
基于Actor-Critic帧间预定位的改进SiamRPN模型*
2021-12-01 14:13陆建峰
计算机与数字工程 2021年11期
韩 慧 陆建峰
(南京理工大学 南京 210094)
1 引言
目标跟踪是计算机视觉领域的重要研究方向之一,在雷达制导、航空航天、医疗诊断、智能机器人、人工智能、自动控制等多领域都有广泛的应用[1]。目标跟踪,简而言之,其目的是在视频的每一帧中寻找到运动目标物体,并用一个紧紧包含该目标物体的边界框将其“追踪”出来。近几十年来,尽管视觉跟踪算法已经取得诸多进展,但有些阻碍视觉跟踪的问题依然存在,例如:运动模糊、外观变化、遮挡、光照变化和背景混杂等[2]。
近些年来,深度神经网络的发展为视觉跟踪领域带来丰富的特征表示,基于卷积神经网络CNN的目标跟踪方法更具鲁棒性的同时也提升了性能。目前两种主流的基于深度学习的目标跟踪算法发展方向主要是以轻量级网络架构MDNet[3]和孪生网络架构SiamFC[4]为代表。
2015年,Nam等提出一种CNN架构的检测跟踪算法MDNet[3],该算法采用浅层的VGG-M网络[5],直接利用多域学习的网络结构,将每一个视频视为一个单独的域,从多个标注的视频序列中预训练VGG-M网络,学习目标的共性特征表示能力,对前一帧目标邻域采样样本进行分类,并引入目标检测领域中的边界框回归[6]对分类得分最高的样本框修正。该算法速度为1fps,除了完全被遮挡时会有跟踪失败的情况,精度和鲁棒性都很好。在跟踪视频数据集,例如VOT2014[7]和OTB2015[2]上训练CNN,取得了比传统追踪器更好的结果。
随着深度强化学习在游戏、机器人、自然语言处理和智能驾驶等诸多领域更加广泛的应用推广,目标跟踪领域也在近几年开始出现基于深度强化学习的目标跟踪方法。2017年,Yun等[8~9]提出顺序性跟踪动作控制的目标跟踪算法ADNet,该方法参考MDNet使用VGG-M网络,利用深度强化学习方法学习目标框偏移动作,从而多次迭代出最佳目标框。与当下使用深度网络的跟踪器相比,这是第一次尝试通过追踪深度强化学习训练出的动作来控制跟踪策略。2018年,Chen Boyu等[10]提出了基于“Actor-Critic”架构的实时追踪器ACT,Actor模型旨在一个连续动作空间里推测最佳选择动作,让跟踪器直接在当前帧把边界框移动到目标位置;线下训练时,Critic模型输出一个Q值来引导Actor和Critic深度网络的学习过程,在线跟踪时,作者采用MDNet作为Critic验证模块使得跟踪器更加鲁棒。ACT作为第一个使用连续动作空间和Actor-Critic框架的目标跟踪算法,实时跟踪算法的跟踪速度达到了30fps。
MDNet系列算法关注学习目标表观特征,并需要在目标外观发生变化时更新模型,然而,SiamFC系列将目标跟踪问题视为当前帧的搜索区域与模板分支目标相似性度量问题。2016年,Luca等提出SiamFC[4],利用在大规模目标检测视频集ILS⁃VRC2015[11]上进行端到端训练的全卷积孪生网络在搜索区域计算模板目标响应最强烈的位置进行定位,由于无需在线更新模型,该算法速度达到了58fps,对目标跟踪方法的发展产生了深远的影响。2017年,Jack等提出CFNet[12],结合相关滤波器和SiamFC进行端到端跟踪,相关滤波的引入使得模型使用较浅层的神经网络就可以达到较好的效果。2018年,Li等提出了SiamRPN[13]算法,利用孪生子网络对搜索区域和模板目标进行特征提取,借鉴目标检测领域的区域候选网络RPN[14],对目标前景和背景进行分类和边界框回归。由于可以预先计算模板分支子网络提取第一帧目标特征并生成网络的相关卷积层进行在线跟踪,且RPN修正候选框可以避免传统算法对目标框的多尺度测试和在线微调过程,SiamRPN在保持高准确率和成功率的同时,跟踪速度达到了惊人的160fps。
