
基于Hadoop平台的结算数据切片方法及实现
2021-11-30 09:36:58梁伟晟
现代计算机 2021年29期
梁伟晟
(中国移动通信集团广东有限公司,广州510623)
0 引言
渠道费用结算系统实现对社会渠道费用的计算。系统定期从外围系统(CRM系统、计费账务系统、BI、ESOP、物联网IOT、和商汇等)采集业务办理及状态数据,对采集的数据进行预处理,包括数据清洗、数据转换等操作,然后根据结算规则对预处理完成的数据进行费用计算,生成费用结算报表。Hadoop是用于海量数据存储和计算的分布式系统基础架构。Hadoop具有可扩展、可伸缩等特性,适用于海量业务数据预处理和计算。渠道费用结算系统引入Hadoop框架,充分利用Hadoop的分布式存储和计算能力,实现弹性伸缩,提高数据预处理的性能。在预处理过程中,由于海量数据以离散数据表的形式流转,依赖于平台数据处理性能,对资源消耗较大,影响预处理效率。为此,采用一种结算数据切片处理技术将无状态的离散数据按照一定数据特征规则进行结构化解析处理,以提高数据运算的效率。
1 系统设计
渠道费用结算系统基于Hadoop平台采集数据源,并做初步过滤预处理,再将初步预处理的数据按照结算规则生成计算所需的结构化数据。

图1 数据预处理
在预处理过程中,大量的数据是以离散数据表的形式被处理,没有根据数据特征归类处理,对资源消耗较大,处理性能依赖于平台处理能力。同时也无法进行动态扩展集群化数据处理,可能导致负载不均衡。
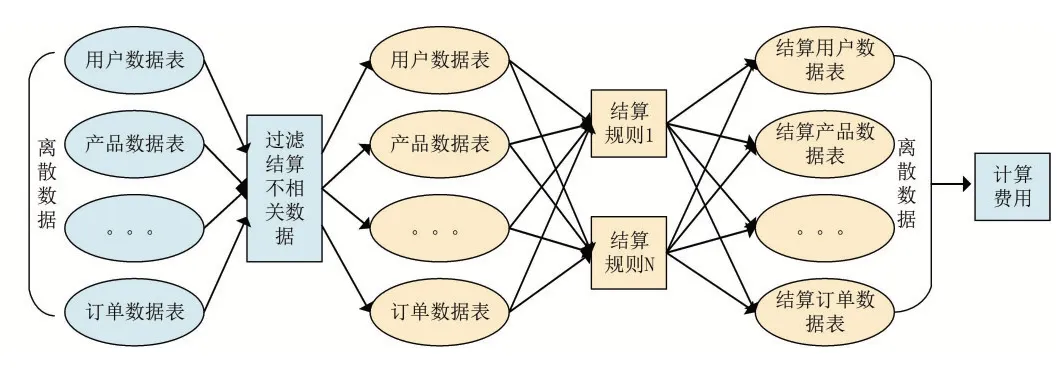
图2 离散数据流转
为解决处理性能和负载均衡问题,采用一种将结算数据切片处理的方法将无状态的离散数据按照一定数据特征规则进行结构化解析处理,将数据分割至各个redis内存数据库进行计算,提高数据运算的效率,实现资源负载的均衡。
1.1 功能流程图
(1)源数据采集。通过Hadoop平台采集用户订单、产品、计费等信息。
(2)数据归类处理。针对采集的数据按照业务数据对象特征进行归类,归类后得到结构化的数据用于切片。
(3)数据切片。提供数据切片模型设置,根据数据对象归类信息进行数据分割,将数据均衡分类分割至redis预处理逻辑集群。
(4)数据处理集群。数据逻辑处理单元,集群可根据数据切片模型切片结果并行处理以及集群数量自动伸缩。
1.2 数据切片方法
(1)数据归类。费用结算涉及的业务数据主要以用户资料、产品数据、订单数据为主。数据归类模块提供通用配置能力,将结算政策码以及所需的数据对象进行配置。根据配置信息,业务数据以结算政策码为特征进行聚合归类,生成包含结算政策码、用户资料、产品数据、订单数据等信息的数据对象,得到结构化的数据(U1,U2,U3,U4…Ut)T。对结构化的数据打上标签Y,封装形成n个切片标签(U1,U2,U3,U4…Ut|Y)T。
