
基于GAN的ISAR图像语义分割方法 *
2021-11-29 08:59吕国欣
雷达科学与技术 2021年5期
杜 兰, 吕国欣, 石 钰
(西安电子科技大学雷达信号处理国家重点实验室, 陕西西安 710071)
0 引言
逆合成孔径雷达(Inverse Synthetic Aperture Radar,ISAR)成像技术是当前对海、陆、空观测的重要方式,它作为一种能够远距离获取非合作目标图像的技术,在军事领域起到了重要作用。随着ISAR成像技术的不断成熟,对ISAR图像进行快速有效的自动解译,获得目标丰富的结构、姿态、尺寸等信息,受到了越来越广泛的关注。ISAR图像语义分割是ISAR图像处理和解译的重要技术支撑,语义分割指根据某种准则将图像划分为互不重叠的同质区域,并且给出不同区域中像素的语义类别,它能够提取图像中感兴趣区域,为后续图像识别与分类、场景解析、目标检测等任务作预处理。传统的语义分割方法利用像素的灰度、色彩、纹理等低级语义特征对像素进行分类,图像分割精度有限[1]。随着深度卷积神经网络的快速发展,基于深度学习的语义分割方法成为语义分割的主流方法[2-3]。Long 等人[4]在2014年提出的全卷积网络(Fully Convolutional Network,FCN)是首个端到端的深度语义分割模型,目前大多语义分割网络都是基于 FCN 的编码-解码结构实现的。 FCN 通过对编码过程中提取的特征图进行双线性插值上采样将其恢复至输入图像尺寸,实现像素级分类。文献[5]基于编码-解码结构,解码器进行上采样时利用编码部分记录的池化索引来恢复图像的细节信息,提升分割精度。文献[6]基于编码-解码结构,引入深度可分离空洞卷积在减少计算量的同时增大感受野,采用金字塔池化模块获取图像多尺度上下文信息,提升图像分割精度。传统的深度语义分割模型通常采用交叉熵损失函数训练模型对图像中的每一个像素进行分类,使模型学习原始图像像素到分割图像像素的映射关系,因此需要非常精准的标注图像来对模型进行训练。ISAR图像与光学图像相比表征性差,图像中散射点的不连续和强散射点存在的旁瓣效应,使得人工精准标注十分困难,传统深度语义分割方法在训练数据标注不精准的情况下无法保证分割性能稳健。
