型
3.2.1 数据库结构设计
本文的轨迹数据存储采用HBase[13],首先在轨迹索引速度上,HBase性能远远好于传统数据库,尤其是在数据量很大的情况下,这种优势更加明显,HBase的存储形式是基于列存储,每个列簇由不同文件保存,不同列簇是分开保存的;其次,HBase更适合存储实时更新的数据。为了防止re⁃gion过多的情况,我们将所有车辆每一天的轨迹分段放在一个表中,rowkey使用时间戳+车牌的形式唯一标识轨迹,这种方式方便对轨迹进行快速索引[14]。
3.2.2 轨迹索引算法
轨迹检索只需要找出同起点和终点的轨迹段即可,不需要考虑轨迹整体情况。轨迹索引算法如算法1所示。

给出一组起始和终止位置,我们可以在车辆的历史轨迹中索引出满足条件的轨迹段列表供个性化推荐使用。
3.3 偏好混合分布模型
3.3.1 用户的行驶偏好挖掘
根据用户的偏好进行建模工作时,将路径挖掘[15]出来的特征开销越多,建模工作就越精确。Dai[9]等挖掘出距离、油耗和时间这三个开销进行建模,本文将在此基础上增加转向和红绿灯这两个开销进行进一步建模。
3.3.2 距离开销
整条路经的距离就是两两轨迹点之间的距离和,轨迹点之间距离的计算本文借鉴了最广泛的一种计算方法Haversin[16],其计算方法如式(1)所示。

其中,r是地球半径,φi和φj分别是两点的纬度,λi和λj分别是两点的经度。
3.3.3 转向开销
汽车在笔直的路上行驶会节省油耗,反之如果是一条转弯比较多的路径就会相对耗油。轨迹路段转角计算如图4所示。
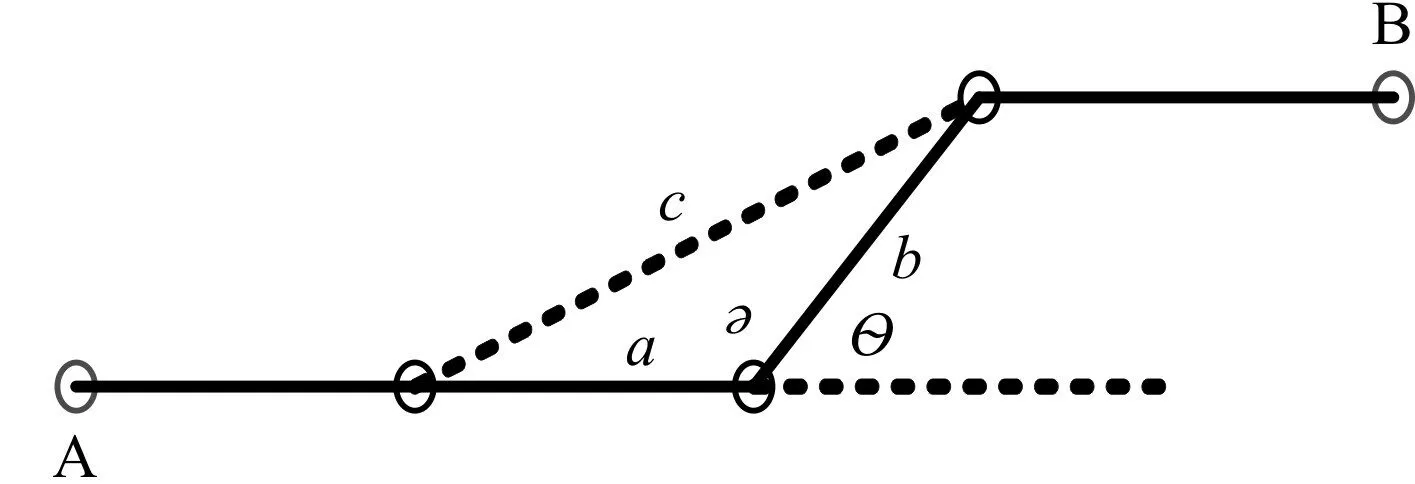
图4 转向示意图
从上图可以看出,A到B的一条轨迹,连续轨迹段在交汇点夹角表示为∂,轨迹的夹角表示为Θ。a,b,c分别为夹角∂的临边和对边,则夹角∂的计算方法如式(2)所示。
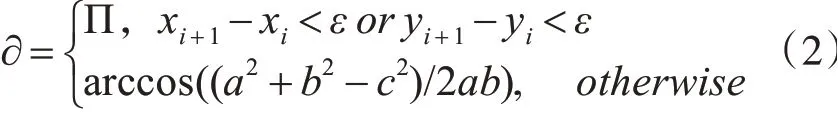
计算出∂后,我们就可以得到转角Θ的度数如式(3)所示。
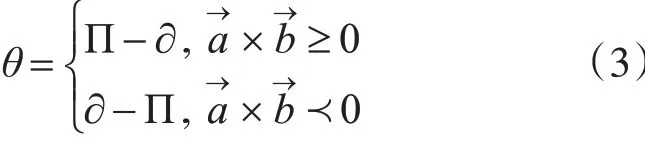
3.3.4 油耗开销
本文计算油耗开销的方法使用SIDRA-Run⁃ning模型[17],其中计算油耗公式如式(4)所示。

