
基于目标识别的智能视频监控系统研究
2021-11-28 10:51李良熹荣进国
电脑知识与技术 2021年28期
李良熹 荣进国


摘要:研究野生动物生活习性所部署的视频监控设备,由于网络条件限制,通常只能将视频保存在存储设备中,由研究人员定期取回分析。大量的无效视频一方面影响监控设备的续航能力,一方面需要耗费大量的时间进行分析。使用目标识别算法赋予监控系统智能,对视频进行预处理,自动识别和保存包含目标动物的视频,可以提高监控设备的续航能力,降低研究者在视频中搜寻目标动物的工作量。本文以视频监控系统的智能化为研究目标,提出一种在边缘计算硬件上部署轻量级目标识别算法对包含目标动物的视频进行智能保存的方法。经过仿真实验,使用该方法可以提高视频监控设备的续航能力,减少后期人工处理的时间。
关键词: 目标识别; 深度学习; 智能视频监控; YOLO; 百度飞桨
中图分类号:TP391 文獻标识码:A
文章编号:1009-3044(2021)28-0001-03
开放科学(资源服务)标识码(OSID):
A Design of Intelligent Video Surveillance System Based on Target Detection
LI Liang-xi,RONG Jin-guo
(Chongqing Technology and Business Institute, Chongqing 401520,China)
Abstract:Video surveillance system for monitor wildlife usually save video clips in storage device because of network conditions. But most of the saved videos are invalid and need a lot of time to analyze. Target recognition algorithm can give video surveillance system intelligence, and only save the video when a specific wildlife is recognized. This paper presents an intelligence surveillance system using edge computing to recognize wildlife. Through testing, surveillance system with object-detection algorithm can effectively save a lot of storage space and reduce search time when locating the wildlife in video clips.
Key words:object detection; deep learning; intelligent video surveillance; YOLO; PaddlePaddle
生物多样性是确保生态环境的关键,任何一种生物的灭绝,都会带来一系列的链条式反应,引起生态环境的逐渐崩溃,保护野生动物就是保护人类自己。70年来,我国建立了2750个自然保护区,其中国家级有474个,自然保护区的总面积达到147万平方公里,占到陆域国土面积的15%,面积广大人烟稀少。
研究野生动物的分布、行为生态是对野生动物进行有针对性保护的关键之一,非侵入式监测是对野生动物进行监测的基本要求,数字影像技术是实现这一基本要求的重要途径之一。我国从20世纪90年代中期就开始使用红外相机技术在云南省高黎贡山地区研究物种分布和活动模式的研究[1]。随着对数据的要求越来越高,视频监控系统被广泛应用于野生动物的监控。在有条件的保护区通常部署实时视频监控系统,通过无线网络实时上传数据到服务器,而在缺乏条件的保护区通常部署硬塑料保护的视频监控设备,将数据保存在固态硬盘中,由研究人员定期取回分析,这种方式对视频监控设备的功耗和存储能力都提出了巨大的挑战。另外,由于取回的大部分视频数据都是没有野生动物出现的无效视频,研究人员需要花费大量的时间来分析和识别视频。