本文针对上述问题,提出了一种基于Pix2pixGAN[7]的ISAR图像语义分割方法。本方法将GAN[8]的对抗思想引入ISAR图像语义分割任务中,通过对抗学习使模型学习ISAR图像分布到其语义分割图像分布之间的映射,约束方式相比较于像素到像素的映射更加灵活,从而减弱模型对于精准标注的需求,提升语义标注不够精准的情况下模型的稳健性。
1 基于Pix2pixGAN的ISAR图像语义分割方法
1.1 基于Pix2pixGAN的ISAR图像语义分割网络
Pix2pixGAN是GAN的衍生模型之一,在图像生成、图像翻译和图像风格转换等任务上具有十分出色的表现[7]。所提方法的网络结构如图1所示,我们定义ISAR图像为x,其对应语义分割标签图像集为y,将ISAR图像作为条件信息约束生成器G生成数据的方向,训练生成器G以生成判别器D难以分辨的分割图像,训练判别器D以尽可能地分辨真假分割图像,通过这种对抗训练学习ISAR图像到其分割图像的映射关系G:(x,z)→y。本方法将ISAR图像xi和噪声向量z作为生成器G的输入,输出为生成的分割图像G(xi,z);将ISAR图像xi和生成的分割图像G(xi,z)或ISAR图像xi和真实的分割图像yi作为图像对输入判别器D,输出为判别器D判断输入图像对为真实图像的概率。采用交替迭代的方式训练该网络,首先固定生成器G,训练判别器D使其尽可能地区分G(xi,z)与yi;然后固定判别器D,训练生成器G使其生成的分割图像G(xi,z)与真实分割图像yi尽可能相似;循环上述交替迭代过程,当对抗达到平衡时,判别器D无法区分生成的分割图像G(xi,z)和真实的分割图像yi,也就是说生成器G能够生成近似于真实分割图像的分割结果。
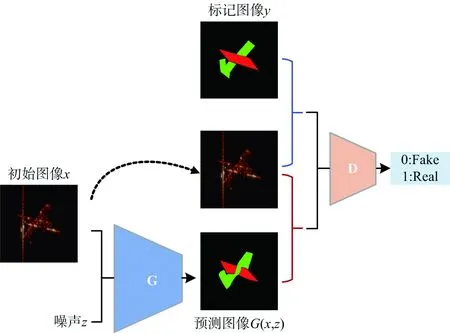
图1 基于Pix2pixGAN的ISAR图像语义分割方法框架
1.1.1 生成器网络结构
编码-解码结构是语义分割任务中常用的网络结构,首先使用编码器对输入图像进行特征提取,再使用解码器对特征图进行上采样,将特征图尺寸恢复至输入图像分辨率大小进行像素级分类。本文的生成器如图2所示,在编码-解码结构的基础上引入跳线结构,在上采样时引入编码部分的信息,将解码器每层特征与编码器中对称层的特征按通道拼接后再进行上采样,避免直接对特征图进行上采样时丢失大量细节信息,通过融合编码部分的底层特征来保证输出图像在细节上能够有较好的表现。