
基于Boosting集成学习算法的网络入侵检测技术研究
2021-11-30 09:33易琳王欣
现代计算机 2021年29期
易琳,王欣
(中国民用航空飞行学院计算机学院,广汉618307)
0 引言
由于人们对于网络接触的愈来愈多,如何保证网络中的安全成为人民关注的重点。现在网络入侵检测的相关技术已经逐渐成为在网络安全的第一防线和重要手段。网络入侵的技术越来愈多,针对网络入侵相关检测技术要求以及标准也在不断提升。对于网络入侵检测技术而言,其首要任务便是将入侵检测逐渐转变成为分类问题以及模式识别两个部分来进行处理。利用机器学习技术将网络流量的特征行为划分为正常流量和异常流量进行数据采集、预处理、建模和分类。现阶段,针对网络入侵相关检测技术主要通过机器学习来完成,同时深度学习在检测网络入侵中的应用在不断提升。当前,国内外关于此方面的研究大多处于基础理论研究状态,同时在体现结构以及相关技术方面获得了一定成果。
机器学习中很多相关算法被广泛用于网络入侵检测,常见的入侵检测算法有很多,如KNN(K-nearest neighbor)。多种机器学习的算法结合的网络入侵检测方法可以适用于复杂的系统。文献[1]创造性地提出了网络入侵检测相关模型;文献[2]-[3]通过聚类的方法对流量进行分析;文献[4]提出了通过蚁群算法旋转神经网络参数进而针对网络入侵进行检测的方法;文献[5]主要通过自动编码器来进行网络入侵检测;文献[6]提出一种以机器学习为基础的网络端口扫描检测技术;文献[7]借助卷积神经网络来展开入侵检测,进而针对日志信息特征以及灰度图进行提取,借助spark来针对日志信息进行处理,进而借助不断迭代的方式来产生相应新特征,通过卷积来达到降噪目的;文献[8]提出了以人工神经网络作为基础的网络入侵检测系统,降低了传统方法的误报率高的问题。
现阶段,通过决策树以及SVM等经典机器学习算法来处理海量数据以及高纬度数据,存在攻击率检测结果普遍偏低以及误报率高等问题。而Boosting在处理大量数据时泛用性较好,可以有效的保证分类正确,提高检测的精度。本文选择Boosting算法对入侵进行检测和识别,同时采用Boosting来针对样本进行训练Boosting算法训练时间短,参数调整有独特的优势。进而将正则项添加到迭代函数里面,并且将其用于模型复杂度的控制当中。笔者首先介绍Boosting算法,进而以此算法为基础,协同kdd99数据集来针对入侵检测模型进行构建,最终达到特征工程以及数据预处理的目的。为了对Boosting的模型进行提升,使用热编码与随机森林选择特征相结合,实现参数的优化与特征的提取。最终实验表明,和随机森林算法进行相关比较,Boosting模型在分类正确率方面有明显优势,大大提升了网络入侵的检测效果。
1 Boosting模型
Boosting算法是集成学习算法的一种,多个弱学习器相互组成Boosting算法,通过多个弱学习器的结果来进行结果预测,进而获取相应的投票结果。在进行训练过程中,针对各弱学习器予以训练,核心要点便是关注错分样本。Xgboost、AdaBoost以及GBDT为Boosting相关的三大注意算法类型。
1.1 AdaBoost
Adaboost将处理属于同一的训练集,此算法会应用到多种不同的弱分类器,然后将许多弱学习器,进行相对的组合,以便组合成为强学习器。根据每次训练的结果,调整样本的权值,将得到的新权值使用与后面的训练器进行训练,然后每次新增一个弱分类器,直至最终获得最小错误率以及预先制定的相应最大迭代次数。
在Adaboost算法模型上,大体上分为3个步骤:
(1)对于各训练样本给予相同比例权重值。

(2)经过多轮迭代以后,然后利用权重分布Dm对数据集进行有针对性的学习,然后训练,之后获得基本分类器,m代表迭代了多少轮。

计算Gm(x)的误差率:
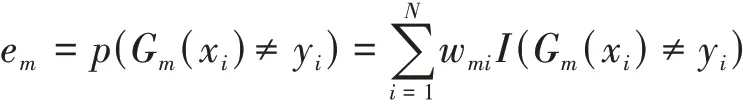
针对Gm(x)的系数进行计算,am代表的是在最终分类器里面Gm(x)相应的重要程度:

对于权值分布进行更新,在之后的迭代进行使用。
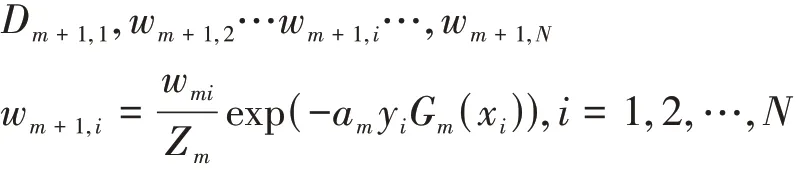
Zt是规范化因子:

