
词袋模型和TF-IDF在文本分类中的比较研究
2021-11-28 02:30阎亚亚
电脑知识与技术 2021年28期
关键词:文本分类
阎亚亚
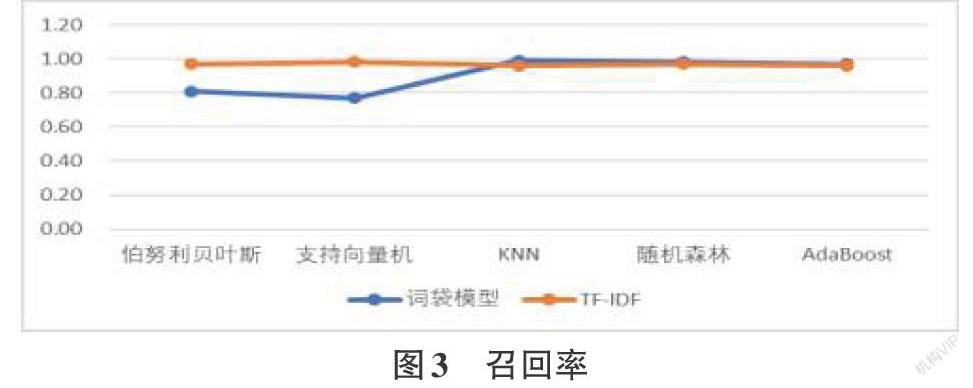
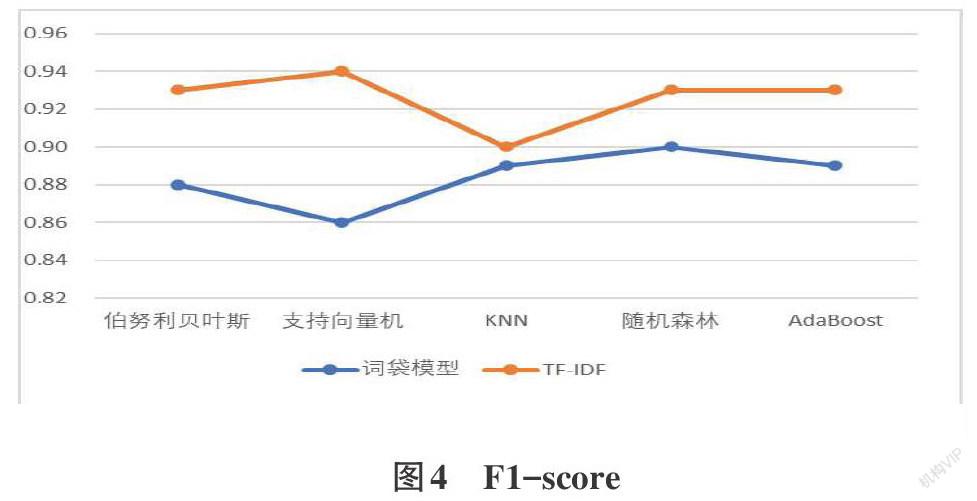
摘要:电商市场日益完善,网络购物成为更多人的消费方式,用户在电商平台上保留了大量的产品评论信息,通过人工对文本评论情感分类任务愈加艰巨,文本情感的自动分类作为自然语言处理技术的重要一门,近年来受到各界的广泛关注。本文首先对京东网页上爬取的某商品评论文本做预处理,重点研究词袋模型和TF-IDF两种文本特征选择方法下不同文本分类算法的分类效果,研究结果表明TF-IDF下的文本分类效果显著优于词袋模型。
关键词:词袋模型;TF-IDF;文本分类
中图分类号:TP391.1 文献标识码:A
文章编号:1009-3044(2021)28-0138-03
开放科学(资源服务)标识码(OSID):
Comparative Study of Word-bag Models and TF-IDF in Text Classification
YAN Ya-ya
(Chongqing Industrial and Commercial University, Chongqing 400067,China)
Absrtact: E-commerce market is becoming more and more perfect, online shopping has become more and more people's consumption mode, users have retained a large number of product comment information on the e-commerce platform, through manual text comment emotional classification task is becoming more and more arduous. As an important natural language processing technology, text emotion automatic classification has attracted wide attention in recent years. This paper first preprocesses the text of a commodity comment crawling on the JingDong web page, focusing on the classification effect of different text classification algorithms under the word bag model and TF-IDF two text feature selection methods. The results show that the text classification effect under TF-IDF is significantly better than that of the word bag model.