生成器网络结构如图2所示,编码器由8个卷积层构成,对一张宽度、高度和通道数为256×256×3的图像经过特征提取后输出为512个大小为1×1的特征图。解码器由8个转置卷积层组成,对512个大小为1×1的特征图经过上采样后输出为一张宽度、高度和通道数为256×256×3的图像。

图2 生成器网络结构示意图
1.1.2 判别器网络结构
本文采用马尔科夫判别器来构建生成图像的局部信息,进一步提升生成的语义分割图像在细节上的表现。马尔科夫判别器的结构如图3所示,其为一个全卷积网络,采用四层卷积层对输入图像进行特征提取,得到一张n×n的特征图,网络的输出为一个n×n矩阵,其中矩阵中每一个结果对应输入图像中的一个感受野,即输出矩阵为输入图像中n×n个Patch的判别结果,最终以输出矩阵的均值判断输入图像为生成图像还是真实图像。马尔科夫判别器和生成器均是全卷积网络,因此可以处理任意尺寸的图像,增强了网络的扩展性。

图3 判别器网络结构示意图
1.2 损失函数
本文方法的损失函数由对抗损失和重构损失两部分组成。对抗损失函数LCGAN(G,D)如式(1)所示:
LCGAN(G,D)=Ex,y[logD(x,y)]+
Ex,z[log(1-D(x,G(x,z)))]
(1)
其中,生成器G的目标是生成与真实分割图像尽可能相似的图像以最小化损失函数,判别器D的目标是尽可能区分生成的分割图像与真实的分割图像以最大化损失函数,该过程可表示为
(2)
为了进一步提升生成器的性能,减小生成的分割图像与真实的分割图像的差异,本文方法采用L1损失函数减少生成图像的模糊程度,所以本方法使用L1损失函数构建生成的分割图像的低频部分,促使生成图像在全局上更接近于真实图像,L1重构损失如式(3)所示:
LL1(G)=Ex,y,z[‖y-G(x,z)‖1]
(3)
本文方法的目标函数可以表示为式(4)所示的形式:
(4)
式中,λ表示两个损失函数的相对重要程度。
2 实验结果与分析
2.1 实验数据
本文使用由电磁仿真软件FEKO对卫星目标建模、再通过BP成像算法得到的卫星目标ISAR图像数据集进行实验。该数据集包含五类卫星目标,分别为阿波罗卫星、北斗卫星、锁眼卫星、美国陆地卫星和天宫卫星,仿真CAD模型和其对应的ISAR图像示例分别如图4和图5所示。为了满足深度神经网络对于训练数据量的要求,我们对训练数据集进行平移和镜像操作,将训练图像数量扩充至原始数据量的36倍,五类卫星ISAR图像数量如表1所示。