其中,Fi是停留时间内的油耗开销,fr为其他时间内的油耗开销,xs为总的行驶路程。
3.3.5 时间开销
一条路径的时间开销就是行驶完整条路经所用的时间,也就是轨迹终点时间减去轨迹开始时间,计算公式如式(5)所示。

3.3.6 信号灯开销
一般车辆在通过交通信号灯的时候总会产生一些消耗,所以一些司机在选择路径的时候将通过交通信号灯的开销也考虑在内。
3.4 偏好建模模型
为了形象地表示用户的偏好,我们采取建模的方式。偏好建模离不开两个定义:偏好率和偏好向量。偏好率就是用户对一条轨迹两个开销的偏好比率,如式(6)所示。

其中ci(T)和cj(T)分别为对于轨迹T的两个开销。
用 户 的 偏 好 向 量P=p1,p2,…,pm,其 中为开销的个数,pi代表偏好比率的分布。对应本文中提及的“距离,转向,油耗,时间,信号灯”这五个开销,得到10个偏好比率,如算法2。

混合高斯分布(Gaussian Mixture Model,GMM)[18],用来表示复杂的分布[19],文中每个偏好向量P中的每个pi都可以用混合高斯分布来表示。根据EM算法求出GMM参数如算法3。

为了计算用户是否有明显的偏好,本文将8000多辆车的轨迹分成两部分,50%作为训练集,50%作为测试集。同时计算出偏好向量,然后进行差异对比。计算差异的公式如式(7)所示。
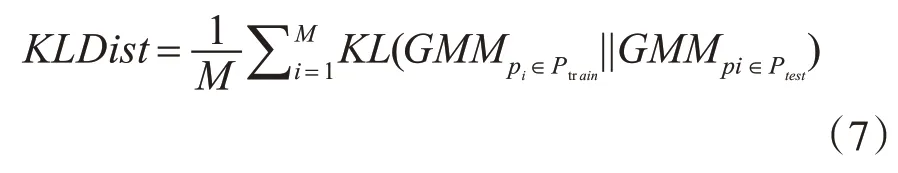
计算出的差异越小,就代表轨迹的特征越明显,个性化推荐就会越有意义。本文对8000多辆车进行差异计算,我们从中抽取差异值小于0.1的5200辆车进行个性化推荐实验。
3.5 获取个性化路径
根据索引出来的轨迹列表,进行个性化路径导航。主要分为两个过滤过程:相似偏好过滤、相似时间过滤和频繁度。
1)相似偏好过滤,用于不同的用户在选择轨迹的时候具有不同的偏好,所以本文选择与用户偏好最为相近的轨迹作为推荐轨迹。计算不同轨迹的偏好相似度用JS散度计算方法,如式(8)。

其中,P1、P2为推荐轨迹和真实轨迹的偏好比率,JS的分布值越小,代表轨迹就越相似,推荐的就越准确。
2)相似时间过滤,基于不同的时间段,路况也会有所不同,所以我们把时间分为每天24个时间段,每个时间段一个小时,推荐轨迹时按照相似时间段优先策略进行推荐最合理。
3)虽然检索出的TOP-K条轨迹都是最符合用户偏好的,但是往往人们越是常走的就越是容易被大家认可的,计算轨迹频繁度[20]的公式如式(9)所示。
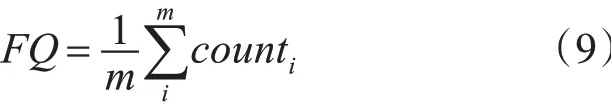
其中,m为组成路径的路段个数,count为路段被经过的次数。从TOP-K中选择频繁度较高的路线作为最终推荐路线。
4 实验结果及分析
4.1 实验目标
1)本文数据存储选择大数据技术,首先通过在轨迹提取速度上证明本文的改进方法具有一定价值。
2)本文的方法根据已有方法改进而来,通过与原有方法进行比对,证明本文的改进方法有效。
4.2 评价指标
1)评价指标1
在不同的时间段对大数据集群的性能进行测试,分别统计磁盘IO性能和集群网络流量走势。
2)评价指标2
对于一段测试轨迹,用户实际走的路线定为R1,个性导航路线定为R2,通过JAC的值来判断两段轨迹的相似性,JAC计算方法如式(10)所示。
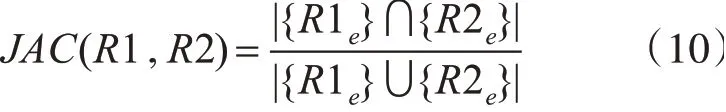
3)评价指标3
本文推荐方法与原有推荐方法准确度比对,通过CR值来进行分析,用户实际走的路线定为R1,个性导航路线定为R2,原有推荐算法推荐路线为R3,若CR值大于1,则默认准确度有提升,计算方法如式(11)所示。