(3)组合各类弱分类器:
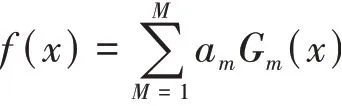
进而得到最终分类器:

1.2 GBDT
作为一种以迭代叠加为基础的决策树算法,GBDT主要是将多个不同弱学习器予以组合,并且对应的预测结果当作是最终预测结果。GBDT算法模型具体步骤包含如下:
输入训练集{(x1,y1),(x2,y2),…,(xn,yn)},损失函数为L(y,f(x)),迭代m轮,m为迭代次数。
计算m轮的i个样本残差:

针对各节点相应最小损失函数进行计算,进而得到最佳的输出值:
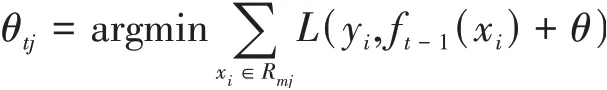
Rmj代表是第m棵树所对应的一个叶子节点区域,j代表的也就是叶子节点数所对应的个数,θ代表的也就是初始常数,则本轮最终的算法模型::

1.3 Xgboost
Xgboost即 指 的 是eXtreme gradient boosting,此算法属于梯度提升算法经过优化改进以后的算法。针对Xgboost对应预测模型可以通过如下式子来进行表示。
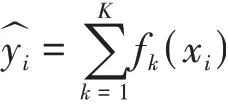
上述式子中K代表的是树对应总个数,fk代表的是第k颗树,yi代表的是样本xi对应预测结果。
Xgboost代表的是实现了运算速度以及模型表现得平衡算法,在模型当中引入了复杂度,进而针对算法效率进行衡量,以此来防止模型过拟合。关于Xgboost目标函数可以表示成为模型复杂度+传统损失函数。
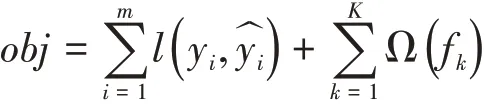
上述式子里面i代表的是一个数据集合里面所对应得某个样本i,m代表的是某个k棵树所对应的数据总量大小,k代表的是所有k棵树对应的数目,上述式子里面每一项都是代表损失函数,体现了损失函数是预测值和真实标签之间所共同存在的差异。一般情况下,指的是经过调节以后对应得均方误差rmse。第二项所要代表的是一个模型对应的数据复杂度,借助于该树在模型中采取相应变换方式来对其进行表示:

其中γ和λ为人工设置的参数,T为叶子总数,w代表的是叶子节点对应分值为w的L2模平方。
2 基于Boosting集成学习算法的网络入侵检测
Boosting集成算法,将多个弱学习算法结合,训练出精度较高的强学习算法。本文使用KDD99中10%kddcup.data_10_percent作为训练数据集。如今,网络入侵检测应用最为普遍的数据集为KDD99,在此数据集里面保证的特征数为44个,大体上包含五个标签大类,即probe、nomal、u21、dos以及r2l。具体分类如表1所示。