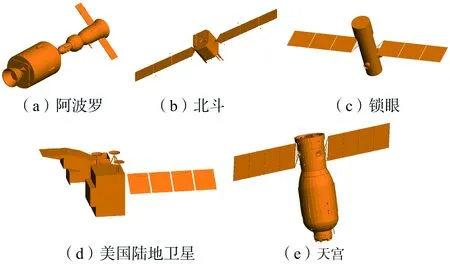
图4 卫星CAD模型示意图

图5 卫星目标ISAR图像示例
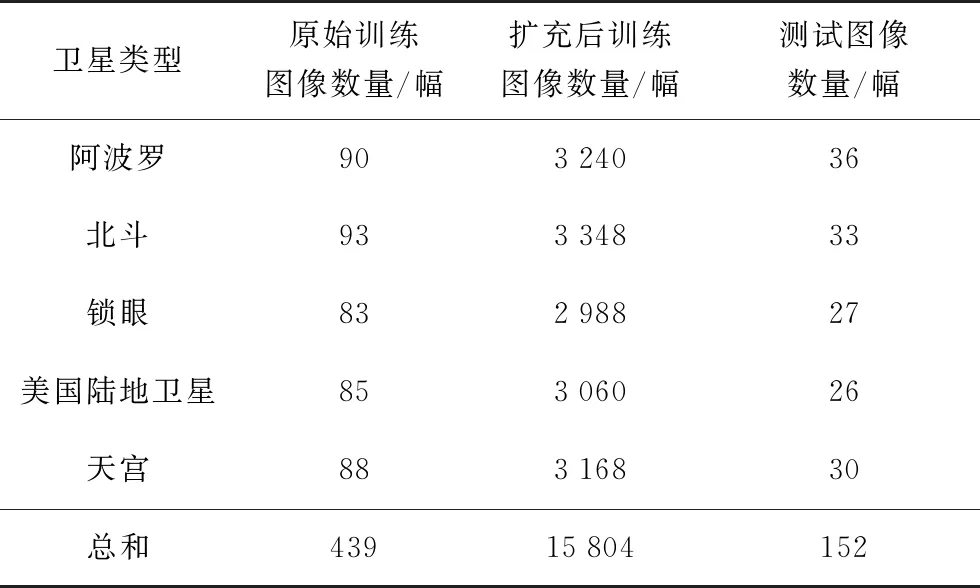
表1 五类卫星目标的样本数信息
2.2 性能评价指标
为了定量评估不同方法的分割性能,本文采用语义分割标准衡量准则——平均交并比(Mean Intersection over Union,MIoU)作为定量评判的准则,MIoU为预测结果与真实结果之间的交集与并集之比,计算示意图如图6所示。
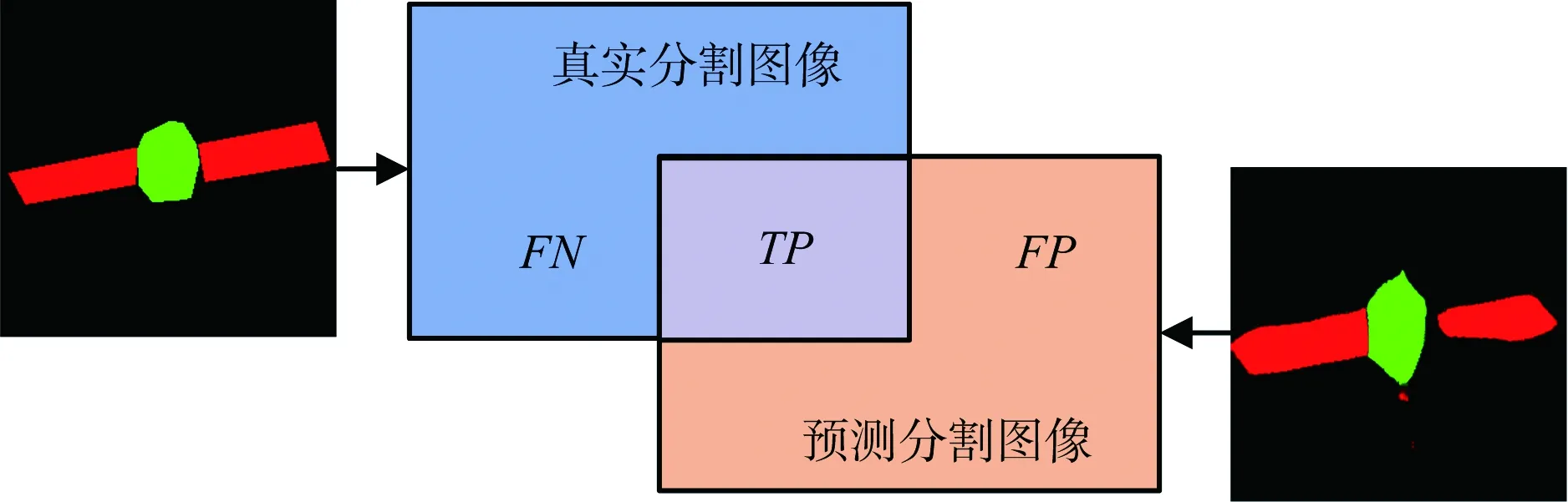
图6 计算MIoU示意图
图6中,TP表示预测分割图像与真实分割图像分类一致的像素数,FP表示真实分割图像中除去TP以外的像素数,FN表示预测分割图像中除去TP以外的像素数。
计算公式如下:
(5)
式中,M表示图像总数。
2.3 实验结果分析
1) 语义分割性能比较分析
图7给出了本文方法对不同卫星目标的分割结果,图中第一、二、三列分别为ISAR图像、分割图像和标签,第四列和第五列分别为从分割图像提取到的卫星太阳能帆板和主体,并且经过边缘细化、空洞填充等形态学操作后的结果。结果表明,对于不同类型卫星目标的ISAR图像,本文方法均能够取得较好的分割结果,经过掩膜分割后得到完整的太阳能帆板和主体。由图可知,本文的方法在太阳能帆板与主体粘连处能够实现精细的分割,在细节上有较好的表现,这表明本文方法中生成器和判别器的结构能够提升语义分割的细节表现,精细的语义分割结果能够为后续解译工作奠定良好的基础。
为了评估本文方法与现有的深度语义分割方法性能,表2给出了不同语义分割方法对于每类卫星的MIoU结果以及五类卫星MIoU的平均结果。由表2可以看出,在ISAR图像标签不够精准的情况下,本文方法依然取得了较好的分割精度,且对于不同卫星目标的分割性能稳定,说明模型具有较好的鲁棒性。由于ISAR图像人工标注无法保证语义标签的精确性,这种情况下MIoU定量评估结果并不能完全说明本文方法在分割精度上一定最优,但是足以说明其具有较好的分割性能。