为了延长视频监控设备的续航时间,非实时视频监控设备通常采用“陷阱法”来触发录制,常用的陷阱法包括红外线探测器、动作传感器或者其他光感作为触发机关[2]。这些方法都无法有针对性地进行观测,任何风吹草动都可能触发录制。本文提出一种基于目标识别的智能视频监控方法,通过在嵌入式设备上部署轻量级目标识别算法,智能地识别所研究的野生动物,当特定的野生动物出现在镜头前时,智能地开始保存视频。通过使用视频进行仿真验证,该方法能有效地提高视频监控设备的续航能力,极大地减少后期筛选和识别的时间,具有很好的应用价值。
1 方案设计
1.1硬件设计
在视频监控终端部署AI智能算法,需要综合考虑功耗和运算速度[3],同时还需要考虑到硬件对深度学习框架的支持[4]。Jetson TX2是英伟达公司推出的嵌入式AI超级计算模块,只有一张信用卡大小,配置有NVIDA Pascal GPU和8G显存。其嵌入式、高性能的特性,使得在终端设备上使用深度学习进行目标识别成为可能。TX2提供两种运行模式,在MAX-Q均衡模式下,能效比最高,功耗仅为7.5瓦,而当运行于MAX-P强效模式下时,性能最高,功耗在15瓦左右。
Jetson TX2自带32G eMMC存储,在部署了深度学习算法后剩余12G左右空间,不足以保存视频数据。我们使用载板上提供的两种扩展接口进行扩展,其中SD card插槽支持256G的Full-Size SD卡,SATA接口可以使用SSD固态硬盘存储数据。
Jetson TX2支持多种接口的摄像设备,可以配备USB相机或者CSI相机。USB相机的优势在于易于整合,支持长距离工作,在不使用USB Hub的情况下线缆可以长达3米-5米,对于野外部署视频监控设备有一定的优势。而CSI相机的优势在于可以提供更高的分辨率,通过TX2的专用MIPI CSI-2接口可以降低CPU的处理时间。
经过综合权衡,在实验室环境中使用TX2 + USB高清摄像头 + SD卡方案进行系统仿真验证,生产环境则使用 TX2 + CSI相机 + SSD固态硬盘方案。
1.2目标识别算法设计
YOLO(You Only Look Once)是一种基于深度神经网络的目标检测和定位算法,其最大的特点是运行速度很快,可以用于实时系统[5]。YOLO是一种端到端的One Stage算法,将提出候选区和目标识别放在一个步骤中完成。Yolov3算法在Yolov1和YOLOv2的基础上,加深了网络结构,利用多尺度特征进行对象检测,在保持速度优势的前提下,提升了预测精度,增加了对小物体的识别能力[6]。
百度飞桨是中国首个自主研发、开源开放的深度学习框架,可以轻松的部署到不同架构的设备上。PaddleDetection飞桨目标检测模块,实现了多种主流目标检测算法,提供了丰富的数据增强策略、网络模块组件(如骨干网络)、损失函数等,并集成了模型压缩和跨平台高性能部署能力,成为我们的首选深度学习框架。在百度飞桨框架上对YOLOv3模型进行改进,可以取得流畅的识别效果和识别精度。
1.3视频输入输出设计
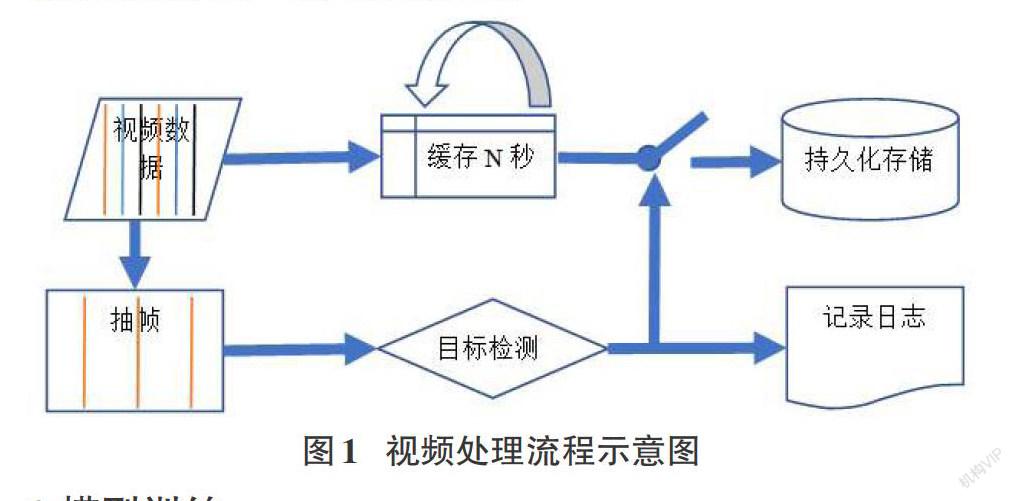
使用OpenCV获取USB摄像头的视频流数据,由于我们这里并不需要保存带有识别结果框的视频,我们对视频保存代码进行了修改。在内存中循环缓存一个长度为3秒的视频片段,当目标检测算法检测到目标动物出现时,记录动物的出现时间和离开时间,并从检测到目标动物前3秒开始将视频保存到持久存储设备。如果在3秒内都未检测到目标动物,则停止持久化视频数据,进入循环检测模式。
2 模型训练