(2)业务数据切片。依照结构化数据的数据记录数维度,对结构化数据进行排序,并标记切片标签(U)的边缘切片标签,即标签最大值和最小值(Ymax,Ymin)。按照切片标签值Y进行分类得到切片数据:
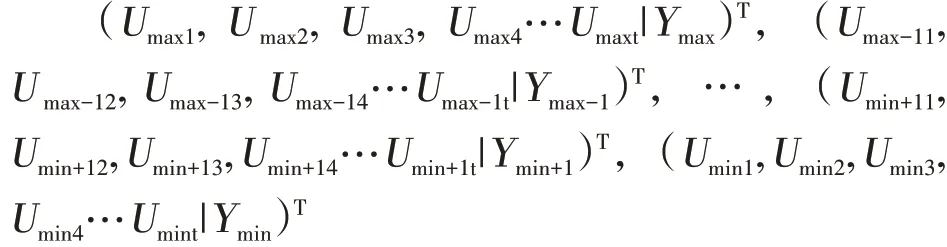
(3)切片数据队列生成。以切片标签匹配所有业务数据,按照redis节点数量m和切片标签数量n进行数据拼接,然后通过边缘标签最大值(Ymax)和最小值(Ymin)作为一组队列进行切分,总计可得到个队列。具体如下:
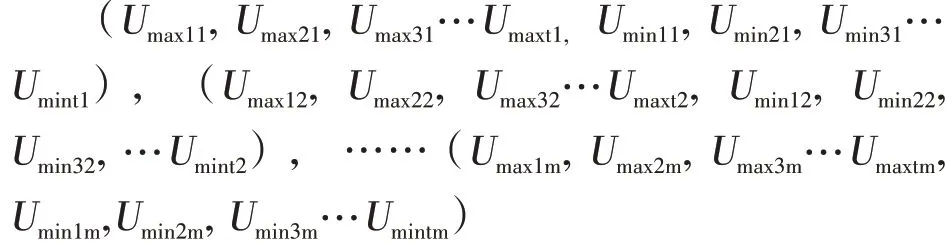
将分割好的数据量均衡的队列根据redis实时负载情况分配至各redis节点进行业务逻辑处理。每一个的结算数据对象经过切片可分配至单独的业务逻辑处理单元集群。
1.3 实施效果
通过在预J处理过程中将结算数据切片处理,所有离散数据与渠道费用政策在预处理阶段就关联起来,生成结构化对象数据。同时通过对数据对象进行切片,实现数据的集群化处理,有效利用集群自动弹性伸缩。通过此方案的实施,渠道费用结算数据预处理效率提升87%以上。
2 结语
本文给出了基于Hadoop框架的结算数据切片方法和实现,以此解决海量离散数据的预处理对资源消耗较大,影响了预处理效率。在Hadoop处理大数据优势的基础上,将源数据采集得到的离散数据结构化,通过数据切片方案适配具备一定关联性的离散数据,数据分割切片后再分配到redis集群化均衡负载处理。实际系统建设表明,经过改造后,数据预处理效率得到较大提升。
猜你喜欢
中学生数理化·中考版(2021年10期)2021-11-22 07:26:40
河北理科教学研究(2021年4期)2021-04-19 13:34:44
计算机教育(2020年5期)2020-07-24 08:53:00
疯狂英语·新读写(2018年2期)2018-11-29 17:59:24
中学生数理化·七年级数学人教版(2017年12期)2017-04-18 11:22:16
电信科学(2016年11期)2016-11-23 05:07:58
中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40
计算机工程(2015年8期)2015-07-03 12:20:35
中国当代医药(2015年17期)2015-03-01 02:03:38
华东理工大学学报(自然科学版)(2014年5期)2014-02-27 13:49:32