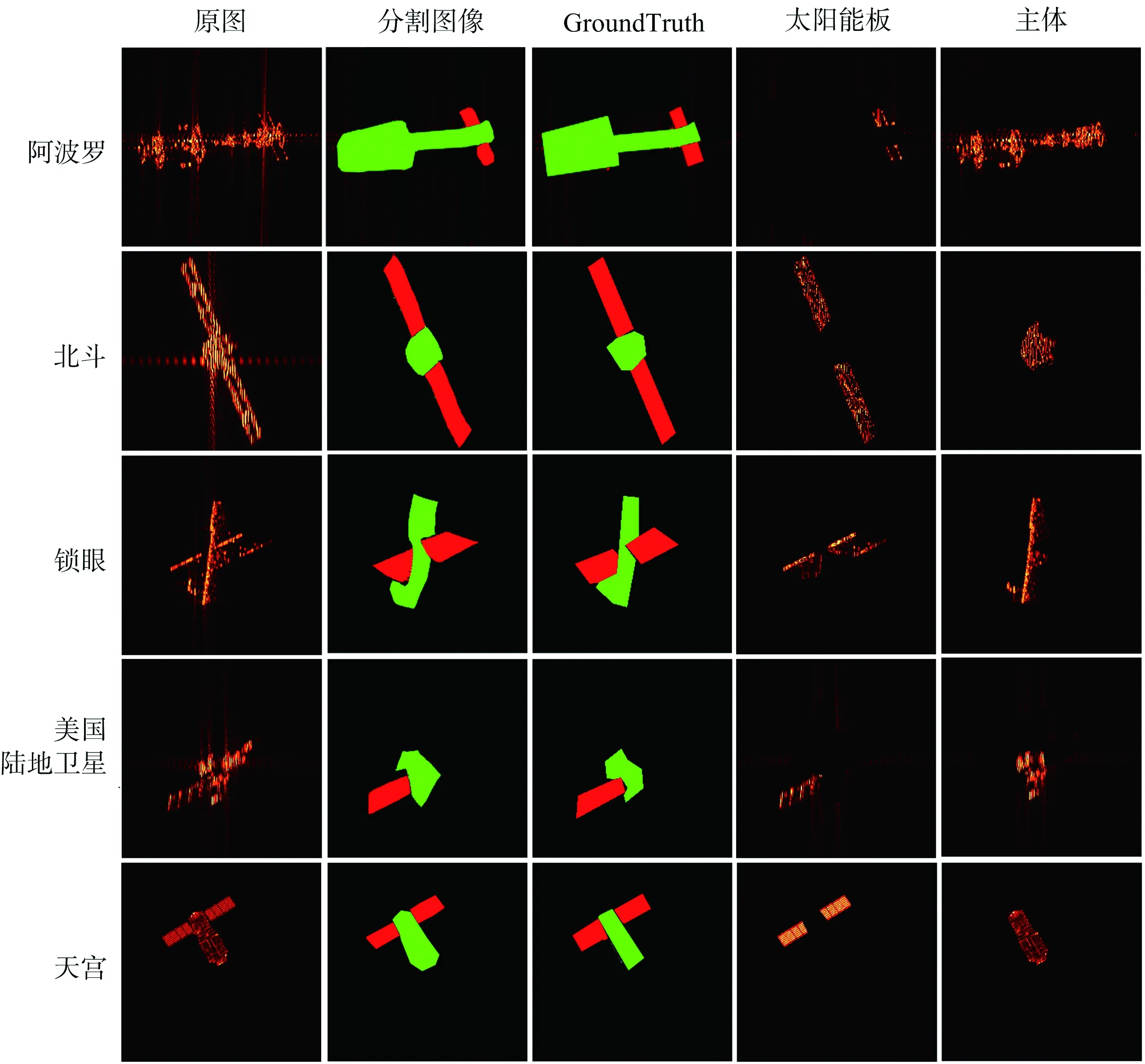
图7 本文方法的卫星ISAR图像分割结果示例(红色:太阳能板;绿色:主体)

表2 不同语义分割方法的MIoU %
图8给出了本文方法与三种传统深度语义分割方法在语义标签不够精准的情况下训练数据的分割结果示例。对照图8中的原图和Ground Truth可以看出,第一行至第三行的GroundTruth中均存在太阳能板和主体标注不完整的问题(主体标注明显不完整),第一、二行的GroundTruth中太阳能板和主体之间存在不同程度的断裂。其他三种对比方法的分割结果存在与GroundTruth相同的问题,分割结果不够准确;相比于对比方法的分割结果,本文方法的结果对GroundTruth的拟合度较低,但通过对照原图和本文方法的结果可以看出,本文方法能够比较完整地分割出主体和太阳能板,且太阳能板和主体间的连续性较好,没有明显断裂的情况。图8的结果说明在语义标注不够精准的情况下,其他对比的语义分割方法学习到的结果非常接近标注、也不够精准,而本文方法仍然能够准确地、完整地将目标的太阳能板和主体分割出来。这是因为所对比的语义分割方法采用交叉熵损失函数学习像素到像素之间语义类别的映射,此类方法对于语义标注的精度要求较高,在标注图像不精准的情况下会使得模型学到一些错误信息,导致分割结果不够精准;而GAN的对抗学习思想能够训练模型学习数据分布到分布之间的映射,它能够通过生成器与判别器的对抗博弈过程探究数据的分布情况,即使标注本身存在误差,由于约束方式相比较于像素到像素之间的语义类别映射更加灵活,不会对每个像素的预测误差进行惩罚,因而可以减弱模型对于精准标注的需求,使模型具有较好的泛化性。因此,在语义标签不够精准的情况下本文方法的语义分割性能更加稳健。

图8 语义标注不精准情况下不同分割方法的训练结果示例(红色:太阳能板;绿色:主体)
2) 不同模型空间、时间复杂度分析
为了分析本文方法与现有语义分割方法的模型复杂度与运算效率,表3计算了用于衡量不同模型时间复杂度和空间复杂度的浮点运算次数(Floating-point Operations, FLOPs)和总参数量,由于CNN 的FLOPs和参数量主要集中在卷积层、反卷积层和全连接层,其余层的FLOPs和参数量相比于卷积层、反卷积层和全连接层非常少,可以忽略,又由于所提方法和对比方法均未含有全连接层,因此我们分析时间和空间复杂度时仅考虑了卷积层和反卷积层。