4.3 实验结果及有效性分析
实验所用的数据为全国私家车真实的轨迹数据,将具有偏好的5200辆车的历史轨迹作为训练集,从中选取1000辆车的随机轨迹数据作为验证集,再选取600辆车的随机轨迹数据作为测试集。本文TOP-K中K的选值为5。
1)集群磁盘IO性能走势图如图5所示。

图5 集群性能图
其中浅灰线表示读数据,深灰线表示写数据磁盘、网络等指标均能够基本符合或靠近理论值。从上面两张图可以看出在集群进行读写轨迹数据的时候,磁盘读速度为135MB/s,写速率为40MB/s。按照这样来计算,持续一天不间断的进行导出,总数据量约在7.8T左右;持续一天不间断的进行导入,总数据量约在3.2T。性能远远超过传统数据库。
2)轨迹相似度JAC值对比结果如图6所示。

图6 轨迹相似度对比图
从图中可以看出本文所改进的推荐轨迹与用户时机选择的轨迹更加相近,JAC的值大幅度提高代表着本文的推荐结果更有效。
3)推荐准确度CR值对比结果如图7所示。
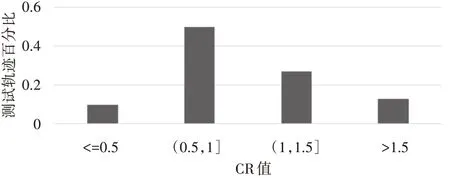
图7 推荐准确度对比图
将本文的推荐方法的准确度与原文的相比,得到的平均值结果为1.102,说明在平均情况下,本文所推荐的路径更能让用户满意,更能符合用户的需求。
5 结语
车辆导航与我们每个人的生活息息相关,它不仅仅可以在你迷路的时候提供一条最佳路线,还可以根据我们的驾驶偏好进行个性化推荐,这也正是本文所研究的意义。本文与之前方法在轨迹相似度和推荐准确度的对比上都有明显的提高,相似度80%以上的轨迹提高了近一倍,推荐准确度的平均值也稳定在1以上,同时也保证了轨迹提取的实时性,这说明本文的方法具有一定的价值。
在接下来的工作中,我将着重在数据挖掘上进行研究,本文所涉及到的用户偏好还很局限,这就需要更多的轨迹挖掘来发现更多的轨迹特征,这些轨迹特征可以帮助我们更好地对用户的偏好进行建模,找到与用户行驶习惯更相近的路线。同时,要想在功能上对导航进行完善,行驶时间的预测也是很重要的功能,在本文研究的基础上对行驶路线所花费时间的预测也是日后工作的内容,由于不同的时间会有不同的路况,再加上天气的影响,行驶时间的预测也将面临巨大的挑战。在未来的车辆导航发展中,个性化路径推荐将占有越来越重要的的地位,随时间的推移,越来越多轨迹的出现也会帮助我们提取到越来越多的用户特征,但同时也对轨迹的处理和存储造成巨大的挑战。但我相信,我们一定会逐渐优化算法,提高性能,从而推荐出准确率更高的个性化路线。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
成都信息工程大学学报(2021年5期)2021-12-30
天津外国语大学学报(2021年1期)2021-03-29
小哥白尼(神奇星球)(2021年12期)2021-03-08
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
读友·少年文学(清雅版)(2020年4期)2020-08-24
读友·少年文学(清雅版)(2020年3期)2020-07-24
初中生世界·九年级(2020年2期)2020-04-10
小猕猴智力画刊(2018年3期)2018-06-12
小学生导刊(低年级)(2016年8期)2016-09-24