2.1 数据预处理
我们使用AWA2(Animals with Attributes 2)数据库中的野生动物数据在原始的权重文件上进行再训练。AWA2数据集由50个类别的37322个图像组成,包含大象、老虎、斑马、蜘蛛猴等多种野生动物。我们从中挑选出长颈鹿的图片共1202张作为我们的原始数据,每张图片进行左右翻转,共得到2404张图片。
这些图片再使用Labelimg标注工具进行手工标注,标注为只包含单类别的YOLO的txt格式。
标注好的图片,采用K折交叉验证法随机选取其中的2204张作为训练集,其余的200张作为验证集。在训练之前,先对标注好的图片进行Anchor重聚类,得到适合检测长颈鹿的Anchor框大小,原始的Anchor大小和经过聚类后得到的Anchor框大小见下表:
2.2 模型选择
我们使用PP-YOLO_MobileNetV3_large轻量级模型[7]作为baseline进行模型的再训练,使用特定的野生动物数据在预訓练好的模型上进行再训练,可以有效的提高泛化能力。MobileNet相对于YOLO-tiny来说层数更深,但是计算量维持较小,是Google推出的针对移动端进行优化的轻量型网络结构。使用MobileNetV3作为backbone,可以在精准和效率上取得平衡。
MobileNetV3综合了V1的深度可分离卷积、V2的逆残差结构,并使用轻量级注意力机制来优化性能,使用h-swish激活函数代替swish函数来降低运算量[8]。
2.3 迁移学习
PP-YOLO_MobileNetV3_large使用COCO2017作为训练集,当我们需要使用AWA2数据集学习识别特定的动物时,需要进行迁移学习。我们去掉了预训练模型的最后一层,添加新层用于学习是否目标动物。由于我们只需要判断目标动物是否出现,所以需要修改多分类损失函数为二分类交叉熵损失函数[9]。
为了尽可能的保留在COCO数据集上的学习成果,我们冻结了预训练模型的基础层,充分训练后再使用非常小的学习率进行微调[10],经过微调得到的模型作为野生动物识别的基本模型。
2.4 抽帧检测
由于相邻的帧基本上是相同的,我们并不需要对每一帧都调用目标检测算法。常用的抽帧算法有两种,一种是按比例抽帧,一种是按FPS抽帧。在智能视频监控系统中,为了保证目标识别算法的流畅,我们选用按FPS进行抽帧。在视频处理模块中加入参数 fps_rate_max,如果视频的FPS大于fps_rate_max,则按照fps_rate_max进行抽帧检测。抽帧检测可以极大地降低系统的运算压力,提高检测的流畅度。
2.5 模型部署
在深度学习服务器上训练完成的模型,使用PaddleSlim进行模型压缩和量化后,使用TensorRT部署到Jetson TX2上[11]。NVIDIA TensorRT 是英伟达为NVIDIA GPU设计的高性能深度学习预测库,可为深度学习推理应用程序提供低延迟和高吞吐量,通常可以提高图像分类任务的推理速度3-6倍,PaddlePaddle采用子图的形式集成了TensorRT。经过测试,在不使用PaddleSlim和TensorRT进行加速的情况下,只能达到14fps,而使用了加速后能够达到42fps。
3 实验仿真
3.1 动物世界视频测试
根据实际测试需要,我们从购买的动物世界、国家地理、人与自然、生命礼赞、与猛兽同行、地球脉动等纪录片光盘中人工挑选了12段视频作为验证数据集进行测试。对于选中的测试视频,手工标记视频中长颈鹿出现的时间点和离开镜头的时间点,和智能视频系统所保存的视频进行回放对比。下面是《动物世界》 20181215 勇敢的长颈鹿(上)中截取的10分钟视频片段进行仿真测试的结果:
图3为智能识别监控系统录制的视频还原到原视频时间轴的结果。可以看出,智能视频监控系统能够有效地对目标动物进行识别,并智能地进行视频的保存。在实际工作场景下,目标动物的出现不会如此频繁,智能监控系统可以更大地节省存储空间。