表1 kdd99特征值
在数据集上运用交叉验证,并用交叉验证得到的平均准确率,平均召回比例作为模型中最终评价的指标[8]文中将常见的Boosting集成算法用于网络入侵检测,首先对KDD99进行预处理,尝试针对特征“service”予以合并,并且稀疏特征,结果发现redi、ntpu、urhi以及urhi相对应标签均属于normal,故而能够将上述四个标签予以合并。通过One-hot编码来针对离散型特征予以处理:在针对离散型特征予以数字化处理的过程中,此时的算法方能够进行处理,如若某个特征包含三种值,即蓝、红和绿,假如编码是“0”、“1”以及“2”,则“0”和“1”之间对应距离则是1,而“0”和“2”之间对应距离则是2,存在大小关系,然而对于原属性值红绿蓝而言,则不存在大小区分。通过随机森林来针对特征值进行提取,借助Xgboost、Adaboost以及GBDT算法来针对训练数据集,然后用测试集进行预测,具体流程如图1所示。
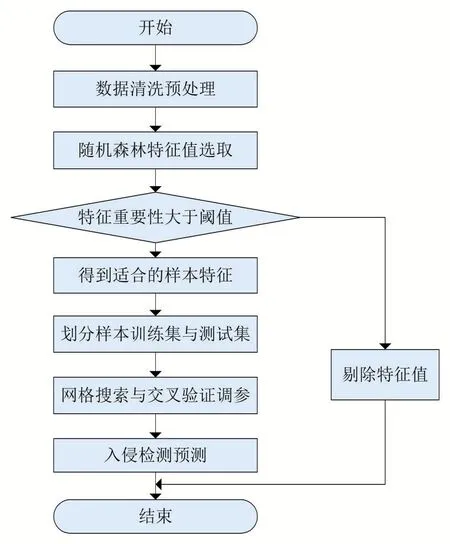
图1 基于boosting的入侵检测模型
3 实验及结果分析
本文选用召回率与准确率作为评价入侵检测模型的指标,从不同的角度对基于Boosting集成学习算法的入侵检测模型进行评估,评价指标的计算公式如下:
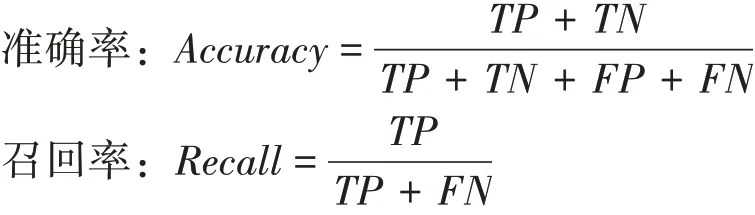
公式中的TP表示预测结果和实际结果同时攻击的样本数。TN代表预测结果和实际结果都死正常的样本个数,FP指的是将原本属于正常类型识别成为攻击型样本数,FN指的是将原本属于攻击型识别成为正常样本对应个数。
借助GBDT、Xgboost以及Adaboost来处理经过KD999数据集处理过后的数据,进而构建模型。具体方法步骤参见如下:
(1)采取5折交叉验证的方式处理试验数据。并且将获得数据划分成为数量相同且不重复的五个部分,经过分割以后对于各数据样本均包含五个不同类别。
(2)借助四份数据来针对分类器构建模型,剩余1份数据则用于验证召回率以及准确率。针对四种不同分类器构建模型分析,重复五次。
(3)选取5次建模结果平均值,进而获得对应评价指标。
上述4种分类器对应分类准确率参见表2内容。
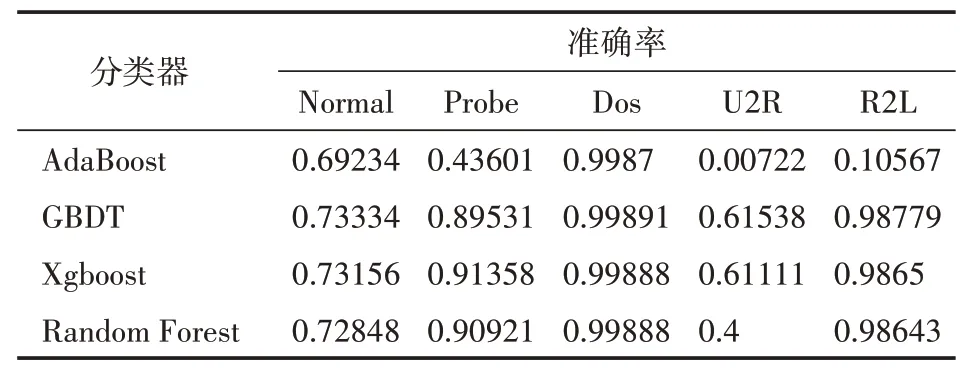
表2 4种分类器的分类准确率结果
由表2可以观察到,GBDT模型相比Ada⁃Boost模型、Xgboost模型而言,在U2R、normal、Dos以及probe等积累样本的分类准确率方面优势更加显著,即便Xgboost模型相比GBDT模型要差,但是显著优于随机森林。
由表3可以观察到,一般GBDT模型对应召回率维持在80%水平,但是总体上优于随机森林模型、AdaBoost以及Xgboost三种模型,并且随机森林模型在召回率方面基本保持一致,故而可以在识别数据里面存在的异常样本方面,GBDT模型更加合适。

表3 4种分类器的分类召回率结果
4 结语
在本文中,笔者将Boosting算法作为研究目标对象,并且针对三种不同类型机器学习算法进行了对比分析,同时针对三种不同机器学习算法对应数学原理进行了论述,借助试验对比了Xg⁃boost,AdaBoost,GBDT在KDD999准确率以及召回率上的表现。Boosting算法比随机森林算法更具优势。在进行网络入侵检测方面,GBDT和Xgboost比AdaBoost更具优势。对于Boosting算法而言,在集成学习方面具有显著优势特点,在今后的研究中,将采用真实的网络入侵流量进行研究,进一步的运用在实际网络异常检测过程中。
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
阅读与作文(英语初中版)(2019年8期)2019-08-27
软件导刊(2017年4期)2017-06-20
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年2期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