时间复杂度与模型的FLOPs成正相关,计算公式如下式所示:
(6)
式中,K为卷积核与反卷积核的尺寸,C为卷积与反卷积通道数,D为卷积层的层数,N为反卷积层的层数,Mout,l为第l卷积层输出的特征图尺寸,Min,n为第n反卷积层输入的特征图尺寸。
空间复杂度与模型的总参数量成正相关,计算公式如下式所示:
(7)
式中,K为卷积核与反卷积核的尺寸,C为卷积与反卷积通道数,D为卷积层与反卷积层的总层数。

表3 不同模型总参数量、FLOPs和MIoU
由表3可以看出,FCN[3]和SegNet[4]具有较高的FLOPs, 这是因为FCN和SegNet均用普通的卷积组堆叠构成深层编码-解码结构,并且使用步长为1的卷积核使得输出特征图尺寸较大;Deep-LabV3+[5]模型中使用深度可分离卷积减少了计算量;本文方法采用步长为2的卷积核进行下采样使得输出特征图尺寸大大减小,因此具有最低的FLOPs;然而,本文方法使用跳线连接保持编码器细节信息的同时使得解码器部分的卷积通道数倍增,因此具有较高的参数量,如何进一步优化模型的空间复杂度,减少模型参数量是下一步需要探索的方向。
3 结束语
本文针对ISAR图像语义分割问题,提出了一种基于Pix2pixGAN的ISAR图像语义分割方法,该方法采用对抗学习思想学习ISAR图像分布到其语义分割图像分布的映射关系,同时通过构建分割图像的局部信息和全局信息来保证语义分割的精度。实验结果证明,本文方法能够对ISAR图像取得较好的语义分割结果,且在语义标注不够精准的情况下模型更稳健。然而,本文方法的网络存在较高时间复杂度的问题,如何进一步优化模型的时间复杂度是下一步需要探索的方向。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2022年8期)2022-08-31
北京大学学报(自然科学版)(2022年4期)2022-08-18
社会科学战线(2022年2期)2022-03-16
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
长江学术(2016年4期)2016-03-11