搜索区域通常与上一帧的目标框大小有关,常用的策略是2倍策略,如ACT[10],即裁剪区域以目标框的中心为裁剪中心,区域边长为目标框边长的2倍。致力于长期跟踪的MBMD[15]算法为了保证更大的搜索区域可以找到目标,采用了4倍策略,即区域边长为目标框边长的4倍。SiamRPN模型其当前帧的搜索区域基于上一帧目标框的大小进行裁剪并调整至模型输入固定尺寸,裁剪公式如下:
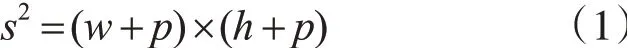
其中,s为裁剪区域边长,w和h分别代表上一帧目标框的宽和高,p是填充间距,p=(w+h)/2。裁剪区域近似于2倍策略大小。
由于SiamRPN模型搜索目标区域面积较小,模型有丢失目标的风险,为了提高跟踪准确率和成功率,本文提出了一种扩大搜索区域的基于Ac⁃tor-Critic帧间预定位的改进SiamRPN模型ACSia⁃mRPN。由于SiamRPN模型仅利用第一帧模板和当前帧的相似性度量结果进行目标跟踪,并未关注相邻帧之间目标的运动信息,ACSiamRPN融合前后帧的帧间目标运动信息,扩大搜索区域为4倍目标边长,借鉴ACT算法利用Actor-Critic方法训练预定位网络,在更大的搜索区域单步计算目标位移,利用较大的搜索区域和预定位方法来改进Sia⁃mRPN模型,本文的创新性如下:
1)提出了一种融合帧间目标运动信息来进行预定位的方法,实验证明该方法能有效地利用帧间目标运动信息在更大的搜索范围里对目标进行预定位。
2)提出了改进的SiamRPN模型ACSiamRPN,结合帧间目标运动信息来预定位目标,后续Siam⁃RPN模型跟踪目标的准确性和成功率有所提高。实验证明本文提出的改进SiamRPN模型ACSiam⁃RPN的跟踪准确率和成功率均超越了SiamRPN,运行速度达到65fps,仍然保持良好的实时性能,与当今较为先进的一些跟踪方法相比具有明显优势。
2 基于Actor-Critic帧间预定位方法
2.1 帧间预定位模型框架
为了保证更大的搜索区域可以找到目标,本文参考长期跟踪的MBMD[15]算法,采用4倍策略。帧间预定位模型Actor-Critic架构示意图如图1所示,a代表Actor,c代表Critic。

图1 帧间预定位模型Actor-Critic架构示意图
采用VGG-M网络作为Actor和Critic的主干网络,其中Actor网络用于决策一个连续的偏移动作,可以直接将边界框移动到当前帧中的目标位置;Critic网络输出Q值用来引导Actor-Critic网络的训练学习过程。利用预训练好的VGG-M的前三层卷积层初始化Actor和Critic网络,Actor网络后两层全连接层的输出拼接后经历最后一层全连接层输出一个三维的动作向量,Critic网络最后一层全连接层需要上一层拼接三维的动作向量,从而获得对当前状态的动作评估Q值。在测试阶段,仅保留Actor网络作为预定位网络使用。
2.2 强化学习问题设定
本文将帧间目标预定位问题视为一个序列性决策问题,服从马尔科夫决策过程MDP。MDP的四个要素是:状态s∈S,动作a∈A,状态转移方程s′=f(s,a),奖赏函数r(s,a)。在本文的MDP框架中,帧间预定位跟踪器通过一系列的观测状态(s1,s2,…,st)、动作(a1,a2,…,at)以及奖赏(r1,r2,……,rt)与环境进行交互,在第t帧,智能体根据当前状态st给出连续性动作at,获得目标预定位结果作为新状态s′t。本文将第t帧目标框与前一帧目标框的相对位移定义为动作at,详细的状态s、动作a、状态转移方程f(s,a)、奖赏r的设置如下所示。