3.2 结果分析
重新为保存的视频加上识别框后,结合日志进行检查,发现模型在目标动物密集的时候存在漏检现象,另外在视频片段开始21秒处有长颈鹿在水中的倒影并没有被识别到。由于智能视频监控系统只需要识别到目标动物的出现,当目标动物密集出现时的漏检现象并不会影响到系统的可靠存储。动物倒影的漏检,是由于做数据增强的时候没有考虑到可能会出现上下颠倒的长颈鹿,经过进一步的数据增强,增加了上下颠倒和旋转的数据集后,系统能够对倒影进行识别。
同时,对视频的目标识别算法常见的问题是无法达到足够的帧率,相对于行人识别等对fps敏感的场景,野生动物的识别可以采用抽帧识别的方法,大大地降低了系统的运算压力,这也是能够将YOLO目标识别算法实际应用到智能视频监控系统上的主要原因之一。
4 結语
将基于边缘计算的目标识别算法引入智能监控系统,可以为监控系统带来更多的智能。相对于传统的红外陷阱法和动感陷阱法,实时的目标识别方法能让相机更加有针对性的识别到特定的目标出现。智能的视频数据保存算法,进一步地确保了监控的可靠性。实验表明,本文所设计的智能监控系统能够大幅的提高视频监控设备的续航能力,降低研究人员后期分析大量视频所需要耗费的时间。
参考文献:
[1] 张明霞,曹林,权锐昌,等.利用红外相机监测西双版纳森林动态样地的野生动物多样性[J].生物多样性,2014,22(6):830-832.
[2] 肖治术,李欣海,姜广顺.红外相机技术在我国野生动物监测研究中的应用[J].生物多样性,2014,22(6):683-684.
[3] 孙洁,钱蕾.基于边缘计算模型的智能视频监控的研究[J].计算机与数字工程,2019,47(2):402-406.
[4] 孔令军,王锐,张南,等.边缘计算下的AI检测与识别算法综述[J].无线电通信技术,2019,45(5):453-462.
[5] Redmon J,Divvala S,Girshick R,et al.You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:779-788.
[6] Redmon J,Farhadi A.YOLOv3:an incremental improvement[EB/OL].2018:arXiv:1804.02767[cs.CV].https://arxiv.org/abs/1804.02767
[7] Long X,Deng K P,Wang G Z,et al.PP-YOLO:an effective and efficient implementation of object detector[EB/OL].2020
[8] Howard A,Sandler M,Chen B,et al.Searching for MobileNetV3[C]//2019 IEEE/CVF International Conference on Computer Vision (ICCV).October 27 - November 2,2019,Seoul,Korea (South).IEEE,2019:1314-1324.
[9] 宋非洋,吴黎明,郑耿哲,等.基于MobileNetV3的结构性剪枝优化[J].自动化与信息工程,2019,40(6):20-25.
[10] 邵伟平,王兴,曹昭睿,等.基于MobileNet与YOLOv3的轻量化卷积神经网络设计[J].计算机应用,2020,40(S1):8-13.
[11] 殷迅.基于嵌入式GPU平台深度学习算法的加速与优化[D].上海:上海交通大学,2019.
【通联编辑:唐一东】
猜你喜欢
中国水运(2016年11期)2017-01-04
电脑知识与技术(2016年28期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
科学与财富(2016年28期)2016-10-14