Key words: word bag model; TF-IDF; text classification
隨着大数据、云技术等现代化信息技术不断发展,电商市场也成为经济市场的重要部分,人们开始普遍习惯网络购物模式,很多购物平台保留了大量用户的评价信息,这些信息体现用户对商品的真实购买体验,对于新用户来说,根据他人的评论内容决定是否购买此商品,因此,这些评论信息对新用户的购买行为产生一定影响,同时,商家也可通过用户评论提高相关服务水平。类似此类评论信息更新速度快,信息量大,传统的人工文本处理不能满足发展需求,所以自动文本分类技术日益成为时代背景下的研究热点。
1文本分类概述及研究现状
文本分类可以理解为按照一定的分类标准或体系使用计算机对文本集实现对文本自动打标签的分类过程[1],文本分类的目的是将文档集合中为止类型的文本自动识别到一个类别或几个类别中。复旦大学李荣陆依据最大熵模型进行中文文本分类研究[2]。文本特征选取是文本分类的重要过程,ChuanWan等人提出了一种基于文本结构的SABigam算法可以对文本进行复合特征的提取[3]。徐冠华等人详细地对文本特征提取方法做了研究,从封装式特征选择算法和过滤式特征选择算法两方面进行总结[4]。朱梦等人引入特征词类间分布的表现力指数的特征选取算法[5]。文本分类在应用于众多领域中,学者对于文本分类的研究逐渐深入,文本自动分类技术愈加成熟。
2相关工作
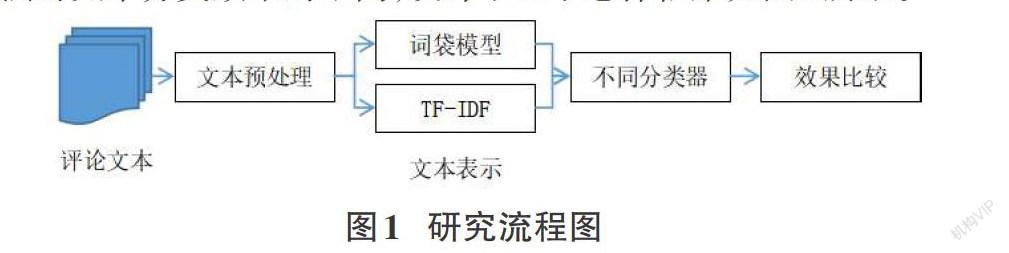
本文为研究词袋模型和TF-IDF进行文本特征选择处理方法对文本分类效果的不同,设计了以下总体框架如图1所示。
2.1文本采集及预处理
2.1.1文本采集
本文使用八爪鱼采集器,从京东商品网页上随机获取某商品的文本评论内容,将数据集保存在excel表格中,每条评价内容对应相应的评价态度,对应为1-5星,5星为评价最好的星级,这里采用人工打标签方式将星级划分为两种情感态度,其中1-2级为差评,3-5级为好评。
2.1.2文本预处理
首先对采集到的文本数据进行去重、删除异常样本处理,得到有效样本2566条,其中好评2083条,差评483条,并采用jieba分词工具进行分词,将文本中的停用词剔除;其次拆分训练集和测试集,得到训练样本1924条,测试样本642条。
2.2文本表示
文本是由词和短语构成的符号序列。要将自然语言处理问题转化成机器可学习的数学模型,首先要对词和文本进行向量化建模,即将自然语言转化为向量,这一过程叫做文本表示。
猜你喜欢
电脑知识与技术(2016年30期)2017-03-06
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
湖南大学学报·自然科学版(2016年4期)2016-08-12
中国教育信息化·基础教育(2016年2期)2016-05-31
软件(2015年5期)2015-08-22
电脑知识与技术(2015年10期)2015-05-29