2.2.1 状态
本文定义边界框b=[x,y,w,h]包围的图像块作为状态s,其中(x,y)为边界框中心坐标,w,h分别为宽和高。定义预处理函数为在给定帧F中裁剪边界框b相关区域并缩放成网络所需固定尺寸的函数,预处理后的结果也即为当前状态s,见式(2)。

2.2.2 动作和状态转移
本文定义动作空间是连续的,动作a=[Δx,Δy,Δs]为目标从上一帧运动到当前帧位置的相对运动,其中Δx,Δy分别为目标中心点在水平和竖直方向上的相对位移,Δs为边界框的尺度变化。依据跟踪问题的帧间差分连续性[10],限制动作a的范 围 为:Δx∈[-1,1],Δy∈[-1,1],Δs∈[-0.05,0.05]。目标框b经过动作a偏移后的目标框b′=[x′,y′,w′,h′],如式(3)所示。随后,状态转移方程s′=f(s,a)即可依据偏移后的目标框b′和预处理函数∅(b′,F)实现。
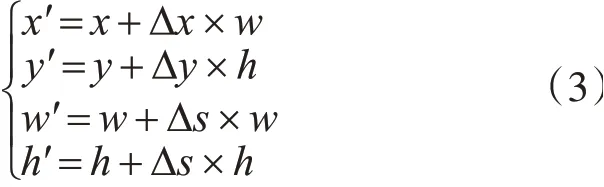
本文可依据当前状态s通过Actor网络直接推断获得最优动作a,如式(4),其中,μ(.)代表参数为θμ的神经网络Actor,可通过ACT中的改进DDPG[10]策略线下训练得到。

2.2.3 奖赏
奖赏函数r(s,a)表明了从状态s采取动作a变成新状态s′时预定位的准确性,本文依据新边界框b′和真实值G的交并比IoU来定义奖赏函数,如式(5)所示,其中IoU的定义如式(6)所示。每次采取动作都会产生相应的奖赏,随后奖赏会被用来训练更新神经网络。
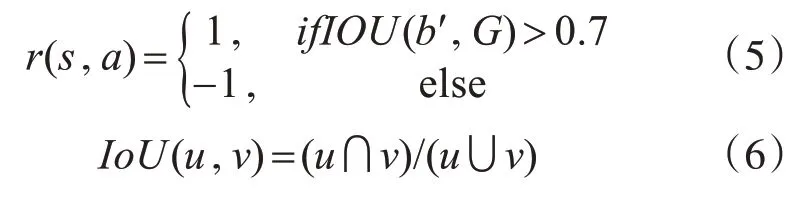
3 改进SiamRPN模型ACSiamRPN
3.1 模型结构
ACSiamRPN模型框架融合前一帧和当前帧目标的帧间目标运动信息,扩大搜索区域为4倍目标边长,借鉴ACT算法利用Actor-Critic方法训练预定位网络,在更大的搜索区域单步计算目标位移,校正SiamRPN模型搜索区域中心,随后SiamRPN部分利用孪生网络分支对模板和搜索区域提取特征,RPN在相关性特征图上进行候选框的分类和回归,最终获得当前帧的目标框。ACSiamRPN模型框架如图2所示。

图2 基于Actor-Critic帧间预定位的改进SiamRPN模型ACSiamRPN示意图
3.2 模型线下训练
3.2.1 训练Actor-Critic帧间预定位网络方法
本文的Actor-Critic帧间预定位网络依据ACT改进的DDPG方法[10]来训练,即在正式采用传统DPPG训练之前,利用第一帧的监督信息来初始化帧间预定位网络Actor网络从而适应当前环境,针对Actor网络采取L2损失函数优化帧间预定位动作决策,如式(7)所示。其中,M为训练样本数,μ(.|θμ)代表参数为θμ的神经网络Actor,sm为第m个采样状态,am为相应的真实标签动作向量。
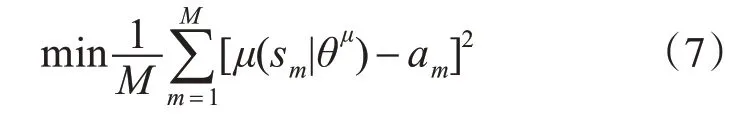
给定N对样本(si,ai,ri,s′i),Critic模型Q(s,a)可以依据Q-learning中的贝尔曼方程来学习,借助Actor目标网络μ′和Critic目标网络Q′,最小化累积差分误差(即损失函数),如式(8)所示。
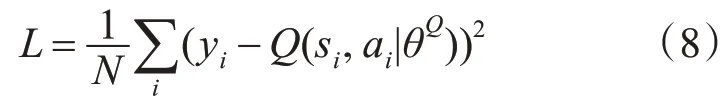
随后,利用微分链式法则针对累积期望奖赏J对Actor模型参数求导,如式(9)所示,即可优化更新Actor模型参数。

线下训练帧间预定位网络时,从ImagetNet视频[11]训练集中选取768个视频序列,每次迭代时随机从一段视频里面选取20~40帧图像,利用第一张图像初始化帧间预定位网络Actor时,选取32个与目标框真实值的IoU大于0.7的正样本,这些正样本服从以目标框真实值为中心的正态分布,协方差为对角矩阵diag(0.09d2,0.09d2,0.25),其中d为跟踪目标框宽和高的均值。随后,应用Actor网络和Critic网络在第t帧获得训练数据样本对(st,at,rt,s′t)。初始化阶段的学习率设置为1e-4,学习阶段Actor网络和Critic网络的学习率分别设置为1e-6和1e-5,此外使用一个104大小的记忆回放缓存。整体训练迭代次数为240000次。
此外,在传统的DDPG算法基础上采用一定概率为ε的专家决策(即真实动作值)取代Actor网络的结果来引导训练学习过程,概率ε初始值设置为0.5,每迭代10000次减少5%,与此同时更新Actor目标网络μ′和Critic目标网络Q′的网络参数θμ′和θQ′,如式(10)所示,其中参数τ设置为0.001。
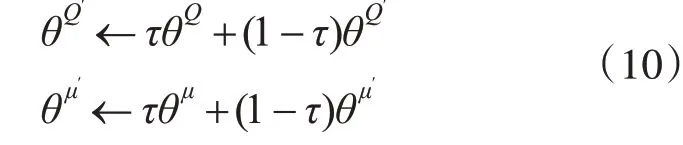
3.2.2 训练SiamRPN模型方法
本文的SiamRPN模型训练方法参考原文[13]。训练数据来源于ILSVRC2015大规模视频图像数据集[11],选取同一个视频序列的第一帧和随机间隔帧组成一个数据对。RPN的回归分支损失函数Lreg针对回归的归一化坐标,定义锚框的中心点坐标和尺寸为:Ax,Ay,Aw,Ah,定义对应的目标框真实值为:Tx,Ty,Tw,Th,归一化距离如式(11)所示;Lreg参考Faster R-CNN[14]采用smoothL1损失,Lreg见式(12)。
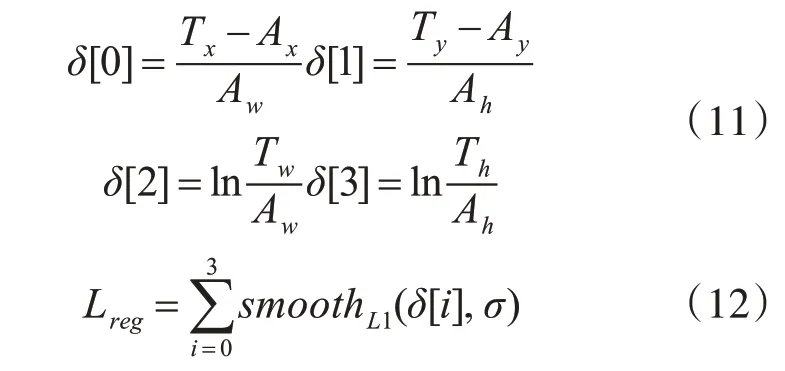
分类分支的损失函数Lcls为交叉熵损失函数,联合训练两个分支的总体损失函数loss见式(13),其中λ为平衡两个分支的超参数。
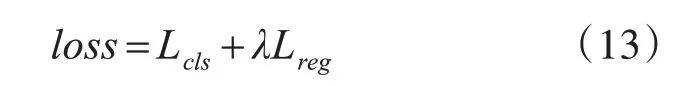
4 实验结果及分析
为了验证本文提出的基于Actor-Critic帧间预定位的改进SiamRPN模型的效果,实验环境为Ubuntu 16.04系统,采用TITAN Xp 12GB显卡加速训练和测试,其中Actor-Critic帧间预定位模型训练采用TensorFlow框架训练,SiamRPN模型和AC⁃SiamRPN模型均采用Pytorch框架训练和测试。实验所用的训练数据集为ILSVRC2015大规模视频图 像 数 据 集[11],测 试 数 据 集 为OTB2013[16]、OTB2015[2]、DTB70[17]、NFS30[18]以及VOT2016[19]。
4.1 评价指标
4.1.1 常用指标
大多数目标跟踪数据集,如OTB2013、OTB2015、DTB70和NFS30,主要采用精确率(Preci⁃sion Rate,简称P)和成功率(Success Rate,S)来评价跟踪器的效果,利用帧率(Frames Per Second,fps)来衡量跟踪算法的实时性能。
4.1.2 VOT2016指标
本文采用的VOT2016主要采用准确率(Accu⁃racy,A)和鲁棒性(Robustness,R)来评价跟踪器的效果,利用帧率fps来衡量跟踪算法的实时性能。
4.2 实验结果与分析
在OTB2013和OTB2015数据集上,本文选取了SiamRPN[13]、ACT[10]、ECO-HC[20]、SiamFC-Tri[4]、SiamFc_3s[4]、CFNet[12]等较为先进的跟踪算法和本文提出的ACSiamRPN作对比试验,准确性图和成功率图如图3所示,图例所示的数值为曲线所对应的AUC(Area under curve)值,反映了跟踪器在数据集上的平均精确率和平均成功率,其中主要采用平均成功率来对跟踪器进行排名。因此可见:1)AC⁃SiamRPN在OTB2013和OTB2015上的平均精确率和平均成功率均超越了SiamRPN。2)ACSiamRPN在OTB2013上以0.657的平均成功率超越了所有的对比对象,在OTB2015上以0.642的平均成功率超越了几乎所有对比对象,仅次于ECO-HC。
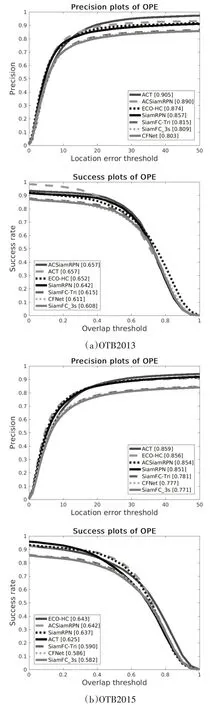
图3 OTB2013和OTB2015数据集ACSiamRPN对比试验图
在DTB70、NFS30和VOT2016数据集上,本文主要选取SiamRPN算法做对比实验,从而比较AC⁃SiamRPN作为改进SiamRPN模型与原始SiamRPN模型的跟踪效果,如表1所示。在DTB70和NFS30上,ACSiamRPN的精确率和成功率均高于Siam⁃RPN,在VOT2016上,ACSiamRPN的准确率超越了SiamRPN,但是鲁棒性稍逊于SiamRPN。

表1 ACSiamRPN和SiamRPN在DTB70、NFS30、VOT2016上的实验结果
由OTB2013、OTB2015、DTB70、NFS30以 及VOT2016数据集上的对比实验结果可知,本文提出的ACSiamRPN模型作为SiamRPN的改进模型,对于SiamRPN跟踪效果的提升较为明显,从精确性到成功率均取得了良好的改进结果,与此同时,和其他当今较为先进的跟踪模型相比,ACSiamRPN模型依然具有明显的优势。
在实时性能方面,SiamRPN由于是端到端的一步跟踪,在OTB2013数据集上达到了100fps的速度,ACSiamRPN由于采用更大的搜索区域且增加了帧间预定位模型来校正SiamRPN搜索区域的中心,这种两步跟踪的方法降低了SiamRPN原有的跟踪速度,但是由于帧间预定位模型采用了轻量级网络VGG-M,在OTB2013上的跟踪速度依然可以达到65fps,在提高模型跟踪效果的同时依然保持了较好的实时性能。
5 结语
本文提出了一种基于Actor-Critic帧间预定位的改进SiamRPN模型ACSiamRPN。该方法融合前后帧的帧间目标运动信息,扩大搜索区域为4倍目标边长,利用Actor-Critic方法训练预定位网络,在更大的搜索区域单步计算目标位移,从而校正Sia⁃mRPN模型搜索区域中心。实验证明该方法能有效地利用帧间目标运动信息在更大的搜索范围里对目标进行预定位,并且可以改进和提升原始Sia⁃mRPN模型的准确性和成功率,与此同时运行速度达到65fps,仍然保持良好的实时性能,与当今较为先进的一些跟踪方法相比具有明显优势。
猜你喜欢
天天爱科学(2022年9期)2022-09-15
当代水产(2022年6期)2022-06-29
太阳能(2022年3期)2022-03-29
发明与创新·小学生(2021年3期)2021-03-25
水上消防(2020年4期)2021-01-04
软件(2020年3期)2020-04-20
环境(2019年10期)2019-10-24
当代工人·精品C(2019年2期)2019-05-10
北京教育·普教版(2017年1期)2017-02-05
海峡姐妹(2015年5期)2015-02-27
